Azure HDInsight で実行される Apache Spark ジョブのデバッグ
この記事では、HDInsight クラスターで実行されている Apache Spark ジョブを追跡およびデバッグする方法について説明します。 Apache Hadoop YARN UI、Spark UI、および Spark History Server を使用してデバッグします。 まず、「Machine Learning:MLLib を使用した食品検査データの予測分析」で使用した Spark クラスターのノートブックを使用して Spark ジョブを実行します。 以下の手順を使用して、他の方法 (spark-submit など) を使って送信したアプリケーションも追跡します。
Azure サブスクリプションをお持ちでない場合は、開始する前に 無料アカウント を作成してください。
前提条件
HDInsight での Apache Spark クラスター。 手順については、「 Create Apache Spark clusters in Azure HDInsight (Azure HDInsight での Apache Spark クラスターの作成)」を参照してください。
「 Machine Learning:MLlib を使用した食品検査データの予測分析 」のノートブックが既に実行されているはずです。 このノートブックの実行方法については、リンク先のページを参照してください。
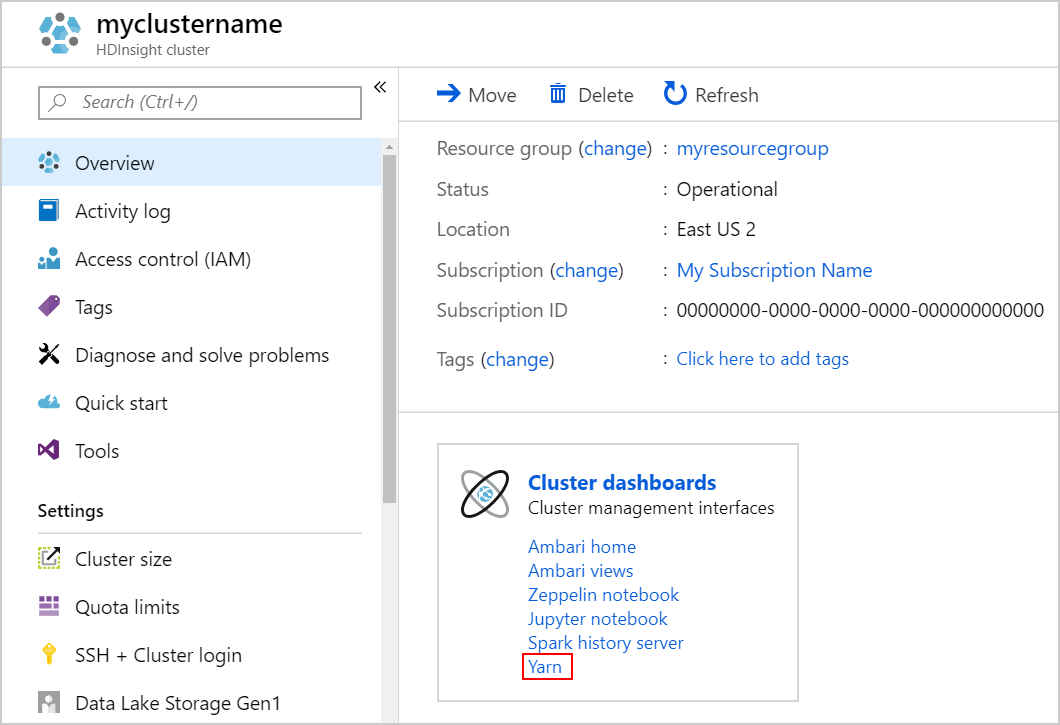
YARN UI でのアプリケーションの追跡
YARN UI を起動します。 [クラスター ダッシュボード] で [Yarn] を選択します。
ヒント
Ambari UI から YARN UI を起動してもかまいません。 Ambari UI を起動するには、 [クラスター ダッシュボード] で [Ambari ホーム] を選択します。 Ambari UI で、[YARN]>[Quick Links]\(クイック リンク\)> アクティブな Resource Manager >[Resource Manager UI] に移動します。
Jupyter Notebook を使用して Spark ジョブを開始したため、アプリケーションの名前は remotesparkmagics (ノートブックから開始されたすべてのアプリケーション用の名前) になっています。 ジョブに関する詳しい情報を確認するには、アプリケーション名に対応するアプリケーション ID を選択します。 この操作により、アプリケーション ビューが起動されます。
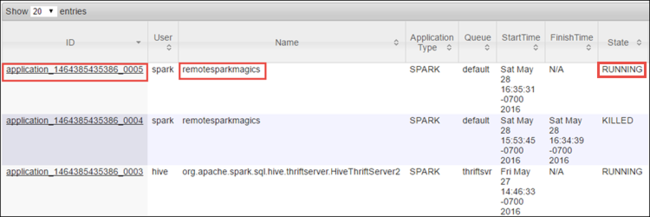
Jupyter Notebook から起動されたアプリケーションの場合、ノートブックを終了するまでステータスは常に [実行中] になります。
アプリケーション ビューからドリルダウンして、アプリケーションやログ (stdout/stderr) に関連付けられているコンテナーを探すことができます。 次のように、 [追跡 URL] に対応するリンクをクリックして Spark UI を起動することもできます。
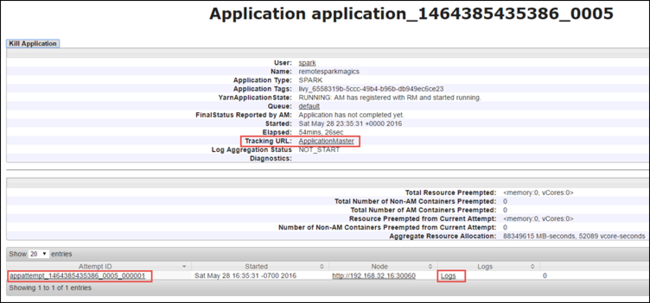
Spark UI でのアプリケーションの追跡
以前アプリケーションを実行したときに生成された Spark ジョブは、Spark UI からドリルダウンすることができます。
Spark UI を起動するには、アプリケーション ビューから [追跡 URL] に対応するリンクを選択します (上のスクリーン ショットを参照)。 Jupyter Notebook で実行中のアプリケーションによって開始されたすべての Spark ジョブを表示できます。
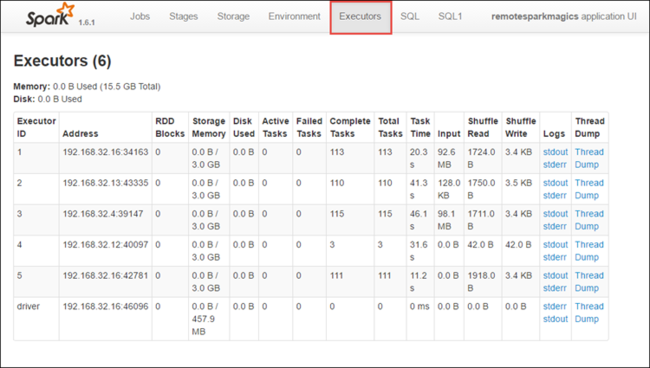
[Executors] タブを選択すると、実行プログラムごとの処理やストレージの情報が表示されます。 [Thread Dump]\(スレッド ダンプ\) リンクを選択して、呼び出し履歴を取得することもできます。
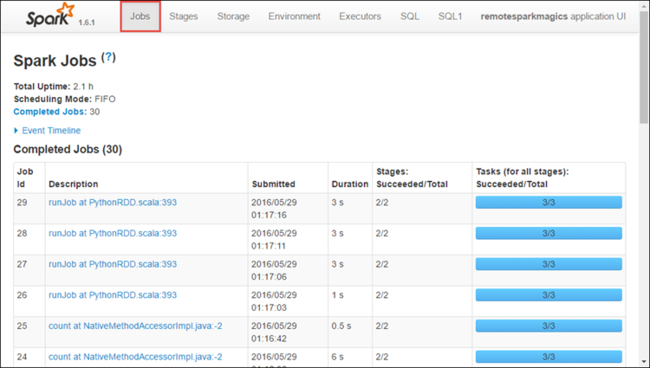
アプリケーションに関連するステージを確認するには、 [Stages]\(ステージ\) タブを選択します。
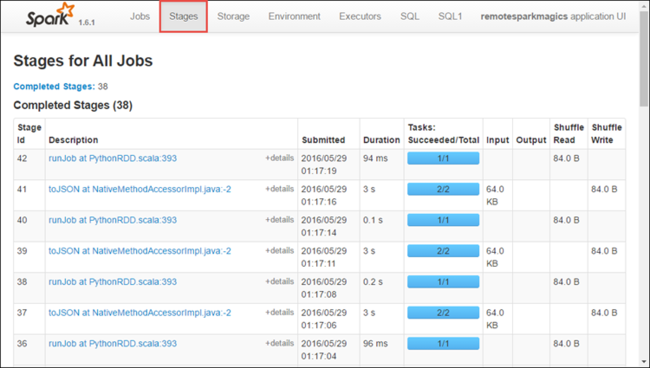
1 つのステージに複数のタスクが存在する場合もあり、対応する実行の統計を表示することができます (下図参照)。
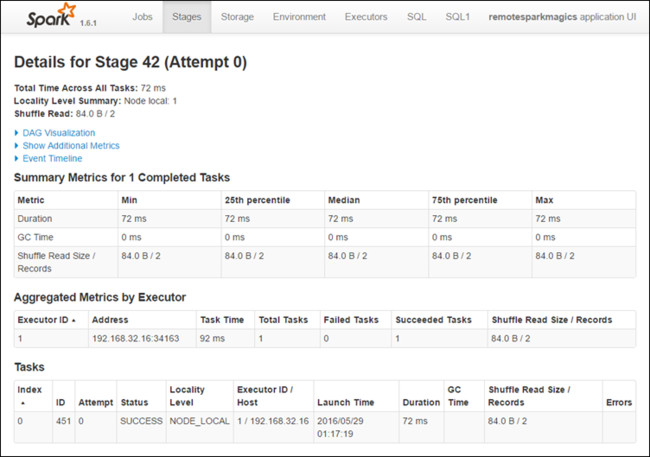
ステージの詳細ページから DAG Visualization を起動できます。 以下に示したように、ページの上部にある [DAG Visualization] リンクを展開してください。
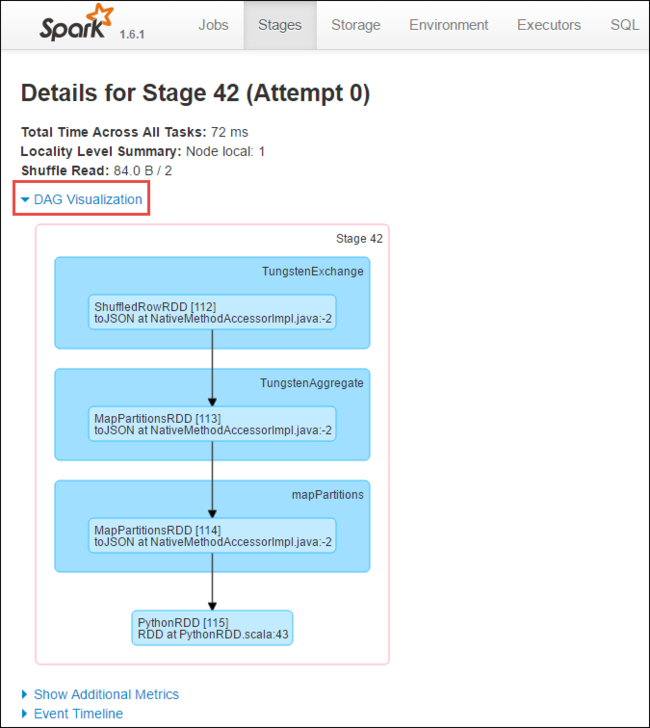
DAG (Direct Aclyic Graph) は、アプリケーション内の各種ステージを表します。 グラフ内の青色のボックスはそれぞれ、アプリケーションから呼び出された Spark 操作を表します。
ステージの詳細ページから、アプリケーションのタイムライン ビューを起動することもできます。 以下に示したように、ページの上部にある [Event Timeline (イベントのタイムライン)] リンクを展開してください。
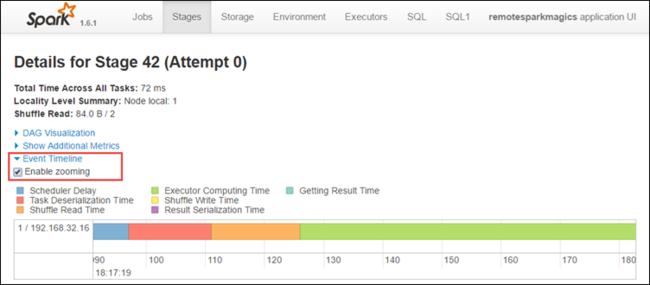
この画像には、Spark イベントがタイムラインの形式で表示されています。 タイムライン ビューには 3 種類の表示があります (ジョブ間、ジョブ内、ステージ内)。 上の画像は、特定のステージのタイムライン ビューをキャプチャしたものです。
ヒント
[Enable zooming (ズームを有効にする)] チェック ボックスをオンにすると、タイムライン ビューを左右にスクロールすることができます。
Spark UI には、Spark インスタンスに関する有益な情報を得ることのできるタブが他にもあります。
- [ストレージ] タブ - アプリケーション上で RDD が作成されると、[ストレージ] タブ内で情報を確認できます。
- [環境] タブ: このタブには、Spark インスタンスに関する有益な情報が表示されます。その例を次に示します。
- Scala バージョン
- クラスターに関連付けられているイベント ログ ディレクトリ
- アプリケーションの Executor のコア数
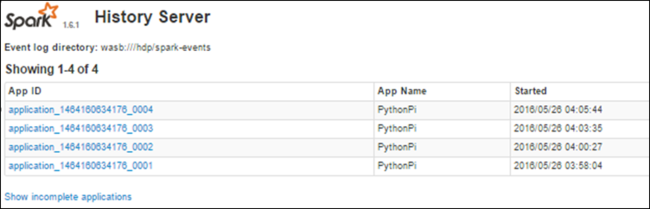
完了したジョブに関する情報を Spark History Server で探す
完了したジョブに関する情報は、Spark History Server に保存されています。
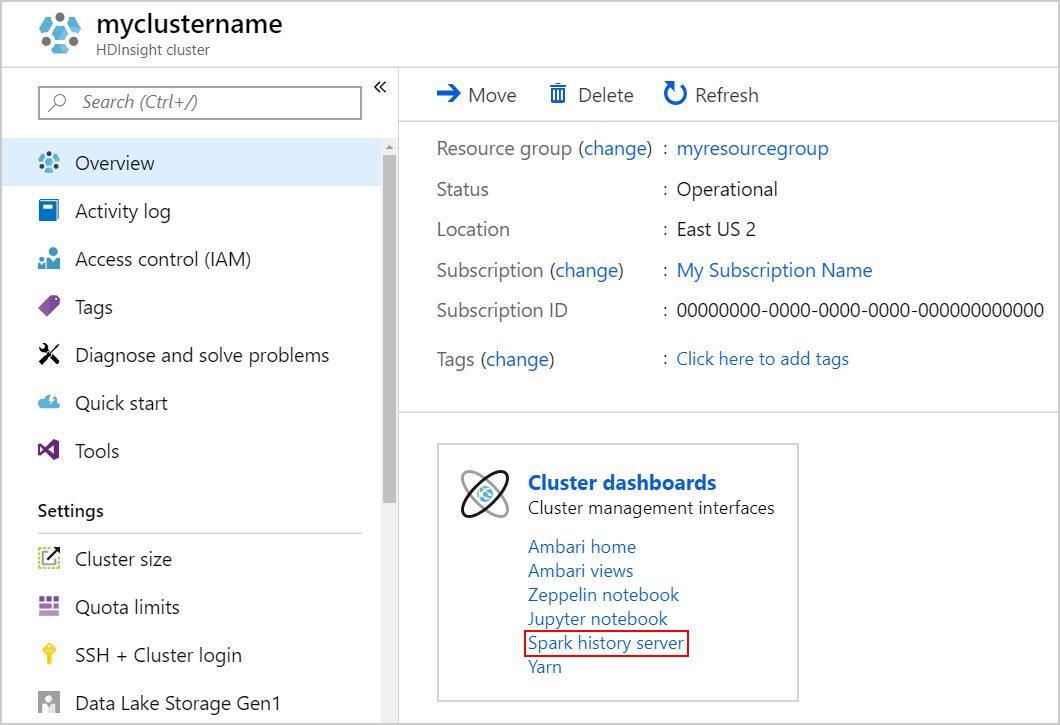
Spark History Server を起動するには、 [概要] ページの [クラスター ダッシュボード] で [Spark History Server] を選択します。
ヒント
Ambari UI から Spark History Server の UI を起動してもかまいません。 Ambari UI を起動するには、[概要] ブレードの [クラスター ダッシュボード] で [Ambari ホーム] を選択します。 Ambari UI で、 [Spark2]>[クイック リンク]>[Spark2 History Server UI]\(Spark2 History Server の UI\) に移動します。
完了済みのすべてのアプリケーションが一覧表示されます。 アプリケーションをドリルダウンして、より詳しい情報を入手するには、アプリケーション ID を選択します。