działanie Kopiuj w usługach Azure Data Factory i Azure Synapse Analytics
DOTYCZY:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
W potokach usług Azure Data Factory i Synapse można użyć działanie Kopiuj do kopiowania danych między magazynami danych znajdującymi się lokalnie i w chmurze. Po skopiowaniu danych możesz użyć innych działań, aby jeszcze bardziej je przekształcić i przeanalizować. Możesz również użyć działanie Kopiuj, aby opublikować wyniki transformacji i analizy na potrzeby analizy biznesowej i użycia aplikacji.
Działanie Kopiuj jest wykonywany w środowisku Integration Runtime. Różne typy środowisk Integration Runtime można używać w różnych scenariuszach kopiowania danych:
- Podczas kopiowania danych między dwoma magazynami danych, które są publicznie dostępne za pośrednictwem Internetu z dowolnego adresu IP, możesz użyć środowiska Azure Integration Runtime do działania kopiowania. To środowisko Integration Runtime jest bezpieczne, niezawodne, skalowalne i globalnie dostępne.
- Podczas kopiowania danych do i z magazynów danych, które znajdują się lokalnie lub w sieci z kontrolą dostępu (na przykład sieci wirtualnej platformy Azure), należy skonfigurować własne środowisko Integration Runtime.
Środowisko Integration Runtime musi być skojarzone z każdym magazynem danych źródła i ujścia. Aby uzyskać informacje na temat sposobu, w jaki działanie Kopiuj określa, które środowisko Integration Runtime ma być używane, zobacz Określanie, którego środowiska IR użyć.
Uwaga
Nie można używać więcej niż jednego własnego środowiska Integration Runtime w ramach tego samego działanie Kopiuj. Źródło i ujście dla działania muszą być połączone z tym samym własnym środowiskiem Integration Runtime.
Aby skopiować dane ze źródła do ujścia, usługa uruchamiana przez działanie Kopiuj wykonuje następujące kroki:
- Odczytuje dane ze źródłowego magazynu danych.
- Wykonuje serializacji/deserializacji, kompresji/dekompresji, mapowania kolumn itd. Wykonuje te operacje na podstawie konfiguracji wejściowego zestawu danych, wyjściowego zestawu danych i działanie Kopiuj.
- Zapisuje dane w magazynie danych ujścia/docelowego.

Uwaga
Jeśli własne środowisko Integration Runtime jest używane w źródłowym lub ujściu magazynu danych w ramach działanie Kopiuj, źródło i ujście muszą być dostępne z serwera obsługującego środowisko Integration Runtime, aby działanie Kopiuj zakończyło się pomyślnie.
Obsługiwane magazyny danych i formaty
Uwaga
Jeśli łącznik jest oznaczony jako wersja zapoznawcza można go wypróbować, a następnie przekazać nam opinię na jego temat. Jeśli w swoim rozwiązaniu chcesz wprowadzić zależność od łączników w wersji zapoznawczej, skontaktuj się z pomocą techniczną platformy Azure.
Obsługiwane formaty plików
Usługa Azure Data Factory obsługuje następujące formaty plików. Zapoznaj się z każdym artykułem, aby zapoznać się z ustawieniami opartymi na formacie.
- Format Avro
- Format binarny
- Format tekstu rozdzielanego
- Format programu Excel
- Format góry lodowej (tylko dla usługi Azure Data Lake Storage Gen2)
- Format JSON
- Format ORC
- Format Parquet
- Format XML
Można użyć działanie Kopiuj, aby skopiować pliki zgodnie z rzeczywistym użyciem między dwoma magazynami danych opartymi na plikach, w tym przypadku dane są wydajnie kopiowane bez serializacji lub deserializacji. Ponadto można również analizować lub generować pliki danego formatu, na przykład można wykonać następujące czynności:
- Skopiuj dane z bazy danych programu SQL Server i zapisz je w usłudze Azure Data Lake Storage Gen2 w formacie Parquet.
