本机 GPU 围栏对象
本文介绍 GPU 围栏同步对象,该对象可用于 GPU 硬件计划阶段 2 中真正的 GPU 到 GPU 同步。 从 Windows 11 版本 24H2 (WDDM 3.2) 开始支持此功能。 图形驱动程序开发人员应熟悉 WDDM 2.0 和 GPU 硬件计划阶段 1。
WDDM 2.x 的受监视围栏同步对象
WDDM 2.x 的受监视的围栏同步对象支持以下操作:
- CPU 在受监视的围栏值上等待,方法是:
- 使用 CPU 虚拟地址 (VA) 轮询。
- 在 Dxgkrnl 内排队等待阻止,当 CPU 观察到新的受监视围栏值时,会发出信号。
- 受监视值的 CPU 信号。
- 通过写入受监视围栏 GPU VA,并引发受监视围栏信号中断,通知 CPU 值更新,从而获得受监视值的 GPU 信号。
不支持的是本机 ON-GPU 等待受监视的围栏值。 相反,OS 保留的 GPU 工作取决于 CPU 上的等待值。 仅当发出值信号时,它才会将此工作发布到 GPU。
添加了 GPU 本机围栏同步对象
从 WDDM 3.2 开始,监视的围栏对象已扩展,以支持以下新增功能:
- GPU 等待受监视的围栏值,这允许高性能引擎到引擎同步,而无需 CPU 往返。
- 有条件的中断通知只针对有 CPU 等待程序的 GPU 栅栏信号。 此功能允许 CPU 在所有 GPU 工作排队时进入低功率状态,从而节省大量电源。
- GPU 本地内存中的围栏值存储(而不是系统内存)。
GPU 本机围栏同步对象设计
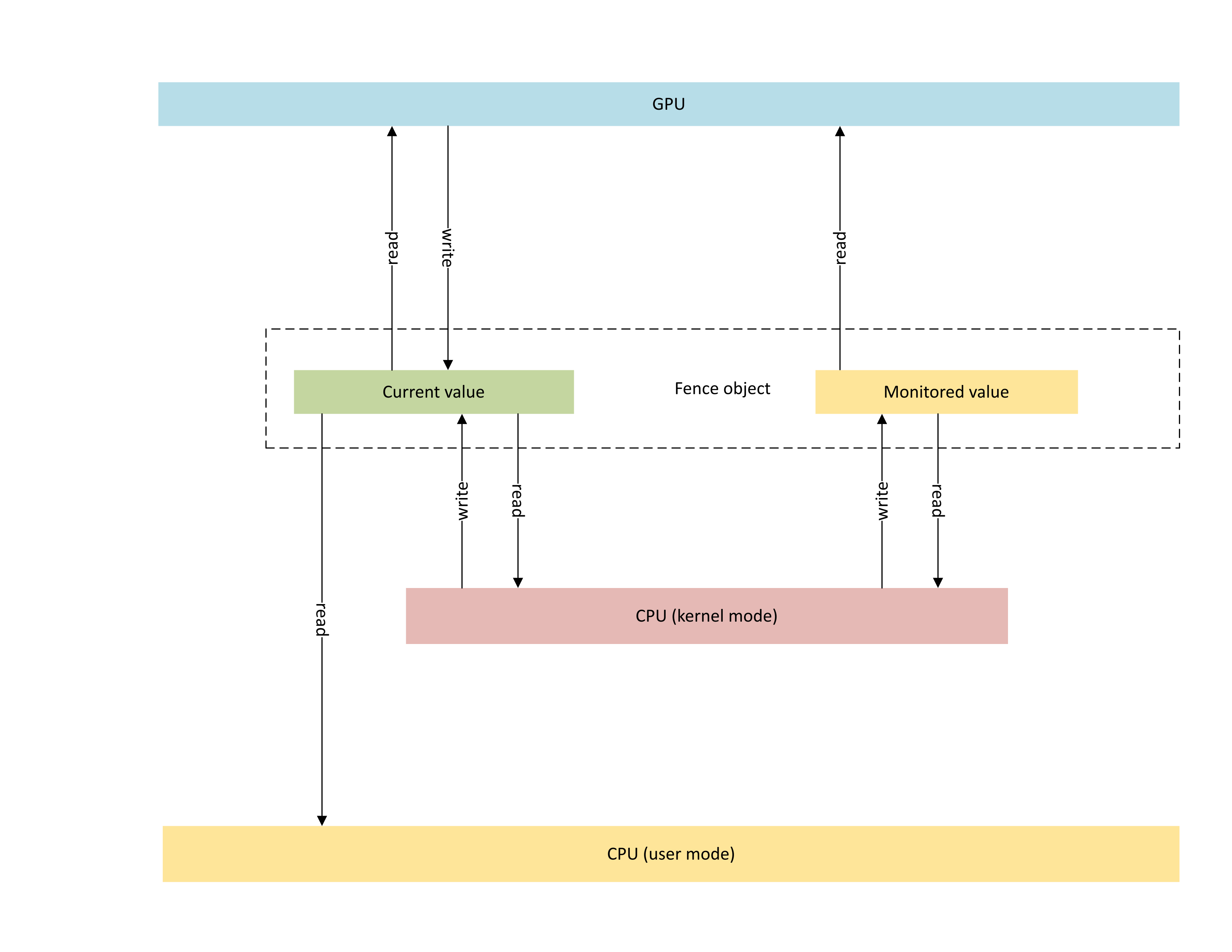
下图演示了 GPU 本机围栏对象的基本体系结构,重点介绍 CPU 和 GPU 之间共享的同步对象状态。
:
该示意图包括两个主要组成部分:
当前值(本文中称为 CurrentValue)。 此内存位置包含当前用信号发送的 64 位围栏值。 CurrentValue 被映射到 CPU 并可访问 CPU(可从内核模式写入、可从用户和内核模式读取)和 GPU(使用 GPU 虚拟地址可读和可写)。 CurrentValue 需要 64 位写入从 CPU 和 GPU 的角度来看都是原子的。 也就是说,对高 32 位和低 32 位的更新不能被破坏,并且应该同时可见。 此概念已存在于现有的受监视围栏对象中。
受监视的值(本文中称为 MonitoredValue)。 此内存位置包含 CPU 减去 1(1)的值当前等待的最小值。 MonitoredValue 被映射到 CPU 并可访问 CPU(可从内核模式读取和可写入、无用户模式访问)和 GPU(使用 GPU VA 读取,无写入访问权限)。 OS 维护给定围栏对象的未完成 CPU 等待程序列表,并在添加和删除等待程序时更新 MonitoredValue。 当没有未完成的等待程序时,该值将设置为 UINT64_MAX。 此概念是 GPU 本机围栏同步对象的新增概念。
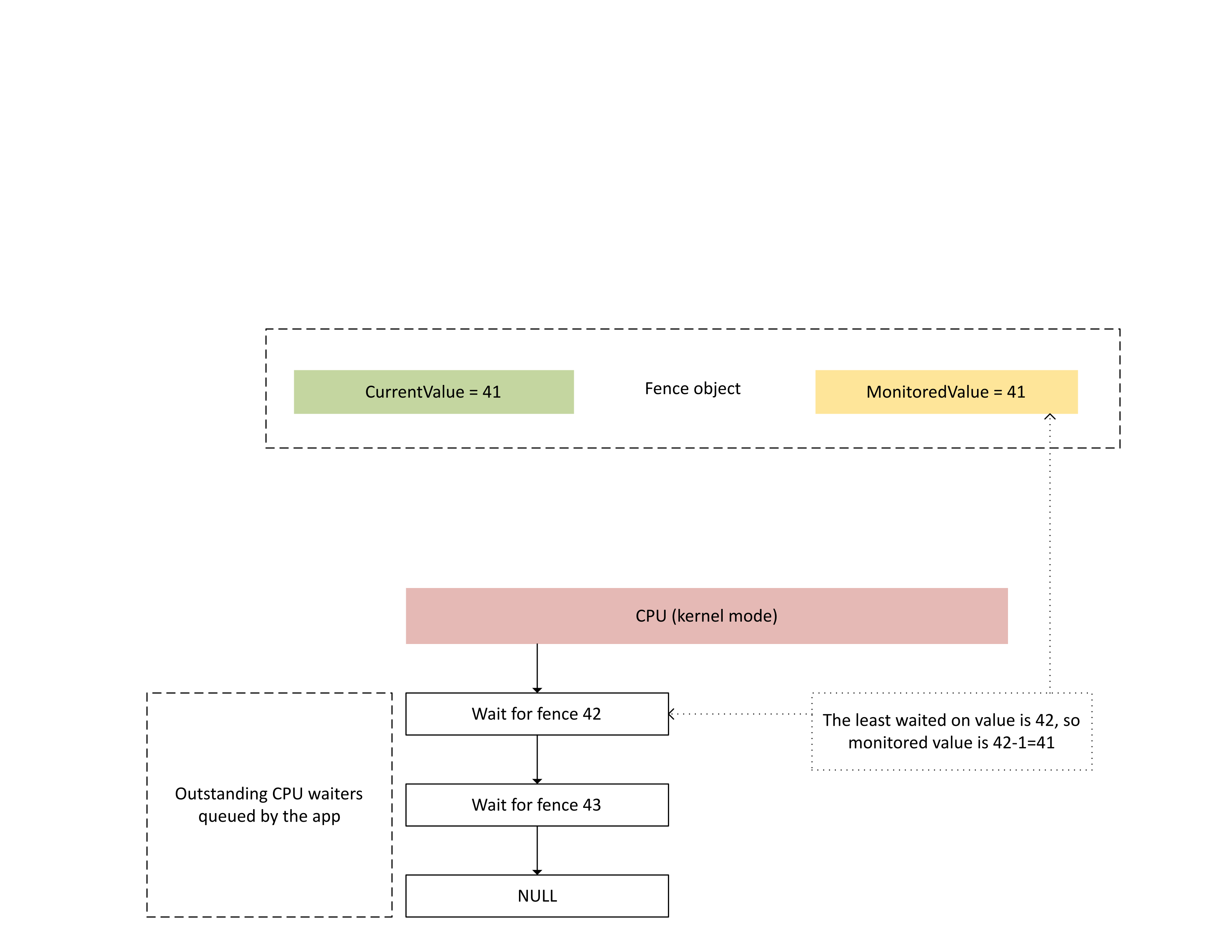
下图说明了 Dxgkrnl 如何在特定的受监视围栏值上跟踪未完成的 CPU 等待程序。 同时还显示了在给定时间点设置的受监视围栏值。 CurrentValue 和 MonitoredValue 均为 41,这意味着:
- GPU 完成了围栏值 41 之前的所有任务。
- CPU 未等待任何小于或等于 41 的围栏值。
:
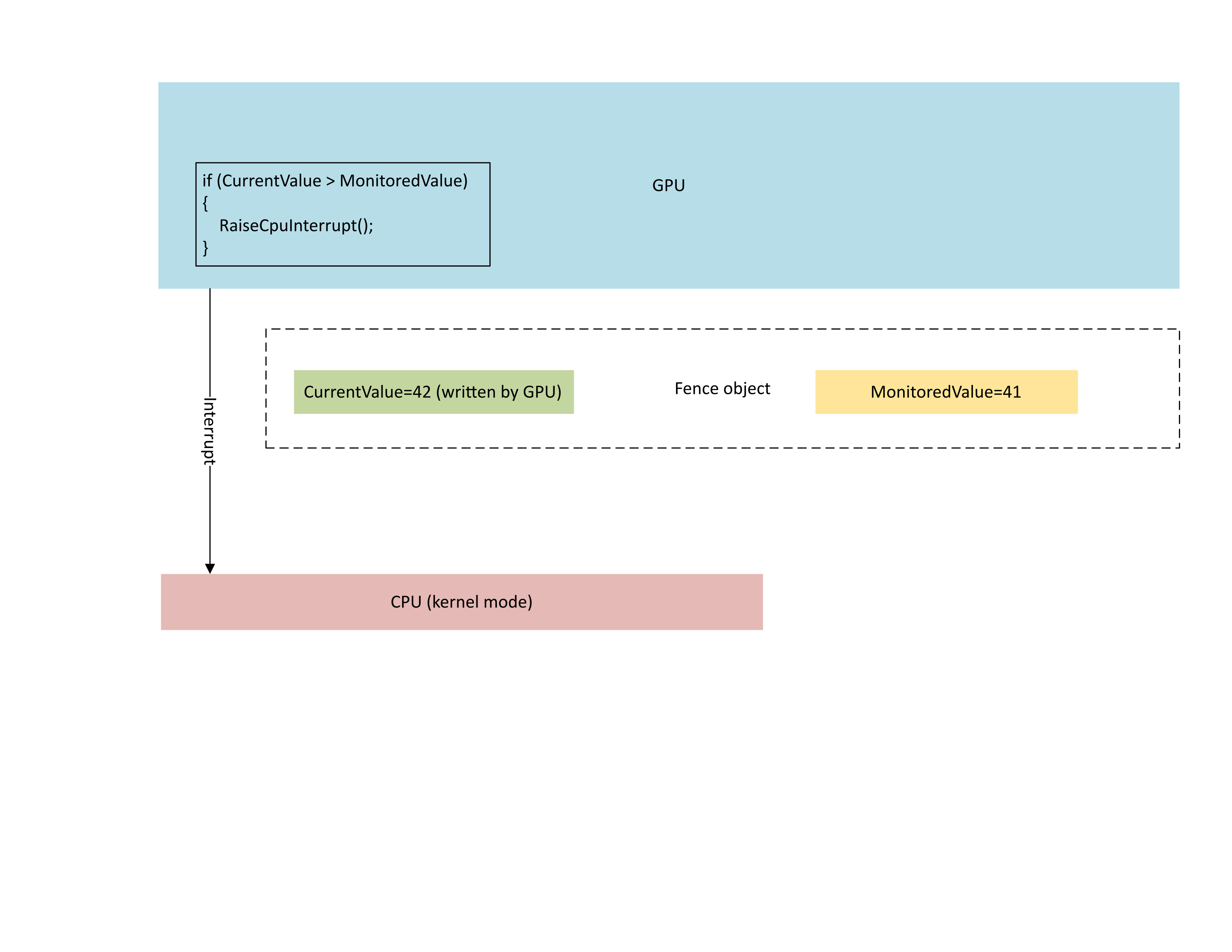
下图说明了 GPU 的上下文管理处理器 (CMP) 只有在新围栏值大于受监视值时才有条件地引发 CPU 中断。 这种中断意味着有未完成的 CPU 等待程序可以满足新写入的值。
:
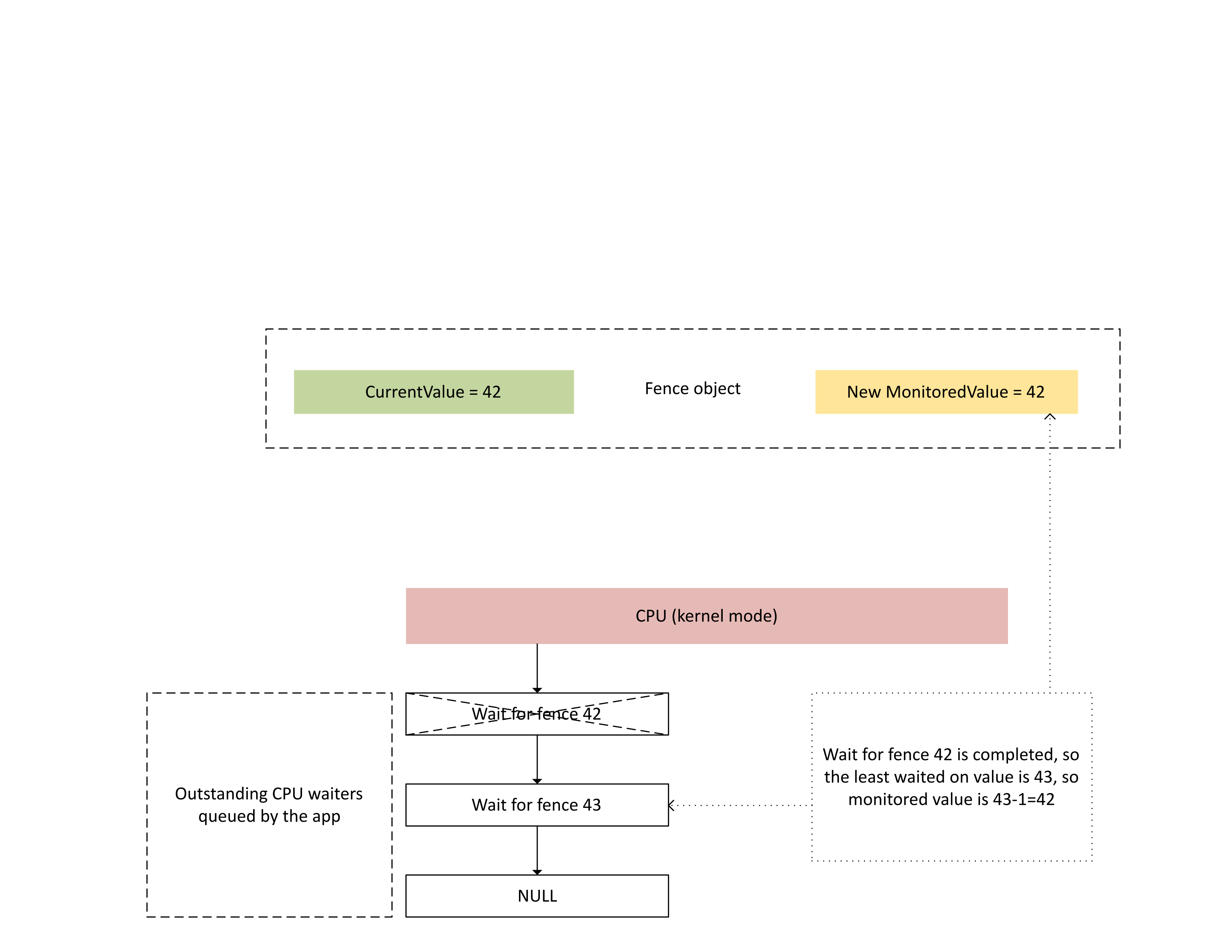
当 CPU 处理此中断时,Dxgkrnl 将执行如下图所示的操作:
- 它解除对新编写的围栏感到满意的 CPU 等待程序的锁定。
- 它将受监视的值向前推进,使其对应于等待时间最少的值减去 1。
:
用于当前值和受监视围栏值的物理内存存储
对于给定的围栏对象,CurrentValue 和 MonitoredValue 存储在不同的位置。
不可共享的围栏对象在同一内存页中为同一进程中的不同围栏对象存储围栏值。 这些值根据本文稍后所述的本机围栏 KMD 上限中指定的步幅值进行打包。
可共享的围栏对象将其当前值和受监视值放置在不与其他围栏对象共享的内存页中。
当前值
当前值可以驻留在系统内存或 GPU 本地内存中,具体取决于D3DDDI_NATIVEFENCE_TYPE指定的围栏类型。
跨适配器围栏的当前值始终位于系统内存中。
将当前值存储在系统内存中时,将从内部系统内存池分配存储。
将当前值存储在本地内存中时,将从驱动程序在D3DKMDT_FENCESTORAGESURFACEDATA中指定的内存段分配存储。
受监视的值
监视的值也可以驻留在系统或 GPU 本地内存中,具体取决于 D3DDDI_NATIVEFENCE_TYPE。
当受监视的值存储在系统内存中时,OS 将从内部系统内存池分配存储。
当受监视的值存储在本地内存中时,OS 将从D3DKMDT_FENCESTORAGESURFACEDATA中指定的驱动程序的内存段分配存储。
当 OS 的 CPU 等待条件发生更改时,它会调用 KMD 的 DxgkDdiUpdateMonitoredValues 回调,以指示 KMD 将监视的值更新为指定的值。
同步问题
上述机制在 CPU 和 GPU 读取和写入当前值与受监视的值之间具有固有的争用条件。 如果不特别注意,可能会出现以下问题:
- GPU 可以读取过时的 MonitoredValue,而不会像 CPU 预期的那样引发中断。
- GPU 引擎可以在 CMP 决定中断条件的过程中写入一个较新的 CurrentValue。 此较新的 CurrentValue 可能不会按预期引发中断,也可能在 CPU 获取当前值时不可见。
GPU 内引擎与 CMP 之间的同步
为了提高效率,许多离散 GPU 使用驻留在 GPU 本地内存中的阴影状态实现受监视的围栏信号语义:
GPU 引擎执行命令缓冲区流,并有条件地向 CMP 发出硬件信号。
决定是否应引发 CPU 中断的 GPU CMP。
在这种情况下,CMP 需要将内存访问与执行对围栏值的内存写入的 GPU 引擎同步。 具体而言,应从 CMP 角度对更新阴影 MonitoredValue 的操作进行排序:
- 编写新的 MonitoredValue (影子 GPU 存储)。
- 执行内存屏障以将内存访问与 GPU 引擎同步。
- 读取 CurrentValue:
- 如果 CurrentValue>MonitoredValue,则引发 CPU 中断。
- 如果 CurrentValue<= MonitoredValue,则不引发 CPU 中断。
为了正确解决这种争用条件,步骤 2 中的内存屏障必须正常运行。 在步骤 3 中,如果命令没有看到步骤 1 中 MonitoredValue 的更新,则不能出现对 CurrentValue 的内存写入操作。 如果步骤 3 中写入的围栏大于步骤 1 中更新的值,则这种情况将生成中断。
GPU 和 CPU 之间的同步
CPU 必须执行 MonitoredValue 的更新,并读取 CurrentValue,以确保不会丢失正在进行的信号中断通知。
- 当向系统中添加新的 CPU 等待程序时,或者如果现有的 CPU 等待程序失效时,OS 必须修改受监视的值。
- OS 调用 DxgkDdiUpdateMonitoredValues,以通知 GPU 新的受监视值。
- DxgkDdiUpdateMonitoredValue 在设备中断级别执行,因此与受监视的围栏信号中断服务例程 (ISR) 同步。
- DxgkDdiUpdateMonitoredValue 必须保证,在它返回后,任何处理器核心读取的 CurrentValue 都是在观察到新的 MonitoredValue 后由 GPU CMP 写入的。
- 从 DxgkDdiUpdateMonitoredValue 返回后,OS 将对 CurrentValue 进行重新采样,并满足被新的 CurrentValue 取消阻止的任何等待程序。
对于 CPU 来说,观察一个比 GPU 用来决定是否引发中断的 CurrentValue 更新的值是完全可以接受的。 这种情况偶尔会导致中断通知,但不会解除对任何等待程序的阻止。 无法接受的是,CPU 没有收到受监视的最新 CurrentValue 更新(即 CurrentValue>MonitoredValue)的中断通知。
查询 OS 中的本机围栏功能启用情况
驱动程序必须在驱动程序初始化期间查询操作系统中是否启用了本机围栏功能。从 WDDM 3.2 开始,OS 使用添加 的 IsFeatureEnabled 接口来控制是否启用了某些功能,包括本机围栏功能。
因此,KMD 必须实现 IsFeatureEnabled 接口。 KMD 的实现必须查询 OS 是否在DXGK_VIDSCHCAPS中播发本机围栏支持之前启用了DXGK_FEATURE_NATIVE_FENCE功能。 如果 KMD 在 OS 未启用该功能时播发本机围栏支持,OS 将失败适配器初始化。
有关功能启用接口的详细信息,请参阅 查询 WDDM 功能支持和启用。
用于查询本机围栏功能的 DDI 启用
KMD 引入了以下接口,用于查询 OS 是否启用了本机围栏功能:
- DXGKCB_FEATURE_NATIVEFENCE_CAPS_1
- DXGKARGCB_FEATURE_NATIVEFENCE_CAPS_1
- DXGKCBINT_FEATURE_NATIVEFENCE_1
OS 实现了新增的 DXGKCB_FEATURE_NATIVEFENCE_CAPS_1 接口表,专用于 DXGK_FEATURE_NATIVE_FENCE 的版本 1。 KMD 必须查询此功能接口表以确定 OS 的功能。 在将来的 OS 版本中,OS 可能会引入此接口表的未来版本,详细说明对新功能的支持。
用于查询支持的示例驱动程序代码
以下示例代码演示如何使用DXGK_FEATURE_INTERFACE接口中的DXGK_FEATURE_NATIVE_FENCE功能来查询支持。
DXGK_FEATURE_INTERFACE FeatureInterface;
struct FEATURE_RESULT
{
bool Enabled;
DXGK_FEATURE_VERSION Version;
};
// Driver internal cache for state & version of queried features
struct FEATURE_STATE
{
struct
{
UINT NativeFenceEnabled : 1;
};
DXGK_FEATURE_VERSION NativeFenceVersion = 0;
// Interfaces
DXGKCBINT_FEATURE_NATIVEFENCE_1 NativeFenceInterface = {};
// Interface queried values
DXGKARGCB_FEATURE_NATIVEFENCE_CAPS_1 NativeFenceOSCaps1 = {};
};
// Helper function to query OS's feature enabled interface
FEATURE_RESULT IsFeatureEnabled(
DXGK_FEATURE_ID FeatureId
)
{
FEATURE_RESULT Result = {};
//
// If the feature interface functionality is available (e.g. supported by the OS)
//
DXGKARGCB_ISFEATUREENABLED2 Args = {};
Args.FeatureId = FeatureId;
if(NT_SUCCESS(FeatureInterface.IsFeatureEnabled(DxgkInterface.DeviceHandle, &Args)))
{
Result.Enabled = Args.Result.Enabled;
Result.Version = Args.Result.Version;
}
return Result;
}
// Actual code to query whether OS has enabled Native Fence support and corresponding OS caps
FEATURE_RESULT FeatureResult = IsFeatureEnabled(DXGK_FEATURE_NATIVE_FENCE);
FEATURE_STATE FeatureState = {};
FeatureState.NativeFenceEnabled = !!FeatureResult.Enabled;
if (FeatureResult.Enabled)
{
// Query OS caps for native fence feature, using the feature interface
DXGKARGCB_QUERYFEATUREINTERFACE QFIArgs = {};
QFIArgs.FeatureId = DXGK_FEATURE_NATIVE_FENCE;
QFIArgs.Interface = &FeatureState.NativeFenceInterface;
QFIArgs.InterfaceSize = sizeof(FeatureState.NativeFenceInterface);
QFIArgs.Version = FeatureResult.Version;
Status = FeatureInterface.QueryFeatureInterface(DxgkInterface.DeviceHandle, &QFIArgs);
if(NT_SUCCESS(Status))
{
FeatureState.NativeFenceVersion = FeatureResult.Version;
Status = FeatureState.NativeFenceInterface.GetOSCaps(&FeatureState.NativeFenceOSCaps1);
NT_ASSERT(NT_SUCCESS(Status));
}
else
{
// We should always succeed getting an interface from a successfully
// negotiated feature + version.
NT_ASSERT(FALSE);
}
}
本机围栏功能
更新或引入以下接口以查询本机围栏上限:
在 DXGK_VIDSCHCAPS 中增加了 NativeGpuFence 字段。 如果 OS 启用了 DXGK_FEATURE_NATIVE_FENCE 功能,则驱动程序可以在适配器初始化期间通过将 DXGK_VIDSCHCAPS::NativeGpuFence 位设置为 1 来声明对本机 GPU 围栏功能的支持。
为 DXGK_QUERYADAPTERINFOTYPE 添加了 DXGKQAITYPE_NATIVE_FENCE_CAPS。
Dxgkrnl 通过添加相应 D3DKMT_WDDM_3_1_CAPS::NativeGpuFenceSupported 结构/位向用户模式公开此功能。
为 KMTQUERYADAPTERINFOTYPE 添加了 KMTQAITYPE_WDDM_3_1_CAPS。
为 KMD 添加了以下实体,以指示其对本机 GPU 围栏功能的支持能力。
DXGK_NATIVE_FENCE_CAPS 结构描述 GPU 的本机围栏功能。 当 KMD 设置此结构的 MapToGpuSystemProcess 位时,它会指示 OS 保留系统进程 GPU 虚拟地址空间以供 CMP 使用,并为本地围栏CurrentValue 和 MonitoredValue 创建 GPU VA 映射到该地址空间。 这些 GPU VA 稍后作为 DXGKARG_CREATENATIVEFENCE::CurrentValueSystemProcessGpuVa 和 MonitoredValueSystemProcessGpuVa 传递给 KMD 的围栏创建回调。
当调用其 DxgkDdiQueryAdapterInfo 函数并添加 DXGKQAITYPE_NATIVE_FENCE_CAPS 查询适配器信息类型时,KMD 返回其填充的 DXGK_NATIVE_FENCE_CAPS 结构。
KMD DDI 用于创建、打开、关闭和销毁本机围栏对象
引入了以下 KMD 实现的 DDI 来创建、打开、关闭和销毁本机围栏对象。 Dxgkrnl 代表用户模式组件调用这些 DDI。 Dxgkrnl 仅在 OS 启用 DXGK_FEATURE_NATIVE_FENCE 功能时调用它们。
- DxgkDdiCreateNativeFence/DXGKARG_CREATENATIVEFENCE
- DxgkDdiOpenNativeFence/DXGKARG_OPENNATIVEFENCE
- DxgkDdiCloseNativeFence/DXGKARG_CLOSENATIVEFENCE
- DxgkDdiDestroyNativeFence/DXGKARG_DESTROYNATIVEFENCE
已更新以下 DDI 以支持本机围栏对象:
以下成员已添加到 DRIVER_INITIALIZATION_DATA。 支持本机 GPU 围栏对象的驱动程序应实现这些函数,并通过该结构为 Dxgkrnl 提供指向它们的指针。
- PDXGKDDI_CREATENATIVEFENCE DxgkDdiCreateNativeFence(在 WDDM 3.1 中添加)
- PDXGKDDI_DESTROYNATIVEFENCE DxgkDdiDestroyNativeFence(在 WDDM 3.1 中添加)
- PDXGKDDI_OPENNATIVEFENCE DxgkDdiCreateNativeFence(在 WDDM 3.2 中添加)
- PDXGKDDI_CLOSENATIVEFENCE DxgkDdiCloseNativeFence(在 WDDM 3.2 中添加)
- PDXGKDDI_SETNATIVEFENCELOGBUFFER DxgkDdiSetNativeFenceLogBuffer(在 WDDM 3.2 中添加)
- PDXGKDDI_UPDATENATIVEFENCELOGS DxgkDdiUpdateNativeFenceLogs(在 WDDM 3.2 中添加)
共享围栏的全局句柄和本地句柄
假设进程 A 创建共享本机围栏,然后进程 B 打开此围栏。
进程 A 创建共享本机围栏时,Dxgkrnl 使用创建此围栏的适配器驱动程序句柄调用 DxgkDdiCreateNativeFence。 在 hGlobalNativeFence 中创建并返回的围栏句柄是全局围栏句柄。
Dxgkrnl 随后调用 DxgkDdiOpenNativeFence 以打开进程 A 的特定本地句柄(hLocalNativeFenceA)。
当进程 B 打开相同的共享本机围栏时,Dxgkrnl 调用 DxgkDdiOpenNativeFence 以打开特定于进程 B 的本地句柄 (hLocalNativeFenceB)。
如果进程 A 销毁其共享本机围栏实例,Dxgkrnl 会发现仍有一个挂起的对此全局围栏的引用,因此驱动程序只调用 DxgkDdiCloseNativeFence(hLocalNativeFenceA) 来清理特定于进程 A 的结构。 hGlobalNativeFence 句柄仍然存在。
当进程 B 销毁其围栏实例时,Dxgkrnl 调用 DxgkDdiCloseNativeFence(hLocalNativeFenceB),然后调用 DxgkDdiDestroyNativeFence(hGlobalNativeFence),以允许 KMD 销毁其全局围栏数据。
为 CMP 使用的分页进程地址空间中的 GPU VA 映射
KMD 在要求本地围栏 GPU VA 也映射到 GPU 分页进程地址空间的硬件上设置 DXGK_NATIVE_FENCE_CAPS::MapToGpuSystemProcess 上限。 设置 MapToGpuSystemProcess 位指示 OS 在分页进程地址空间中为本机围栏的 CurrentValue 和 MonitoredValue 创建 GPU VA 映射,供 CMP 使用。 这些 GPU VA 随后被传递给 DxgkDdiCreateNativeFence 作为 DXGKARG_CREATENATIVEFENCE::CurrentValueSystemProcessGpuVa 和 MonitoredValueSystemProcessGpuVa。
用于创建、打开和销毁本机围栏的 D3DKMT 内核 API
引入了以下 D3DKMT 内核模式 API 来创建和打开本机围栏对象。
- D3DKMTCreateNativeFence / D3DKMT_CREATENATIVEFENCE
- D3DKMTOpenNativeFenceFromNTHandle / D3DKMT_OPENNATIVEFENCEFROMNTHANDLE
Dxgkrnl 调用现有的 D3DKMTDestroySynchronizationObject 函数来关闭并销毁(释放)现有的本地围栏对象。
引入或更新的支持结构和枚举包括:
- D3DDDI_NATIVEFENCEINFO
- D3DDDI_NATIVEFENCE_TYPE
- D3DDDI_SYNCHRONIZATIONOBJECT_FLAGS
- D3DDDI_NATIVEFENCE_MAPPING
用于支持在本地内存中放置本机围栏值的 DDI
添加了或更改了以下 DDI 以支持在本地内存中放置本机围栏值:
添加了 D3DKMDT_FENCESTORAGESURFACEDATA 结构。
本机围栏类型的 Native fence MonitoredValue 和 CurrentValue D3DDDI_NATIVEFENCE_TYPE_INTRA_GPU可以放置在本地设备内存中。 为此,OS 会要求驱动程序指定应在其中放置围栏存储的内存段。 DxgkDdiGetStandardAllocation 已扩展以提供此类信息。
D3DKMDT_STANDARDALLOCATION_FENCESTORAGE添加到DXGKARG_GETSTANDARDALLOCATIONDRIVERDATA。
指示硬件队列的本机进度围栏
引入了以下更新来指示本机硬件队列进度围栏对象:
为对 DxgkDdiCreateHwQueue 的调用添加了 NativeProgressFence 标志。
- 在受支持的系统上,OS 将硬件队列进度围栏更新为本机围栏。 当 OS 设置 NativeProgressFence 时,它向 KMD 指示 DXGKARG_CREATEHWQUEUE::hHwQueueProgressFence 句柄指向以前使用 DxgkDdiCreateNativeFence 创建的本机 GPU 围栏对象的驱动程序句柄。
本机围栏信号中断
对中断机制进行了以下更改,以支持本机围栏信号中断:
DXGK_INTERRUPT_TYPE 枚举更新为具有 DXGK_INTERRUPT_NATIVE_FENCE_SIGNALED 中断类型。
DXGKARGCB_NOTIFY_INTERRUPT_DATA结构更新为包含 NativeFenceSignaled 结构以表示本机围栏信号中断
NativeFenceSignaled 用于通知 OS,CPU 监视的一组本机围栏 GPU 对象在 GPU 引擎上发出信号。 如果 GPU 能够确定具有活动 CPU 等待程序的对象确切子集,则它通过 pSignaledNativeFenceArray 传递此子集。 此数组中的句柄必须是 Dxgkrnl 在 DxgkDdiCreateNativeFence 中传递给 KMD 的有效 hGlobalNativeFence 句柄。 将句柄传递给已销毁的本机围栏对象会导致错误检查。
DXGKCB_NOTIFY_INTERRUPT_DATA_FLAGS 结构更新为包含 EvaluateLegacyMonitoredFences 成员。
GPU 可以在以下条件下传递 NULL pSignaledNativeFenceArray:
- GPU 无法确定具有活动 CPU 等待程序的对象的确切子集。
- 多个信号中断被折叠在一起,使得很难确定具有活动等待程序的信号集。
NULL 值指示 OS 扫描所有未完成的本机 GPU 围栏对象等待程序。
OS 和驱动程序之间的协定是:如果 OS 具有活动 CPU 等待程序(由 MonitoredValue 表示),并且 GPU 引擎将该对象标记为需要 CPU 中断的值,则 GPU 必须执行以下操作之一:
- 在 pSignaledNativeFenceArray 中包括此本机围栏句柄。
- 使用 NULL pSignaledNativeFenceArray 引发 NativeFenceSignaled 中断。
默认情况下,当 KMD 使用 NULL pSignaledNativeFenceArray 引发此中断时,Dxgkrnl 仅扫描所有挂起的本机围栏等待程序,而不会扫描旧的受监视的围栏等待程序。 在无法区分旧的 DXGK_INTERRUPT_MONITORED_FENCE_SIGNALED 和 DXGK_INTERRUPT_NATIVE_FENCE_SIGNALED 的硬件上,KMD 始终只能引发引入的 DXGK_INTERRUPT_NATIVE_FENCE_SIGNALED 中断(pSignaledNativeFenceArray = NULL 和 EvaluateLegacyMonitoredFences = 1),这表示 OS 扫描所有等待程序(旧的受监视的围栏等待程序和本机围栏等待程序)。
指示 KMD 更新一批值
引入了以下接口,以指示 KMD 更新一批当前值或受监视值:
DxgkDdiUpdateCurrentValuesFromCpu / DXGKARG_UPDATECURRENTVALUESFROMCPU
DxgkDdiUpdateMonitoredValues / DXGKARG_UPDATEMONITOREDVALUES
跨适配器本机围栏
OS 必须支持创建跨适配器本机围栏,因为现有的 DX12 应用创建和使用跨适配器监视的围栏。 如果这些应用的基础队列和计划切换到用户模式提交,则受监视的围栏也必须切换到本机围栏(用户模式队列不支持受监视的围栏)。
必须使用类型 D3DDDI_NATIVEFENCE_TYPE_DEFAULT 创建跨适配器围栏。 否则,D3DKMTCreateNativeFence 会失败。
所有 GPU 共享 CurrentValue 存储的相同副本,该副本始终在系统内存中分配。 当运行时在 GPU1 上创建跨适配器本机围栏并在 GPU2 上打开它时,两个 GPU 上的 GPU VA 映射都指向同一 CurrentValue 物理存储。
每个 GPU 都有自己的 MonitoredValue 副本。 因此,可以在系统内存或本地内存中分配 MonitoredValue 存储。
跨适配器本机围栏必须解决 GPU1 正在等待 GPU2 发出信号的本机围栏的条件。 目前,没有 GPU 到 GPU 信号的概念;因此,OS 通过从 CPU 发信号通知 GPU1 来明确地解决该条件。 通过将跨适配器围栏的 MonitoredValue 设置为 0,以延长其使用寿命,可以完成此信号发送。 然后,当 GPU2 向本机围栏发出信号时,它也会引发 CPU 中断,从而允许 Dxgkrnl 更新 GPU1 上的 CurrentValue(使用 DxgkDdiUpdateCurrentValuesFromCpu,NotificationOnly 标志设置为 TRUE),并取消阻止该 GPU 的任何挂起的 CPU/GPU 等待程序。
尽管 MonitoredValue 对于跨适配器的本机围栏始终为 0,但在同一 GPU 上提交的等待和信号仍受益于 GPU 同步速度更快。 但是,减少 CPU 中断的电源优势会丧失,因为即使在另一个 GPU 上没有 CPU 等待程序,CPU 中断也会无条件地增加。 进行这种权衡是为了使跨适配器本机围栏的设计和实现成本保持简单。
OS 支持在 GPU1 上创建本机围栏对象并在 GPU2 上打开的方案,其中 GPU1 支持该功能,而 GPU2 不支持。 围栏对象在 GPU2 上以常规 MonitoredFence 的形式打开。
OS 支持在 GPU1 上创建常规受监视的围栏对象,并在支持该功能的 GPU2 上作为本地围栏打开的方案。 围栏对象将作为 GPU2 上的本地围栏打开。
跨适配器等待/信号组合
以下各子部分中的表以 iGPU 和 dGPU 系统为例,列出了可能用于 CPU/GPU 的本机围栏等待/信号的各种配置。 考虑以下两种情况:
- 这两个 GPU 都支持本机围栏。
- iGPU 不支持本机围栏,但 dGPU 支持本机围栏。
第二种方案也类似于两个 GPU 都支持本机围栏的情况,但本机围栏等待/信号提交到 iGPU 上的内核模式队列。
应通过从列中选择一对等待和信号来读取表,例如 WaitFromGPU - SignalFromGPU 或 WaitFromGPU - SignalFromCPU 等。
方案 1
在方案 1 中,dGPU 和 iGPU 都支持本机围栏。
| iGPU WaitFromGPU (hFence, 10) | iGPU WaitFromCPU (hFence, 10) | dGPU SignalFromGpu (hFence, 10) | dGPU SignalFromCpu(hFence, 10) |
|---|---|---|---|
| UMD 在命令缓冲区中插入等待 hfence CurrentValue == 10 指令 | 运行时调用 D3DKMTWaitForSynchronizationObjectFromCpu | ||
| VidSch 在其本机围栏 CPU 等待程序列表中跟踪此同步对象 | |||
| UMD 在命令缓冲区中插入写入 hFence CurrentValue = 10 信号指令 | 运行时调用 D3DKMTSignalSynchronizationObjectFromCpu | ||
| 当写入 CurrentValue 时,VidSch 收到本机围栏信号 ISR(因为始终是 MonitoredValue == 0) | VidSch 调用 DxgkDdiUpdateCurrentValuesFromCpu(hFence, 10) | ||
| VidSch 将信号 (hFence, 10) 传播到 iGPU | VidSch 将信号 (hFence, 10) 传播到 iGPU | ||
| VidSch 接收传播的信号并调用 DxgkDdiUpdateCurrentValuesFromCpu(hFence, NotificationOnly=TRUE) | VidSch 接收传播的信号并调用 DxgkDdiUpdateCurrentValuesFromCpu(hFence, NotificationOnly=TRUE) | ||
| KMD 重新扫描运行列表,以取消阻止在 hFence 上等待的 HW 通道 | VidSch 通过向 KEVENT 发出信号来取消阻止 CPU 等待条件 |
方案 2a
在方案 2a 中,iGPU 不支持本机围栏,但 dGPU 支持。 在 iGPU 上提交等待,并在 dGPU 上提交信号。
| iGPU WaitFromGPU (hFence, 10) | iGPU WaitFromCPU (hFence, 10) | dGPU SignalFromGpu (hFence, 10) | dGPU SignalFromCpu(hFence, 10) |
|---|---|---|---|
| 运行时调用 D3DKMTWaitForSynchronizationObjectFromGpu | 运行时调用 D3DKMTWaitForSynchronizationObjectFromCpu | ||
| VidSch 在其受监视的围栏等待列表中跟踪此同步对象 | VidSch 在其受监视的围栏 CPU 等待程序列表标头中跟踪此同步对象 | ||
| UMD 在命令缓冲区中插入写入 hFence CurrentValue = 10 信号指令 | 运行时调用 D3DKMTSignalSynchronizationObjectFromCpu | ||
| 当写入 CurrentValue 时,VidSch 接收 NativeFenceSignaledISR(因为始终是 MV == 0) | VidSch 调用 DxgkDdiUpdateCurrentValuesFromCpu(hFence, 10) | ||
| VidSch 将信号 (hFence, 10) 传播到 iGPU | VidSch 将信号 (hFence, 10) 传播到 iGPU | ||
| VidSch 接收传播的信号并观察新的围栏值 | VidSch 接收传播的信号并观察新的围栏值 | ||
| VidSch 扫描其受监视的围栏等待列表并取消阻止软件上下文 | VidSch 扫描其受监视的围栏 CPU 等待程序列表标头,并通过发出 KEVENT 信号来取消阻止 CPU 等待 |
方案 2b
在方案 2b 中,本机围栏支持保持不变(iGPU 不支持,dGPU 支持)。 这一次,在 iGPU 上提交信号,并在 dGPU 上提交等待。
| iGPU SignalFromGPU (hFence, 10) | iGPU SignalFromCPU (hFence, 10) | dGPU WaitFromGpu (hFence, 10) | dGPU WaitFromCpu(hFence, 10) |
|---|---|---|---|
| UMD 在命令缓冲区中插入等待 hfence CurrentValue == 10 指令 | 运行时调用 D3DKMTWaitForSynchronizationObjectFromCpu | ||
| VidSch 在其本机围栏 CPU 等待程序列表中跟踪此同步对象 | |||
| UMD 调用 D3DKMTSignalSynchronizationObjectFromGpu | UMD 调用 D3DKMTSignalSynchronizationObjectFromCpu | ||
| 当数据包位于软件上下文的头时,VidSch 直接从 CPU 更新围栏值 | VidSch 直接从 CPU 更新围栏值 | ||
| VidSch 将信号 (hFence, 10) 传播到 dGPU | VidSch 将信号 (hFence, 10) 传播到 dGPU | ||
| VidSch 接收传播的信号并调用 DxgkDdiUpdateCurrentValuesFromCpu(hFence, NotificationOnly=TRUE) | VidSch 接收传播的信号并调用 DxgkDdiUpdateCurrentValuesFromCpu(hFence, NotificationOnly=TRUE) | ||
| KMD 重新扫描运行列表,以取消阻止在 hFence 上等待的 HW 通道 | VidSch 通过向 KEVENT 发出信号来取消阻止 CPU 等待条件 |
未来的 GPU 到 GPU 跨适配器信号
如同步问题中所述,对于跨适配器本机围栏,由于无条件引发 CPU 中断,因此无法节省电源。
在将来的版本中,OS 将开发一个基础结构,允许一个 GPU 上的 GPU 信号通过写入公共门铃内存来中断其他 GPU,从而允许其他 GPU 唤醒、处理其运行列表并取消阻止就绪的 HW 队列。
这项工作面临的挑战是设计:
- 常用门铃内存。
- GPU 可以写入门铃的智能有效负载或句柄,该门铃允许其他 GPU 确定已发出信号的围栏,以便它只能扫描 HWQueues 子集。
使用此类跨适配器信号,GPU 甚至可能共享本机围栏存储的相同副本(一种线性格式的跨适配器分配,类似于跨适配器扫描分配),所有 GPU 都可以从中读写。
本机围栏日志缓冲区设计
对于本机围栏和用户模式提交,Dxgkrnl 不知道本机 GPU 何时等待,以及从 UMD 排队的信号何时在 GPU 上为特定 HWQueue 取消阻止。 对于本机围栏,可以为给定的围栏抑制受监视的围栏信号中断。
:
需要一种方法来重新创建围栏操作,如该 GPUView 图所示。 深粉红色的框是信号,浅粉红色的框是等待。 当操作在 CPU 上提交给 Dxgkrnl 时,每个框开始;当 Dxgkrnl 在 CPU 上完成操作时结束。 通过这种方式,我们可以研究命令的整个生命周期。
因此,在较高级别上,需要记录的每个 HWQueue 条件为:
| 条件 | 含义 |
|---|---|
| FENCE_WAIT_QUEUED | UMD 在命令队列中插入 GPU 等待指令时的 CPU 时间戳 |
| FENCE_SIGNAL_QUEUED | UMD 在命令队列中插入 GPU 信号指令时的 CPU 时间戳 |
| FENCE_SIGNAL_EXECUTED | 在 GPU 上为 HWQueue 执行信号命令时的 GPU 时间戳 |
| FENCE_WAIT_UNBLOCKED | GPU 上满足等待条件且 HWQueue 未被阻止时的 GPU 时间戳 |
本机围栏日志缓冲区 DDI
引入了以下 DDI、结构和枚举来支持本机围栏日志缓冲区:
- DxgkDdiSetNativeFenceLogBuffer / DXGKARG_SETNATIVEFENCELOGBUFFER
- DxgkDdiUpdateNativeFenceLogs / DXGKARG_UPDATENATIVEFENCELOGS
- 一种日志缓冲区,包含一个标头和一组日志条目。 标头标识条目是用于等待还是信号,每个条目标识操作类型(已执行或取消阻止):
日志缓冲区设计适用于本机围栏和用户模式提交队列,其中日志缓冲区有效负载由 GPU 引擎/CMP 编写,而无需 Dxgkrnl 或 KMD 参与。 因此,UMD 将在生成等待/信号命令缓冲区时插入指令,将 GPU 编程为在执行时将日志缓冲区有效负载写入日志缓冲区条目。 对于非用户模式提交(即内核模式队列),等待和信号是 Dxgkrnl 中的软件命令,因此我们已经知道这些操作的时间戳和其他详细信息,我们不需要硬件/KMD 更新日志缓冲区。 对于此类内核模式队列, Dxgkrnl 不会创建日志缓冲区。
日志缓冲区机制
Dxgkrnl 为每个 HWQueue 分配两个专用 4-KB 日志缓冲区。
- 一个用于日志记录等待。
- 一个用于日志记录信号。
这些日志缓冲区具有内核模式 CPU VA (LogBufferCpuVa)、进程地址空间中的 GPU VA (LogBufferGpuVa) 和 CMP VA (LogBufferSystemProcessGpuVa) 的映射,因此它们可以读/写到 KMD、GPU 引擎和 CMP。 Dxgkrnl 调用 DxgkDdiSetNativeFenceLogBuffer 两次:一次设置日志缓冲区用于日志记录等待,一次设置日志缓冲区用于日志记录信号。
UMD 在命令列表中插入本机围栏等待或信号指令后,还插入一个命令,指示 GPU 将特定条目的有效负载写入日志缓冲区。
GPU 引擎执行围栏操作后,会看到 UMD 指令,将有效负载写入日志缓冲区中的给定条目。 此外,GPU 还会将当前的 FenceEndGpuTimestamp 写入此日志缓冲区条目。
虽然 UMD 无法访问 GPU 可访问的日志缓冲区,但它控制日志缓冲区的进展。 也就是说,UMD 确定要写入的下一个空闲条目(如果有的话),并用该信息对 GPU 进行编程。 当 GPU 写入日志缓冲区时,它会递增日志标头中的 FirstFreeEntryIndex 值。 UMD 必须确保对日志条目的写入单调递增。
假设出现了下面这种情景:
- 有两个 HWQueue(HWQueueA 和 HWQueueB)具有相应的围栏日志缓冲区,其中 GPU VA 为 FenceLogA 和 FenceLogB。 HWQueueA 与日志记录等待的日志缓冲区相关联,HWQueueB 与日志记录信号的日志缓冲区相关联。
- 有一个本机围栏对象,其用户模式 D3DKMT_HANDLE 为 FenceF。
- 在 FenceF 上等待值 V1 的 GPU 在时间 CPUT1 排队到 HWQueueA。 UMD 生成命令缓冲区时,它会插入命令,指示 GPU 记录有效负载:LOG(FenceF, V1, DXGK_NATIVE_FENCE_LOG_OPERATION_WAIT_UNBLOCKED)。
- 在时间 CPUT2 时,到值 V1 的 FenceF 的 GPU 信号排队到 HWQueueB。 UMD 生成命令缓冲区时,它会插入命令,指示 GPU 记录有效负载:LOG(FenceF, V1, DXGK_NATIVE_FENCE_LOG_OPERATION_SIGNAL_EXECUTED)。
GPU 计划程序在 GPU 时间 GPUT1 在 HWQueueB 上执行 GPU 信号后,读取 UMD 有效负载,并将事件记录在 OS 提供的 HWQueueB 围栏日志中:
DXGK_NATIVE_FENCE_LOG_ENTRY LogEntry = {};
LogEntry.hNativeFence = FenceF;
LogEntry.FenceValue = V1;
LogEntry.OperationType = DXGK_NATIVE_FENCE_LOG_OPERATION_SIGNAL_EXECUTED;
LogEntry.FenceEndGpuTimestamp = GPUT1; // Time when UMD submits a command to the GPU
GPU 计划程序在 GPU 时间 GPUT2 取消阻止 HWQueueA 后,会读取 UMD 有效负载,并将事件记录在 OS 提供的 HWQueueA 的围栏日志中:
DXGK_NATIVE_FENCE_LOG_ENTRY LogEntry = {};
LogEntry.hNativeFence = FenceF;
LogEntry.FenceValue = V1;
LogEntry.OperationType = DXGK_NATIVE_FENCE_LOG_OPERATION_WAIT_UNBLOCKED;
LogEntry.FenceObservedGpuTimestamp = GPUTo; // Time that GPU acknowledged UMD's submitted command and queued the fence wait on HW
LogEntry.FenceEndGpuTimestamp = GPUT2;
Dxgkrnl 可以销毁并重新创建日志缓冲区。 每次这样做时,它都会调用 DxgkDdiSetNativeFenceLogBuffer 来通知 KMD 新位置。
围栏排队操作的 CPU 时间戳
鉴于以下情况,让 UMD 记录这些 CPU 时间戳没有什么好处:
- 可以在 GPU 执行包括命令列表的命令缓冲区之前几分钟记录命令列表。
- 这几分钟可能与同一命令缓冲区中的其他同步对象不同步。
将 CPU 时间戳包含在 UMD 向 GPU 写入的日志缓冲区的指令中是有代价的,因此 CPU 时间戳不包含在日志条目有效负载中。
相反,运行时或 UMD 可以在记录命令列表时发出带有 CPU 时间戳的本机围栏排队 ETW 事件。 因此,工具可以通过组合来自该新事件的 CPU 时间戳和来自日志缓冲区条目的 GPU 时间戳来构建围栏排队和已完成事件的时间线。
发出信号或取消阻止围栏时 GPU 上的操作顺序
UMD 必须确保在构建命令列表指示 GPU 发出信号/取消阻止围栏时保持以下顺序:
- 将新围栏值写入围栏 GPU VA/CMP VA。
- 将日志有效负载写入相应的日志缓冲区 GPU VA/CMP VA。
- 如有必要,引发本机围栏信号中断。
此操作顺序确保当中断引发到 OS 时,Dxgkrnl 看到最近的日志条目。
允许日志缓冲区溢出
GPU 可以通过覆盖 OS 尚未看到的条目来溢出日志缓冲区。 它通过递增 WraparoundCount 来执行此操作。
当 OS 最终读取日志时,它可以通过将日志标头中的新 WraparoundCount 值与其缓存的值进行比较来检测是否发生了溢出。 如果发生溢出,OS 有以下回退选项:
- 为了在发生溢出时取消阻止围栏,OS 会扫描所有围栏,并确定哪些等待程序被取消阻止。
- 如果启用了跟踪,OS 可以在跟踪中发出标志,以通知用户事件丢失。 此外,启用跟踪后,OS 首先会增加日志缓冲区的大小,以防止首次溢出。
UMD 没有必要在处理日志缓冲区条目时实现回压支持。
日志缓冲区时间戳为空或重复
在一般情况下,Dxgkrnl 期望日志条目中的时间戳单调递增。 但是,在某些情况下,后续日志条目的时间戳为零或与以前的日志条目相同。
例如,在具有链接显示适配器的方案中,LDA 中的链接适配器之一可以跳过围栏写入操作。 在这种情况下,其日志缓冲区条目的时间戳为零。 Dxgkrnl 处理此类情况。 也就是说, Dxgkrnl 从不期望给定日志条目的时间戳小于上一个日志条目的时间戳;即,时间戳永远不会倒退。
同步更新本机围栏日志
GPU 写入以更新围栏值和相应的日志缓冲区必须确保在 CPU 读取之前写入已完全传播。 此要求需要使用内存屏障。 例如:
- 信号围栏 (N):将 N 写入为新的当前值
- 写入日志条目,包括 GPU 时间戳
- MemoryBarrier
- 递增 FirstFreeEntryIndex
- MemoryBarrier
- 受监视的围栏中断 (N):读取地址“M”,并将该值与 N 进行比较,以决定是否传递 CPU 中断
在每个 GPU 信号上插入两个屏障的成本太高,尤其是在条件中断检查不满足且不需要 CPU 中断时。 因此,设计将插入其中一个内存屏障的成本从 GPU(生产者)转移到 CPU(消费者)。 Dxgkrnl 调用引入的 DxgkDdiUpdateNativeFenceLogs 函数,使 KMD 按需同步刷新挂起的本机围栏日志写入(类似于为 HW 翻转队列日志刷新引入 DxgkddiUpdateflipqueuelog 的方式)。
对于 GPU 操作:
- 信号围栏 (N):将 N 写入为新的当前值
- 写入日志条目,包括 GPU 时间戳
- 递增 FirstFreeEntryIndex
- MemoryBarrier => 确保 FirstFreeEntryIndex 完全传播
- 受监视的围栏中断 (N):读取地址“M”,并将该值与 N 进行比较,以决定是否传递中断
对于 CPU 操作:
在 Dxgkrnl 的本机围栏信号中断处理程序 (DISPATCH_IRQL) 中:
- 对于每个 HWQueue 日志:读取 FirstFreeEntryIndex,并确定是否写入新条目。
- 对于每个包含新条目的 HWQueue 日志:调用 DxgkDdiUpdateNativeFenceLogs,并为这些 HWQueue 提供内核句柄。 在此 DDI 中,KMD 向每个给定的 HWQueue 插入一个内存屏障,以确保提交所有日志条目写入。
- Dxgkrnl 读取日志条目以提取时间戳有效负载。
因此,只要硬件在写入 FirstFreeEntryIndex 后插入内存屏障,Dxgkrnl 就会始终调用 KMD 的 DDI,从而允许 KMD 在 Dxgkrnl 读取任何日志条目之前插入内存屏障。
未来硬件要求
大多数当前一代硬件可能只支持在本机围栏信号中断中写入它发出信号的本机对象的内核句柄。 此设计在前面的本机围栏信号中断中进行了介绍。 在这种情况下,Dxgkrnl 处理中断有效负载,如下所示:
- OS 对围栏值执行读取(可能跨 PCI)。
- 知道哪个围栏已发出信号和围栏值,OS 会唤醒正在等待该围栏/值的 CPU 等待程序。
- 另外,对于此围栏的父设备,OS 会扫描其所有 HWQueues 的日志缓冲区。 然后,OS 读取最后一个写入的日志缓冲区条目,以确定哪个 HWQueue 发出了信号,并提取相应的时间戳有效负载。 这种方法可能会在 PCI 上冗余地读取一些围栏值。
在未来的平台上,Dxgkrnl 更倾向于在本机围栏信号中断中获取内核 HwQueue 句柄数组。 此方法使 OS 能够:
- 读取该 HwQueue 的最新日志缓冲区条目。 中断处理程序不知道用户设备;因此,此 HwQueue 句柄需要是一个内核句柄。
- 扫描日志缓冲区中的日志条目,以指示哪些围栏已发出信号,以及信号的值。 仅读取日志缓冲区可确保通过 PCI 进行单次读取,而不必冗余地读取围栏值和日志缓冲区。 只要日志缓冲区未溢出(删除 Dxgkrnl 从不读取的条目),此优化就会成功。
- 如果 OS 检测到日志缓冲区已溢出,它会返回到读取同一设备所拥有的每个围栏的实时值的非优化路径。 性能与设备拥有的围栏数量成正比。 如果围栏值位于视频内存中,则这些读取在 PCI 之间是缓存一致的。
- 知道哪些围栏已发出信号和围栏值,OS 会唤醒正在等待这些围栏/值的 CPU 等待程序。
优化的本机围栏信号中断
除了本机围栏信号中断中所述的更改外,还进行了以下更改以支持优化的方法:
- 为 DXGK_VIDSCHCAPS 添加了 OptimizedNativeFenceSignaledInterrupt 上限。
如果硬件支持,则 GPU 应只提及引发中断时运行的 HWQueue 的 KMD 句柄,而不是填写发出信号的围栏句柄数组。 Dxgkrnl 扫描此 HWQueue 的围栏日志缓冲区,并读取自上次更新以来 GPU 完成的所有围栏操作,并取消阻止任何相应的 CPU 等待程序。 如果 GPU 无法确定哪个子集的围栏已发出信号,则应指定 NULL HWQueue 句柄。 当 Dxgkrnl 看到 NULL HWQueue 句柄时,它会回退以重新扫描此引擎上所有 HWQueue 的日志缓冲区,以确定哪些围栏得到了信号。
对此优化的支持是可选的;KMD 应设置 DXGK_VIDSCHCAPS:OptimizedNativeFenceSignaledInterrupt 上限(如果硬件支持)。 如果未设置 OptimizedNativeFenceSignaledInterrupt 上限,则 GPU/KMD 会遵循本机围栏信号中断中所述的行为。
优化的本机围栏信号中断的示例
HWQueueA:GPU 信号到围栏 F1、值 V1 -> 写入日志缓冲区条目 E1 -> 无需中断
HWQueueA:GPU 信号到围栏 F1、值 V2 -> 写入日志缓冲区条目 E2 -> 无需中断
HWQueueA:GPU 信号到围栏 F2、值 V3 -> 写入日志缓冲区条目 E3 -> 无需中断
HWQueueA:GPU 信号到围栏 F2、值 V3 -> 写入日志缓冲区条目 E4 -> 引发中断
DXGKARGCB_NOTIFY_INTERRUPT_DATA FenceSignalISR = {}; FenceSignalISR.NodeOrdinal = 0; FenceSignalISR.EngineOrdinal = 0; FenceSignalISR.hHWQueue = A;Dxgkrnl 读取 HWQueueA 的日志缓冲区。 它读取日志缓冲区条目 E1、E2、E3 和 E4,观察信号围栏 F1 @ Value V1、F1 @ Value V2、F2 @ Value V3 和 F2 @ Value V3,并取消阻止在这些围栏和值上等待的任何等待程序
可选和强制日志记录
必须支持 DXGK_NATIVE_FENCE_LOG_TYPE_WAITS 和DXGK_NATIVE_FENCE_LOG_TYPE_SIGNALS 的本机围栏日志记录。
未来,只有当 GPUView 等工具在 OS 中启用详细的 ETW 日志记录时,才可能添加其他日志记录类型。 OS 必须通知 UMD 和 KMD 何时启用和禁用详细日志记录,以便选择性地启用这些详细事件的日志记录。