Format ORC w usługach Azure Data Factory i Synapse Analytics
DOTYCZY:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
Postępuj zgodnie z tym artykułem, gdy chcesz przeanalizować pliki ORC lub zapisać dane w formacie ORC.
Format ORC jest obsługiwany dla następujących łączników: Amazon S3, Amazon S3 Compatible Storage, Azure Blob, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2, Azure Files, File System, FTP, Google Cloud Storage, HDFS, HTTP, Oracle Cloud Storage i SFTP.
Właściwości zestawu danych
Aby uzyskać pełną listę sekcji i właściwości dostępnych do definiowania zestawów danych, zobacz artykuł Zestawy danych. Ta sekcja zawiera listę właściwości obsługiwanych przez zestaw danych ORC.
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type zestawu danych musi być ustawiona na Orc. | Tak |
| lokalizacja | Ustawienia lokalizacji plików. Każdy łącznik oparty na plikach ma własny typ lokalizacji i obsługiwane właściwości w obszarze location. Zobacz szczegóły w artykule dotyczącym łącznika —> sekcja Właściwości zestawu danych. |
Tak |
| compressionCodec | Koder koder-dekoder kompresji używany podczas zapisywania w plikach ORC. Podczas odczytywania z plików ORC fabryki danych automatycznie określają koder-dekoder kompresji na podstawie metadanych pliku. Obsługiwane typy to brak, zlib, snappy (wartość domyślna) i lzo. Uwaga obecnie działanie Kopiuj nie obsługuje LZO podczas odczytu/zapisu plików ORC. |
Nie. |
Poniżej przedstawiono przykład zestawu danych ORC w usłudze Azure Blob Storage:
{
"name": "OrcDataset",
"properties": {
"type": "Orc",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"container": "containername",
"folderPath": "folder/subfolder",
}
}
}
}
Należy uwzględnić następujące informacje:
- Złożone typy danych (np. MAP, LIST, STRUCT) są obecnie obsługiwane tylko w Przepływ danych, a nie w działaniu kopiowania. Aby używać złożonych typów w przepływach danych, nie importuj schematu pliku w zestawie danych, pozostawiając schemat pusty w zestawie danych. Następnie w transformacji Źródło zaimportuj projekcję.
- Białe znaki w nazwie kolumny nie są obsługiwane.
Właściwości działania kopiowania
Aby uzyskać pełną listę sekcji i właściwości dostępnych do definiowania działań, zobacz artykuł Pipelines (Potoki ). Ta sekcja zawiera listę właściwości obsługiwanych przez źródło i ujście ORC.
ORC jako źródło
Następujące właściwości są obsługiwane w sekcji działanie kopiowania *źródło* .
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type źródła działania kopiowania musi być ustawiona na OrcSource. | Tak |
| storeSettings | Grupa właściwości dotyczących odczytywania danych z magazynu danych. Każdy łącznik oparty na plikach ma własne obsługiwane ustawienia odczytu w obszarze storeSettings. Zobacz szczegóły w artykule dotyczącym łącznika —> sekcja właściwości działanie Kopiuj. |
Nie. |
ORC jako ujście
Następujące właściwości są obsługiwane w sekcji działanie kopiowania *ujście*.
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type ujścia działania kopiowania musi być ustawiona na OrcSink. | Tak |
| formatUstawienia | Grupa właściwości. Zapoznaj się z poniższą tabelą ustawień zapisu ORC. | Nie. |
| storeSettings | Grupa właściwości dotyczących sposobu zapisywania danych w magazynie danych. Każdy łącznik oparty na plikach ma własne obsługiwane ustawienia zapisu w obszarze storeSettings. Zobacz szczegóły w artykule dotyczącym łącznika —> sekcja właściwości działanie Kopiuj. |
Nie. |
Obsługiwane ustawienia zapisu ORC w obszarze formatSettings:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Typ formatUstawienia musi być ustawiony na OrcWriteSettings. | Tak |
| maxRowsPerFile | Podczas zapisywania danych w folderze można wybrać zapisywanie w wielu plikach i określić maksymalną liczbę wierszy na plik. | Nie. |
| fileNamePrefix | Dotyczy konfiguracji maxRowsPerFile .Określ prefiks nazwy pliku podczas zapisywania danych w wielu plikach, co spowodowało następujący wzorzec: <fileNamePrefix>_00000.<fileExtension>. Jeśli nie zostanie określony, prefiks nazwy pliku zostanie wygenerowany automatycznie. Ta właściwość nie ma zastosowania, gdy źródło jest magazynem opartym na plikach lub magazynem danych z włączoną opcją partycji. |
Nie. |
Właściwości przepływu mapowania danych
W przepływach mapowania danych można odczytywać i zapisywać w formacie ORC w następujących magazynach danych: Azure Blob Storage, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2 i SFTP, a format ORC można odczytać w usłudze Amazon S3.
Możesz wskazać pliki ORC przy użyciu zestawu danych ORC lub wbudowanego zestawu danych.
Właściwości źródła
W poniższej tabeli wymieniono właściwości obsługiwane przez źródło ORC. Te właściwości można edytować na karcie Opcje źródła.
W przypadku korzystania z wbudowanego zestawu danych zostaną wyświetlone dodatkowe ustawienia pliku, które są takie same jak właściwości opisane w sekcji właściwości zestawu danych.
| Nazwa/nazwisko | opis | Wymagania | Dozwolone wartości | Właściwość skryptu przepływu danych |
|---|---|---|---|---|
| Formatuj | Format musi być następujący: orc |
tak | orc |
format |
| Ścieżki z symbolami wieloznacznymi | Wszystkie pliki pasujące do ścieżki wieloznacznej zostaną przetworzone. Zastępuje folder i ścieżkę pliku ustawioną w zestawie danych. | nie | Ciąg[] | symbole wieloznacznePaths |
| Ścieżka główna partycji | W przypadku danych plików podzielonych na partycje można wprowadzić ścieżkę katalogu głównego partycji, aby odczytywać foldery podzielone na partycje jako kolumny | nie | String | partitionRootPath |
| Lista plików | Czy źródło wskazuje plik tekstowy, który wyświetla listę plików do przetworzenia | nie | true lub false |
fileList |
| Kolumna do przechowywania nazwy pliku | Utwórz nową kolumnę z nazwą pliku źródłowego i ścieżką | nie | String | rowUrlColumn |
| Po zakończeniu | Usuń lub przenieś pliki po przetworzeniu. Ścieżka pliku rozpoczyna się od katalogu głównego kontenera | nie | Usuń: true lub false Ruszać: [<from>, <to>] |
przeczyszczanie plików moveFiles |
| Filtruj według ostatniej modyfikacji | Wybierz filtrowanie plików w oparciu o czas ich ostatniej zmiany | nie | Sygnatura czasowa | modifiedAfter modifiedBefore |
| Zezwalaj na brak znalezionych plików | Jeśli wartość true, błąd nie jest zgłaszany, jeśli nie znaleziono żadnych plików | nie | true lub false |
ignoreNoFilesFound |
Przykład źródła
Skojarzony skrypt przepływu danych konfiguracji źródła ORC to:
source(allowSchemaDrift: true,
validateSchema: false,
rowUrlColumn: 'fileName',
format: 'orc') ~> OrcSource
Właściwości ujścia
W poniższej tabeli wymieniono właściwości obsługiwane przez ujście ORC. Te właściwości można edytować na karcie Ustawienia .
W przypadku korzystania z wbudowanego zestawu danych zostaną wyświetlone dodatkowe ustawienia pliku, które są takie same jak właściwości opisane w sekcji właściwości zestawu danych.
| Nazwa/nazwisko | opis | Wymagania | Dozwolone wartości | Właściwość skryptu przepływu danych |
|---|---|---|---|---|
| Formatuj | Format musi być następujący: orc |
tak | orc |
format |
| Wyczyść folder | Jeśli folder docelowy zostanie wyczyszczone przed zapisem | nie | true lub false |
truncate |
| Opcja Nazwa pliku | Format nazewnictwa zapisanych danych. Domyślnie jeden plik na partycję w formacie part-#####-tid-<guid> |
nie | Wzorzec: ciąg Na partycję: Ciąg[] Jako dane w kolumnie: Ciąg Dane wyjściowe do pojedynczego pliku: ['<fileName>'] |
filePattern partitionFileNames rowUrlColumn partitionFileNames |
Przykład ujścia
Skojarzony skrypt przepływu danych konfiguracji ujścia ORC to:
OrcSource sink(
format: 'orc',
filePattern:'output[n].orc',
truncate: true,
allowSchemaDrift: true,
validateSchema: false,
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> OrcSink
Korzystanie z własnego środowiska Integration Runtime
Ważne
W przypadku kopiowania z uprawnieniami własnego środowiska Integration Runtime, np. między lokalnymi i w chmurze magazynami danych, jeśli nie kopiujesz plików ORC w taki sposób, musisz zainstalować 64-bitowe środowisko JRE 8 (Środowisko uruchomieniowe Java) lub Pakiet Redystrybucyjny Microsoft Visual C++ 2010 na maszynie ir. Zapoznaj się z poniższym akapitem, aby uzyskać więcej szczegółów.
W przypadku kopiowania działającego na własnym środowisku IR z serializacji/deserializacji plików ORC usługa lokalizuje środowisko uruchomieniowe Języka Java, sprawdzając najpierw rejestr (SOFTWARE\JavaSoft\Java Runtime Environment\{Current Version}\JavaHome) środowiska JRE, jeśli nie zostanie znaleziony, po drugie sprawdzając zmienną systemową JAVA_HOME dla zestawu OpenJDK.
- Aby użyć środowiska JRE: 64-bitowe środowisko IR wymaga 64-bitowego środowiska JRE. Możesz go znaleźć tutaj.
- Aby użyć zestawu OpenJDK: jest obsługiwany od czasu środowiska IR w wersji 3.13. Spakuj jvm.dll ze wszystkimi innymi wymaganymi zestawami zestawu OpenJDK na maszynę własnego środowiska IR i odpowiednio ustaw zmienną środowiskową systemu JAVA_HOME.
- Aby zainstalować pakiet redystrybucyjny Visual C++ 2010: Pakiet redystrybucyjny Visual C++ 2010 nie jest zainstalowany z instalacjami własnego środowiska IR. Możesz go znaleźć tutaj.
Napiwek
Jeśli skopiujesz dane do/z formatu ORC przy użyciu własnego środowiska Integration Runtime i wystąpi błąd informujący o błędzie "Wystąpił błąd podczas wywoływania języka Java, komunikat: java.lang.OutOfMemoryError: Przestrzeń sterty Java", możesz dodać zmienną środowiskową _JAVA_OPTIONS na maszynie, która hostuje własne środowisko IR, aby dostosować minimalny/maksymalny rozmiar sterty dla maszyny wirtualnej JVM w celu wzmocnienia takiej możliwości kopiowania, a następnie ponownie uruchomić potok.
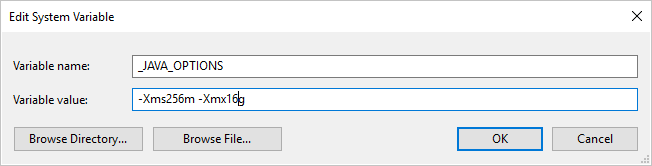
Przykład: ustaw zmienną _JAVA_OPTIONS z wartością -Xms256m -Xmx16g. Flaga Xms określa początkową pulę alokacji pamięci dla maszyny wirtualnej Java (JVM), podczas gdy Xmx określa maksymalną pulę alokacji pamięci. Oznacza to, że maszyny JVM zostaną uruchomione z ilością Xms pamięci i będą mogły korzystać z maksymalnej Xmx ilości pamięci. Domyślnie usługa używa min 64 MB i maksymalnej liczby 1G.