- Skopiuj pliki w formacie tekstowym (CSV) z lokalnego systemu plików i zapisuj je w usłudze Azure Blob Storage w formacie Avro.
- Skopiuj spakowane pliki z lokalnego systemu plików, dekompresuj je na bieżąco i zapisz wyodrębnione pliki do usługi Azure Data Lake Storage Gen2.
- Skopiuj dane w formacie skompresowanego tekstu Gzip (CSV) z usługi Azure Blob Storage i zapisz je w usłudze Azure SQL Database.
- Wiele innych działań wymagających serializacji/deserializacji lub kompresji/dekompresji.
Obsługiwane regiony
Usługa, która umożliwia działanie Kopiuj, jest dostępna globalnie w regionach i lokalizacjach geograficznych wymienionych w lokalizacjach środowiska Azure Integration Runtime. Globalnie dostępna topologia zapewnia wydajne przenoszenie danych, które zwykle pozwala uniknąć przeskoków między regionami. Zobacz Produkty według regionów , aby sprawdzić dostępność usług Data Factory, Obszarów roboczych usługi Synapse i przenoszenia danych w określonym regionie.
Konfigurowanie
Aby wykonać działanie Kopiuj za pomocą potoku, możesz użyć jednego z następujących narzędzi lub zestawów SDK:
- Narzędzie do kopiowania danych
- Witryna Azure Portal
- Zestaw SDK platformy .NET
- Zestaw SDK języka Python
- Azure PowerShell
- Interfejs API REST
- Szablon usługi Azure Resource Manager
Ogólnie rzecz biorąc, aby używać działanie Kopiuj w potokach usługi Azure Data Factory lub Synapse, należy:
- Utwórz połączone usługi dla źródłowego magazynu danych i magazynu danych ujścia. Listę obsługiwanych łączników można znaleźć w sekcji Obsługiwane magazyny danych i formaty tego artykułu. Zapoznaj się z sekcją "Właściwości połączonej usługi" w artykule dotyczącym łącznika, aby uzyskać informacje o konfiguracji i obsługiwane właściwości.
- Tworzenie zestawów danych dla źródła i ujścia. Zapoznaj się z sekcjami "Właściwości zestawu danych" w artykułach dotyczących łącznika źródła i ujścia, aby uzyskać informacje o konfiguracji i obsługiwane właściwości.
- Utwórz potok przy użyciu działanie Kopiuj. Następna sekcja zawiera przykład.
Składnia
Poniższy szablon działanie Kopiuj zawiera pełną listę obsługiwanych właściwości. Określ te, które pasują do danego scenariusza.
"activities":[
{
"name": "CopyActivityTemplate",
"type": "Copy",
"inputs": [
{
"referenceName": "<source dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<sink dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>",
<properties>
},
"sink": {
"type": "<sink type>"
<properties>
},
"translator":
{
"type": "TabularTranslator",
"columnMappings": "<column mapping>"
},
"dataIntegrationUnits": <number>,
"parallelCopies": <number>,
"enableStaging": true/false,
"stagingSettings": {
<properties>
},
"enableSkipIncompatibleRow": true/false,
"redirectIncompatibleRowSettings": {
<properties>
}
}
}
]
Szczegóły składni
| Właściwości | opis | Wymagane? |
|---|---|---|
| type | W przypadku działanie Kopiuj ustaw wartość naCopy |
Tak |
| Wejścia | Określ utworzony zestaw danych wskazujący dane źródłowe. Działanie Kopiuj obsługuje tylko pojedyncze dane wejściowe. | Tak |
| Wyjść | Określ utworzony zestaw danych wskazujący dane ujścia. Działanie Kopiuj obsługuje tylko pojedyncze dane wyjściowe. | Tak |
| typeProperties | Określ właściwości do skonfigurowania działanie Kopiuj. | Tak |
| source | Określ typ źródła kopiowania i odpowiednie właściwości pobierania danych. Aby uzyskać więcej informacji, zobacz sekcję "właściwości działanie Kopiuj" w artykule łącznika wymienionym w temacie Obsługiwane magazyny danych i formaty. |
Tak |
| zlew | Określ typ ujścia kopiowania i odpowiednie właściwości do zapisywania danych. Aby uzyskać więcej informacji, zobacz sekcję "właściwości działanie Kopiuj" w artykule łącznika wymienionym w temacie Obsługiwane magazyny danych i formaty. |
Tak |
| Translator | Określ jawne mapowania kolumn ze źródła do ujścia. Ta właściwość ma zastosowanie, gdy domyślne zachowanie kopiowania nie spełnia Twoich potrzeb. Aby uzyskać więcej informacji, zobacz Mapowanie schematu w działaniu kopiowania. |
Nie. |
| dataIntegrationUnits | Określ miarę reprezentującą ilość mocy używanej przez środowisko Azure Integration Runtime do kopiowania danych. Te jednostki były wcześniej znane jako jednostki przenoszenia danych w chmurze (DMU). Aby uzyskać więcej informacji, zobacz Integracja danych Units (Jednostki Integracja danych). |
Nie. |
| parallelCopies | Określ równoległość, której chcesz użyć działanie Kopiuj podczas odczytywania danych ze źródła i zapisywania danych do ujścia. Aby uzyskać więcej informacji, zobacz Kopiowanie równoległe. |
Nie. |
| zachować | Określ, czy zachować metadane/listy ACL podczas kopiowania danych. Aby uzyskać więcej informacji, zobacz Zachowywanie metadanych. |
Nie. |
| enableStaging ustawienia przejściowe |
Określ, czy dane tymczasowe mają być przygotowane w usłudze Blob Storage zamiast bezpośrednio kopiować dane ze źródła do ujścia. Aby uzyskać informacje na temat przydatnych scenariuszy i szczegółów konfiguracji, zobacz Kopiowanie etapowe. |
Nie. |
| enableSkipIncompatibleRow redirectIncompatibleRowSettings |
Wybierz sposób obsługi niezgodnych wierszy podczas kopiowania danych ze źródła do ujścia. Aby uzyskać więcej informacji, zobacz Odporność na uszkodzenia. |
Nie. |
Monitorowanie
Możesz monitorować działanie działanie Kopiuj w potokach usługi Azure Data Factory i Synapse zarówno wizualnie, jak i programowo. Aby uzyskać szczegółowe informacje, zobacz Monitorowanie działania kopiowania.
Kopia przyrostowa
Potoki usługi Data Factory i Synapse umożliwiają przyrostowe kopiowanie danych różnicowych ze źródłowego magazynu danych do magazynu danych ujścia. Aby uzyskać szczegółowe informacje, zobacz Samouczek: przyrostowe kopiowanie danych.
Wydajności i dostosowywanie
Środowisko monitorowania działania kopiowania pokazuje statystyki wydajności kopiowania dla każdego przebiegu działania. W przewodniku działanie Kopiuj wydajności i skalowalności opisano kluczowe czynniki wpływające na wydajność przenoszenia danych za pośrednictwem działanie Kopiuj. Zawiera również listę wartości wydajności obserwowanych podczas testowania i omawia sposób optymalizacji wydajności działanie Kopiuj.
Wznów z ostatniego nieudanego przebiegu
działanie Kopiuj obsługuje wznawianie ostatniego nieudanego uruchomienia podczas kopiowania dużych plików w formacie binarnym między magazynami opartymi na plikach i wybrać zachowanie hierarchii folderów/plików ze źródła do ujścia, np. do migrowania danych z usługi Amazon S3 do usługi Azure Data Lake Storage Gen2. Dotyczy to następujących łączników opartych na plikach: Amazon S3, Amazon S3 Compatible Storage Azure Blob, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2, Azure Files, File System, FTP, Google Cloud Storage, HDFS, Oracle Cloud Storage i SFTP.
Działanie kopiowania można wykorzystać na następujące dwa sposoby:
Ponawianie próby na poziomie działania: możesz ustawić liczbę ponownych prób dla działania kopiowania. W trakcie wykonywania potoku, jeśli uruchomienie tego działania kopiowania zakończy się niepowodzeniem, następne automatyczne ponowienie zostanie uruchomione od punktu niepowodzenia ostatniej wersji próbnej.
Ponowne uruchamianie z działania zakończonego niepowodzeniem: po zakończeniu wykonywania potoku można również wyzwolić ponowne uruchomienie z działania zakończonego niepowodzeniem w widoku monitorowania interfejsu użytkownika usługi ADF lub programowo. Jeśli działanie nie powiodło się, jest działaniem kopiowania, potok będzie nie tylko ponownie uruchamiany z tego działania, ale także wznawiać działanie z punktu awarii poprzedniego przebiegu.
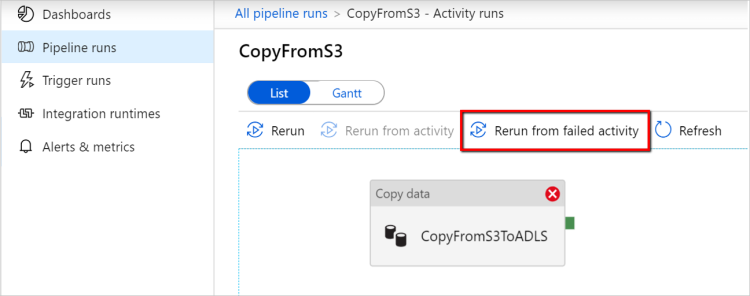
Kilka punktów do zapamiętania:
- Wznawianie odbywa się na poziomie pliku. Jeśli działanie kopiowania nie powiedzie się podczas kopiowania pliku, w następnym uruchomieniu ten konkretny plik zostanie ponownie skopiowany.
- Aby wznowić działanie w celu prawidłowego działania, nie należy zmieniać ustawień działania kopiowania między ponownymi uruchomieniami.
- Podczas kopiowania danych z usług Amazon S3, Azure Blob, Azure Data Lake Storage Gen2 i Google Cloud Storage działanie kopiowania może wznawiać z dowolnej liczby skopiowanych plików. Chociaż w przypadku pozostałych łączników opartych na plikach jako źródła, obecnie działanie kopiowania obsługuje wznawianie z ograniczonej liczby plików, zwykle w zakresie dziesiątek tysięcy i różni się w zależności od długości ścieżek plików; pliki wykraczające poza tę liczbę zostaną ponownie skopiowane podczas ponownego uruchamiania.
W przypadku innych scenariuszy niż kopiowanie plików binarnych działanie kopiowania rozpoczyna się od początku.
Uwaga
Wznawianie ostatniego nieudanego uruchomienia za pośrednictwem własnego środowiska Integration Runtime jest teraz obsługiwane tylko w środowisku Integration Runtime hostowanym samodzielnie w wersji 5.43.8935.2 lub nowszej.
Zachowywanie metadanych wraz z danymi
Podczas kopiowania danych ze źródła do ujścia w scenariuszach, takich jak migracja typu data lake, można również zachować metadane i listy ACL wraz z danymi przy użyciu działania kopiowania. Aby uzyskać szczegółowe informacje, zobacz Zachowywanie metadanych .
Dodawanie tagów metadanych do ujścia opartego na plikach
Gdy ujście jest oparte na usłudze Azure Storage (Azure Data Lake Storage lub Azure Blob Storage), możemy zdecydować się na dodanie niektórych metadanych do plików. Te metadane będą wyświetlane jako część właściwości pliku jako pary Klucz-wartość. Dla wszystkich typów ujść opartych na plikach można dodać metadane obejmujące zawartość dynamiczną przy użyciu parametrów potoku, zmiennych systemowych, funkcji i zmiennych. Oprócz tego w przypadku ujścia opartego na plikach binarnych istnieje możliwość dodania daty/godziny ostatniej modyfikacji (pliku źródłowego) przy użyciu słowa kluczowego $$LASTMODIFIED, a także wartości niestandardowych jako metadanych do pliku ujścia.
Mapowanie schematu i typu danych
Zobacz Mapowanie schematu i typu danych, aby uzyskać informacje o tym, jak działanie Kopiuj mapuje dane źródłowe na ujście.
Dodawanie dodatkowych kolumn podczas kopiowania
Oprócz kopiowania danych ze źródłowego magazynu danych do ujścia można również skonfigurować dodawanie dodatkowych kolumn danych do kopiowania do ujścia. Na przykład:
- Podczas kopiowania ze źródła opartego na plikach zapisz względną ścieżkę pliku jako dodatkową kolumnę, aby śledzić, z którego pliku pochodzą dane.
- Zduplikuj określoną kolumnę źródłową jako inną kolumnę.
- Dodaj kolumnę z wyrażeniem usługi ADF, aby dołączyć zmienne systemowe usługi ADF, takie jak nazwa potoku/identyfikator potoku, lub zapisać inną wartość dynamiczną z danych wyjściowych działania nadrzędnego.
- Dodaj kolumnę ze statyczną wartością, aby zaspokoić potrzeby użycia podrzędnego.
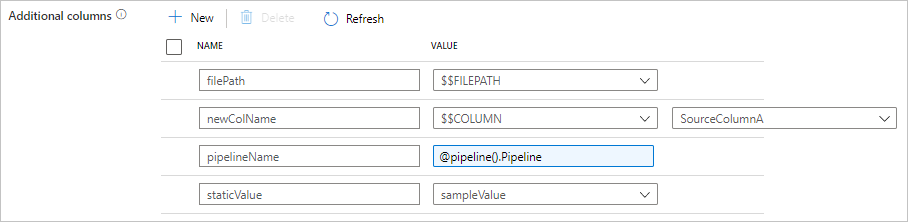
Poniższa konfiguracja znajduje się na karcie źródło działania kopiowania. Możesz również mapować te dodatkowe kolumny w mapowaniu schematu działania kopiowania jak zwykle przy użyciu zdefiniowanych nazw kolumn.
Napiwek
Ta funkcja działa z najnowszym modelem zestawu danych. Jeśli ta opcja nie jest widoczna w interfejsie użytkownika, spróbuj utworzyć nowy zestaw danych.
Aby skonfigurować ją programowo, dodaj additionalColumns właściwość w źródle działania kopiowania:
| Właściwości | Opis | Wymagania |
|---|---|---|
| additionalColumns | Dodaj dodatkowe kolumny danych, aby skopiować je do ujścia. Każdy obiekt w tablicy additionalColumns reprezentuje dodatkową kolumnę. Element name definiuje nazwę kolumny i value wskazuje wartość danych tej kolumny.Dozwolone wartości danych to: - $$FILEPATH — zmienna zarezerwowana wskazuje, aby przechowywać ścieżkę względną plików źródłowych do ścieżki folderu określonej w zestawie danych. Zastosuj do źródła opartego na plikach.- $$COLUMN:<source_column_name> — wzorzec zmiennej zarezerwowanej wskazuje, aby zduplikować określoną kolumnę źródłową jako inną kolumnę- Expression - Wartość statyczna |
Nie. |
Przykład:
"activities":[
{
"name": "CopyWithAdditionalColumns",
"type": "Copy",
"inputs": [...],
"outputs": [...],
"typeProperties": {
"source": {
"type": "<source type>",
"additionalColumns": [
{
"name": "filePath",
"value": "$$FILEPATH"
},
{
"name": "newColName",
"value": "$$COLUMN:SourceColumnA"
},
{
"name": "pipelineName",
"value": {
"value": "@pipeline().Pipeline",
"type": "Expression"
}
},
{
"name": "staticValue",
"value": "sampleValue"
}
],
...
},
"sink": {
"type": "<sink type>"
}
}
}
]
Napiwek
Po skonfigurowaniu dodatkowych kolumn pamiętaj, aby mapować je na ujście docelowe na karcie Mapowanie.
Automatyczne tworzenie tabel ujścia
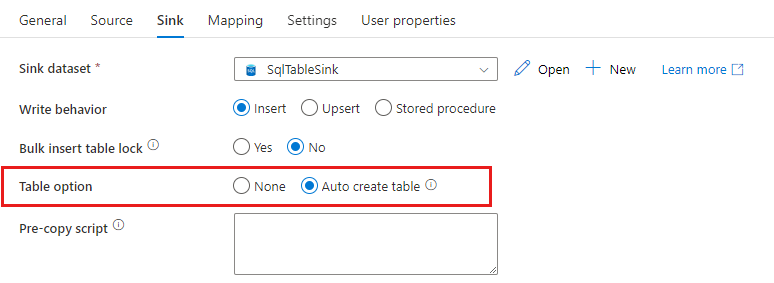
Podczas kopiowania danych do bazy danych SQL/usługi Azure Synapse Analytics, jeśli tabela docelowa nie istnieje, działanie kopiowania obsługuje automatyczne tworzenie ich na podstawie danych źródłowych. Ma ona na celu ułatwienie szybkiego rozpoczęcia ładowania danych i oceny bazy danych SQL/usługi Azure Synapse Analytics. Po pozyskaniu danych można przejrzeć i dostosować schemat tabeli ujścia zgodnie z potrzebami.
Ta funkcja jest obsługiwana podczas kopiowania danych z dowolnego źródła do następujących magazynów danych ujścia. Możesz znaleźć opcję w interfejsie użytkownika tworzenia usługi ADF ->działanie Kopiuj ujście -opcja Tabela ->>Automatycznie utwórz tabelę lub za pomocą tableOption właściwości w ładunku ujścia działania kopiowania.
Odporność na uszkodzenia
Domyślnie działanie Kopiuj zatrzymuje kopiowanie danych i zwraca błąd, gdy wiersze danych źródłowych są niezgodne z wierszami danych ujścia. Aby kopia powiodła się, można skonfigurować działanie Kopiuj, aby pominąć i zarejestrować niezgodne wiersze i skopiować tylko zgodne dane. Aby uzyskać szczegółowe informacje, zobacz działanie Kopiuj odporność na uszkodzenia.
Weryfikacja spójności danych
Podczas przenoszenia danych ze źródła do magazynu docelowego działanie kopiowania umożliwia przeprowadzenie dodatkowej weryfikacji spójności danych, aby upewnić się, że dane nie tylko zostały pomyślnie skopiowane ze źródła do magazynu docelowego, ale także zweryfikowane, aby były spójne między magazynem źródłowym i docelowym. Po znalezieniu niespójnych plików podczas przenoszenia danych można przerwać działanie kopiowania lub kontynuować kopiowanie reszty, włączając ustawienie odporności na uszkodzenia, aby pominąć niespójne pliki. Nazwy pominiętych plików można uzyskać, włączając ustawienie dziennika sesji w działaniu kopiowania. Aby uzyskać szczegółowe informacje, zobacz Weryfikacja spójności danych w działaniu kopiowania.
Dziennik sesji
Możesz rejestrować skopiowane nazwy plików, co może pomóc w dalszym zapewnieniu, że dane nie tylko zostały pomyślnie skopiowane ze źródła do magazynu docelowego, ale także spójne między magazynem źródłowym i docelowym, przeglądając dzienniki sesji kopiowania. Aby uzyskać szczegółowe informacje, zobacz Działanie kopiowania logowania do sesji.
Powiązana zawartość
Zobacz następujące przewodniki Szybki start, samouczki i przykłady: