Kopiowanie danych z bazy danych PostgreSQL przy użyciu usługi Azure Data Factory lub Synapse Analytics
DOTYCZY: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
W tym artykule opisano sposób używania działania kopiowania w potokach usługi Azure Data Factory i usługi Synapse Analytics do kopiowania danych z bazy danych PostgreSQL. Jest on oparty na artykule omówienie działania kopiowania, który przedstawia ogólne omówienie działania kopiowania.
Ważne
Łącznik PostgreSQL w wersji 2 zapewnia ulepszoną natywną obsługę bazy danych PostgreSQL. Jeśli używasz łącznika PostgreSQL W wersji 1 w rozwiązaniu, uaktualnij łącznik PostgreSQL, ponieważ wersja 1 znajduje się na etapie zakończenia pomocy technicznej. Zapoznaj się z tą sekcją , aby uzyskać szczegółowe informacje na temat różnic między wersjami V2 i V1.
Obsługiwane możliwości
Ten łącznik PostgreSQL jest obsługiwany w następujących funkcjach:
| Obsługiwane możliwości | IR |
|---|---|
| działanie Kopiuj (źródło/-) | (1) (2) |
| Działanie Lookup | (1) (2) |
(1) Środowisko Azure Integration Runtime (2) Self-hosted Integration Runtime
Aby uzyskać listę magazynów danych obsługiwanych jako źródła/ujścia przez działanie kopiowania, zobacz tabelę Obsługiwane magazyny danych.
W szczególności ten łącznik PostgreSQL obsługuje program PostgreSQL w wersji 12 lub nowszej.
Wymagania wstępne
Jeśli magazyn danych znajduje się wewnątrz sieci lokalnej, sieci wirtualnej platformy Azure lub chmury prywatnej Amazon Virtual, musisz skonfigurować własne środowisko Integration Runtime , aby się z nim połączyć.
Jeśli magazyn danych jest zarządzaną usługą danych w chmurze, możesz użyć środowiska Azure Integration Runtime. Jeśli dostęp jest ograniczony do adresów IP zatwierdzonych w regułach zapory, możesz dodać adresy IP środowiska Azure Integration Runtime do listy dozwolonych.
Możesz również użyć funkcji środowiska Integration Runtime zarządzanej sieci wirtualnej w usłudze Azure Data Factory, aby uzyskać dostęp do sieci lokalnej bez instalowania i konfigurowania własnego środowiska Integration Runtime.
Aby uzyskać więcej informacji na temat mechanizmów zabezpieczeń sieci i opcji obsługiwanych przez usługę Data Factory, zobacz Strategie dostępu do danych.
Środowisko Integration Runtime udostępnia wbudowany sterownik PostgreSQL, począwszy od wersji 3.7, dlatego nie trzeba ręcznie instalować żadnego sterownika.
Wprowadzenie
Aby wykonać działanie Kopiuj za pomocą potoku, możesz użyć jednego z następujących narzędzi lub zestawów SDK:
- Narzędzie do kopiowania danych
- Witryna Azure Portal
- Zestaw SDK platformy .NET
- Zestaw SDK języka Python
- Azure PowerShell
- Interfejs API REST
- Szablon usługi Azure Resource Manager
Tworzenie połączonej usługi z bazą danych PostgreSQL przy użyciu interfejsu użytkownika
Wykonaj poniższe kroki, aby utworzyć połączoną usługę z bazą danych PostgreSQL w interfejsie użytkownika witryny Azure Portal.
Przejdź do karty Zarządzanie w obszarze roboczym usługi Azure Data Factory lub Synapse i wybierz pozycję Połączone usługi, a następnie kliknij pozycję Nowy:
Wyszukaj pozycję Postgre i wybierz łącznik PostgreSQL.
