Kopiowanie danych z i do bazy danych Oracle przy użyciu usługi Azure Data Factory lub Azure Synapse Analytics
DOTYCZY: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
W tym artykule opisano sposób używania działania kopiowania w usłudze Azure Data Factory do kopiowania danych z i do bazy danych Oracle. Jest on oparty na omówieniu działania kopiowania.
Obsługiwane możliwości
Ten łącznik Oracle jest obsługiwany w przypadku następujących możliwości:
| Obsługiwane możliwości | IR |
|---|---|
| działanie Kopiuj (źródło/ujście) | (1) (2) |
| Działanie Lookup | (1) (2) |
| Działanie skryptu | (1) (2) |
(1) Środowisko Azure Integration Runtime (2) Self-hosted Integration Runtime
Aby uzyskać listę magazynów danych obsługiwanych jako źródła lub ujścia przez działanie kopiowania, zobacz tabelę Obsługiwane magazyny danych.
W szczególności ten łącznik Oracle obsługuje następujące funkcje:
- Następujące wersje bazy danych Oracle:
- Oracle 19c R1 (19.1) i nowsze
- Oracle 18c R1 (18.1) i nowsze
- Oracle 12c R1 (12.1) i nowsze
- Oracle 11g R1 (11.1) i nowsze
- Oracle 10g R1 (10.1) i nowsze
- Oracle 9i R2 (9.2) i nowsze
- Oracle 8i R3 (8.1.7) i nowsze
- Usługa Oracle Database Cloud Exadata
- Równoległe kopiowanie ze źródła Oracle. Aby uzyskać szczegółowe informacje, zobacz sekcję Równoległa kopia z bazy danych Oracle .
Uwaga
Serwer proxy Oracle nie jest obsługiwany.
Wymagania wstępne
Jeśli magazyn danych znajduje się wewnątrz sieci lokalnej, sieci wirtualnej platformy Azure lub chmury prywatnej Amazon Virtual, musisz skonfigurować własne środowisko Integration Runtime , aby się z nim połączyć.
Jeśli magazyn danych jest zarządzaną usługą danych w chmurze, możesz użyć środowiska Azure Integration Runtime. Jeśli dostęp jest ograniczony do adresów IP zatwierdzonych w regułach zapory, możesz dodać adresy IP środowiska Azure Integration Runtime do listy dozwolonych.
Możesz również użyć funkcji środowiska Integration Runtime zarządzanej sieci wirtualnej w usłudze Azure Data Factory, aby uzyskać dostęp do sieci lokalnej bez instalowania i konfigurowania własnego środowiska Integration Runtime.
Aby uzyskać więcej informacji na temat mechanizmów zabezpieczeń sieci i opcji obsługiwanych przez usługę Data Factory, zobacz Strategie dostępu do danych.
Środowisko Integration Runtime udostępnia wbudowany sterownik Oracle. W związku z tym nie trzeba ręcznie instalować sterownika podczas kopiowania danych z i do oracle.
Rozpocznij
Aby wykonać działanie Kopiuj za pomocą potoku, możesz użyć jednego z następujących narzędzi lub zestawów SDK:
- Narzędzie do kopiowania danych
- Witryna Azure Portal
- Zestaw SDK platformy .NET
- Zestaw SDK języka Python
- Azure PowerShell
- Interfejs API REST
- Szablon usługi Azure Resource Manager
Tworzenie połączonej usługi z bazą danych Oracle przy użyciu interfejsu użytkownika
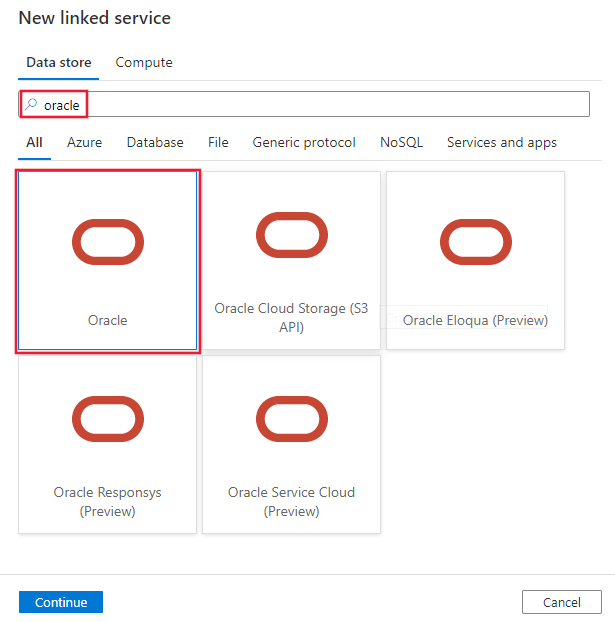
Wykonaj poniższe kroki, aby utworzyć połączoną usługę z bazą danych Oracle w interfejsie użytkownika witryny Azure Portal.
Przejdź do karty Zarządzanie w obszarze roboczym usługi Azure Data Factory lub Synapse i wybierz pozycję Połączone usługi, a następnie kliknij pozycję Nowy:
Wyszukaj pozycję Oracle i wybierz łącznik Oracle.
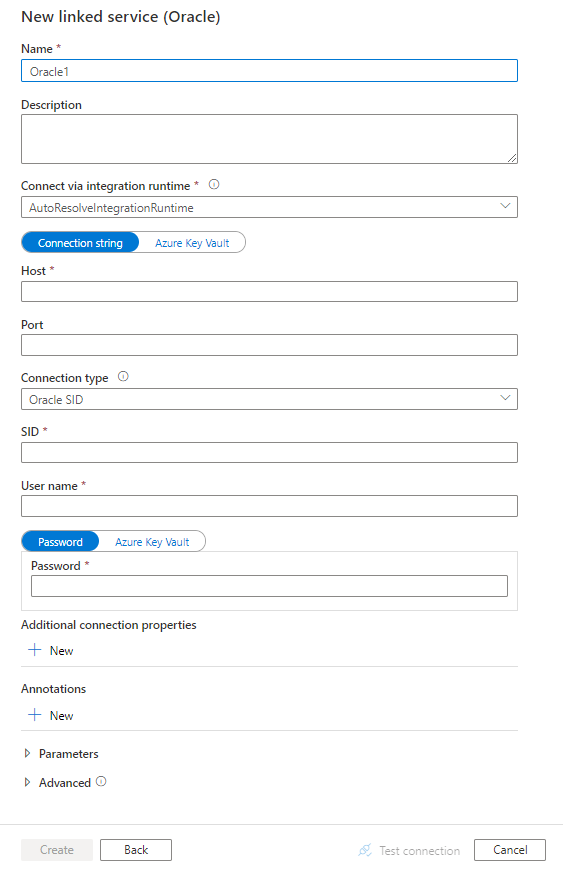
Skonfiguruj szczegóły usługi, przetestuj połączenie i utwórz nową połączoną usługę.
Szczegóły konfiguracji łącznika
Poniższe sekcje zawierają szczegółowe informacje o właściwościach używanych do definiowania jednostek specyficznych dla łącznika Oracle.
Właściwości połączonej usługi
Połączona usługa Oracle obsługuje następujące właściwości:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type musi być ustawiona na Oracle. | Tak |
| Parametry połączenia | Określa informacje potrzebne do nawiązania połączenia z wystąpieniem bazy danych Oracle. Możesz również umieścić hasło w usłudze Azure Key Vault i ściągnąć password konfigurację z parametry połączenia. Aby uzyskać więcej informacji, zapoznaj się z poniższymi przykładami i zapisz poświadczenia w usłudze Azure Key Vault . Obsługiwany typ połączenia: aby zidentyfikować bazę danych, możesz użyć identyfikatora SID oracle lub nazwy usługi Oracle: - Jeśli używasz identyfikatora SID: Host=<host>;Port=<port>;Sid=<sid>;User Id=<username>;Password=<password>;— Jeśli używasz nazwy usługi: Host=<host>;Port=<port>;ServiceName=<servicename>;User Id=<username>;Password=<password>;W przypadku zaawansowanych opcji połączenia natywnego Oracle można dodać wpis w TNSNAMES. Plik ORA na maszynie, na której zainstalowano własne środowisko Integration Runtime, a w połączonej usłudze Oracle wybierz opcję użycia typu połączenia Nazwa usługi Oracle i skonfiguruj odpowiednią nazwę usługi. |
Tak |
| connectVia | Środowisko Integration Runtime do nawiązania połączenia z magazynem danych. Dowiedz się więcej w sekcji Wymagania wstępne . Jeśli nie zostanie określony, zostanie użyte domyślne środowisko Azure Integration Runtime. | Nie. |
Napiwek
Jeśli wystąpi błąd "ORA-01025: parametr UPI poza zakresem", a wersja oracle to 8i, dodaj WireProtocolMode=1 do parametry połączenia. Następnie spróbuj ponownie.
Jeśli masz wiele wystąpień Oracle dla scenariusza trybu failover, możesz utworzyć połączoną usługę Oracle i wypełnić hosta podstawowego, port, nazwę użytkownika, hasło itp., a następnie dodać nowe "Dodatkowe właściwości połączenia" z nazwą właściwości i AlternateServers wartością jako (HostName=<secondary host>:PortNumber=<secondary port>:ServiceName=<secondary service name>) — nie pomijaj nawiasów i zwracaj uwagę na dwukropki (:) jako separator. Na przykład następująca wartość alternatywnych serwerów definiuje dwa alternatywne serwery bazy danych na potrzeby trybu failover połączenia: (HostName=AccountingOracleServer:PortNumber=1521:SID=Accounting,HostName=255.201.11.24:PortNumber=1522:ServiceName=ABackup.NA.MyCompany).
Więcej właściwości połączenia, które można ustawić w parametry połączenia w zależności od przypadku:
| Właściwości | opis | Dozwolone wartości |
|---|---|---|
| ArraySize | Liczba bajtów, które łącznik może pobrać w ramach jednej rundy sieciowej. Np. ArraySize=10485760.Większe wartości zwiększają przepływność, zmniejszając liczbę prób pobierania danych w sieci. Mniejsze wartości zwiększają czas odpowiedzi, ponieważ istnieje mniejsze opóźnienie oczekiwania na przesyłanie danych przez serwer. |
Liczba całkowita z zakresu od 1 do 4294967296 (4 GB). Wartość domyślna to 60000. Wartość 1 nie definiuje liczby bajtów, ale wskazuje przydzielanie miejsca dla dokładnie jednego wiersza danych. |
Aby włączyć szyfrowanie w połączeniu Oracle, dostępne są dwie opcje:
Aby używać szyfrowania Triple-DES (3DES) i Advanced Encryption Standard (AES), po stronie serwera Oracle przejdź do obszaru Oracle Advanced Security (OAS) i skonfiguruj ustawienia szyfrowania. Aby uzyskać szczegółowe informacje, zobacz tę dokumentację oracle. Łącznik Oracle Application Development Framework (ADF) automatycznie negocjuje metodę szyfrowania w celu użycia tej, którą konfigurujesz w systemie operacyjnym podczas nawiązywania połączenia z oracle.
Aby użyć protokołu TLS, skonfiguruj na
truststorepotrzeby uwierzytelniania serwera SSL, stosując jedną z następujących trzech metod:Metoda 1 (zalecana):
Zainstaluj certyfikat TLS/SSL, importując go do lokalnego magazynu certyfikatów. Wbudowany sterownik Oracle może załadować wymagany certyfikat z magazynu certyfikatów.
W usłudze skonfiguruj parametry połączenia Oracle za pomocą polecenia
EncryptionMethod=1.
Metoda 2:
Uzyskaj informacje o certyfikacie TLS/SSL. Uzyskaj informacje o certyfikatach zakodowanych w standardzie DER (Distinguished Encoding Rules) lub Privacy Enhanced Mail (PEM) zakodowanych w protokole TLS/SSL.
openssl x509 -inform (DER|PEM) -in [Full Path to the DER/PEM Certificate including the name of the DER/PEM Certificate] -textW usłudze skonfiguruj parametry połączenia Oracle i
EncryptionMethod=1odpowiedniąTrustStorewartość. Na przykładHost=<host>;Port=<port>;Sid=<sid>;User Id=<username>;Password=<password>;EncryptionMethod=1;TrustStore= data:// -----BEGIN CERTIFICATE-----<certificate content>-----END CERTIFICATE-----Uwaga
- Wartość
TrustStorepola powinna być poprzedzona prefiksemdata://. - Podczas określania zawartości dla wielu certyfikatów określ zawartość każdego certyfikatu między
-----BEGIN CERTIFICATE-----i-----END CERTIFICATE-----. Liczba kresków (-----) powinna być taka sama przed i po iBEGIN CERTIFICATEEND CERTIFICATE. Na przykład:
-----BEGIN CERTIFICATE-----<certificate content 1>-----END CERTIFICATE-----
-----BEGIN CERTIFICATE-----<certificate content 2>-----END CERTIFICATE-----
-----BEGIN CERTIFICATE-----<certificate content 3>-----END CERTIFICATE----- - Pole
TrustStoreobsługuje zawartość do 8192 znaków.
- Wartość
Metoda 3:
truststoreUtwórz plik z silnymi szyframi, takimi jak AES256.openssl pkcs12 -in [Full Path to the DER/PEM Certificate including the name of the DER/PEM Certificate] -out [Path and name of TrustStore] -passout pass:[Keystore PWD] -keypbe AES-256-CBC -certpbe AES-256-CBC -nokeys -exporttruststoreUmieść plik na maszynie własnego środowiska Integration Runtime. Na przykład umieść plik w folderzeC:\MyTrustStoreFile.W usłudze skonfiguruj parametry połączenia Oracle i
EncryptionMethod=1odpowiedniąTrustStore/TrustStorePasswordwartość. Na przykładHost=<host>;Port=<port>;Sid=<sid>;User Id=<username>;Password=<password>;EncryptionMethod=1;TrustStore=C:\\MyTrustStoreFile;TrustStorePassword=<trust_store_password>.
Przykład:
{
"name": "OracleLinkedService",
"properties": {
"type": "Oracle",
"typeProperties": {
"connectionString": "Host=<host>;Port=<port>;Sid=<sid>;User Id=<username>;Password=<password>;"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Przykład: przechowywanie hasła w usłudze Azure Key Vault
{
"name": "OracleLinkedService",
"properties": {
"type": "Oracle",
"typeProperties": {
"connectionString": "Host=<host>;Port=<port>;Sid=<sid>;User Id=<username>;",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Właściwości zestawu danych
Ta sekcja zawiera listę właściwości obsługiwanych przez zestaw danych Oracle. Aby uzyskać pełną listę sekcji i właściwości dostępnych do definiowania zestawów danych, zobacz Zestawy danych.
Aby skopiować dane z i do bazy danych Oracle, ustaw właściwość type zestawu danych na OracleTable. Obsługiwane są następujące właściwości.
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type zestawu danych musi być ustawiona na OracleTable. |
Tak |
| schema | Nazwa schematu. | Nie dla źródła, Tak dla ujścia |
| table | Nazwa tabeli/widoku. | Nie dla źródła, Tak dla ujścia |
| tableName | Nazwa tabeli/widoku ze schematem. Ta właściwość jest obsługiwana w celu zapewnienia zgodności z poprzednimi wersjami. W przypadku nowego obciążenia użyj polecenia schema i table. |
Nie dla źródła, Tak dla ujścia |
Przykład:
{
"name": "OracleDataset",
"properties":
{
"type": "OracleTable",
"schema": [],
"typeProperties": {
"schema": "<schema_name>",
"table": "<table_name>"
},
"linkedServiceName": {
"referenceName": "<Oracle linked service name>",
"type": "LinkedServiceReference"
}
}
}
Właściwości działania kopiowania
Ta sekcja zawiera listę właściwości obsługiwanych przez źródło i ujście oracle. Aby uzyskać pełną listę sekcji i właściwości dostępnych do definiowania działań, zobacz Pipelines (Potoki).
Oracle jako źródło
Napiwek
Aby wydajnie ładować dane z bazy danych Oracle przy użyciu partycjonowania danych, dowiedz się więcej na temat kopiowania równoległego z bazy danych Oracle.
Aby skopiować dane z bazy danych Oracle, ustaw typ źródła w działaniu kopiowania na OracleSourcewartość . Poniższe właściwości są obsługiwane w sekcji źródła działania kopiowania.
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type źródła działania kopiowania musi być ustawiona na OracleSourcewartość . |
Tak |
| oracleReaderQuery | Użyj niestandardowego zapytania SQL, aby odczytać dane. Może to być na przykład "SELECT * FROM MyTable".Po włączeniu obciążenia partycjonowanego należy podłączyć wszystkie odpowiednie wbudowane parametry partycji w zapytaniu. Aby zapoznać się z przykładami, zobacz sekcję Kopia równoległa z bazy danych Oracle . |
Nie. |
| convertDecimalToInteger | Typ Oracle NUMBER z liczbą zero lub nieokreśloną skalą zostanie przekonwertowany na odpowiadającą liczbę całkowitą. Dozwolone wartości to true i false (wartość domyślna). | Nie. |
| partitionOptions | Określa opcje partycjonowania danych używane do ładowania danych z oracle. Dozwolone wartości to: Brak (wartość domyślna), PhysicalPartitionsOfTable i DynamicRange. Jeśli opcja partycji jest włączona (czyli nie None), stopień równoległości równoczesnego ładowania danych z bazy danych Oracle jest kontrolowany przez parallelCopies ustawienie działania kopiowania. |
Nie. |
| partitionSettings | Określ grupę ustawień partycjonowania danych. Zastosuj, gdy opcja partycji nie Nonejest . |
Nie. |
| partitionNames | Lista partycji fizycznych, które należy skopiować. Zastosuj, gdy opcja partycji to PhysicalPartitionsOfTable. Jeśli używasz zapytania do pobierania danych źródłowych, należy podłączyć ?AdfTabularPartitionName się do klauzuli WHERE. Aby zapoznać się z przykładem, zobacz sekcję Kopia równoległa z bazy danych Oracle . |
Nie. |
| partitionColumnName | Określ nazwę kolumny źródłowej w typie liczb całkowitych, które będą używane przez partycjonowanie zakresu na potrzeby kopiowania równoległego. Jeśli nie zostanie określony, klucz podstawowy tabeli zostanie automatycznie wykryty i użyty jako kolumna partycji. Zastosuj, gdy opcja partycji to DynamicRange. Jeśli używasz zapytania do pobierania danych źródłowych, należy podłączyć ?AdfRangePartitionColumnName się do klauzuli WHERE. Aby zapoznać się z przykładem, zobacz sekcję Kopia równoległa z bazy danych Oracle . |
Nie. |
| partitionUpperBound | Maksymalna wartość kolumny partycji do skopiowania danych. Zastosuj, gdy opcja partycji to DynamicRange. Jeśli używasz zapytania do pobierania danych źródłowych, należy podłączyć ?AdfRangePartitionUpbound się do klauzuli WHERE. Aby zapoznać się z przykładem, zobacz sekcję Kopia równoległa z bazy danych Oracle . |
Nie. |
| partitionLowerBound | Minimalna wartość kolumny partycji do skopiowania danych. Zastosuj, gdy opcja partycji to DynamicRange. Jeśli używasz zapytania do pobierania danych źródłowych, należy podłączyć ?AdfRangePartitionLowbound się do klauzuli WHERE. Aby zapoznać się z przykładem, zobacz sekcję Kopia równoległa z bazy danych Oracle . |
Nie. |
Przykład: kopiowanie danych przy użyciu zapytania podstawowego bez partycji
"activities":[
{
"name": "CopyFromOracle",
"type": "Copy",
"inputs": [
{
"referenceName": "<Oracle input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "OracleSource",
"convertDecimalToInteger": false,
"oracleReaderQuery": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Oracle jako ujście
Aby skopiować dane do bazy danych Oracle, ustaw typ ujścia w działaniu kopiowania na OracleSinkwartość . Poniższe właściwości są obsługiwane w sekcji ujścia działania kopiowania.
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type ujścia działania kopiowania musi być ustawiona na OracleSinkwartość . |
Tak |
| writeBatchSize | Wstawia dane do tabeli SQL, gdy rozmiar buforu osiągnie writeBatchSizewartość .Dozwolone wartości to liczba całkowita (liczba wierszy). |
Nie (wartość domyślna to 10 000) |
| writeBatchTimeout | Czas oczekiwania na ukończenie operacji wstawiania wsadowego przed przekroczeniem limitu czasu. Dozwolone wartości to Przedział czasu. Przykładem jest 00:30:00 (30 minut). |
Nie. |
| preCopyScript | Określ zapytanie SQL dla działania kopiowania, które ma zostać uruchomione przed zapisaniem danych w programie Oracle w każdym uruchomieniu. Za pomocą tej właściwości można wyczyścić wstępnie załadowane dane. | Nie. |
| maxConcurrentConnections | Górny limit połączeń współbieżnych ustanowionych z magazynem danych podczas uruchamiania działania. Określ wartość tylko wtedy, gdy chcesz ograniczyć połączenia współbieżne. | Nie |
Przykład:
"activities":[
{
"name": "CopyToOracle",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Oracle output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "OracleSink"
}
}
}
]
Kopiowanie równoległe z bazy danych Oracle
Łącznik Oracle zapewnia wbudowane partycjonowanie danych w celu równoległego kopiowania danych z bazy danych Oracle. Opcje partycjonowania danych można znaleźć na karcie Źródło działania kopiowania.

Po włączeniu kopii partycjonowanej usługa uruchamia zapytania równoległe względem źródła Oracle w celu załadowania danych według partycji. Stopień równoległy jest kontrolowany przez parallelCopies ustawienie działania kopiowania. Jeśli na przykład ustawiono parallelCopies wartość cztery, usługa jednocześnie generuje i uruchamia cztery zapytania na podstawie określonej opcji partycji i ustawień, a każde zapytanie pobiera część danych z bazy danych Oracle.
Zaleca się włączenie kopiowania równoległego przy użyciu partycjonowania danych, szczególnie w przypadku ładowania dużej ilości danych z bazy danych Oracle. Poniżej przedstawiono sugerowane konfiguracje dla różnych scenariuszy. Podczas kopiowania danych do magazynu danych opartego na plikach zaleca się zapisywanie w folderze jako wielu plików (tylko określ nazwę folderu), w tym przypadku wydajność jest lepsza niż zapisywanie w jednym pliku.
| Scenariusz | Sugerowane ustawienia |
|---|---|
| Pełne ładowanie z dużej tabeli z partycjami fizycznymi. |
Opcja partycji: fizyczne partycje tabeli. Podczas wykonywania usługa automatycznie wykrywa partycje fizyczne i kopiuje dane według partycji. |
| Pełne ładowanie z dużej tabeli, bez partycji fizycznych, podczas gdy z kolumną całkowitą na potrzeby partycjonowania danych. |
Opcje partycji: partycja zakresu dynamicznego. Kolumna partycji: określ kolumnę używaną do partycjonowania danych. Jeśli nie zostanie określona, zostanie użyta kolumna klucza podstawowego. |
| Załaduj dużą ilość danych przy użyciu zapytania niestandardowego z partycjami fizycznymi. |
Opcja partycji: fizyczne partycje tabeli. Zapytanie: SELECT * FROM <TABLENAME> PARTITION("?AdfTabularPartitionName") WHERE <your_additional_where_clause>.Nazwa partycji: określ nazwy partycji do skopiowania danych. Jeśli nie zostanie określony, usługa automatycznie wykryje partycje fizyczne w tabeli określonej w zestawie danych Oracle. Podczas wykonywania usługa zastępuje ?AdfTabularPartitionName rzeczywistą nazwę partycji i wysyła do oracle. |
| Załaduj dużą ilość danych przy użyciu zapytania niestandardowego, bez partycji fizycznych, natomiast z kolumną całkowitą na potrzeby partycjonowania danych. |
Opcje partycji: partycja zakresu dynamicznego. Zapytanie: SELECT * FROM <TABLENAME> WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>.Kolumna partycji: określ kolumnę używaną do partycjonowania danych. Kolumnę można podzielić na partycje przy użyciu typu danych całkowitych. Górna granica partycji i dolna granica partycji: określ, czy chcesz filtrować względem kolumny partycji, aby pobrać dane tylko między dolnym i górnym zakresem. Podczas wykonywania usługa zastępuje ?AdfRangePartitionColumnNamewartości , ?AdfRangePartitionUpboundi ?AdfRangePartitionLowbound rzeczywistymi nazwami kolumn i zakresami wartości dla każdej partycji i wysyła je do oracle. Jeśli na przykład kolumna partycji "ID" jest ustawiona z dolną granicą jako 1 i górną granicą jako 80, z równoległym zestawem kopiowania ustawionym na 4, usługa pobiera dane przez 4 partycje. Ich identyfikatory to odpowiednio [120], [21, 40], [41, 60] i [61, 80]. |
Napiwek
Podczas kopiowania danych z tabeli bez partycji można użyć opcji partycji "Zakres dynamiczny", aby podzielić je na kolumnę całkowitą. Jeśli dane źródłowe nie mają takiego typu kolumny, możesz użyć funkcji ORA_HASH w zapytaniu źródłowym, aby wygenerować kolumnę i użyć jej jako kolumny partycji.
Przykład: zapytanie z partycją fizyczną
"source": {
"type": "OracleSource",
"query": "SELECT * FROM <TABLENAME> PARTITION(\"?AdfTabularPartitionName\") WHERE <your_additional_where_clause>",
"partitionOption": "PhysicalPartitionsOfTable",
"partitionSettings": {
"partitionNames": [
"<partitionA_name>",
"<partitionB_name>"
]
}
}
Przykład: zapytanie z partycją zakresu dynamicznego
"source": {
"type": "OracleSource",
"query": "SELECT * FROM <TABLENAME> WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column>",
"partitionLowerBound": "<lower_value_of_partition_column>"
}
}
Mapowanie typów danych dla oracle
Podczas kopiowania danych z i do programu Oracle w usłudze są używane następujące tymczasowe mapowania typów danych. Aby dowiedzieć się, jak działanie kopiowania mapuje schemat źródłowy i typ danych na ujście, zobacz Mapowania schematu i typu danych.
| Typ danych Oracle | Typ danych tymczasowych |
|---|---|
| PLIK BFILE | Bajt[] |
| BLOB | Bajt[] (obsługiwane tylko w systemie Oracle 10g i nowszym) |
| CHAR | String |
| CLOB | String |
| DATE | DateTime |
| SPŁAWIK | Liczba dziesiętna, ciąg (jeśli precyzja > 28) |
| LICZBA CAŁKOWITA | Liczba dziesiętna, ciąg (jeśli precyzja > 28) |
| DŁUGI | String |
| DŁUGI NIEPRZETWORZONE | Bajt[] |
| NCHAR | String |
| NCLOB | String |
| LICZBA (p,s) | Liczba dziesiętna, ciąg (jeśli p > 28) |
| LICZBA bez precyzji i skali | Liczba rzeczywista |
| NVARCHAR2 | String |
| SUROWY | Bajt[] |
| IDENTYFIKATOR WIERSZA | String |
| TIMESTAMP | DateTime |
| SYGNATURA CZASOWA Z LOKALNĄ STREFĄ CZASOWĄ | String |
| SYGNATURA CZASOWA ZE STREFĄ CZASOWĄ | String |
| LICZBA CAŁKOWITA BEZ ZNAKU | Liczba |
| VARCHAR2 | String |
| XML | String |
Uwaga
Typy danych INTERVAL YEAR TO MONTH i INTERVAL DAY TO SECOND nie są obsługiwane.
Właściwości działania wyszukiwania
Aby dowiedzieć się więcej o właściwościach, sprawdź działanie Wyszukiwania.
Powiązana zawartość
Aby uzyskać listę magazynów danych obsługiwanych jako źródła i ujścia działania kopiowania, zobacz Obsługiwane magazyny danych.