Apache Spark MLlib を使用して Machine Learning アプリケーションを構築し、データセットを分析する
Apache Spark MLlib を使用し、機械学習アプリケーションを作成する方法について説明します。 このアプリケーションは、オープン データセットに対する予測分析を実行します。 Spark の組み込みの Machine Learning ライブラリから、この例ではロジスティック回帰による分類を使用します。
MLlib は、次のような機械学習タスクに役立つ多数のユーティリティを提供する、コア Spark ライブラリです。
- 分類
- 回帰
- クラスタリング
- モデリング
- 特異値分解 (SVD) と主成分分析 (PCA)
- 仮説テストとサンプル統計の計算
分類およびロジスティック回帰について
一般的な Machine Learning タスクである分類は、入力データをカテゴリに分類するプロセスです。 ユーザーが指定した入力データに "ラベル" を割り当てる方法を決定するのは、分類アルゴリズムの仕事です。 たとえば、入力として在庫情報を受け取る機械学習アルゴリズムを思い浮かべてください。 在庫を 2 つのカテゴリに分割します。販売する在庫と取っておく在庫です。
ロジスティック回帰は、分類に使用するアルゴリズムです。 Spark のロジスティック回帰 API は、 二項分類(入力データを 2 つのグループのいずれかに分類する) に適しています。 ロジスティック回帰の詳細については、 Wikipediaを参照してください。
まとめると、ロジスティック回帰のプロセスから "ロジスティック関数" が作られます。 この関数を使用し、あるグループか別のグループに入力ベクトルが属する確率を予測します。
食品調査データの予測分析の例
この例では、Spark を使用し、飲食施設検査データで予測分析を実行します (Food_Inspections1.csv)。 シカゴ市のデータ ポータルから取得したデータ。 このデータセットには、シカゴで実施された飲食施設検査に関する情報が含まれています。 施設別の情報、見つかった違反 (該当する場合)、検査結果が含まれます。 CSV データ ファイルは、クラスターに関連付けられたストレージ アカウントの /HdiSamples/HdiSamples/FoodInspectionData/Food_Inspections1.csv に既に用意されています。
次の手順で、食品検査に合格または不合格になる理由を示すモデルを作成します。
Apache Spark MLlib 機械学習アプリを作成する
PySpark カーネルを使用して Jupyter Notebook を作成します。 手順については、「Jupyter Notebook ファイルの作成」を参照してください。
このアプリケーションに必要な型をインポートします。 次のコードをコピーして空のセルに貼り付け、Shift + Enter キーを押します。
from pyspark.ml import Pipeline from pyspark.ml.classification import LogisticRegression from pyspark.ml.feature import HashingTF, Tokenizer from pyspark.sql import Row from pyspark.sql.functions import UserDefinedFunction from pyspark.sql.types import *PySpark カーネルであるため、コンテキストを明示的に作成する必要はありません。 最初のコード セルを実行すると、Spark と Hive コンテキストが自動的に作成されます。
入力データフレームを作成する
Spark コンテキストを使用し、未加工の CSV データを非構造化テキストとしてメモリにプルします。 次に、Python の CSV ライブラリを使用してデータの各行を解析します。
次の行を実行して、入力データをインポートおよび解析し、Resilient Distributed Dataset (RDD) を作成します。
def csvParse(s): import csv from io import StringIO sio = StringIO(s) value = next(csv.reader(sio)) sio.close() return value inspections = sc.textFile('/HdiSamples/HdiSamples/FoodInspectionData/Food_Inspections1.csv')\ .map(csvParse)次のコードを実行して RDD から 1 つの行を取得すると、そのデータ スキーマを確認できます。
inspections.take(1)出力は次のようになります。
[['413707', 'LUNA PARK INC', 'LUNA PARK DAY CARE', '2049789', "Children's Services Facility", 'Risk 1 (High)', '3250 W FOSTER AVE ', 'CHICAGO', 'IL', '60625', '09/21/2010', 'License-Task Force', 'Fail', '24. DISH WASHING FACILITIES: PROPERLY DESIGNED, CONSTRUCTED, MAINTAINED, INSTALLED, LOCATED AND OPERATED - Comments: All dishwashing machines must be of a type that complies with all requirements of the plumbing section of the Municipal Code of Chicago and Rules and Regulation of the Board of Health. OBSEVERD THE 3 COMPARTMENT SINK BACKING UP INTO THE 1ST AND 2ND COMPARTMENT WITH CLEAR WATER AND SLOWLY DRAINING OUT. INST NEED HAVE IT REPAIR. CITATION ISSUED, SERIOUS VIOLATION 7-38-030 H000062369-10 COURT DATE 10-28-10 TIME 1 P.M. ROOM 107 400 W. SURPERIOR. | 36. LIGHTING: REQUIRED MINIMUM FOOT-CANDLES OF LIGHT PROVIDED, FIXTURES SHIELDED - Comments: Shielding to protect against broken glass falling into food shall be provided for all artificial lighting sources in preparation, service, and display facilities. LIGHT SHIELD ARE MISSING