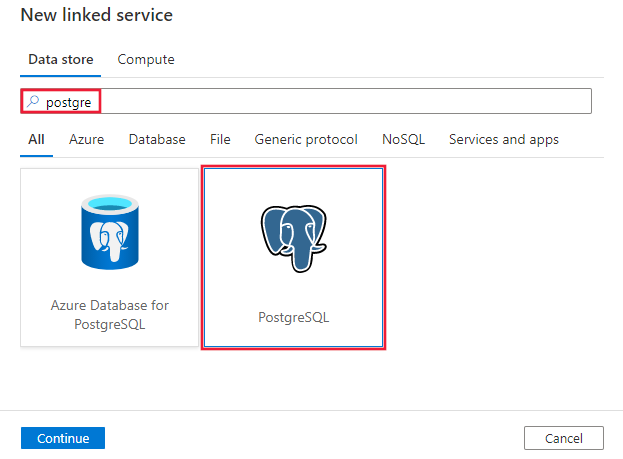
Skonfiguruj szczegóły usługi, przetestuj połączenie i utwórz nową połączoną usługę.
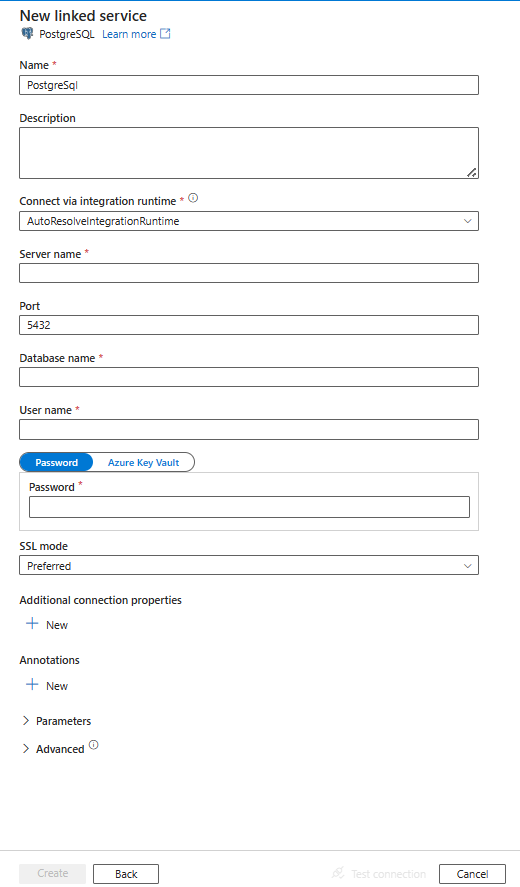
Szczegóły konfiguracji łącznika
Poniższe sekcje zawierają szczegółowe informacje o właściwościach używanych do definiowania jednostek usługi Data Factory specyficznych dla łącznika PostgreSQL.
Właściwości połączonej usługi
Następujące właściwości są obsługiwane w przypadku połączonej usługi PostgreSQL:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type musi być ustawiona na: PostgreSqlV2 | Tak |
| serwer | Określa nazwę hosta — i opcjonalnie port — na którym działa program PostgreSQL. | Tak |
| port | Port TCP serwera PostgreSQL. | Nie. |
| database | Baza danych PostgreSQL do nawiązania połączenia. | Tak |
| nazwa użytkownika | Nazwa użytkownika do nawiązania połączenia. Nie jest wymagane w przypadku używania funkcji IntegratedSecurity. | Tak |
| hasło | Hasło do nawiązania połączenia. Nie jest wymagane w przypadku używania funkcji IntegratedSecurity. | Tak |
| sslMode | Określa, czy protokół SSL jest używany, w zależności od obsługi serwera. - Wyłącz: protokół SSL jest wyłączony. Jeśli serwer wymaga protokołu SSL, połączenie zakończy się niepowodzeniem. - Zezwalaj: preferuj połączenia inne niż SSL, jeśli zezwala na nie serwer, ale zezwalaj na połączenia SSL. - Preferuj: Preferuj połączenia SSL, jeśli serwer zezwala na nie, ale zezwalaj na połączenia bez protokołu SSL. - Wymagaj: Nie można nawiązać połączenia, jeśli serwer nie obsługuje protokołu SSL. - Verify-ca: Nie można nawiązać połączenia, jeśli serwer nie obsługuje protokołu SSL. Sprawdza również certyfikat serwera. - Weryfikacja pełna: Nie można nawiązać połączenia, jeśli serwer nie obsługuje protokołu SSL. Sprawdza również certyfikat serwera z nazwą hosta. Opcje: Wyłącz (0) / Zezwalaj (1) / Preferuj (2) (ustawienie domyślne) / Wymagaj (3) / Verify-ca (4) / Verify-full (5) |
Nie. |
| authenticationType | Typ uwierzytelniania na potrzeby nawiązywania połączenia z bazą danych. Obsługuje tylko warstwę Podstawowa. | Tak |
| connectVia | Środowisko Integration Runtime do nawiązania połączenia z magazynem danych. Dowiedz się więcej w sekcji Wymagania wstępne . Jeśli nie zostanie określony, używa domyślnego środowiska Azure Integration Runtime. | Nie. |
| Dodatkowe właściwości połączenia: | ||
| schema | Ustawia ścieżkę wyszukiwania schematu. | Nie. |
| Buforowanie | Czy należy używać buforowania połączeń. | Nie. |
| connectionTimeout | Czas oczekiwania (w sekundach) podczas próby nawiązania połączenia przed zakończeniem próby i wygenerowaniem błędu. | Nie. |
| commandTimeout | Czas oczekiwania (w sekundach) podczas próby wykonania polecenia przed zakończeniem próby i wygenerowaniem błędu. Ustaw wartość zero dla nieskończoności. | Nie. |
| trustServerCertificate | Czy ufać certyfikatowi serwera bez sprawdzania jego poprawności. | Nie. |
| sslCertificate | Lokalizacja certyfikatu klienta do wysłania na serwer. | Nie. |
| sslKey | Lokalizacja klucza klienta certyfikatu klienta, który ma zostać wysłany do serwera. | Nie. |
| sslPassword | Hasło klucza certyfikatu klienta. | Nie. |
| readBufferSize | Określa rozmiar wewnętrznego buforu Npgsql używany podczas odczytywania. Zwiększenie wydajności może zwiększyć wydajność w przypadku transferu dużych wartości z bazy danych. | Nie. |
| logParameters | Po włączeniu wartości parametrów są rejestrowane po wykonaniu poleceń. | Nie. |
| timezone | Pobiera lub ustawia strefę czasową sesji. | Nie. |
| encoding | Pobiera lub ustawia kodowanie .NET, które będzie używane do kodowania/dekodowania danych ciągu PostgreSQL. | Nie. |
Uwaga
Aby mieć pełną weryfikację SSL za pośrednictwem połączenia ODBC w przypadku korzystania z własnego środowiska Integration Runtime, należy jawnie użyć połączenia typu ODBC zamiast łącznika PostgreSQL i ukończyć następującą konfigurację:
- Skonfiguruj nazwę DSN na dowolnych serwerach SHIR.
- Umieść odpowiedni certyfikat dla bazy danych PostgreSQL w folderze C:\Windows\ServiceProfiles\DIAHostService\AppData\Roaming\postgresql\root.crt na serwerach SHIR. W tym miejscu sterownik ODBC szuka > certyfikatu SSL, aby sprawdzić, kiedy nawiązuje połączenie z bazą danych.
- W połączeniu z fabryką danych użyj połączenia typu ODBC z parametry połączenia wskazującą nazwę DSN utworzoną na serwerach SHIR.
Przykład:
{
"name": "PostgreSqlLinkedService",
"properties": {
"type": "PostgreSqlV2",
"typeProperties": {
"server": "<server>",
"port": 5432,
"database": "<database>",
"username": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
},
"sslmode": <sslmode>,
"authenticationType": "Basic"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Przykład: przechowywanie hasła w usłudze Azure Key Vault
{
"name": "PostgreSqlLinkedService",
"properties": {
"type": "PostgreSqlV2",
"typeProperties": {
"server": "<server>",
"port": 5432,
"database": "<database>",
"username": "<username>",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
"sslmode": <sslmode>,
"authenticationType": "Basic"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Właściwości zestawu danych
Pełna lista sekcji i właściwości dostępnych do definiowania zestawów danych znajduje się w artykule dotyczącym zestawów danych. Ta sekcja zawiera listę właściwości obsługiwanych przez zestaw danych PostgreSQL.
Aby skopiować dane z bazy danych PostgreSQL, obsługiwane są następujące właściwości:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type zestawu danych musi być ustawiona na: PostgreSqlV2Table | Tak |
| schema | Nazwa schematu. | Nie (jeśli określono "zapytanie" w źródle działania) |
| table | Nazwa tabeli. | Nie (jeśli określono "zapytanie" w źródle działania) |
Przykład
{
"name": "PostgreSQLDataset",
"properties":
{
"type": "PostgreSqlV2Table",
"linkedServiceName": {
"referenceName": "<PostgreSQL linked service name>",
"type": "LinkedServiceReference"
},
"annotations": [],
"schema": [],
"typeProperties": {
"schema": "<schema name>",
"table": "<table name>"
}
}
}
Jeśli używasz RelationalTable wpisanego zestawu danych, nadal jest on obsługiwany w miarę działania, chociaż zaleca się użycie nowego zestawu danych w przyszłości.
Właściwości działania kopiowania
Aby uzyskać pełną listę sekcji i właściwości dostępnych do definiowania działań, zobacz artykuł Pipelines (Potoki ). Ta sekcja zawiera listę właściwości obsługiwanych przez źródło postgreSQL.
PostgreSQL jako źródło
Aby skopiować dane z bazy danych PostgreSQL, w sekcji źródła działania kopiowania są obsługiwane następujące właściwości:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type źródła działania kopiowania musi być ustawiona na: PostgreSqlV2Source | Tak |
| zapytanie | Użyj niestandardowego zapytania SQL, aby odczytać dane. Na przykład: "query": "SELECT * FROM \"MySchema\".\"MyTable\"". |
Nie (jeśli określono "tableName" w zestawie danych) |
| queryTimeout | Czas oczekiwania przed zakończeniem próby wykonania polecenia i wygenerowaniem błędu wartość domyślna to 120 minut. Jeśli parametr jest ustawiony dla tej właściwości, dozwolone wartości są przedziałem czasu, takim jak "02:00:00" (120 minut). Aby uzyskać więcej informacji, zobacz CommandTimeout. Jeśli obie commandTimeout opcje i queryTimeout są skonfigurowane, queryTimeout pierwszeństwo ma. |
Nie. |
Uwaga
W nazwach schematów i tabel uwzględniana jest wielkość liter. Umieszczaj je w "" cudzysłowie (cudzysłowy) w zapytaniu.
Przykład:
"activities":[
{
"name": "CopyFromPostgreSQL",
"type": "Copy",
"inputs": [
{
"referenceName": "<PostgreSQL input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "PostgreSqlV2Source",
"query": "SELECT * FROM \"MySchema\".\"MyTable\"",
"queryTimeout": "00:10:00"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Jeśli używasz RelationalSource wpisanego źródła, nadal jest obsługiwana w taki sposób, jak jest, podczas gdy sugerowane jest użycie nowego źródła w przyszłości.
Mapowanie typów danych dla bazy danych PostgreSQL
Podczas kopiowania danych z bazy danych PostgreSQL następujące mapowania są używane z typów danych PostgreSQL do tymczasowych typów danych używanych wewnętrznie przez usługę. Zobacz Mapowania schematu i typu danych, aby dowiedzieć się, jak działanie kopiowania mapuje schemat źródłowy i typ danych na ujście.
| Typ danych PostgreSql | Typ danych usługi tymczasowej | Typ danych usługi tymczasowej dla bazy danych PostgreSQL (starsza wersja) |
|---|---|---|
SmallInt |
Int16 |
Int16 |
Integer |
Int32 |
Int32 |
BigInt |
Int64 |
Int64 |
Decimal (Precyzja <= 28) |
Decimal |
Decimal |
Decimal (Precyzja > 28) |
Nieobsługiwane | String |
Numeric |
Decimal |
Decimal |
Real |
Single |
Single |
Double |
Double |
Double |
SmallSerial |
Int16 |
Int16 |
Serial |
Int32 |
Int32 |
BigSerial |
Int64 |
Int64 |
Money |
Decimal |
String |
Char |
String |
String |
Varchar |
String |
String |
Text |
String |
String |
Bytea |
Byte[] |
Byte[] |
Timestamp |
DateTime |
DateTime |
Timestamp with time zone |
DateTime |
String |
Date |
DateTime |
DateTime |
Time |
TimeSpan |
TimeSpan |
Time with time zone |
DateTimeOffset |
String |
Interval |
TimeSpan |
String |
Boolean |
Boolean |
Boolean |
Point |
String |
String |
Line |
String |
String |
Iseg |
String |
String |
Box |
String |
String |
Path |
String |
String |
Polygon |
String |
String |
Circle |
String |
String |
Cidr |
String |
String |
Inet |
String |
String |
Macaddr |
String |
String |
Macaddr8 |
String |
String |
Tsvector |
String |
String |
Tsquery |
String |
String |
UUID |
Guid |
Guid |
Json |
String |
String |
Jsonb |
String |
String |
Array |
String |
String |
Bit |
Byte[] |
Byte[] |
Bit varying |
Byte[] |
Byte[] |
XML |
String |
String |
IntArray |
String |
String |
TextArray |
String |
String |
NumericArray |
String |
String |
DateArray |
String |
String |
Range |
String |
String |
Bpchar |
String |
String |
Właściwości działania wyszukiwania
Aby dowiedzieć się więcej o właściwościach, sprawdź działanie Wyszukiwania.
Uaktualnianie łącznika PostgreSQL
Poniżej przedstawiono kroki ułatwiające uaktualnienie łącznika PostgreSQL:
Utwórz nową połączoną usługę PostgreSQL i skonfiguruj ją, odwołując się do właściwości połączonej usługi.
Mapowanie typu danych dla najnowszej połączonej usługi PostgreSQL różni się od tej dla starszej wersji. Aby poznać najnowsze mapowanie typów danych, zobacz Mapowanie typów danych dla bazy danych PostgreSQL.
Różnice między bazami danych PostgreSQL i PostgreSQL (starsza wersja)
W poniższej tabeli przedstawiono różnice mapowania typów danych między bazami danych PostgreSQL i PostgreSQL (starsza wersja).
| Typ danych PostgreSQL | Typ danych usługi tymczasowej dla bazy danych PostgreSQL | Typ danych usługi tymczasowej dla bazy danych PostgreSQL (starsza wersja) |
|---|---|---|
| Money | Dziesiętne | String |
| Sygnatura czasowa ze strefą czasową | DateTime | String |
| Czas ze strefą czasową | DateTimeOffset | String |
| Interwał | przedział_czasu | String |
| BigDecimal | Nieobsługiwane. Alternatywnie możesz użyć to_char() funkcji, aby przekonwertować bigdecimal na ciąg. |
String |
Powiązana zawartość
Aby uzyskać listę magazynów danych obsługiwanych jako źródła i ujścia działania kopiowania, zobacz obsługiwane magazyny danych.