Monitorowanie działania kopiowania
DOTYCZY:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
W tym artykule opisano sposób monitorowania wykonywania działań kopiowania w potokach usługi Azure Data Factory i Synapse. Jest on oparty na artykule omówienie działania kopiowania, który przedstawia ogólne omówienie działania kopiowania. Możesz również monitorować działania kopiowania generowane za pomocą narzędzia do kopiowania danych, a także działania usuwania przy użyciu tego samego podejścia.
Monitorowanie wizualne
Po utworzeniu i opublikowaniu potoku możesz skojarzyć go z wyzwalaczem lub ręcznie uruchomić uruchomienie ad hoc. Wszystkie uruchomienia potoku można monitorować natywnie w środowisku użytkownika. Dowiedz się więcej o ogólnym monitorowaniu z poziomu wizualnego monitorowania potoków usługi Azure Data Factory i synapse.
Aby monitorować uruchamianie działanie Kopiuj, przejdź do interfejsu użytkownika usługi Data Factory Studio lub Azure Synapse Studio dla wystąpienia usługi. Na karcie Monitor zostanie wyświetlona lista przebiegów potoku, kliknij link nazwa potoku, aby uzyskać dostęp do listy uruchomień działań w przebiegu potoku.

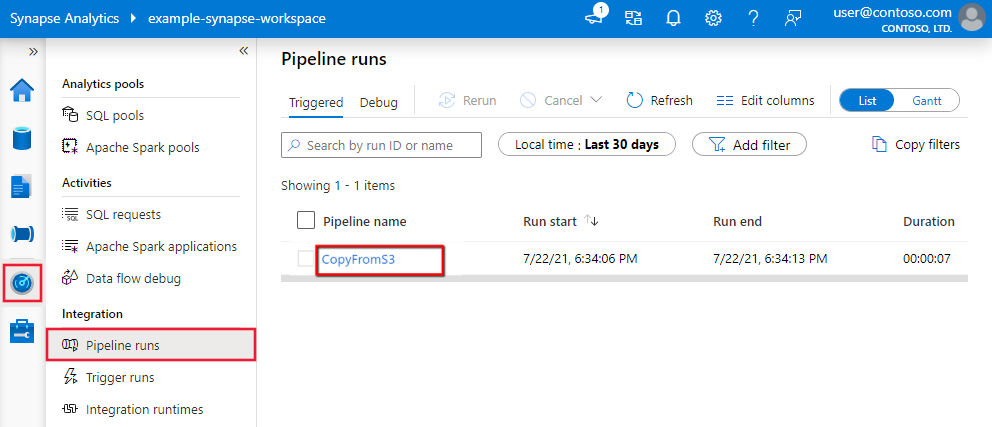
Na tym poziomie można wyświetlić linki do danych wejściowych, wyjściowych i błędów działania kopiowania (jeśli uruchomienie działanie Kopiuj kończy się niepowodzeniem), a także statystyk, takich jak czas trwania/stan. Kliknięcie przycisku Szczegóły (okulary) obok nazwy działania kopiowania spowoduje podanie szczegółowych informacji na temat wykonywania działania kopiowania.
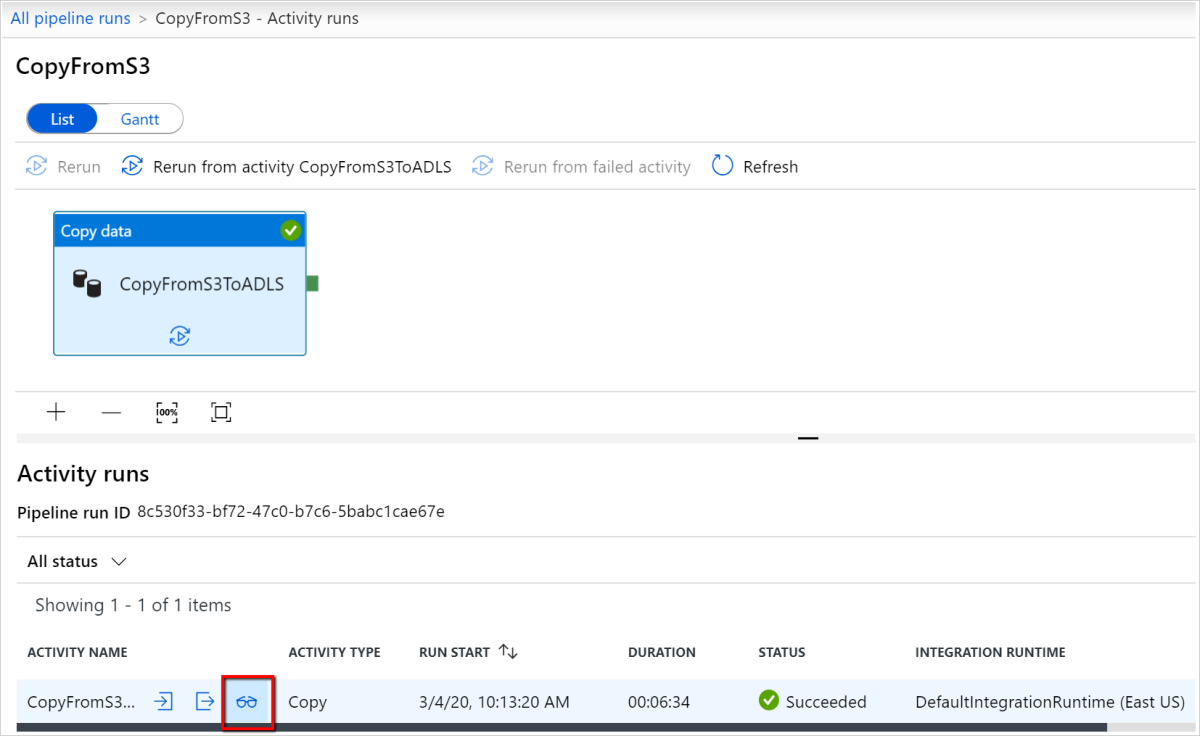
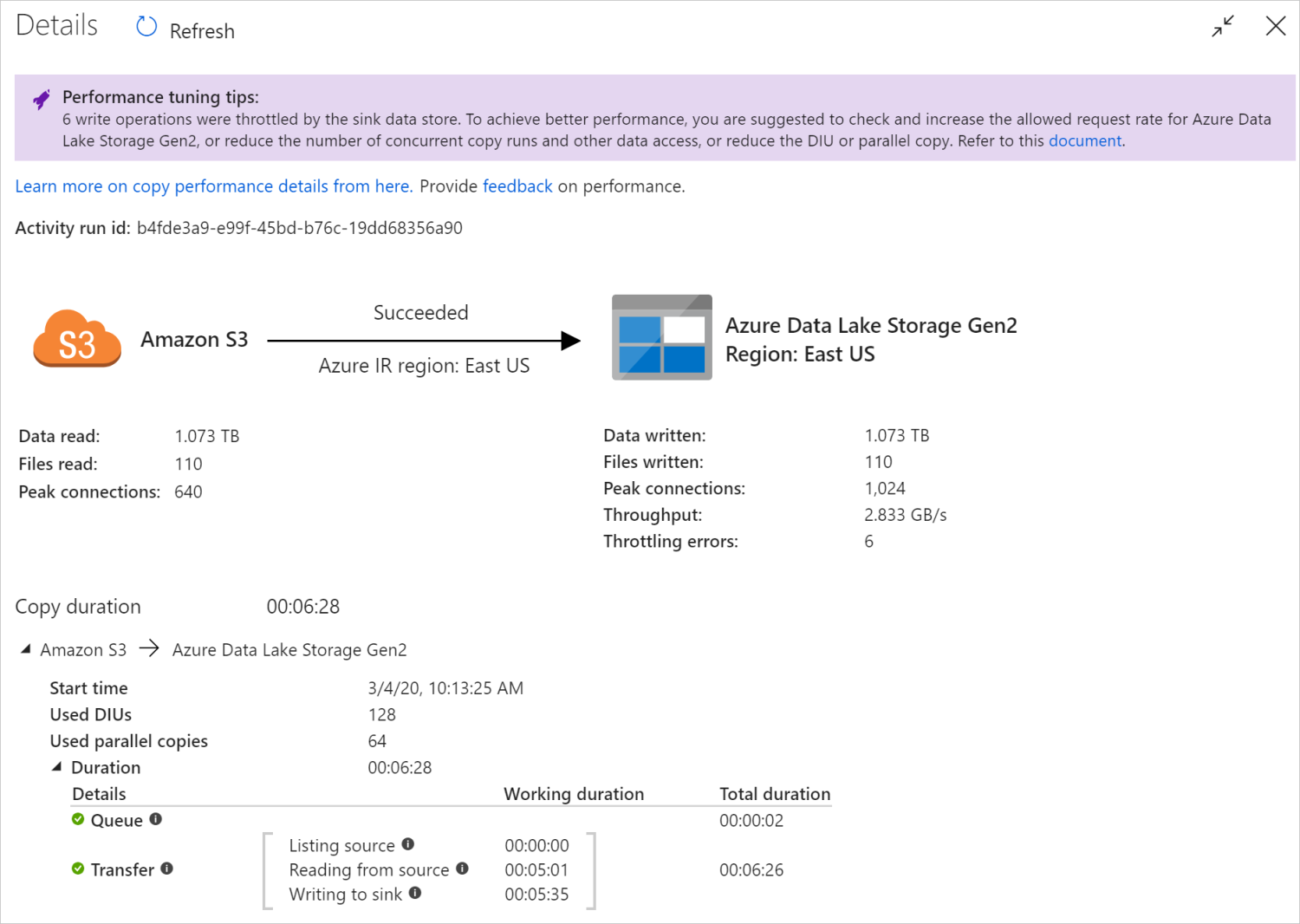
W tym graficznym widoku monitorowania usługa przedstawia informacje o wykonywaniu działania kopiowania, w tym dane odczytu/zapisu woluminu, liczbę plików/wierszy danych skopiowanych ze źródła do ujścia, przepływność, konfiguracje zastosowane do scenariusza kopiowania, kroki, przez które działanie kopiowania przechodzi z odpowiednimi czasami trwania i szczegółami i nie tylko. Zapoznaj się z tą tabelą w każdej możliwej metryce i jej szczegółowym opisem.
W niektórych scenariuszach po uruchomieniu działanie Kopiuj w górnej części widoku monitorowania działania kopiowania zobaczysz "Porady dotyczące dostrajania wydajności", jak pokazano w przykładzie. Porady informują o wąskim gardło zidentyfikowanym przez usługę dla określonego przebiegu kopiowania oraz sugestie dotyczące zmian w celu zwiększenia przepływności kopiowania. Dowiedz się więcej o poradach dotyczących automatycznego dostrajania wydajności.
Szczegóły i czasy trwania dolnego wykonania opisują kluczowe kroki wykonywane przez działanie kopiowania, co jest szczególnie przydatne w przypadku rozwiązywania problemów z wydajnością kopiowania. Wąskim gardłem przebiegu kopiowania jest ten z najdłuższym czasem trwania. Zapoznaj się z tematem Rozwiązywanie problemów z wydajnością działania kopiowania, aby dowiedzieć się, co reprezentuje każdy etap, oraz szczegółowe wskazówki dotyczące rozwiązywania problemów.
Przykład: kopiowanie z usługi Amazon S3 do usługi Azure Data Lake Storage Gen2
Programowe monitorowanie
działanie Kopiuj szczegóły wykonania i charakterystykę wydajności są również zwracane w Sekcja Dane wyjściowe przebiegu>działania kopiowania, która służy do renderowania widoku monitorowania interfejsu użytkownika. Poniżej znajduje się pełna lista właściwości, które mogą zostać zwrócone. Zobaczysz tylko właściwości, które mają zastosowanie do scenariusza kopiowania. Aby uzyskać informacje na temat programowego monitorowania przebiegów działań, zobacz Programowe monitorowanie potoku usługi Azure Data Factory lub Synapse.
| Nazwa właściwości | Opis | Jednostka w danych wyjściowych |
|---|---|---|
| dataRead | Rzeczywista ilość danych odczytanych ze źródła. | Wartość int64 w bajtach |
| dataWritten | Rzeczywista instalacja danych zapisanych/zatwierdzonych w ujściu. Rozmiar może się różnić od dataRead rozmiaru, ponieważ odnosi się do sposobu przechowywania danych w każdym magazynie danych. |
Wartość int64 w bajtach |
| filesRead | Liczba plików odczytanych ze źródła opartego na plikach. | Wartość int64 (bez jednostki) |
| filesWritten | Liczba plików zapisanych/zatwierdzonych w ujściu opartym na plikach. | Wartość int64 (bez jednostki) |
| filesSkipped | Liczba plików pominiętych ze źródła opartego na plikach. | Wartość int64 (bez jednostki) |
| dataConsistencyVerification | Szczegóły weryfikacji spójności danych, w których można sprawdzić, czy skopiowane dane zostały zweryfikowane, aby były spójne między magazynem źródłowym i docelowym. Dowiedz się więcej z tego artykułu. | Tablica |
| sourcePeakConnections | Szczytowa liczba połączeń współbieżnych ustanowionych w źródłowym magazynie danych podczas uruchamiania działanie Kopiuj. | Wartość int64 (bez jednostki) |
| sinkPeakConnections | Szczytowa liczba połączeń współbieżnych nawiązanych z magazynem danych ujścia podczas uruchamiania działanie Kopiuj. | Wartość int64 (bez jednostki) |
| wierszeRead | Liczba wierszy odczytanych ze źródła. Ta metryka nie ma zastosowania podczas kopiowania plików bez analizowania ich, na przykład gdy zestawy danych źródłowych i ujścia są typem formatu binarnego lub innym typem formatu z identycznymi ustawieniami. | Wartość int64 (bez jednostki) |
| wiersze skopiowane | Liczba wierszy skopiowanych do ujścia. Ta metryka nie ma zastosowania podczas kopiowania plików bez analizowania ich, na przykład gdy zestawy danych źródłowych i ujścia są typem formatu binarnego lub innym typem formatu z identycznymi ustawieniami. | Wartość int64 (bez jednostki) |
| wierszeZmapowane | Liczba niezgodnych wierszy, które zostały pominięte. Można włączyć pomijanie niezgodnych wierszy, ustawiając wartość enableSkipIncompatibleRow true. |
Wartość int64 (bez jednostki) |
| copyDuration | Czas trwania przebiegu kopiowania. | Wartość int32 w sekundach |
| danych | Szybkość transferu danych obliczana przez dataRead wartość podzieloną przez copyDuration. |
Liczba zmiennoprzecinkowa w KBps |
| sourcePeakConnections | Szczytowa liczba połączeń współbieżnych ustanowionych w źródłowym magazynie danych podczas uruchamiania działanie Kopiuj. | Wartość int32 (bez jednostki) |
| sinkPeakConnections | Szczytowa liczba połączeń współbieżnych nawiązanych z magazynem danych ujścia podczas uruchamiania działanie Kopiuj. | Wartość int32 (bez jednostki) |
| sqlDwPolyBase | Czy technologia PolyBase jest używana podczas kopiowania danych do usługi Azure Synapse Analytics. | Wartość logiczna |
| redshiftUnload | Czy funkcja UNLOAD jest używana podczas kopiowania danych z usługi Redshift. | Wartość logiczna |
| hdfsDistcp | Czy narzędzie DistCp jest używane podczas kopiowania danych z systemu plików HDFS. | Wartość logiczna |
| effectiveIntegrationRuntime | Środowisko Integration Runtime (IR) lub środowiska uruchomieniowe używane do uruchamiania działania w formacie <IR name> (<region if it's Azure IR>). |
Tekst (ciąg) |
| usedDataIntegrationUnits | Obowiązująca Integracja danych Units podczas kopiowania. | Wartość int32 |
| usedParallelCopies | Skuteczne parallelCopies podczas kopiowania. | Wartość int32 |
| logPath | Ścieżka do dziennika sesji pominiętych danych w magazynie obiektów blob. Zobacz Odporność na uszkodzenia. | Tekst (ciąg) |
| executionDetails | Więcej szczegółów na temat etapów działanie Kopiuj zawiera odpowiednie kroki, czasy trwania, konfiguracje itd. Nie zalecamy analizowania tej sekcji, ponieważ może ona ulec zmianie. Aby lepiej zrozumieć, jak ułatwia zrozumienie wydajności kopiowania i rozwiązywanie problemów z nią, zapoznaj się z sekcją Monitorowanie wizualnie . | Tablica |
| perfRecommendation | Porady dotyczące dostrajania wydajności kopiowania. Aby uzyskać szczegółowe informacje, zobacz Porady dotyczące dostrajania wydajności. | Tablica |
| billingReference | Użycie rozliczeń dla danego przebiegu. Dowiedz się więcej na stronie Monitorowanie zużycia na poziomie działania i uruchamiania. | Objekt |
| durationInQueue | Czas trwania kolejkowania w sekundach przed rozpoczęciem działania kopiowania. | Objekt |
Przykład:
"output": {
"dataRead": 1180089300500,
"dataWritten": 1180089300500,
"filesRead": 110,
"filesWritten": 110,
"filesSkipped": 0,
"sourcePeakConnections": 640,
"sinkPeakConnections": 1024,
"copyDuration": 388,
"throughput": 2970183,
"errors": [],
"effectiveIntegrationRuntime": "DefaultIntegrationRuntime (East US)",
"usedDataIntegrationUnits": 128,
"billingReference": "{\"activityType\":\"DataMovement\",\"billableDuration\":[{\"Managed\":11.733333333333336}]}",
"usedParallelCopies": 64,
"dataConsistencyVerification":
{
"VerificationResult": "Verified",
"InconsistentData": "None"
},
"executionDetails": [
{
"source": {
"type": "AmazonS3"
},
"sink": {
"type": "AzureBlobFS",
"region": "East US",
"throttlingErrors": 6
},
"status": "Succeeded",
"start": "2020-03-04T02:13:25.1454206Z",
"duration": 388,
"usedDataIntegrationUnits": 128,
"usedParallelCopies": 64,
"profile": {
"queue": {
"status": "Completed",
"duration": 2
},
"transfer": {
"status": "Completed",
"duration": 386,
"details": {
"listingSource": {
"type": "AmazonS3",
"workingDuration": 0
},
"readingFromSource": {
"type": "AmazonS3",
"workingDuration": 301
},
"writingToSink": {
"type": "AzureBlobFS",
"workingDuration": 335
}
}
}
},
"detailedDurations": {
"queuingDuration": 2,
"transferDuration": 386
}
}
],
"perfRecommendation": [
{
"Tip": "6 write operations were throttled by the sink data store. To achieve better performance, you are suggested to check and increase the allowed request rate for Azure Data Lake Storage Gen2, or reduce the number of concurrent copy runs and other data access, or reduce the DIU or parallel copy.",
"ReferUrl": "https://go.microsoft.com/fwlink/?linkid=2102534 ",
"RuleName": "ReduceThrottlingErrorPerfRecommendationRule"
}
],
"durationInQueue": {
"integrationRuntimeQueue": 0
}
}
Powiązana zawartość
Zobacz inne artykuły dotyczące działania kopiowania: