HDInsight の Apache Spark クラスターの Jupyter Notebook で外部のパッケージを使用する
HDInsight 上の Apache Spark クラスター内の Jupyter Notebook を、そのクラスターに標準では含まれていない、コミュニティから提供された外部の Apache maven パッケージを使用するように構成する方法について説明します。
利用できるすべてのパッケージは、 Maven リポジトリ で検索できます。 公開されているパッケージの一覧を他のソースから入手してもかまいません。 たとえば、コミュニティから提供されている全パッケージの一覧を Spark Packagesで入手できます。
この記事では、Jupyter Notebook で spark-csv パッケージを使用する方法について説明します。
前提条件
HDInsight での Apache Spark クラスター。 手順については、「 Create Apache Spark clusters in Azure HDInsight (Azure HDInsight での Apache Spark クラスターの作成)」を参照してください。
HDInsight の Spark での Jupyter Notebook の使用方法を熟知していること。 詳細については、HDInsight の Apache Spark を使用したデータの読み込みとクエリの実行に関するページを参照してください。
クラスターのプライマリ ストレージの URI スキーム。 これは、Azure Storage では
wasb://、Azure Data Lake Storage Gen2 ではabfs://です。 Azure Storage または Data Lake Storage Gen2 で安全な転送が有効になっている場合、URI はそれぞれwasbs://またはabfss://になります。安全な転送に関するページも参照してください。
Jupyter Notebook で外部のパッケージを使用する
https://CLUSTERNAME.azurehdinsight.net/jupyterに移動します。CLUSTERNAMEはご自身の Spark クラスターの名前です。新しい Notebook を作成します。 [新規] を選択した後、[Spark] を選択します。
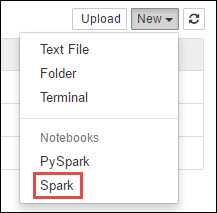
Untitled.pynb という名前の新しい Notebook が作成されて開かれます。 上部のノートブック名を選択し、わかりやすい名前を入力します。
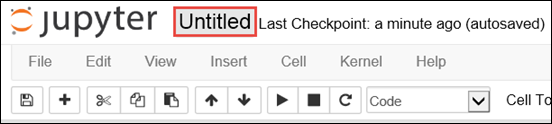
外部のパッケージを使用するようにノートブックを構成するには、
%%configureマジックを使用します。 外部のパッケージを使用するノートブックでは必ず、最初のコード セルで%%configureマジックを呼び出すようにしてください。 そうすることでセッションが開始される前に、指定のパッケージを使用するようにカーネルが構成されます。重要
最初のセルでカーネルを構成しなかった場合、
-fパラメーターを指定して%%configureを使用できますが、その場合セッションが最初からやり直しとなり、すべての進捗が失われます。HDInsight のバージョン コマンド HDInsight 3.5 および HDInsight 3.6 %%configure{ "conf": {"spark.jars.packages": "com.databricks:spark-csv_2.11:1.5.0" }}HDInsight 3.3 および HDInsight 3.4 %%configure{ "packages":["com.databricks:spark-csv_2.10:1.4.0"] }上のスニペットには、Maven Central Repository における外部パッケージの maven コーディネートを指定します。 このスニペットの
com.databricks:spark-csv_2.11:1.5.0は、 spark-csv パッケージの maven コーディネートです。 パッケージのコーディネートは、以下の方法で構築します。a. Maven リポジトリから目的のパッケージを探します。 この記事では spark-csv を使用します。
b. リポジトリで GroupId、ArtifactId、Version の値を確認します。 収集した値が、クラスターに一致することを確認します。 この例では、Scala 2.11 と Spark 1.5.0 パッケージを使用していますが、クラスター内の Scala または Spark のバージョンに応じて別のバージョンを選択しなければならないことがあります。 クラスター上の Scala のバージョンを確認するには、Spark Jupyter カーネルまたは Spark 送信に対して
scala.util.Properties.versionStringを実行します。 クラスター上の Spark のバージョンを確認するには、Jupyter Notebook に対してsc.versionを実行します。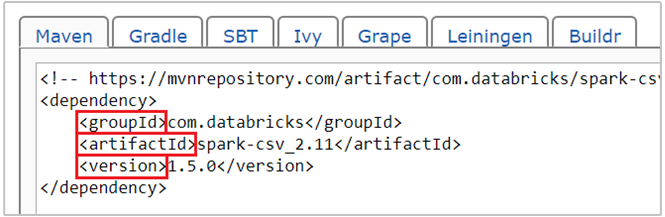
c. 3 つの値をコロン ( : ) で区切って連結します。
com.databricks:spark-csv_2.11:1.5.0%%configureマジックのコード セルを実行します。 これで、指定したパッケージを使用するように基になる Livy セッションが構成されます。 これでノートブック内の後続セルで、指定したパッケージを使用できるようになります (以下の例を参照)。val df = spark.read.format("com.databricks.spark.csv"). option("header", "true"). option("inferSchema", "true"). load("wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv")HDInsight 3.4 以下の場合、次のスニペットをご利用ください。
val df = sqlContext.read.format("com.databricks.spark.csv"). option("header", "true"). option("inferSchema", "true"). load("wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv")前の手順で作成したデータフレームからのデータは、以下のスニペットで表示できます。
df.show() df.select("Time").count()
関連項目
シナリオ
- Apache Spark と BI:HDInsight と BI ツールで Spark を使用した対話型データ分析の実行
- Apache Spark と Machine Learning: HDInsight で Spark を使用して、HVAC データを使用して建物の温度を分析する
- Apache Spark と Machine Learning:HDInsight で Spark を使用して食品の検査結果を予測する
- HDInsight 上での Apache Spark を使用した Web サイト ログ分析
アプリケーションの作成と実行
ツールと拡張機能
- HDInsight Linux の Apache Spark クラスターの Jupyter Notebook で外部の Python パッケージを使用する
- IntelliJ IDEA 用の HDInsight Tools プラグインを使用して Spark Scala アプリケーションを作成し、送信する
- IntelliJ IDEA 用の HDInsight Tools プラグインを使用して Apache Spark アプリケーションをリモートでデバッグする
- HDInsight 上の Apache Spark クラスターで Apache Zeppelin Notebook を使用する
- HDInsight 用の Apache Spark クラスター内の Jupyter Notebook で使用可能なカーネル
- Jupyter をコンピューターにインストールして HDInsight Spark クラスターに接続する