多引擎同步
大多数新式 GPU 包含多个提供专用功能的独立引擎。 许多人具有一个或多个专用复制引擎和计算引擎,通常不同于 3D 引擎。 每个引擎都可以彼此并行执行命令。 Direct3D 12 使用队列和命令列表提供对 3D、计算和复制引擎的精细访问。
GPU 引擎
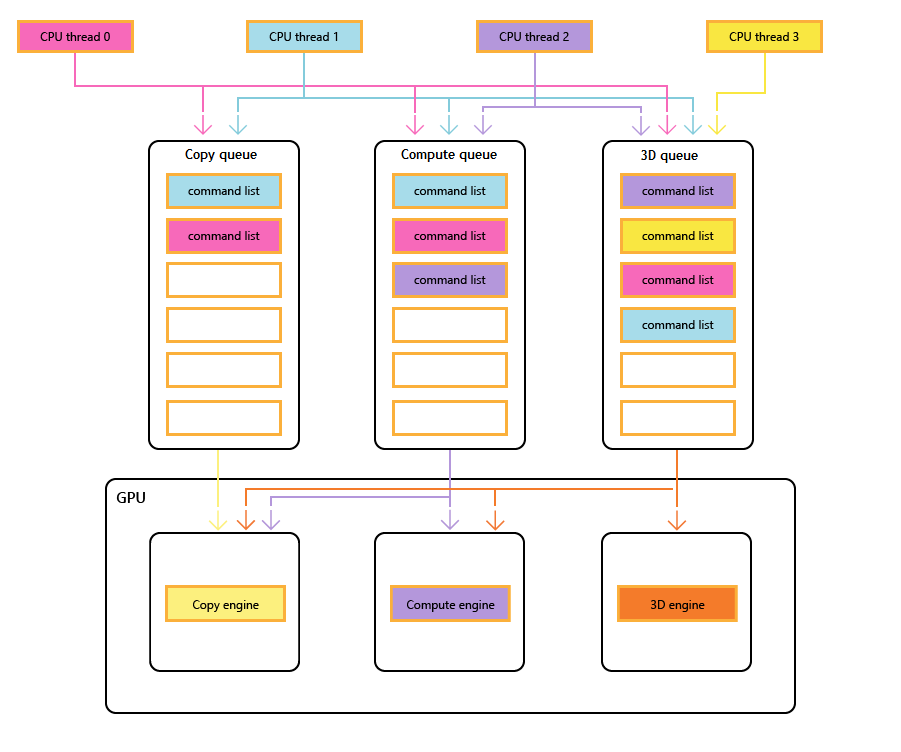
下图显示了游戏的 CPU 线程,每个线程填充一个或多个复制、计算和 3D 队列。 3D 队列可以驱动所有三个 GPU 引擎:计算队列可以驱动计算和复制引擎;和复制队列只是复制引擎。
当不同的线程填充队列时,无法简单地保证执行顺序,因此,当游戏需要它们时,需要同步机制。
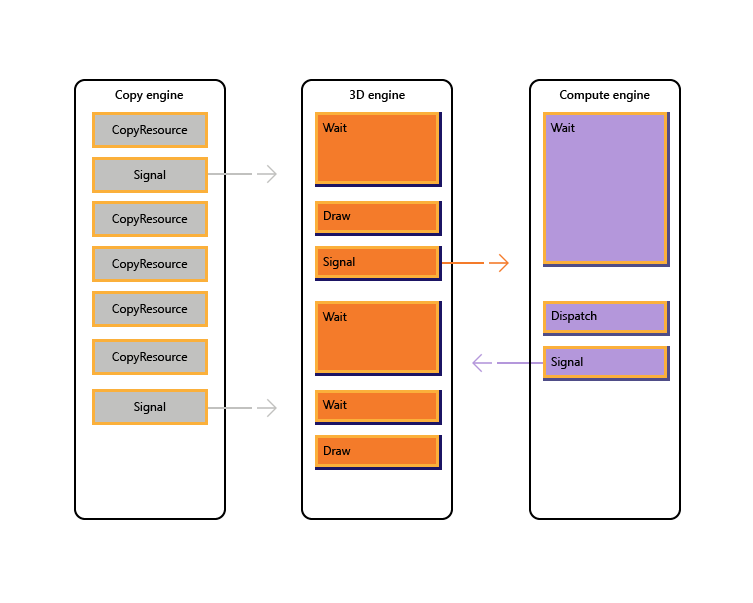
下图演示了游戏如何跨多个 GPU 引擎计划工作,包括在必要时进行引擎间同步:它显示具有引擎间依赖项的每个引擎工作负荷。 在此示例中,复制引擎首先复制呈现所需的某些几何图形。 3D 引擎等待这些副本完成,并呈现几何图形的预传递。 然后,计算引擎会使用此函数。 计算引擎 Dispatch的结果以及复制引擎上的多个纹理复制作由 3D 引擎用于最终 Draw 调用。
以下伪代码演示了游戏如何提交此类工作负载。
// Get per-engine contexts. Note that multiple queues may be exposed
// per engine, however that design is not reflected here.
copyEngine = device->GetCopyEngineContext();
renderEngine = device->GetRenderEngineContext();
computeEngine = device->GetComputeEngineContext();
copyEngine->CopyResource(geometry, ...); // copy geometry
copyEngine->Signal(copyFence, 101);
copyEngine->CopyResource(tex1, ...); // copy textures
copyEngine->CopyResource(tex2, ...); // copy more textures
copyEngine->CopyResource(tex3, ...); // copy more textures
copyEngine->CopyResource(tex4, ...); // copy more textures
copyEngine->Signal(copyFence, 102);
renderEngine->Wait(copyFence, 101); // geometry copied
renderEngine->Draw(); // pre-pass using geometry only into rt1
renderEngine->Signal(renderFence, 201);
computeEngine->Wait(renderFence, 201); // prepass completed
computeEngine->Dispatch(); // lighting calculations on pre-pass (using rt1 as SRV)
computeEngine->Signal(computeFence, 301);
renderEngine->Wait(computeFence, 301); // lighting calculated into buf1
renderEngine->Wait(copyFence, 102); // textures copied
renderEngine->Draw(); // final render using buf1 as SRV, and tex[1-4] SRVs
以下伪代码演示了复制和 3D 引擎之间的同步,以通过环形缓冲区完成类似堆的内存分配。 游戏可以灵活地在最大化并行度(通过大型缓冲区)和减少内存消耗和延迟(通过小缓冲区)之间选择适当的平衡。
device->CreateBuffer(&ringCB);
for(int i=1;i++){
if(i > length) copyEngine->Wait(fence1, i - length);
copyEngine->Map(ringCB, value%length, WRITE, pData); // copy new data
copyEngine->Signal(fence2, i);
renderEngine->Wait(fence2, i);
renderEngine->Draw(); // draw using copied data
renderEngine->Signal(fence1, i);
}
// example for length = 3:
// copyEngine->Map();
// copyEngine->Signal(fence2, 1); // fence2 = 1
// copyEngine->Map();
// copyEngine->Signal(fence2, 2); // fence2 = 2
// copyEngine->Map();
// copyEngine->Signal(fence2, 3); // fence2 = 3
// copy engine has exhausted the ring buffer, so must wait for render to consume it
// copyEngine->Wait(fence1, 1); // fence1 == 0, wait
// renderEngine->Wait(fence2, 1); // fence2 == 3, pass
// renderEngine->Draw();
// renderEngine->Signal(fence1, 1); // fence1 = 1, copy engine now unblocked
// renderEngine->Wait(fence2, 2); // fence2 == 3, pass
// renderEngine->Draw();
// renderEngine->Signal(fence1, 2); // fence1 = 2
// renderEngine->Wait(fence2, 3); // fence2 == 3, pass
// renderEngine->Draw();
// renderEngine->Signal(fence1, 3); // fence1 = 3
// now render engine is starved, and so must wait for the copy engine
// renderEngine->Wait(fence2, 4); // fence2 == 3, wait
多引擎方案
使用 Direct3D 12,可以避免意外出现因意外同步延迟而导致效率低下的问题。 它还允许在更高级别引入同步,以便可以确定所需的同步程度更高。 多引擎解决的第二个问题是使成本高昂的作更加明确,包括 3D 和视频之间的转换,由于多个内核上下文之间的同步,传统成本高昂。
具体而言,可以使用 Direct3D 12 解决以下方案。
- 异步和低优先级 GPU 工作。 这样,便可以并发执行低优先级 GPU 工作和原子作,使一个 GPU 线程能够在不阻塞的情况下使用另一个未同步线程的结果。
- 高优先级计算工作。 使用后台计算,可以中断 3D 呈现,以执行少量高优先级计算工作。 可以提前获取此工作的结果,以便在 CPU 上进行其他处理。
- 后台计算工作。 对于计算工作负荷,单独的低优先级队列允许应用程序利用备用 GPU 周期来执行后台计算,而不会对主要呈现(或其他)任务产生负面影响。 后台任务可能包括解压缩资源或更新模拟或加速结构。 后台任务应在 CPU 不频繁(大约每帧一次)上同步,以避免前台工作停滞或变慢。
- 流式处理和上传数据。 单独的复制队列取代了初始数据和更新资源的 D3D11 概念。 尽管应用程序负责 Direct3D 12 模型中的更多详细信息,但此责任附带了电源。 应用程序可以控制用于缓冲上传数据的系统内存量。 应用可以选择何时以及如何(CPU 与 GPU、阻止与非阻止)同步,并且可以跟踪进度并控制排队的工作量。
- 增加了并行度。 当应用程序具有用于前台工作的单独队列时,可以将更深入的队列用于后台工作负荷(例如视频解码)。
在 Direct3D 12 中,命令队列的概念是应用程序提交的大致串行工作序列的 API 表示形式。 屏障和其他技术允许在管道中或无序执行这项工作,但应用程序只看到单个完成时间线。 这对应于 D3D11 中的即时上下文。
同步 API
设备和队列
Direct3D 12 设备具有创建和检索不同类型和优先级的命令队列的方法。 大多数应用程序应使用默认命令队列,因为这些队列允许其他组件共享使用。 具有其他并发要求的应用程序可以创建其他队列。 队列由它们使用的命令列表类型指定。
请参阅以下 ID3D12Device创建方法。
- CreateCommandQueue:基于 direct3D 12_COMMAND_QUEUE_DESC结构中的信息创建命令队列。
- CreateCommandList:创建 Direct3D 12_COMMAND_LIST_TYPE类型的命令列表。
- CreateFence:创建围栏,指出 Direct3D 12_FENCE_FLAGS中的标志。 围栏用于同步队列。
所有类型的队列(3D、计算和复制)共享相同的接口,并且都是基于命令列表的队列。
请参阅以下 ID3D12CommandQueue的方法。
- ExecuteCommandLists:提交用于执行的命令列表数组。 ID3D12CommandList定义的每个命令列表。
- Signal:在队列(GPU 上运行)达到特定点时设置围栏值。
- 等待:队列等待,直到指定的围栏达到指定值。
请注意,捆绑包不受任何队列使用,因此无法使用此类型来创建队列。
围栏
多引擎 API 提供显式 API,用于使用围栏创建和同步。 围栏是由 UINT64 值控制的同步构造。 围栏值由应用程序设置。 信号作会修改围栏值,等待作会阻止,直到围栏达到请求的值或更高值。 当围栏达到特定值时,可以触发事件。
请参阅 ID3D12Fence 接口的方法。
- GetCompletedValue:返回围栏的当前值。
- SetEventOnCompletion:当围栏达到给定值时引发事件。
- Signal:将围栏设置为给定值。
围栏允许 CPU 访问当前围栏值,以及 CPU 等待和信号。
ID3D12Fence 接口上的 Signal 方法更新 CPU 端的围栏。 此更新会立即发生。 ID3D12CommandQueue 上的 Signal 方法 更新 GPU 端的围栏。 完成命令队列的所有其他作后,将进行此更新。
多引擎设置中的所有节点都可以读取并响应到达正确值的任何围栏。
应用程序设置自己的围栏值,一个很好的起点可能会为每个帧增加一次围栏。
围栏 可能。 这意味着围栏值不需要仅递增。 如果在两个不同的命令队列上排队 Signal作,或者如果两个 CPU 线程都在围栏上调用 Signal,则可能存在一个争用来确定哪个 Signal 最后完成,因此,哪些围栏值是保留的。 如果重排围栏,则任何新的等待(包括 SetEventOnCompletion 请求)都将与新的较低围栏值进行比较,因此可能无法满足,即使围栏值以前足够高,无法满足它们。 如果发生争用,则满足未完成等待的值和较低的值之间的等待 将 满足,而不考虑之后保留哪些值。
围栏 API 提供强大的同步功能,但可能会导致调试问题变得可能很困难。 建议每个围栏仅用于指示一个时间线上的进度,以防止信号器之间的争用。
复制和计算命令列表
所有三种类型的命令列表都使用 ID3D12GraphicsCommandList 接口,但复制和计算仅支持一部分方法。
复制和计算命令列表可以使用以下方法。
计算命令列表还可以使用以下方法。
- ClearState
- ClearUnorderedAccessViewFloat
- ClearUnorderedAccessViewUint
- DiscardResource
- Dispatch
- ExecuteIndirect
- SetComputeRoot32BitConstant
- SetComputeRoot32BitConstants
- SetComputeRootConstantBufferView
- SetComputeRootDescriptorTable
- SetComputeRootShaderResourceView
- SetComputeRootSignature
- SetComputeRootUnorderedAccessView
- SetDescriptorHeaps
- SetPipelineState
- SetPredication
- EndQuery
在调用 SetPipelineState时,计算命令列表必须设置计算 PSO。
捆绑包不能用于计算或复制命令列表或队列。
管道计算和图形示例
此示例演示如何使用围栏同步在队列(pComputeQueue引用)上创建计算工作的管道,该管道由图形处理队列 pGraphicsQueue使用。 计算和图形工作通过图形队列进行管道处理,该队列使用从多个帧返回的计算工作结果,并使用 CPU 事件来限制总体排队的工作总数。
void PipelinedComputeGraphics()
{
const UINT CpuLatency = 3;
const UINT ComputeGraphicsLatency = 2;
HANDLE handle = CreateEvent(nullptr, FALSE, FALSE, nullptr);
UINT64 FrameNumber = 0;
while (1)
{
if (FrameNumber > ComputeGraphicsLatency)
{
pComputeQueue->Wait(pGraphicsFence,
FrameNumber - ComputeGraphicsLatency);
}
if (FrameNumber > CpuLatency)
{
pComputeFence->SetEventOnFenceCompletion(
FrameNumber - CpuLatency,
handle);
WaitForSingleObject(handle, INFINITE);
}
++FrameNumber;
pComputeQueue->ExecuteCommandLists(1, &pComputeCommandList);
pComputeQueue->Signal(pComputeFence, FrameNumber);
if (FrameNumber > ComputeGraphicsLatency)
{
UINT GraphicsFrameNumber = FrameNumber - ComputeGraphicsLatency;
pGraphicsQueue->Wait(pComputeFence, GraphicsFrameNumber);
pGraphicsQueue->ExecuteCommandLists(1, &pGraphicsCommandList);
pGraphicsQueue->Signal(pGraphicsFence, GraphicsFrameNumber);
}
}
}
若要支持此管道处理,必须有一个缓冲区,该缓冲区 ComputeGraphicsLatency+1 从计算队列传递到图形队列的数据的不同副本。 命令列表必须使用 UAV 和间接读取和写入缓冲区中相应“版本”的数据。 计算队列必须等到图形队列已完成从帧 N 的数据中读取数据,然后才能写入帧 N+ComputeGraphicsLatency。
请注意,相对于 CPU 运行的计算队列量不直接取决于所需的缓冲量,但是,超出可用缓冲区空间量的队列工作不太有用。
避免间接的替代机制是创建与每个“重命名”版本的数据对应的多个命令列表。 下一个示例在扩展上一个示例时使用此技术,以允许计算和图形队列以更异步方式运行。
异步计算和图形示例
下一个示例允许图形从计算队列异步呈现。 这两个阶段之间仍有固定的缓冲数据量,但是现在图形工作会独立进行,并在图形工作排队时使用 CPU 上已知的计算阶段最 up-to日期结果。 如果图形工作是由另一个源更新的,例如用户输入,这将很有用。 必须有多个命令列表,以便一次运行图形工作的 ComputeGraphicsLatency 帧,并且函数 UpdateGraphicsCommandList 表示更新命令列表以包括最新的输入数据,并从相应的缓冲区中读取计算数据。
计算队列仍必须等待图形队列完成管道缓冲区,但引入了第三个围栏(pGraphicsComputeFence),以便可以跟踪图形读取计算工作与图形进度的进度。 这反映了现在连续图形帧可以从同一计算结果中读取或跳过计算结果这一事实。 更高效但稍微复杂的设计将只使用单个图形围栏,并存储到每个图形帧使用的计算帧的映射。
void AsyncPipelinedComputeGraphics()
{
const UINT CpuLatency{ 3 };
const UINT ComputeGraphicsLatency{ 2 };
// The compute fence is at index 0; the graphics fence is at index 1.
ID3D12Fence* rgpFences[]{ pComputeFence, pGraphicsFence };
HANDLE handles[2];
handles[0] = CreateEvent(nullptr, FALSE, TRUE, nullptr);
handles[1] = CreateEvent(nullptr, FALSE, TRUE, nullptr);
UINT FrameNumbers[]{ 0, 0 };
ID3D12GraphicsCommandList* rgpGraphicsCommandLists[CpuLatency];
CreateGraphicsCommandLists(ARRAYSIZE(rgpGraphicsCommandLists),
rgpGraphicsCommandLists);
// Graphics needs to wait for the first compute frame to complete; this is the
// only wait that the graphics queue will perform.
pGraphicsQueue->Wait(pComputeFence, 1);
while (true)
{
for (auto i = 0; i < 2; ++i)
{
if (FrameNumbers[i] > CpuLatency)
{
rgpFences[i]->SetEventOnCompletion(
FrameNumbers[i] - CpuLatency,
handles[i]);
}
else
{
::SetEvent(handles[i]);
}
}
auto WaitResult = ::WaitForMultipleObjects(2, handles, FALSE, INFINITE);
if (WaitResult > WAIT_OBJECT_0 + 1) continue;
auto Stage = WaitResult - WAIT_OBJECT_0;
++FrameNumbers[Stage];
switch (Stage)
{
case 0:
{
if (FrameNumbers[Stage] > ComputeGraphicsLatency)
{
pComputeQueue->Wait(pGraphicsComputeFence,
FrameNumbers[Stage] - ComputeGraphicsLatency);
}
pComputeQueue->ExecuteCommandLists(1, &pComputeCommandList);
pComputeQueue->Signal(pComputeFence, FrameNumbers[Stage]);
break;
}
case 1:
{
// Recall that the GPU queue started with a wait for pComputeFence, 1
UINT64 CompletedComputeFrames = min(1,
pComputeFence->GetCompletedValue());
UINT64 PipeBufferIndex =
(CompletedComputeFrames - 1) % ComputeGraphicsLatency;
UINT64 CommandListIndex = (FrameNumbers[Stage] - 1) % CpuLatency;
// Update graphics command list based on CPU input and using the appropriate
// buffer index for data produced by compute.
UpdateGraphicsCommandList(PipeBufferIndex,
rgpGraphicsCommandLists[CommandListIndex]);
// Signal *before* new rendering to indicate what compute work
// the graphics queue is DONE with
pGraphicsQueue->Signal(pGraphicsComputeFence, CompletedComputeFrames - 1);
pGraphicsQueue->ExecuteCommandLists(1,
rgpGraphicsCommandLists + CommandListIndex);
pGraphicsQueue->Signal(pGraphicsFence, FrameNumbers[Stage]);
break;
}
}
}
}
多队列资源访问
若要访问多个队列上的资源,应用程序必须遵循以下规则。
资源访问(引用 Direct3D 12_RESOURCE_STATES)由队列类型类而不是队列对象确定。 队列有两个类型类:计算/3D 队列是一个类型类,Copy 是第二个类型类。 因此,一个 3D 队列上具有NON_PIXEL_SHADER_RESOURCE状态障碍的资源可以在任何 3D 或计算队列上使用该状态,但需要序列化大多数写入的同步要求。 在两个类型类(COPY_SOURCE和COPY_DEST)之间共享的资源状态被视为每种类型类的不同状态。 因此,如果资源转换为复制队列上的COPY_DEST,则无法从 3D 或计算队列访问复制目标,反之亦然。
总结。
- 队列“object”是任何单个队列。
- 队列“type”是以下三者之一:计算、3D 和 Copy。
- 队列“type class”是以下两者中的任何一个:计算/3D 和 Copy。
用作初始状态的 COPY 标志(COPY_DEST和COPY_SOURCE)表示 3D/Compute 类型类中的状态。 若要最初在复制队列上使用资源,应以 COMMON 状态启动。 COMMON 状态可用于使用隐式状态转换在复制队列上的所有用法。
尽管资源状态在所有计算队列和 3D 队列之间共享,但不允许在不同队列上同时写入资源。 此处的“同时”表示在某些硬件上无法进行非同步执行,因此无法同步执行。 以下规则适用。
- 一次只能有一个队列写入资源。
- 只要多个队列不读取写入器正在修改的字节(同时写入的字节会生成未定义的结果),就可以从资源中读取这些队列。
- 在写入后,必须使用隔离区来同步,然后另一个队列才能读取写入的字节或进行任何写入访问。
显示的后退缓冲区必须处于 Direct3D 12_RESOURCE_STATE_COMMON状态。
相关主题
使用资源屏障在 Direct3D 12 中同步资源状态
Direct3D 12 中的 内存管理