Azure HDInsight Spark クラスターで Microsoft Cognitive Toolkit ディープ ラーニング モデルを使用する
この記事では、次の手順を実行します。
Microsoft Cognitive Toolkit を Azure HDInsight Spark クラスターにインストールするカスタム スクリプトを実行する。
Jupyter Notebook を Apache Spark クラスターにアップロードし、トレーニング済みの Microsoft Cognitive Toolkit ディープ ラーニング モデルを Spark Python API (PySpark) を使用して Azure Blob Storage アカウント内のファイルに適用する方法を確認する。
前提条件
HDInsight での Apache Spark クラスター。 Apache Spark クラスターの作成に関するページを参照してください。
HDInsight の Spark での Jupyter Notebook の使用方法を熟知していること。 詳細については、HDInsight の Apache Spark を使用したデータの読み込みとクエリの実行に関するページを参照してください。
このソリューションの流れ
このソリューションは、この記事と、この記事の一部としてアップロードする Jupyter Notebook に分割されます。 この記事では、次の手順を完了します。
- HDInsight Spark クラスターでスクリプト アクションを実行して、Microsoft Cognitive Toolkit と Python のパッケージをインストールします。
- HDInsight Spark クラスターに対してソリューションを実行する Jupyter Notebook をアップロードします。
次の残りの手順は、Jupyter Notebook に関する記事に記載されています。
- サンプル イメージを Spark Resilient Distributed Dataset (RDD) に読み込む。
- モジュールを読み込んでプリセットを定義する。
- データセットを Spark クラスターにローカルにダウンロードする。
- データセットを RDD に変換する。
- トレーニング済みの Cognitive Toolkit モデルを使用してイメージをスコア付けする。
- トレーニング済みの Cognitive Toolkit モデルを Spark クラスターにダウンロードする。
- ワーカー ノードで使用される関数を定義する。
- ワーカー ノードでイメージをスコア付けする。
- モデルの精度を評価する。
Microsoft Cognitive Toolkit をインストールする
スクリプト アクションを使用して Spark クラスターに Microsoft Cognitive Toolkit をインストールします。 スクリプト操作では、既定で使用できないコンポーネントをクラスターにインストールするためにカスタム スクリプトを使用します。 カスタム スクリプトは、Azure portal から使用するか、HDInsight .NET SDK または Azure PowerShell によって使用できます。 スクリプトを使用して、ツールキットのインストールをクラスター作成の一環として、またはクラスターの稼働後に実行することもできます。
この記事では、クラスターの作成後にポータルを使用してツールキットをインストールします。 カスタム スクリプトを実行する他の方法については、スクリプト アクションを使用した HDInsight クラスターのカスタマイズに関するページを参照してください。
Azure ポータルの使用
Azure portal を使用してスクリプト アクションを実行する方法については、スクリプト アクションを使用した HDInsight クラスターのカスタマイズに関するページを参照してください。 Microsoft Cognitive Toolkit をインストールするには、次の入力を行ってください。 スクリプト操作には、次の値を使用します。
| プロパティ | 値 |
|---|---|
| スクリプトの種類 | - Custom |
| Name | MCT をインストールする |
| Bash スクリプト URI | https://raw.githubusercontent.com/Azure-Samples/hdinsight-pyspark-cntk-integration/master/cntk-install.sh |
| ノードの種類: | ヘッド、ワーカー |
| パラメーター | なし |
Jupyter Notebook を Azure HDInsight Spark クラスターにアップロードする
Azure HDInsight Spark クラスターで Microsoft Cognitive Toolkit を使用するには、Jupyter Notebook CNTK_model_scoring_on_Spark_walkthrough.ipynb を Azure HDInsight Spark クラスターに読み込む必要があります。 このノートブックは https://github.com/Azure-Samples/hdinsight-pyspark-cntk-integration の GitHub から入手できます。
https://github.com/Azure-Samples/hdinsight-pyspark-cntk-integration をダウンロードして解凍します。
Web ブラウザーから、
https://CLUSTERNAME.azurehdinsight.net/jupyterに移動します。ここで、CLUSTERNAMEはクラスターの名前です。Jupyter Notebook で、右上隅にある [アップロード] を選択し、ダウンロードに移動して
CNTK_model_scoring_on_Spark_walkthrough.ipynbファイルを選びます。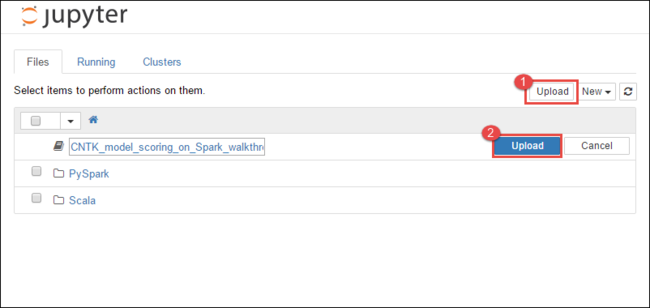
もう一度 [アップロード] を選択します。
ノートブックのアップロード後、ノートブックの名前をクリックします。データセットの読み込みとこの記事の実行方法については、ノートブック自体の指示に従います。
参照
シナリオ
- Apache Spark と BI:HDInsight と BI ツールで Spark を使用した対話型データ分析の実行
- Apache Spark と Machine Learning: HDInsight で Spark を使用して、HVAC データを使用して建物の温度を分析する
- Apache Spark と Machine Learning:HDInsight で Spark を使用して食品の検査結果を予測する
- HDInsight 上での Apache Spark を使用した Web サイト ログ分析
- HDInsight での Apache Spark を使用した Application Insight テレメトリ データ分析
アプリケーションの作成と実行
ツールと拡張機能
- IntelliJ IDEA 用の HDInsight Tools プラグインを使用して Spark Scala アプリケーションを作成し、送信する
- IntelliJ IDEA 用の HDInsight Tools プラグインを使用して Apache Spark アプリケーションをリモートでデバッグする
- HDInsight 上の Apache Spark クラスターで Apache Zeppelin Notebook を使用する
- HDInsight 用の Apache Spark クラスター内の Jupyter Notebook で使用可能なカーネル
- Jupyter Notebook で外部のパッケージを使用する
- Jupyter をコンピューターにインストールして HDInsight Spark クラスターに接続する