Odporność na uszkodzenia działania kopiowania w potokach usług Azure Data Factory i Synapse Analytics
DOTYCZY:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
Podczas kopiowania danych ze źródła do magazynu docelowego działanie kopiowania zapewnia określony poziom odporności na uszkodzenia, aby zapobiec przerwom w działaniu przenoszenia danych. Na przykład kopiujesz miliony wierszy ze źródłowego do magazynu docelowego, w którym utworzono klucz podstawowy w docelowej bazie danych, ale źródłowa baza danych nie ma zdefiniowanych kluczy podstawowych. W przypadku kopiowania zduplikowanych wierszy ze źródła do miejsca docelowego wystąpi błąd naruszenia PK w docelowej bazie danych. W tej chwili działanie kopiowania oferuje dwa sposoby obsługi takich błędów:
- Działanie kopiowania można przerwać po napotkaniu dowolnego błędu.
- Możesz nadal kopiować resztę, włączając odporność na uszkodzenia, aby pominąć niezgodne dane. Na przykład pomiń zduplikowany wiersz w tym przypadku. Ponadto można rejestrować pominięte dane, włączając dziennik sesji w ramach działania kopiowania. Więcej szczegółów można znaleźć w działaniu kopiowania w dzienniku sesji.
Kopiowanie plików binarnych
Usługa obsługuje następujące scenariusze odporności na uszkodzenia podczas kopiowania plików binarnych. Możesz przerwać działanie kopiowania lub kontynuować kopiowanie reszty w następujących scenariuszach:
- Pliki, które mają być kopiowane przez usługę, są usuwane przez inne aplikacje w tym samym czasie.
- Niektóre określone foldery lub pliki nie zezwalają na dostęp do usługi, ponieważ listy ACL tych plików lub folderów wymagają wyższego poziomu uprawnień niż skonfigurowane informacje o połączeniu.
- Co najmniej jeden plik nie jest weryfikowany tak, aby był spójny między magazynem źródłowym i docelowym, jeśli włączysz ustawienie weryfikacji spójności danych.
Włączanie odporności na uszkodzenia za pomocą interfejsu użytkownika
Aby skonfigurować odporność na uszkodzenia w działanie Kopiuj w potoku za pomocą interfejsu użytkownika, wykonaj następujące kroki:
Jeśli nie utworzono już działanie Kopiuj dla potoku, wyszukaj pozycję Kopiuj w okienku Działania potoku i przeciągnij działanie Kopiuj dane do kanwy potoku.
Wybierz nowe działanie Kopiuj dane na kanwie, jeśli nie zostało jeszcze wybrane, a karta Ustawienia , aby skonfigurować odporność na uszkodzenia.
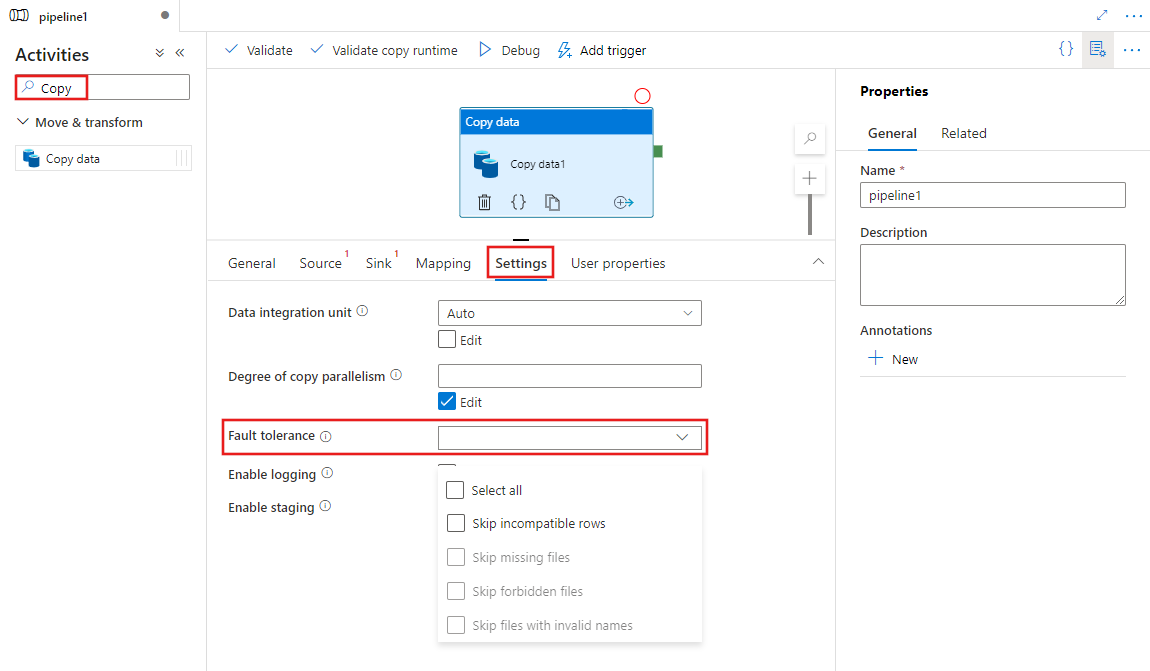
Konfigurowanie
Podczas kopiowania plików binarnych między magazynami magazynu można włączyć odporność na uszkodzenia w następujący sposób:
{
"name": "CopyActivityFaultTolerance",
"type": "Copy",
"typeProperties": {
"source": {
"type": "BinarySource",
"storeSettings": {
"type": "AzureDataLakeStoreReadSettings",
"recursive": true
}
},
"sink": {
"type": "BinarySink",
"storeSettings": {
"type": "AzureDataLakeStoreWriteSettings"
}
},
"skipErrorFile": {
"fileMissing": true,
"fileForbidden": true,
"dataInconsistency": true,
"invalidFileName": true
},
"validateDataConsistency": true,
"logSettings": {
"enableCopyActivityLog": true,
"copyActivityLogSettings": {
"logLevel": "Warning",
"enableReliableLogging": false
},
"logLocationSettings": {
"linkedServiceName": {
"referenceName": "ADLSGen2",
"type": "LinkedServiceReference"
},
"path": "sessionlog/"
}
}
}
}
| Właściwości | opis | Dozwolone wartości | Wymagania |
|---|---|---|---|
| skipErrorFile | Grupa właściwości określających typy niepowodzeń, które mają zostać pominięte podczas przenoszenia danych. | Nie. | |
| fileMissing | Jedna z par klucz-wartość w worku właściwości skipErrorFile, aby określić, czy chcesz pominąć pliki, które są usuwane przez inne aplikacje w czasie wykonywania operacji kopiowania przez usługę. -True: chcesz skopiować resztę, pomijając pliki usuwane przez inne aplikacje. - Fałsz: chcesz przerwać działanie kopiowania po usunięciu wszystkich plików z magazynu źródłowego w środku przenoszenia danych. Należy pamiętać, że ta właściwość jest ustawiona na wartość true jako domyślną. |
True(wartość domyślna) Fałsz |
Nie. |
| fileForbidden | Jedna z par klucz-wartość w worku właściwości skipErrorFile, aby określić, czy chcesz pominąć określone pliki, gdy listy ACL tych plików lub folderów wymagają wyższego poziomu uprawnień niż skonfigurowane połączenie. -True: chcesz skopiować resztę, pomijając pliki. - Fałsz: chcesz przerwać działanie kopiowania po otrzymaniu problemu z uprawnieniami w folderach lub plikach. |
Prawda False(wartość domyślna) |
Nie. |
| dataInconsistency | Jedna z par klucz-wartość w torbie właściwości skipErrorFile, aby określić, czy chcesz pominąć niespójne dane między magazynem źródłowym i docelowym. -True: chcesz skopiować resztę, pomijając niespójne dane. - Fałsz: chcesz przerwać działanie kopiowania po znalezieniu niespójnych danych. Należy pamiętać, że ta właściwość jest prawidłowa tylko po ustawieniu wartości validateDataConsistency na wartość True. |
Prawda False(wartość domyślna) |
Nie. |
| invalidFileName | Jedna z par klucz-wartość w torbie właściwości skipErrorFile, aby określić, czy chcesz pominąć określone pliki, gdy nazwy plików są nieprawidłowe dla magazynu docelowego. -True: chcesz skopiować resztę, pomijając pliki o nieprawidłowych nazwach plików. - Fałsz: chcesz przerwać działanie kopiowania, gdy wszystkie pliki mają nieprawidłowe nazwy plików. Należy pamiętać, że ta właściwość działa podczas kopiowania plików binarnych z dowolnego magazynu do usługi ADLS Gen2 lub kopiowania plików binarnych z usługi AWS S3 tylko do dowolnego magazynu. |
Prawda False(wartość domyślna) |
Nie. |
| logSettings | Grupa właściwości, które można określić, gdy chcesz zarejestrować pominięte nazwy obiektów. | Nie. | |
| linkedServiceName | Połączona usługa usługi Azure Blob Storage lub Azure Data Lake Storage Gen2 do przechowywania plików dziennika sesji. | Nazwy połączonej AzureBlobStorage usługi lub AzureBlobFS typu odwołujące się do wystąpienia używanego do przechowywania pliku dziennika. |
Nie. |
| path | Ścieżka plików dziennika. | Określ ścieżkę używaną do przechowywania plików dziennika. Jeśli nie podasz ścieżki, usługa utworzy kontener. | Nie. |
Uwaga
Poniżej przedstawiono wymagania wstępne dotyczące włączania odporności na uszkodzenia w działaniu kopiowania podczas kopiowania plików binarnych. Aby pominąć określone pliki po usunięciu z magazynu źródłowego:
- Źródłowy zestaw danych i zestaw danych ujścia muszą być formatem binarnym, a nie można określić typu kompresji.
- Obsługiwane typy magazynów danych to Azure Blob Storage, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2, Azure Files, File System, FTP, SFTP, Amazon S3, Google Cloud Storage i HDFS.
- Tylko wtedy, gdy określisz wiele plików w źródłowym zestawie danych, który może być folderem, symbolem wieloznacznymi lub listą plików, działanie kopiowania może pominąć określone pliki błędów. Jeśli w źródłowym zestawie danych zostanie określony pojedynczy plik do skopiowania do miejsca docelowego, działanie kopiowania zakończy się niepowodzeniem w przypadku wystąpienia jakiegokolwiek błędu.
W przypadku pomijania określonych plików, gdy dostęp do tych plików jest zabroniony z magazynu źródłowego:
- Źródłowy zestaw danych i zestaw danych ujścia muszą być formatem binarnym, a nie można określić typu kompresji.
- Obsługiwane typy magazynów danych to Azure Blob Storage, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2, Azure Files, SFTP, Amazon S3 i HDFS.
- Tylko wtedy, gdy określisz wiele plików w źródłowym zestawie danych, który może być folderem, symbolem wieloznacznymi lub listą plików, działanie kopiowania może pominąć określone pliki błędów. Jeśli w źródłowym zestawie danych zostanie określony pojedynczy plik do skopiowania do miejsca docelowego, działanie kopiowania zakończy się niepowodzeniem w przypadku wystąpienia jakiegokolwiek błędu.
Aby pominąć określone pliki, gdy są weryfikowane jako niespójne między magazynem źródłowym i docelowym:
- Więcej szczegółów można znaleźć w doc spójności danych tutaj.
Monitorowanie
Dane wyjściowe z działania kopiowania
Liczbę plików odczytywanych, zapisywanych i pomijanych można uzyskać za pośrednictwem danych wyjściowych każdego uruchomienia działania kopiowania.
"output": {
"dataRead": 695,
"dataWritten": 186,
"filesRead": 3,
"filesWritten": 1,
"filesSkipped": 2,
"throughput": 297,
"logFilePath": "myfolder/a84bf8d4-233f-4216-8cb5-45962831cd1b/",
"dataConsistencyVerification":
{
"VerificationResult": "Verified",
"InconsistentData": "Skipped"
}
}
Dziennik sesji z działania kopiowania
Jeśli skonfigurujesz rejestrowanie pominiętych nazw plików, możesz znaleźć plik dziennika z tej ścieżki: https://[your-blob-account].blob.core.windows.net/[path-if-configured]/copyactivity-logs/[copy-activity-name]/[copy-activity-run-id]/[auto-generated-GUID].csv.
Pliki dziennika muszą być plikami csv. Schemat pliku dziennika jest następujący:
| Kolumna | opis |
|---|---|
| Sygnatura czasowa | Sygnatura czasowa po pominiętiu pliku. |
| Poziom | Poziom dziennika tego elementu. Będzie on na poziomie "Ostrzeżenie" dla elementu pokazującego pomijanie pliku. |
| OperationName | działanie Kopiuj zachowanie operacyjne dla każdego pliku. Będzie on mieć wartość "FileSkip", aby określić plik, który ma zostać pominięty. |
| OperationItem | Nazwy plików, które mają zostać pominięte. |
| Komunikat | Więcej informacji ilustrujących, dlaczego plik jest pomijany. |
Przykład pliku dziennika jest następujący:
Timestamp,Level,OperationName,OperationItem,Message
2020-03-24 05:35:41.0209942,Warning,FileSkip,"bigfile.csv","File is skipped after read 322961408 bytes: ErrorCode=UserErrorSourceBlobNotExist,'Type=Microsoft.DataTransfer.Common.Shared.HybridDeliveryException,Message=The required Blob is missing. ContainerName: https://transferserviceonebox.blob.core.windows.net/skipfaultyfile, path: bigfile.csv.,Source=Microsoft.DataTransfer.ClientLibrary,'."
2020-03-24 05:38:41.2595989,Warning,FileSkip,"3_nopermission.txt","File is skipped after read 0 bytes: ErrorCode=AdlsGen2OperationFailed,'Type=Microsoft.DataTransfer.Common.Shared.HybridDeliveryException,Message=ADLS Gen2 operation failed for: Operation returned an invalid status code 'Forbidden'. Account: 'adlsgen2perfsource'. FileSystem: 'skipfaultyfilesforbidden'. Path: '3_nopermission.txt'. ErrorCode: 'AuthorizationPermissionMismatch'. Message: 'This request is not authorized to perform this operation using this permission.'. RequestId: '35089f5d-101f-008c-489e-01cce4000000'..,Source=Microsoft.DataTransfer.ClientLibrary,''Type=Microsoft.DataTransfer.Common.Shared.HybridDeliveryException,Message=Operation returned an invalid status code 'Forbidden',Source=,''Type=Microsoft.Azure.Storage.Data.Models.ErrorSchemaException,Message='Type=Microsoft.Azure.Storage.Data.Models.ErrorSchemaException,Message=Operation returned an invalid status code 'Forbidden',Source=Microsoft.DataTransfer.ClientLibrary,',Source=Microsoft.DataTransfer.ClientLibrary,'."
W powyższym dzienniku można zobaczyć, bigfile.csv został pominięty z powodu usunięcia tego pliku przez inną aplikację podczas kopiowania go przez usługę. I 3_nopermission.txt został pominięty, ponieważ usługa nie może uzyskać do niej dostępu z powodu problemu z uprawnieniami.
Kopiowanie danych tabelarycznych
Obsługiwane scenariusze
działanie Kopiuj obsługuje trzy scenariusze wykrywania, pomijania i rejestrowania niezgodnych danych tabelarycznych:
Niezgodność między typem danych źródłowych a typem natywnym ujścia.
Na przykład: Skopiuj dane z pliku CSV w usłudze Blob Storage do bazy danych SQL z definicją schematu zawierającą trzy kolumny typu INT. Wiersze pliku CSV zawierające dane liczbowe, takie jak 123 456 789, są pomyślnie kopiowane do magazynu ujścia. Jednak wiersze zawierające wartości nieliczbowe, takie jak 123 456, abc są wykrywane jako niezgodne i pomijane.
Niezgodność liczby kolumn między źródłem a ujściem.
Na przykład: Kopiowanie danych z pliku CSV w usłudze Blob Storage do bazy danych SQL z definicją schematu zawierającą sześć kolumn. Wiersze pliku CSV zawierające sześć kolumn zostały pomyślnie skopiowane do magazynu ujścia. Wiersze pliku CSV zawierające więcej niż sześć kolumn są wykrywane jako niezgodne i pomijane.
Naruszenie klucza podstawowego podczas zapisywania w usłudze SQL Server/Azure SQL Database/Azure Cosmos DB.
Na przykład: Kopiowanie danych z serwera SQL do bazy danych SQL. Klucz podstawowy jest zdefiniowany w ujściu bazy danych SQL, ale taki klucz podstawowy nie jest zdefiniowany na źródłowym serwerze SQL. Nie można skopiować zduplikowanych wierszy w źródle do ujścia. działanie Kopiuj kopiuje tylko pierwszy wiersz danych źródłowych do ujścia. Kolejne wiersze źródłowe zawierające zduplikowaną wartość klucza podstawowego są wykrywane jako niezgodne i pomijane.
Uwaga
- Aby załadować dane do usługi Azure Synapse Analytics przy użyciu technologii PolyBase, skonfiguruj ustawienia natywnej odporności na uszkodzenia technologii PolyBase, określając zasady odrzucania za pomocą funkcji "polyBaseSettings" w działaniu kopiowania. Nadal można włączyć przekierowywanie niezgodnych wierszy programu PolyBase do usługi Blob lub ADLS w normalny sposób, jak pokazano poniżej.
- Ta funkcja nie ma zastosowania, gdy działanie kopiowania jest skonfigurowane do wywoływania funkcji Amazon Redshift Unload.
- Ta funkcja nie ma zastosowania, gdy działanie kopiowania jest skonfigurowane do wywoływania procedury składowanej z ujścia SQL lub użycia operacji Upsert do zapisywania danych w ujściu SQL.
Konfigurowanie
Poniższy przykład zawiera definicję JSON w celu skonfigurowania pomijania niezgodnych wierszy w działaniu kopiowania:
"typeProperties": {
"source": {
"type": "AzureSqlSource"
},
"sink": {
"type": "AzureSqlSink"
},
"enableSkipIncompatibleRow": true,
"logSettings": {
"enableCopyActivityLog": true,
"copyActivityLogSettings": {
"logLevel": "Warning",
"enableReliableLogging": false
},
"logLocationSettings": {
"linkedServiceName": {
"referenceName": "ADLSGen2",
"type": "LinkedServiceReference"
},
"path": "sessionlog/"
}
}
},
| Właściwości | opis | Dozwolone wartości | Wymagania |
|---|---|---|---|
| enableSkipIncompatibleRow | Określa, czy pomijać niezgodne wiersze podczas kopiowania, czy nie. | Prawda False (domyślnie) |
Nie. |
| logSettings | Grupa właściwości, które można określić, gdy chcesz zarejestrować niezgodne wiersze. | Nie. | |
| linkedServiceName | Połączona usługa usługi Azure Blob Storage lub Azure Data Lake Storage Gen2 do przechowywania dziennika zawierającego pominięte wiersze. | Nazwy połączonej AzureBlobStorage usługi lub AzureBlobFS typu odwołujące się do wystąpienia używanego do przechowywania pliku dziennika. |
Nie. |
| path | Ścieżka plików dziennika, które zawierają pominięte wiersze. | Określ ścieżkę, której chcesz użyć do rejestrowania niezgodnych danych. Jeśli nie podasz ścieżki, usługa utworzy kontener. | Nie. |
Monitorowanie pominiętych wierszy
Po zakończeniu działania kopiowania można zobaczyć liczbę pominiętych wierszy w danych wyjściowych działania kopiowania:
"output": {
"dataRead": 95,
"dataWritten": 186,
"rowsCopied": 9,
"rowsSkipped": 2,
"copyDuration": 16,
"throughput": 0.01,
"logFilePath": "myfolder/a84bf8d4-233f-4216-8cb5-45962831cd1b/",
"errors": []
},
Jeśli skonfigurujesz rejestrowanie niezgodnych wierszy, możesz znaleźć plik dziennika z tej ścieżki: https://[your-blob-account].blob.core.windows.net/[path-if-configured]/copyactivity-logs/[copy-activity-name]/[copy-activity-run-id]/[auto-generated-GUID].csv.
Pliki dziennika będą plikami csv. Schemat pliku dziennika jest następujący:
| Kolumna | opis |
|---|---|
| Sygnatura czasowa | Sygnatura czasowa pomijania niezgodnych wierszy |
| Poziom | Poziom dziennika tego elementu. Będzie on na poziomie "Ostrzeżenie", jeśli ten element pokazuje pominięte wiersze |
| OperationName | działanie Kopiuj zachowanie operacyjne w każdym wierszu. Będzie to "TabelarycznyRowSkip", aby określić, że określony niezgodny wiersz został pominięty |
| OperationItem | Pominięte wiersze ze źródłowego magazynu danych. |
| Komunikat | Więcej informacji ilustrujących, dlaczego niezgodność tego określonego wiersza. |
Przykład zawartości pliku dziennika wygląda następująco:
Timestamp, Level, OperationName, OperationItem, Message
2020-02-26 06:22:32.2586581, Warning, TabularRowSkip, """data1"", ""data2"", ""data3""," "Column 'Prop_2' contains an invalid value 'data3'. Cannot convert 'data3' to type 'DateTime'."
2020-02-26 06:22:33.2586351, Warning, TabularRowSkip, """data4"", ""data5"", ""data6"",", "Violation of PRIMARY KEY constraint 'PK_tblintstrdatetimewithpk'. Cannot insert duplicate key in object 'dbo.tblintstrdatetimewithpk'. The duplicate key value is (data4)."
W powyższym przykładowym pliku dziennika widać, że jeden wiersz "data1, data2, data3" został pominięty z powodu problemu z konwersją typu ze źródła do magazynu docelowego. Inny wiersz "data4, data5, data6" został pominięty z powodu problemu z naruszeniem klucza PK ze źródła do magazynu docelowego.
Kopiowanie danych tabelarycznych (starsza wersja):
Poniższe podejście to starszy sposób włączania odporności na uszkodzenia tylko do kopiowania danych tabelarycznych. Jeśli tworzysz nowy potok lub działanie, zachęcamy do rozpoczęcia od tego miejsca .
Konfigurowanie
Poniższy przykład zawiera definicję JSON w celu skonfigurowania pomijania niezgodnych wierszy w działaniu kopiowania:
"typeProperties": {
"source": {
"type": "BlobSource"
},
"sink": {
"type": "SqlSink",
},
"enableSkipIncompatibleRow": true,
"redirectIncompatibleRowSettings": {
"linkedServiceName": {
"referenceName": "<Azure Storage or Data Lake Store linked service>",
"type": "LinkedServiceReference"
},
"path": "redirectcontainer/erroroutput"
}
}
| Właściwości | opis | Dozwolone wartości | Wymagania |
|---|---|---|---|
| enableSkipIncompatibleRow | Określa, czy pomijać niezgodne wiersze podczas kopiowania, czy nie. | Prawda False (domyślnie) |
Nie. |
| redirectIncompatibleRowSettings | Grupa właściwości, które można określić, gdy chcesz zarejestrować niezgodne wiersze. | Nie. | |
| linkedServiceName | Połączona usługa usługi Azure Storage lub Azure Data Lake Store do przechowywania dziennika zawierającego pominięte wiersze. | Nazwy połączonej AzureStorage usługi lub AzureDataLakeStore typu odwołujące się do wystąpienia, którego chcesz użyć do przechowywania pliku dziennika. |
Nie. |
| path | Ścieżka pliku dziennika zawierającego pominięte wiersze. | Określ ścieżkę, której chcesz użyć do rejestrowania niezgodnych danych. Jeśli nie podasz ścieżki, usługa utworzy kontener. | Nie. |
Monitorowanie pominiętych wierszy
Po zakończeniu działania kopiowania można zobaczyć liczbę pominiętych wierszy w danych wyjściowych działania kopiowania:
"output": {
"dataRead": 95,
"dataWritten": 186,
"rowsCopied": 9,
"rowsSkipped": 2,
"copyDuration": 16,
"throughput": 0.01,
"redirectRowPath": "https://myblobstorage.blob.core.windows.net//myfolder/a84bf8d4-233f-4216-8cb5-45962831cd1b/",
"errors": []
},
Jeśli skonfigurujesz rejestrowanie niezgodnych wierszy, możesz znaleźć plik dziennika w następującej ścieżce: https://[your-blob-account].blob.core.windows.net/[path-if-configured]/[copy-activity-run-id]/[auto-generated-GUID].csv.
Pliki dziennika mogą być tylko plikami csv. W razie potrzeby oryginalne dane, które są pomijane, zostaną zarejestrowane przy użyciu przecinka jako ogranicznika kolumn. Dodamy jeszcze dwie kolumny "ErrorCode" i "ErrorMessage" w dodatku do oryginalnych danych źródłowych w pliku dziennika, gdzie można zobaczyć główną przyczynę niezgodności. Kod błędu i errorMessage będą cytowane za pomocą podwójnych cudzysłowów.
Przykład zawartości pliku dziennika wygląda następująco:
data1, data2, data3, "UserErrorInvalidDataValue", "Column 'Prop_2' contains an invalid value 'data3'. Cannot convert 'data3' to type 'DateTime'."
data4, data5, data6, "2627", "Violation of PRIMARY KEY constraint 'PK_tblintstrdatetimewithpk'. Cannot insert duplicate key in object 'dbo.tblintstrdatetimewithpk'. The duplicate key value is (data4)."
Powiązana zawartość
Zobacz inne artykuły dotyczące działań kopiowania: