チュートリアル:HDInsight での Power BI を使用した Apache Spark データの分析
このチュートリアルでは、Microsoft Power BI を使用して Azure HDInsight で Apache Spark クラスター内のデータを視覚化する方法を学習します。
このチュートリアルでは、以下の内容を学習します。
- Power BI を使用して Spark データを視覚化する
Azure サブスクリプションをお持ちでない場合は、開始する前に 無料アカウント を作成してください。
前提条件
「チュートリアル: Azure HDInsight での Apache Spark クラスターへのデータの読み込みとクエリの実行」の記事を完了します。
省略可能:Power BI 試用版サブスクリプション。
データの検証
前のチュートリアルで作成した Jupyter Notebook には、hvac テーブルを作成するためのコードが含まれています。 この表は、\HdiSamples\HdiSamples\SensorSampleData\hvac\hvac.csv にあるすべての HDInsight Spark クラスターで使用可能な CSV ファイルに基づいています。 データの検証に使用する手順は、以下のとおりです。
Jupyter Notebook から次のコードを貼り付けて、Shift + Enter キーを押します。 このコードによってテーブルの存在が検証されます。
%%sql SHOW TABLES出力は次のようになります。
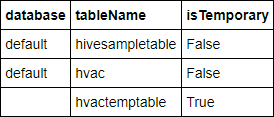
このチュートリアルを開始する前に Notebook を閉じると、
hvactemptableはクリーンアップされるため、出力に含まれません。 BI ツールからアクセスできるのは、metastore に保存された Hive テーブル (isTemporary 列に False と表示される) のみです。 このチュートリアルでは、作成した hvac テーブルに接続します。次のコードを空のセルに貼り付け、Shift + Enter キーを押します。 このコードによってテーブル内のデータが検証されます。
%%sql SELECT * FROM hvac LIMIT 10出力は次のようになります。
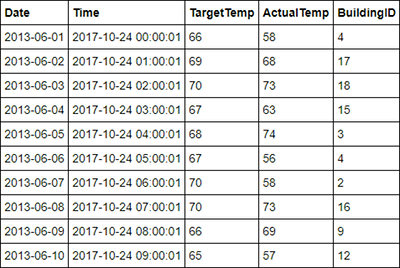
ノートブックの [File](ファイル) メニューの [Close and Halt](閉じて停止) を選びます。 Notebook をシャットダウンしてリソースを解放します。
データの視覚化
このセクションでは、Power BI を使用して Spark クラスター データから視覚エフェクト、レポート、およびダッシュボードを作成します。
Power BI Desktop でレポートを作成する
Spark を操作する最初のステップでは、Power BI Desktop のクラスターに接続し、クラスターからデータを読み込み、そのデータを基に基本的な視覚エフェクトを作成します。
Power BI Desktop を開きます。 起動のスプラッシュ画面が開いていれば閉じます。
[ホーム] タブから、 [データの取得]>[その他...] に移動します。
検索ボックスに「
Spark」と入力し、 [Azure HDInsight Spark] 、 [接続] の順に選択します。
[サーバー] テキスト ボックスにクラスター URL を (
mysparkcluster.azurehdinsight.netの形式で) 入力します。[データ接続モード] で、 [DirectQuery] を選択します。 [OK] をクリックします。
Spark では、いずれかのデータ接続モードをご利用いただけます。 DirectQuery を使用する場合、データセット全体を更新しなくても変更がレポートに反映されます。 データをインポートする場合は、データセットを更新して変更内容を確認する必要があります。 DirectQuery をいつ、どのように使用するかの詳細については、「Power BI で DirectQuery を使用する」をご覧ください。
HDInsight のログイン アカウント情報を入力し、 [接続] を選択します。 既定のアカウント名は admin です。
hvacテーブルを選択し、データのプレビューが表示されるのを待ってから、 [読み込み] を選択します。
Spark クラスターに接続し、
hvacテーブルからデータを読み込むために必要な情報が Power BI Desktop に整いました。 [フィールド] ウィンドウにテーブルとその列が表示されます。各ビルの目標温度と実際の温度の差を視覚化します。
[視覚エフェクト] ウィンドウで [面グラフ] を選択します。
[BuildingID] フィールドを軸にドラッグし、 [ActualTemp] と [TargetTemp] の各フィールドを値にドラッグします。
図は次のようになります。
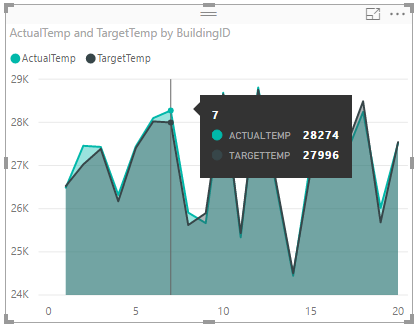
既定では、ActualTemp および TargetTemp の合計が表示されます。 [視覚化] ペイン内の ActualTemp と TargetTemp の横にある下矢印を選択すると、[合計] が選択されていることを確認できます。
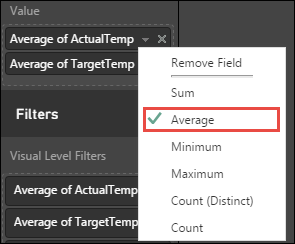
[視覚化] ペイン内の ActualTemp と TargetTemp の横にある下矢印を選択し、[平均] を選択して、各ビルの実際の温度と目標温度の平均を取得します。
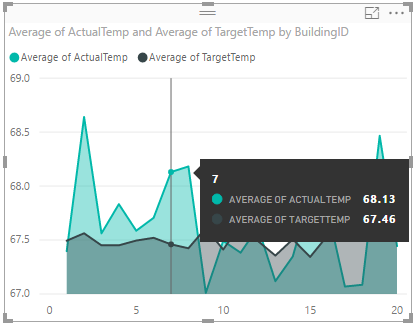
次のスクリーンショットのようにデータが視覚化されます。 グラフの上にカーソルを移動すると、関連データを含むツール ヒントが表示されます。
[ファイル]>[保存] に移動し、ファイルの名前
BuildingTemperatureを入力して [保存] を選択します。
Power BI サービスにレポートを発行する (省略可能)
Power BI サービスを使用すると、組織全体でレポートとダッシュボードを共有できます。 このセクションでは、まずデータセットとレポートを発行します。 次に、このレポートをダッシュボードにピン留めします。 通常、ダッシュボードは、レポート内のデータのサブセットにフォーカスするために使用します。 レポート内にある視覚エフェクトは 1 つのみですが、それでも手順を実行するのに役立ちます。
Power BI Desktop を開きます。
[ホーム] タブで [発行] を選択します。

データセットを発行してレポートするワークスペースを選択して、 [選択] をクリックします。 次の図では、既定値の [マイ ワークスペース] が選択されています。
発行に成功したら、 [Open 'BuildingTemperature.pbix' in Power BI]('BuildingTemperature.pbix' を Power BI で開く) を選択します。
Power BI サービスで、 [資格情報を入力する] を選択します。

[資格情報を編集] を選択します。
HDInsight のログイン アカウント情報を入力し、 [サインイン] を選択します。 既定のアカウント名は admin です。
左ペインで [ワークスペース]>[マイ ワークスペース]>[レポート] の順に移動して、 [BuildingTemperature] を選択します。
左ウィンドウ枠の [データセット] にも [BuildingTemperature] が表示されます。
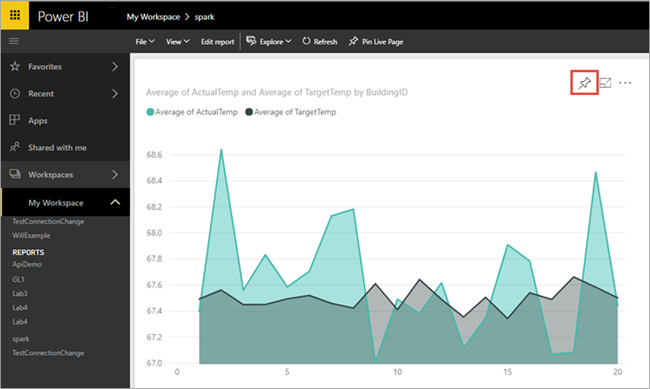
これで、Power BI Desktop で作成したビジュアルが Power BI サービスで使用できるようになりました。
視覚エフェクトにカーソルを合わせ、右上隅のピン アイコンを選択します。
[新しいダッシュボード] を選択して、名前
Building temperatureを入力し、 [ピン留め] を選択します。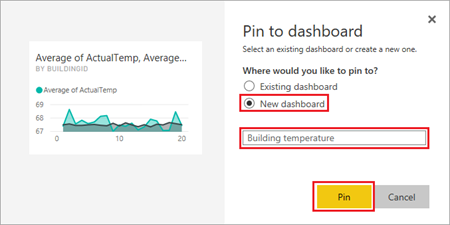
レポートで、 [ダッシュボードへ移動] を選択します。
ビジュアルはダッシュボードにピン留めされます。他のビジュアルをレポートに追加して、同じダッシュボードにピン留めすることもできます。 レポートとダッシュボードの詳細については、「Power BI のレポート」のほか、Power BI のダッシュボードに関する記事を参照してください。
リソースをクリーンアップする
チュートリアルを完了したら、必要に応じてクラスターを削除できます。 HDInsight を使用すると、データは Azure Storage に格納されるため、クラスターは、使用されていない場合に安全に削除できます。 また、HDInsight クラスターは、使用していない場合でも課金されます。 クラスターの料金は Storage の料金の何倍にもなるため、クラスターを使用しない場合は削除するのが経済的にも合理的です。
クラスターを削除するには、「ブラウザー、PowerShell、または Azure CLI を使用して HDInsight クラスターを削除する」を参照してください。
次のステップ
このチュートリアルでは、Microsoft Power BI を使用して Azure HDInsight で Apache Spark クラスター内のデータを視覚化する方法を学習しました。 次の記事に進み、Machine Learning アプリケーションを作成できることを確認します。