Format JSON w usługach Azure Data Factory i Azure Synapse Analytics
DOTYCZY:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
Postępuj zgodnie z tym artykułem, gdy chcesz przeanalizować pliki JSON lub zapisać dane w formacie JSON.
Format JSON jest obsługiwany dla następujących łączników:
- Amazon S3
- Magazyn zgodny z usługą Amazon S3,
- Azure Blob
- Usługa Azure Data Lake Storage 1. generacji
- Azure Data Lake Storage Gen2
- Azure Files
- System plików
- FTP
- Google Cloud Storage
- HDFS
- HTTP
- Oracle Cloud Storage
- SFTP
Właściwości zestawu danych
Aby uzyskać pełną listę sekcji i właściwości dostępnych do definiowania zestawów danych, zobacz artykuł Zestawy danych. Ta sekcja zawiera listę właściwości obsługiwanych przez zestaw danych JSON.
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type zestawu danych musi być ustawiona na wartość Json. | Tak |
| lokalizacja | Ustawienia lokalizacji plików. Każdy łącznik oparty na plikach ma własny typ lokalizacji i obsługiwane właściwości w obszarze location. Zobacz szczegóły w artykule dotyczącym łącznika —> sekcja Właściwości zestawu danych. |
Tak |
| encodingName | Typ kodowania używany do odczytu/zapisu plików testowych. Dozwolone wartości są następujące: "UTF-8","UTF-8 bez BOM", "UTF-16", "UTF-16BE", "UTF-32", "UTF-32BE", "US-ASCII", "UTF-7", "BIG5", "EUC-JP", "EUC-KR", "GB2312", "GB18030", "JOHAB", "SHIFT-JIS", "CP875", "CP866", "IBM00858", "IBM037", "IBM273", "IBM437", "IBM500", "IBM737", "IBM737", "IBM775", "IBM850", "IBM852", "IBM855", "IBM857", "IBM860", "IBM861", "IBM863", "IBM864", "IBM865", "IBM865", "IBM869", "IBM870", "IBM01140", "IBM01141", "IBM01142", "IBM01143", "IBM01144", "IBM01145", "IBM01146", "IBM01147", "IBM01148", "IBM01149", "ISO-2022-JP", "ISO-2022-KR", "ISO-8859-1", "ISO-8859-2", "ISO-8859-3", "ISO-8859-4", "ISO-8859-5", "ISO-8859-6", "ISO-8859-7", "ISO-8859-8", "ISO-8859-9", "ISO-8859-13", "ISO-8859-15", "WINDOWS-874", "WINDOWS-1250", "WINDOWS-1251", "WINDOWS-1255"2", "WINDOWS-1253", "WINDOWS-1254", "WINDOWS-1255", "WINDOWS-1256", "WINDOWS-1257", "WINDOWS-1258". |
Nie. |
| kompresja | Grupa właściwości do skonfigurowania kompresji pliku. Skonfiguruj tę sekcję, gdy chcesz wykonać kompresję/dekompresję podczas wykonywania działań. | Nie. |
| type (w obszarze compression) |
Koder koder kompresji używany do odczytu/zapisu plików JSON. Dozwolone wartości to bzip2, gzip, deflate, ZipDeflate, TarGzip, Tar, Snappy lub lz4. Wartość domyślna nie jest kompresowana. Uwaga obecnie działanie Kopiuj nie obsługuje "snappy" i "lz4", a przepływ danych mapowania nie obsługuje "ZipDeflate", "TarGzip" i "Tar". Uwaga podczas używania działania kopiowania do dekompresowania plików TarDeflate/TarGzip/ i zapisu w magazynie danych ujścia opartego na plikach pliki domyślnie pliki są wyodrębniane do folderu: <path specified in dataset>/<folder named as source compressed file>/ użyj/preserveCompressionFileNameAsFolder preserveZipFileNameAsFolderźródła działania kopiowania, aby kontrolować, czy zachować nazwę skompresowanych plików jako struktury folderów. |
L.p. |
| poziom (w obszarze compression) |
Współczynnik kompresji. Dozwolone wartości są optymalne lub najszybsze. - Najszybsza: operacja kompresji powinna zostać ukończona tak szybko, jak to możliwe, nawet jeśli wynikowy plik nie jest optymalnie skompresowany. - Optymalna: operacja kompresji powinna być optymalnie skompresowana, nawet jeśli operacja trwa dłużej. Aby uzyskać więcej informacji, zobacz Temat Poziom kompresji. |
Nie. |
Poniżej przedstawiono przykład zestawu danych JSON w usłudze Azure Blob Storage:
{
"name": "JSONDataset",
"properties": {
"type": "Json",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"container": "containername",
"folderPath": "folder/subfolder",
},
"compression": {
"type": "gzip"
}
}
}
}
Właściwości działania kopiowania
Aby uzyskać pełną listę sekcji i właściwości dostępnych do definiowania działań, zobacz artykuł Pipelines (Potoki ). Ta sekcja zawiera listę właściwości obsługiwanych przez źródło i ujście JSON.
Dowiedz się, jak wyodrębniać dane z plików JSON i mapować je na ujście magazynu danych/formatu lub odwrotnie z mapowania schematu.
Kod JSON jako źródło
Następujące właściwości są obsługiwane w sekcji działanie kopiowania *źródło* .
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type źródła działania kopiowania musi być ustawiona na wartość JSONSource. | Tak |
| formatUstawienia | Grupa właściwości. Zapoznaj się z poniższą tabelą ustawień odczytu w formacie JSON. | Nie. |
| storeSettings | Grupa właściwości dotyczących odczytywania danych z magazynu danych. Każdy łącznik oparty na plikach ma własne obsługiwane ustawienia odczytu w obszarze storeSettings. Zobacz szczegóły w artykule dotyczącym łącznika —> sekcja właściwości działanie Kopiuj. |
Nie. |
Obsługiwane ustawienia odczytu w formacie JSON w obszarze formatSettings:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Typ formatUstawienia musi być ustawiony na wartość JsonReadSettings. | Tak |
| compressionProperties | Grupa właściwości dotyczących dekompresowania danych dla danego koder-dekodera kompresji. | Nie. |
| preserveZipFileNameAsFolder (pod compressionProperties->type jako ZipDeflateReadSettings) |
Dotyczy konfiguracji wejściowego zestawu danych z kompresją ZipDeflate . Wskazuje, czy podczas kopiowania zachować nazwę źródłowego pliku zip jako strukturę folderów. — W przypadku ustawienia wartości true (wartość domyślna) usługa zapisuje rozpakowane pliki na wartość <path specified in dataset>/<folder named as source zip file>/.— Po ustawieniu wartości false usługa zapisuje rozpakowane pliki bezpośrednio do . <path specified in dataset> Upewnij się, że nie masz zduplikowanych nazw plików w różnych źródłowych plikach zip, aby uniknąć wyścigów ani nieoczekiwanych zachowań. |
Nie. |
| preserveCompressionFileNameAsFolder (w obszarze compressionProperties->type jako TarGZipReadSettings lub TarReadSettings) |
Ma zastosowanie w przypadku skonfigurowania wejściowego zestawu danych z kompresją TarGzip/Tar. Wskazuje, czy podczas kopiowania zachować nazwę skompresowanego pliku źródłowego jako strukturę folderów. — W przypadku ustawienia wartości true (wartość domyślna) usługa zapisuje dekompresowane pliki na wartość <path specified in dataset>/<folder named as source compressed file>/. - W przypadku ustawienia wartości false usługa zapisuje dekompresowane pliki bezpośrednio do <path specified in dataset>. Upewnij się, że nie masz zduplikowanych nazw plików w różnych plikach źródłowych, aby uniknąć wyścigów ani nieoczekiwanych zachowań. |
Nie. |
Kod JSON jako ujście
Następujące właściwości są obsługiwane w sekcji działanie kopiowania *ujście*.
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type źródła działania kopiowania musi być ustawiona na wartość JSONSink. | Tak |
| formatUstawienia | Grupa właściwości. Zapoznaj się z poniższą tabelą ustawień zapisu w formacie JSON. | Nie. |
| storeSettings | Grupa właściwości dotyczących sposobu zapisywania danych w magazynie danych. Każdy łącznik oparty na plikach ma własne obsługiwane ustawienia zapisu w obszarze storeSettings. Zobacz szczegóły w artykule dotyczącym łącznika —> sekcja właściwości działanie Kopiuj. |
Nie. |
Obsługiwane ustawienia zapisu w formacie JSON w obszarze formatSettings:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Typ formatUstawienia musi być ustawiony na wartość JsonWriteSettings. | Tak |
| filePattern | Wskazuje wzorzec danych przechowywanych w każdym pliku JSON. Dozwolone wartości to: setOfObjects (linie JSON) i arrayOfObjects. Wartością domyślną jest setOfObjects. Aby uzyskać szczegółowe informacje o tych wzorcach, zobacz sekcję Wzorce plików JSON. | Nie. |
Wzorce plików JSON
Podczas kopiowania danych z plików JSON działanie kopiowania może automatycznie wykrywać i analizować następujące wzorce plików JSON. Podczas zapisywania danych w plikach JSON można skonfigurować wzorzec pliku w ujściu działania kopiowania.
Typ I: setOfObjects
Każdy plik zawiera pojedynczy obiekt, linie JSON lub obiekty łączone.
przykład kodu JSON z pojedynczym obiektem
{ "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" }Linie JSON (ustawienie domyślne dla ujścia)
{"time":"2015-04-29T07:12:20.9100000Z","callingimsi":"466920403025604","callingnum1":"678948008","callingnum2":"567834760","switch1":"China","switch2":"Germany"} {"time":"2015-04-29T07:13:21.0220000Z","callingimsi":"466922202613463","callingnum1":"123436380","callingnum2":"789037573","switch1":"US","switch2":"UK"} {"time":"2015-04-29T07:13:21.4370000Z","callingimsi":"466923101048691","callingnum1":"678901578","callingnum2":"345626404","switch1":"Germany","switch2":"UK"}przykład kodu JSON z obiektami połączonymi
{ "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" } { "time": "2015-04-29T07:13:21.0220000Z", "callingimsi": "466922202613463", "callingnum1": "123436380", "callingnum2": "789037573", "switch1": "US", "switch2": "UK" } { "time": "2015-04-29T07:13:21.4370000Z", "callingimsi": "466923101048691", "callingnum1": "678901578", "callingnum2": "345626404", "switch1": "Germany", "switch2": "UK" }
Typ II: arrayOfObjects
Każdy plik zawiera tablicę obiektów.
[ { "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" }, { "time": "2015-04-29T07:13:21.0220000Z", "callingimsi": "466922202613463", "callingnum1": "123436380", "callingnum2": "789037573", "switch1": "US", "switch2": "UK" }, { "time": "2015-04-29T07:13:21.4370000Z", "callingimsi": "466923101048691", "callingnum1": "678901578", "callingnum2": "345626404", "switch1": "Germany", "switch2": "UK" } ]
Właściwości przepływu mapowania danych
W przepływach mapowania danych można odczytywać i zapisywać dane w formacie JSON w następujących magazynach danych: Azure Blob Storage, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2 i SFTP oraz odczytywać format JSON w usłudze Amazon S3.
Właściwości źródła
W poniższej tabeli wymieniono właściwości obsługiwane przez źródło json. Te właściwości można edytować na karcie Opcje źródła.
| Nazwa/nazwisko | opis | Wymagania | Dozwolone wartości | Właściwość skryptu przepływu danych |
|---|---|---|---|---|
| Ścieżki z symbolami wieloznacznymi | Wszystkie pliki pasujące do ścieżki wieloznacznej zostaną przetworzone. Zastępuje folder i ścieżkę pliku ustawioną w zestawie danych. | nie | Ciąg[] | symbole wieloznacznePaths |
| Ścieżka główna partycji | W przypadku danych plików podzielonych na partycje można wprowadzić ścieżkę katalogu głównego partycji, aby odczytywać foldery podzielone na partycje jako kolumny | nie | String | partitionRootPath |
| Lista plików | Czy źródło wskazuje plik tekstowy, który wyświetla listę plików do przetworzenia | nie | true lub false |
fileList |
| Kolumna do przechowywania nazwy pliku | Utwórz nową kolumnę z nazwą pliku źródłowego i ścieżką | nie | String | rowUrlColumn |
| Po zakończeniu | Usuń lub przenieś pliki po przetworzeniu. Ścieżka pliku rozpoczyna się od katalogu głównego kontenera | nie | Usuń: true lub false Ruszać: ['<from>', '<to>'] |
przeczyszczanie plików moveFiles |
| Filtruj według ostatniej modyfikacji | Wybierz filtrowanie plików w oparciu o czas ich ostatniej zmiany | nie | Sygnatura czasowa | modifiedAfter modifiedBefore |
| Pojedynczy dokument | Przepływy mapowania danych odczytują jeden dokument JSON z każdego pliku | nie | true lub false |
singleDocument |
| Nazwy kolumn bez cudzysłów | Jeśli wybrano nazwy kolumn bez cudzysłowów, przepływy danych mapowania odczytują kolumny JSON, które nie są otoczone cudzysłowami. | nie | true lub false |
unquotedColumnNames |
| Zawiera komentarze | Wybierz pozycję Ma komentarze , jeśli dane JSON mają komentarz w stylu C lub C++ | nie | true lub false |
asComments |
| Pojedyncze cytowane | Odczytuje kolumny JSON, które nie są otoczone cudzysłowami | nie | true lub false |
singleQuoted |
| Ukośnik odwrotny został uniknięci | Wybierz ukośnik odwrotny, jeśli ukośniki odwrotne są używane do ucieczki znaków w danych JSON | nie | true lub false |
ukośnik odwrotny |
| Zezwalaj na brak znalezionych plików | Jeśli wartość true, błąd nie jest zgłaszany, jeśli nie znaleziono żadnych plików | nie | true lub false |
ignoreNoFilesFound |
Wbudowany zestaw danych
Przepływy danych mapowania obsługują "wbudowane zestawy danych" jako opcję definiowania źródła i ujścia. Wbudowany zestaw danych JSON jest definiowany bezpośrednio wewnątrz przekształceń źródła i ujścia i nie jest udostępniany poza zdefiniowanym przepływem danych. Jest to przydatne w przypadku parametryzacji właściwości zestawu danych bezpośrednio wewnątrz przepływu danych i może korzystać z lepszej wydajności w przypadku udostępnionych zestawów danych usługi ADF.
Podczas odczytywania dużej liczby folderów źródłowych i plików można zwiększyć wydajność odnajdywania plików przepływu danych, ustawiając opcję "Projektowany schemat użytkownika" wewnątrz projekcji | Okno dialogowe Opcje schematu. Ta opcja powoduje wyłączenie domyślnego automatycznego odnajdywania schematu usługi ADF i znacznie poprawi wydajność odnajdywania plików. Przed ustawieniem tej opcji pamiętaj, aby zaimportować projekcję JSON, aby usługa ADF ma istniejący schemat do projekcji. Ta opcja nie działa z dryfem schematu.
Opcje formatu źródłowego
Użycie zestawu danych JSON jako źródła w przepływie danych umożliwia ustawienie pięciu dodatkowych ustawień. Te ustawienia można znaleźć w obszarze akordeonu ustawień JSON na karcie Opcje źródła. W przypadku ustawienia Formularz dokumentu można wybrać jeden z typów dokumentów Pojedynczy dokument, Dokument na wiersz i Tablica dokumentów .
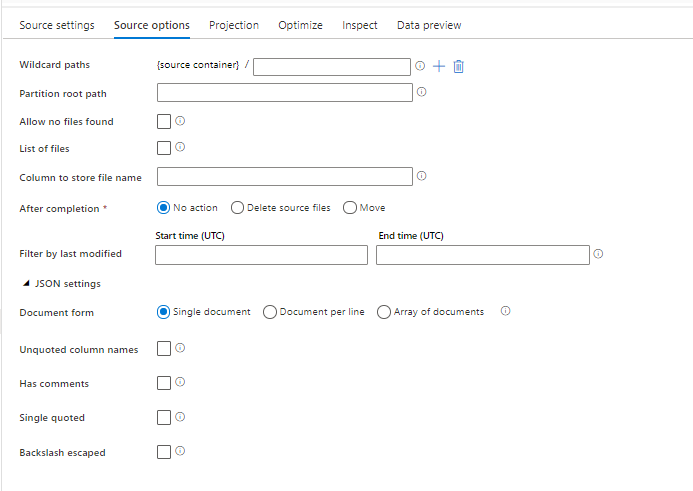
Wartość domyślna
Domyślnie dane JSON są odczytywane w następującym formacie.
{ "json": "record 1" }
{ "json": "record 2" }
{ "json": "record 3" }
Pojedynczy dokument
Jeśli wybrano pojedynczy dokument , przepływy mapowania danych odczytują jeden dokument JSON z każdego pliku.
File1.json
{
"json": "record 1"
}
File2.json
{
"json": "record 2"
}
File3.json
{
"json": "record 3"
}
Jeśli wybrano opcję Dokument na wiersz , mapowanie przepływów danych odczytuje jeden dokument JSON z każdego wiersza w pliku.
File1.json
{"json": "record 1"}
File2.json
{"time":"2015-04-29T07:12:20.9100000Z","callingimsi":"466920403025604","callingnum1":"678948008","callingnum2":"567834760","switch1":"China","switch2":"Germany"}
{"time":"2015-04-29T07:13:21.0220000Z","callingimsi":"466922202613463","callingnum1":"123436380","callingnum2":"789037573","switch1":"US","switch2":"UK"}
File3.json
{"time":"2015-04-29T07:12:20.9100000Z","callingimsi":"466920403025604","callingnum1":"678948008","callingnum2":"567834760","switch1":"China","switch2":"Germany"}
{"time":"2015-04-29T07:13:21.0220000Z","callingimsi":"466922202613463","callingnum1":"123436380","callingnum2":"789037573","switch1":"US","switch2":"UK"}
{"time":"2015-04-29T07:13:21.4370000Z","callingimsi":"466923101048691","callingnum1":"678901578","callingnum2":"345626404","switch1":"Germany","switch2":"UK"}
Jeśli wybrano tablicę dokumentów , przepływy mapowania danych odczytują jedną tablicę dokumentów z pliku.
File.json
[
{
"time": "2015-04-29T07:12:20.9100000Z",
"callingimsi": "466920403025604",
"callingnum1": "678948008",
"callingnum2": "567834760",
"switch1": "China",
"switch2": "Germany"
},
{
"time": "2015-04-29T07:13:21.0220000Z",
"callingimsi": "466922202613463",
"callingnum1": "123436380",
"callingnum2": "789037573",
"switch1": "US",
"switch2": "UK"
},
{
"time": "2015-04-29T07:13:21.4370000Z",
"callingimsi": "466923101048691",
"callingnum1": "678901578",
"callingnum2": "345626404",
"switch1": "Germany",
"switch2": "UK"
}
]
Uwaga
Jeśli przepływy danych zgłaszają błąd "corrupt_record" podczas wyświetlania podglądu danych JSON, prawdopodobnie dane zawierają pojedynczy dokument w pliku JSON. Ustawienie "pojedynczy dokument" powinno wyczyścić ten błąd.
Nazwy kolumn bez cudzysłów
Jeśli wybrano nazwy kolumn bez cudzysłowów, przepływy danych mapowania odczytują kolumny JSON, które nie są otoczone cudzysłowami.
{ json: "record 1" }
{ json: "record 2" }
{ json: "record 3" }
Zawiera komentarze
Wybierz pozycję Ma komentarze , jeśli dane JSON mają komentarz w stylu C lub C++.
{ "json": /** comment **/ "record 1" }
{ "json": "record 2" }
{ /** comment **/ "json": "record 3" }
Pojedyncze cytowane
Wybierz pozycję Pojedynczy cudzysłów , jeśli pola i wartości JSON używają cudzysłowów pojedynczych zamiast cudzysłowów podwójnych.
{ 'json': 'record 1' }
{ 'json': 'record 2' }
{ 'json': 'record 3' }
Ukośnik odwrotny został uniknięci
Wybierz pozycję Ukośnik odwrotny, jeśli ukośniki odwrotne są używane do ucieczki znaków w danych JSON.
{ "json": "record 1" }
{ "json": "\} \" \' \\ \n \\n record 2" }
{ "json": "record 3" }
Właściwości ujścia
W poniższej tabeli wymieniono właściwości obsługiwane przez ujście json. Te właściwości można edytować na karcie Ustawienia .
| Nazwa/nazwisko | opis | Wymagania | Dozwolone wartości | Właściwość skryptu przepływu danych |
|---|---|---|---|---|
| Wyczyść folder | Jeśli folder docelowy zostanie wyczyszczone przed zapisem | nie | true lub false |
truncate |
| Opcja Nazwa pliku | Format nazewnictwa zapisanych danych. Domyślnie jeden plik na partycję w formacie part-#####-tid-<guid> |
nie | Wzorzec: ciąg Na partycję: Ciąg[] Jako dane w kolumnie: Ciąg Dane wyjściowe do pojedynczego pliku: ['<fileName>'] |
filePattern partitionFileNames rowUrlColumn partitionFileNames |
Tworzenie struktur JSON w kolumnie pochodnej
Do przepływu danych można dodać złożoną kolumnę za pomocą konstruktora wyrażeń kolumn pochodnych. W transformacji kolumny pochodnej dodaj nową kolumnę i otwórz konstruktora wyrażeń, klikając niebieskie pole. Aby utworzyć złożone kolumny, możesz ręcznie wprowadzić strukturę JSON lub użyć środowiska użytkownika, aby interaktywnie dodać podkolumny.
Korzystanie z środowiska użytkownika konstruktora wyrażeń
W okienku po stronie schematu wyjściowego umieść kursor nad kolumną i kliknij ikonę znaku plus. Wybierz pozycję Dodaj kolumnę podrzędną, aby utworzyć kolumnę typu złożonego.
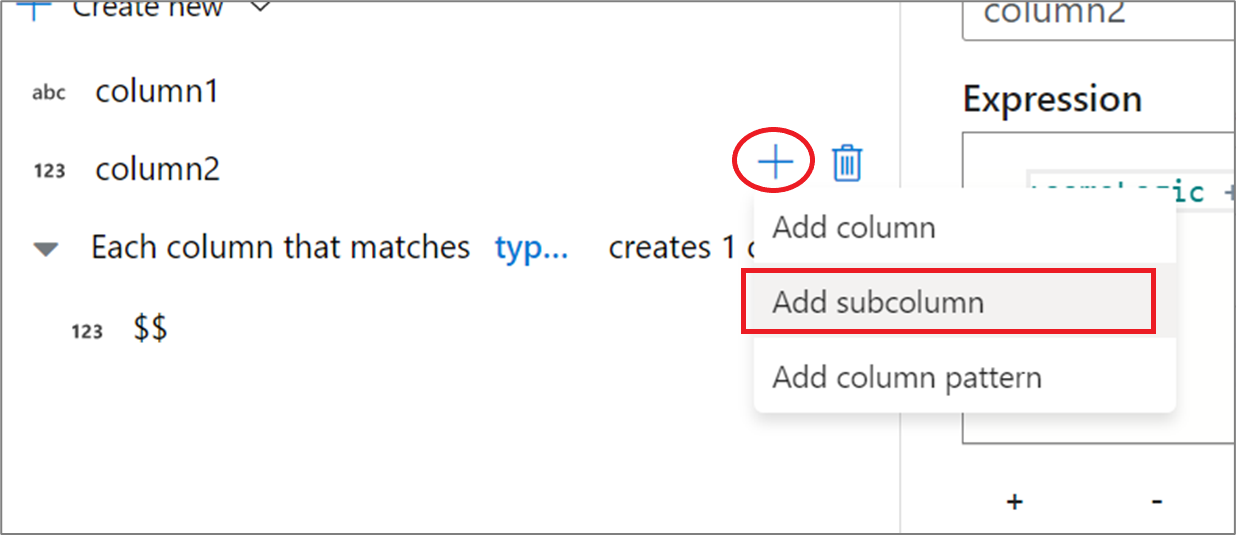
Możesz dodać dodatkowe kolumny i podkolumny w taki sam sposób. Dla każdego niezwiązanego pola wyrażenie można dodać w edytorze wyrażeń po prawej stronie.
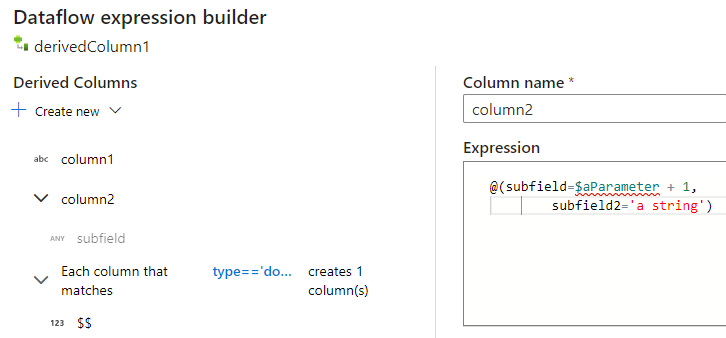
Ręczne wprowadzanie struktury JSON
Aby ręcznie dodać strukturę JSON, dodaj nową kolumnę i wprowadź wyrażenie w edytorze. Wyrażenie ma następujący format ogólny:
@(
field1=0,
field2=@(
field1=0
)
)
Jeśli to wyrażenie zostało wprowadzone dla kolumny o nazwie "complexColumn", zostanie ono zapisane w ujściu jako następujący kod JSON:
{
"complexColumn": {
"field1": 0,
"field2": {
"field1": 0
}
}
}
Przykładowy skrypt ręczny dla pełnej definicji hierarchicznej
@(
title=Title,
firstName=FirstName,
middleName=MiddleName,
lastName=LastName,
suffix=Suffix,
contactDetails=@(
email=EmailAddress,
phone=Phone
),
address=@(
line1=AddressLine1,
line2=AddressLine2,
city=City,
state=StateProvince,
country=CountryRegion,
postCode=PostalCode
),
ids=[
toString(CustomerID), toString(AddressID), rowguid
]
)
Powiązane łączniki i formaty
Poniżej przedstawiono niektóre typowe łączniki i formaty związane z formatem JSON: