Kopiowanie danych z bazy danych Cassandra przy użyciu usługi Azure Data Factory lub Synapse Analytics
DOTYCZY:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
W tym artykule opisano sposób użycia działania kopiowania w potoku usługi Azure Data Factory lub Synapse Analytics w celu skopiowania danych z bazy danych Cassandra. Jest on oparty na artykule omówienie działania kopiowania, który przedstawia ogólne omówienie działania kopiowania.
Obsługiwane możliwości
Ten łącznik Cassandra jest obsługiwany w następujących możliwościach:
| Obsługiwane możliwości | IR |
|---|---|
| działanie Kopiuj (źródło/-) | (1) (2) |
| Działanie Lookup | (1) (2) |
(1) Środowisko Azure Integration Runtime (2) Self-hosted Integration Runtime
Aby uzyskać listę magazynów danych obsługiwanych jako źródła/ujścia, zobacz tabelę Obsługiwane magazyny danych.
W szczególności ten łącznik Cassandra obsługuje następujące funkcje:
- Cassandra w wersjach 2.x i 3.x.
- Kopiowanie danych przy użyciu uwierzytelniania podstawowego lub anonimowego .
Uwaga
W przypadku działań uruchomionych w środowisku Integration Runtime self-hosted system Cassandra 3.x jest obsługiwany od czasu środowiska IR w wersji 3.7 lub nowszej.
Wymagania wstępne
Jeśli magazyn danych znajduje się wewnątrz sieci lokalnej, sieci wirtualnej platformy Azure lub chmury prywatnej Amazon Virtual, musisz skonfigurować własne środowisko Integration Runtime , aby się z nim połączyć.
Jeśli magazyn danych jest zarządzaną usługą danych w chmurze, możesz użyć środowiska Azure Integration Runtime. Jeśli dostęp jest ograniczony do adresów IP zatwierdzonych w regułach zapory, możesz dodać adresy IP środowiska Azure Integration Runtime do listy dozwolonych.
Możesz również użyć funkcji środowiska Integration Runtime zarządzanej sieci wirtualnej w usłudze Azure Data Factory, aby uzyskać dostęp do sieci lokalnej bez instalowania i konfigurowania własnego środowiska Integration Runtime.
Aby uzyskać więcej informacji na temat mechanizmów zabezpieczeń sieci i opcji obsługiwanych przez usługę Data Factory, zobacz Strategie dostępu do danych.
Środowisko Integration Runtime udostępnia wbudowany sterownik Cassandra, dlatego nie trzeba ręcznie instalować żadnego sterownika podczas kopiowania danych z/do rozwiązania Cassandra.
Wprowadzenie
Aby wykonać działanie Kopiuj za pomocą potoku, możesz użyć jednego z następujących narzędzi lub zestawów SDK:
- Narzędzie do kopiowania danych
- Witryna Azure Portal
- Zestaw SDK platformy .NET
- Zestaw SDK języka Python
- Azure PowerShell
- Interfejs API REST
- Szablon usługi Azure Resource Manager
Tworzenie połączonej usługi z usługą Cassandra przy użyciu interfejsu użytkownika
Wykonaj poniższe kroki, aby utworzyć połączoną usługę z usługą Cassandra w interfejsie użytkownika witryny Azure Portal.
Przejdź do karty Zarządzanie w obszarze roboczym usługi Azure Data Factory lub Synapse i wybierz pozycję Połączone usługi, a następnie kliknij pozycję Nowy:
Wyszukaj pozycję Cassandra i wybierz łącznik Cassandra.
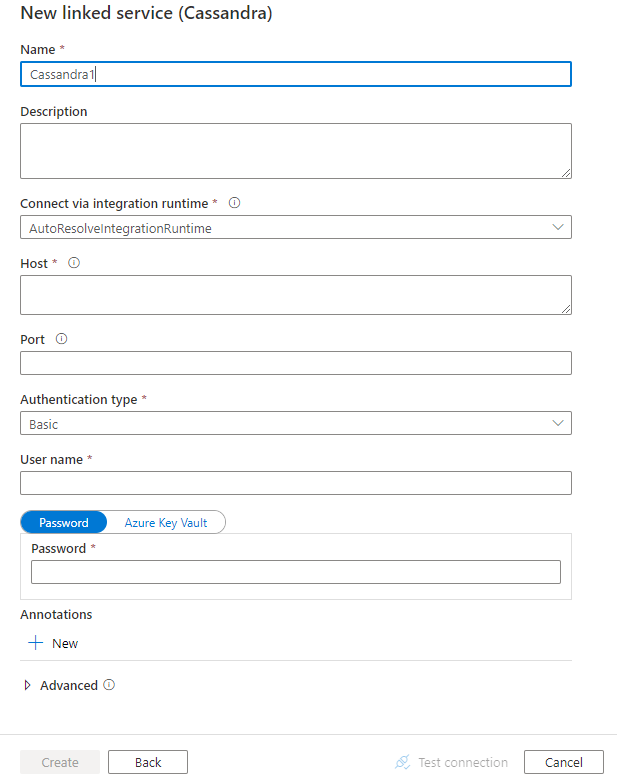
Skonfiguruj szczegóły usługi, przetestuj połączenie i utwórz nową połączoną usługę.
Szczegóły konfiguracji łącznika
Poniższe sekcje zawierają szczegółowe informacje o właściwościach używanych do definiowania jednostek usługi Data Factory specyficznych dla łącznika Cassandra.
Właściwości połączonej usługi
Następujące właściwości są obsługiwane w przypadku połączonej usługi Cassandra:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type musi być ustawiona na: Cassandra | Tak |
| host | Co najmniej jeden adres IP lub nazwy hostów serwerów Cassandra. Określ rozdzielaną przecinkami listę adresów IP lub nazw hostów, aby łączyć się ze wszystkimi serwerami jednocześnie. |
Tak |
| port | Port TCP używany przez serwer Cassandra do nasłuchiwania połączeń klienckich. | Nie (wartość domyślna to 9042) |
| authenticationType | Typ uwierzytelniania używanego do nawiązywania połączenia z bazą danych Cassandra. Dozwolone wartości to: Podstawowa i Anonimowa. |
Tak |
| nazwa użytkownika | Określ nazwę użytkownika dla konta użytkownika. | Tak, jeśli wartość authenticationType jest ustawiona na Wartość Podstawowa. |
| hasło | Określ hasło dla konta użytkownika. Oznacz to pole jako element SecureString w celu bezpiecznego przechowywania go lub odwołuj się do wpisu tajnego przechowywanego w usłudze Azure Key Vault. | Tak, jeśli wartość authenticationType jest ustawiona na Wartość Podstawowa. |
| connectVia | Środowisko Integration Runtime do nawiązania połączenia z magazynem danych. Dowiedz się więcej w sekcji Wymagania wstępne . Jeśli nie zostanie określony, używa domyślnego środowiska Azure Integration Runtime. | Nie. |
Uwaga
Obecnie połączenie z rozwiązaniem Cassandra przy użyciu protokołu TLS nie jest obsługiwane.
Przykład:
{
"name": "CassandraLinkedService",
"properties": {
"type": "Cassandra",
"typeProperties": {
"host": "<host>",
"authenticationType": "Basic",
"username": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Właściwości zestawu danych
Pełna lista sekcji i właściwości dostępnych do definiowania zestawów danych znajduje się w artykule dotyczącym zestawów danych. Ta sekcja zawiera listę właściwości obsługiwanych przez zestaw danych Cassandra.
Aby skopiować dane z bazy danych Cassandra, ustaw właściwość type zestawu danych na CassandraTable. Obsługiwane są następujące właściwości:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type zestawu danych musi być ustawiona na: CassandraTable | Tak |
| przestrzeń kluczy | Nazwa przestrzeni kluczy lub schematu w bazie danych Cassandra. | Nie (jeśli określono "zapytanie" dla elementu "CassandraSource") |
| tableName | Nazwa tabeli w bazie danych Cassandra. | Nie (jeśli określono "zapytanie" dla elementu "CassandraSource") |
Przykład:
{
"name": "CassandraDataset",
"properties": {
"type": "CassandraTable",
"typeProperties": {
"keySpace": "<keyspace name>",
"tableName": "<table name>"
},
"schema": [],
"linkedServiceName": {
"referenceName": "<Cassandra linked service name>",
"type": "LinkedServiceReference"
}
}
}
Właściwości działania kopiowania
Aby uzyskać pełną listę sekcji i właściwości dostępnych do definiowania działań, zobacz artykuł Pipelines (Potoki ). Ta sekcja zawiera listę właściwości obsługiwanych przez źródło cassandra.
Cassandra jako źródło
Aby skopiować dane z bazy danych Cassandra, ustaw typ źródła w działaniu kopiowania na cassandraSource. Następujące właściwości są obsługiwane w sekcji źródło działania kopiowania:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type źródła działania kopiowania musi być ustawiona na: CassandraSource | Tak |
| zapytanie | Użyj zapytania niestandardowego, aby odczytać dane. Zapytanie SQL-92 lub zapytanie CQL. Zobacz dokumentację języka CQL. W przypadku korzystania z zapytania SQL określ nazwę przestrzeni kluczy.nazwa tabeli do reprezentowania tabeli, którą chcesz wykonać. |
Nie (jeśli określono "tableName" i "keyspace" w zestawie danych). |
| consistencyLevel | Poziom spójności określa, ile replik musi odpowiadać na żądanie odczytu przed zwróceniem danych do aplikacji klienckiej. System Cassandra sprawdza określoną liczbę replik dla danych w celu spełnienia żądania odczytu. Aby uzyskać szczegółowe informacje, zobacz Konfigurowanie spójności danych. Dozwolone wartości to: JEDEN, DWA, TRZY, KWORUM, WSZYSTKIE, LOCAL_QUORUM, EACH_QUORUM i LOCAL_ONE. |
Nie (wartość domyślna to ONE) |
Przykład:
"activities":[
{
"name": "CopyFromCassandra",
"type": "Copy",
"inputs": [
{
"referenceName": "<Cassandra input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "CassandraSource",
"query": "select id, firstname, lastname from mykeyspace.mytable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Mapowanie typów danych dla bazy danych Cassandra
Podczas kopiowania danych z bazy danych Cassandra następujące mapowania są używane z typów danych Cassandra do tymczasowych typów danych używanych wewnętrznie w usłudze. Zobacz Mapowania schematu i typu danych, aby dowiedzieć się, jak działanie kopiowania mapuje schemat źródłowy i typ danych na ujście.
| Typ danych cassandra | Typ danych usługi tymczasowej |
|---|---|
| ASCII | String |
| BIGINT | Int64 |
| BLOB | Bajt[] |
| BOOLOWSKI | Wartość logiczna |
| DZIESIĘTNY | Dziesiętne |
| PODWÓJNY | Liczba rzeczywista |
| SPŁAWIK | Pojedynczy |
| ZESTAW INET | String |
| INT | Int32 |
| TEKST | String |
| TIMESTAMP | DateTime |
| IDENTYFIKATOR TIMEUUID | Identyfikator GUID |
| Identyfikator UUID | Identyfikator GUID |
| VARCHAR | String |
| VARINT | Dziesiętne |
Uwaga
W przypadku typów kolekcji (mapa, zestaw, lista itp.) zapoznaj się z sekcją Praca z typami kolekcji Cassandra przy użyciu tabeli wirtualnej.
Typy zdefiniowane przez użytkownika nie są obsługiwane.
Długość kolumny binarnej i długości kolumny ciągu nie może być większa niż 4000.
Praca z kolekcjami przy użyciu tabeli wirtualnej
Usługa używa wbudowanego sterownika ODBC do nawiązywania połączenia i kopiowania danych z bazy danych Cassandra. W przypadku typów kolekcji, w tym mapowania, ustawiania i listy, sterownik renormalizuje dane w odpowiednich tabelach wirtualnych. W szczególności jeśli tabela zawiera jakiekolwiek kolumny kolekcji, sterownik generuje następujące tabele wirtualne:
- Tabela podstawowa zawierająca te same dane co rzeczywista tabela z wyjątkiem kolumn kolekcji. Tabela podstawowa używa takiej samej nazwy jak rzeczywista tabela, którą reprezentuje.
- Tabela wirtualna dla każdej kolumny kolekcji, która rozszerza zagnieżdżone dane. Tabele wirtualne reprezentujące kolekcje mają nazwę przy użyciu nazwy rzeczywistej tabeli, separatora "vt" i nazwy kolumny.
Tabele wirtualne odwołują się do danych w rzeczywistej tabeli, umożliwiając sterownikowi dostęp do danych, które nie są znormalizowane. Aby uzyskać szczegółowe informacje, zobacz sekcję Przykład. Dostęp do zawartości kolekcji Cassandra można uzyskać, wykonując zapytania i łącząc tabele wirtualne.
Przykład
Na przykład następująca tabela "ExampleTable" to tabela bazy danych Cassandra zawierająca kolumnę klucza podstawowego o nazwie "pk_int", kolumnę tekstową o nazwie value, kolumnę listy, kolumnę mapy i kolumnę zestawu (o nazwie "StringSet").
| pk_int | Wartość | List | Mapowanie | StringSet |
|---|---|---|---|---|
| 1 | "przykładowa wartość 1" | ["1", "2", "3"] | {"S1": "a", "S2": "b"} | {"A", "B", "C"} |
| 3 | "przykładowa wartość 3" | ["100", "101", "102", "105"] | {"S1": "t"} | {"A", "E"} |
Sterownik wygenerowałby wiele tabel wirtualnych reprezentujących tę pojedynczą tabelę. Kolumny klucza obcego w tabelach wirtualnych odwołują się do kolumn klucza podstawowego w rzeczywistej tabeli i wskazują, który rzeczywisty wiersz tabeli odpowiada wierszowi tabeli wirtualnej.
Pierwsza tabela wirtualna to tabela podstawowa o nazwie "ExampleTable" pokazana w poniższej tabeli:
| pk_int | Wartość |
|---|---|
| 1 | "przykładowa wartość 1" |
| 3 | "przykładowa wartość 3" |
Tabela podstawowa zawiera te same dane co oryginalna tabela bazy danych z wyjątkiem kolekcji, które zostały pominięte z tej tabeli i rozwinięte w innych tabelach wirtualnych.
W poniższych tabelach przedstawiono tabele wirtualne, które renormalizują dane z kolumn List, Map i StringSet. Kolumny z nazwami kończącymi się ciągiem "_index" lub "_key" wskazują położenie danych na oryginalnej liście lub mapie. Kolumny z nazwami kończącymi się ciągiem "_value" zawierają rozwinięte dane z kolekcji.
Tabela "ExampleTable_vt_List":
| pk_int | List_index | List_value |
|---|---|---|
| 1 | 0 | 1 |
| 1 | 1 | 2 |
| 1 | 2 | 3 |
| 3 | 0 | 100 |
| 3 | 1 | 101 |
| 3 | 2 | 102 |
| 3 | 3 | 103 |
Tabela "ExampleTable_vt_Map":
| pk_int | Map_key | Map_value |
|---|---|---|
| 1 | S1 | A |
| 1 | S2 | b |
| 3 | S1 | t |
Tabela "ExampleTable_vt_StringSet":
| pk_int | StringSet_value |
|---|---|
| 1 | A |
| 1 | B |
| 1 | C |
| 3 | A |
| 3 | E |
Właściwości działania wyszukiwania
Aby dowiedzieć się więcej o właściwościach, sprawdź działanie Wyszukiwania.
Powiązana zawartość
Aby uzyskać listę magazynów danych obsługiwanych jako źródła i ujścia działania kopiowania, zobacz obsługiwane magazyny danych.