UNDER HOOD OF COOKING EQUIPMENT AND NEED TO REPLACE LIGHT UNDER UNIT. 4 LIGHTS ARE OUT IN THE REAR CHILDREN AREA,IN THE KINDERGARDEN CLASS ROOM. 2 LIGHT ARE OUT EAST REAR, LIGHT FRONT WEST ROOM. NEED TO REPLACE ALL LIGHT THAT ARE NOT WORKING. | 35. WALLS, CEILINGS, ATTACHED EQUIPMENT CONSTRUCTED PER CODE: GOOD REPAIR, SURFACES CLEAN AND DUST-LESS CLEANING METHODS - Comments: The walls and ceilings shall be in good repair and easily cleaned. MISSING CEILING TILES WITH STAINS IN WEST,EAST, IN FRONT AREA WEST, AND BY THE 15MOS AREA. NEED TO BE REPLACED. | 32. FOOD AND NON-FOOD CONTACT SURFACES PROPERLY DESIGNED, CONSTRUCTED AND MAINTAINED - Comments: All food and non-food contact equipment and utensils shall be smooth, easily cleanable, and durable, and shall be in good repair. SPLASH GUARDED ARE NEEDED BY THE EXPOSED HAND SINK IN THE KITCHEN AREA | 34. FLOORS: CONSTRUCTED PER CODE, CLEANED, GOOD REPAIR, COVING INSTALLED, DUST-LESS CLEANING METHODS USED - Comments: The floors shall be constructed per code, be smooth and easily cleaned, and be kept clean and in good repair. INST NEED TO ELEVATE ALL FOOD ITEMS 6INCH OFF THE FLOOR 6 INCH AWAY FORM WALL. ', '41.97583445690982', '-87.7107455232781', '(41.97583445690982, -87.7107455232781)']]この出力により、入力ファイルのスキーマの概要を把握できます。 これには各施設の名前と施設の種類が含まれています。 また、住所、検査データ、場所などが含まれています。
次のコードを実行して、データフレーム (df) と、予測分析に役立ついくつかの列を含む一時テーブル (CountResults) を作成します。
sqlContextを使用し、構造化データに対して変換を実行します。schema = StructType([ StructField("id", IntegerType(), False), StructField("name", StringType(), False), StructField("results", StringType(), False), StructField("violations", StringType(), True)]) df = spark.createDataFrame(inspections.map(lambda l: (int(l[0]), l[1], l[12], l[13])) , schema) df.registerTempTable('CountResults')データフレームに含まれている 4 つの対象の列とは、ID、name、results、violations です。
次のコードを実行して、データの小さなサンプルを取得します。
df.show(5)出力は次のようになります。
+------+--------------------+-------+--------------------+ | id| name|results| violations| +------+--------------------+-------+--------------------+ |413707| LUNA PARK INC| Fail|24. DISH WASHING ...| |391234| CAFE SELMARIE| Fail|2. FACILITIES TO ...| |413751| MANCHU WOK| Pass|33. FOOD AND NON-...| |413708|BENCHMARK HOSPITA...| Pass| | |413722| JJ BURGER| Pass| | +------+--------------------+-------+--------------------+
データを理解する
データセットの内容を理解しましょう。
次のコードを実行して、results 列の個別の値を表示します。
df.select('results').distinct().show()出力は次のようになります。
+--------------------+ | results| +--------------------+ | Fail| |Business Not Located| | Pass| | Pass w/ Conditions| | Out of Business| +--------------------+次のコードを実行して、これらの結果の分布を視覚化します。
%%sql -o countResultsdf SELECT COUNT(results) AS cnt, results FROM CountResults GROUP BY results%%sqlマジックの後に-o countResultsdfと入力して、クエリの出力が Jupyter サーバー (通常はクラスターのヘッドノード) にローカルに保持されるようにします。 出力は、指定された countResultsdf という名前で Pandasデータフレームとして保存されます。%%sqlマジックや、PySpark カーネルで使用可能なその他のマジックの詳細については、Apache Spark HDInsight クラスターの Jupyter Notebook で使用可能なカーネルに関するページを参照してください。出力は次のようになります。
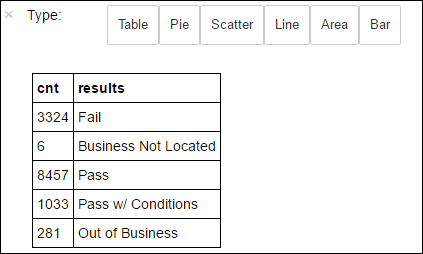
データの視覚効果の構築に使用するライブラリ、Matplotlib を使用して、プロットを作成することもできます。 プロットはローカルに保存された countResultsdf データフレームから作成する必要があるため、コード スニペットは
%%localマジックで始める必要があります。 このアクションにより、コードは Jupyter サーバーでローカルに実行されます。%%local %matplotlib inline import matplotlib.pyplot as plt labels = countResultsdf['results'] sizes = countResultsdf['cnt'] colors = ['turquoise', 'seagreen', 'mediumslateblue', 'palegreen', 'coral'] plt.pie(sizes, labels=labels, autopct='%1.1f%%', colors=colors) plt.axis('equal')食品検査の結果を予測するには、違反に基づくモデルを開発する必要があります。 ロジスティック回帰は二項分類メソッドであるため、結果データをFail と Pass の 2 つのカテゴリにグループ化することは意味があります。
合格
- 合格
- 条件付きで合格
失敗
- 失敗
破棄
- 事業体が存在しない
- 廃業
その他の結果のデータ ("事業体が存在しない" や "廃業") は役に立ちませんが、いずれにしても、これらが結果に占める割合はわずかです。
次のコードを実行して、既存のデータフレーム (
df) を、各検査がラベルと違反のペアとして表される新しいデータフレームに変換します。 ここでは、ラベル0.0は失敗、ラベル1.0は成功、ラベル-1.0はこれら 2 つの結果以外の何らかの結果であることを表します。def labelForResults(s): if s == 'Fail': return 0.0 elif s == 'Pass w/ Conditions' or s == 'Pass': return 1.0 else: return -1.0 label = UserDefinedFunction(labelForResults, DoubleType()) labeledData = df.select(label(df.results).alias('label'), df.violations).where('label >= 0')次のコードを実行して、ラベル付きデータの 1 行を表示します。
labeledData.take(1)出力は次のようになります。
[Row(label=0.0, violations=u"41. PREMISES MAINTAINED FREE OF LITTER, UNNECESSARY ARTICLES, CLEANING EQUIPMENT PROPERLY STORED - Comments: All parts of the food establishment and all parts of the property used in connection with the operation of the establishment shall be kept neat and clean and should not produce any offensive odors. REMOVE MATTRESS FROM SMALL DUMPSTER. | 35. WALLS, CEILINGS, ATTACHED EQUIPMENT CONSTRUCTED PER CODE: GOOD REPAIR, SURFACES CLEAN AND DUST-LESS CLEANING METHODS - Comments: The walls and ceilings shall be in good repair and easily cleaned. REPAIR MISALIGNED DOORS AND DOOR NEAR ELEVATOR. DETAIL CLEAN BLACK MOLD LIKE SUBSTANCE FROM WALLS BY BOTH DISH MACHINES. REPAIR OR REMOVE BASEBOARD UNDER DISH MACHINE (LEFT REAR KITCHEN). SEAL ALL GAPS. REPLACE MILK CRATES USED IN WALK IN COOLERS AND STORAGE AREAS WITH PROPER SHELVING AT LEAST 6' OFF THE FLOOR. | 38. VENTILATION: ROOMS AND EQUIPMENT VENTED AS REQUIRED: PLUMBING: INSTALLED AND MAINTAINED - Comments: The flow of air discharged from kitchen fans shall always be through a duct to a point above the roofline. REPAIR BROKEN VENTILATION IN MEN'S AND WOMEN'S WASHROOMS NEXT TO DINING AREA. | 32. FOOD AND NON-FOOD CONTACT SURFACES PROPERLY DESIGNED, CONSTRUCTED AND MAINTAINED - Comments: All food and non-food contact equipment and utensils shall be smooth, easily cleanable, and durable, and shall be in good repair. REPAIR DAMAGED PLUG ON LEFT SIDE OF 2 COMPARTMENT SINK. REPAIR SELF CLOSER ON BOTTOM LEFT DOOR OF 4 DOOR PREP UNIT NEXT TO OFFICE.")]
入力データ フレームからロジスティック回帰モデルを作成する
最後のタスクは、ラベルの付いたデータを変換することです。 ロジスティック回帰で分析するための形式にデータを変換します。 ロジスティック回帰アルゴリズムに入力するには、"ラベルと特徴ベクトルの組み" が必要です。 "特徴ベクトル" は、入力ポイントを表す数値のベクトルです。 そのため、半構造化され、多くのフリー テキストによるコメントを含む "violations" 列を変換する必要があります。 コンピューターが簡単に理解できる実数の配列に列を変換します。
自然言語を処理するための標準的な機械学習手法の 1 つは、個々の単語にインデックス を割り当てることです。 その後、機械学習アルゴリズムにベクトルを渡します。 そうすることで、各インデックスの値には、テキスト文字列におけるその単語の相対的頻度が含まれます。
MLlib により、この操作を簡単に実行する方法が提供されます。 まず、違反している各文字列を「トークン化」して、各文字列の個々の単語を取得します。 次に、HashingTF を使用してトークンの各セットを特徴ベクトルに変換し、それをロジスティック回帰アルゴリズムに渡してモデルを構築します。 これらすべての手順は、パイプラインを使用したシーケンスの中で実行します。
tokenizer = Tokenizer(inputCol="violations", outputCol="words")
hashingTF = HashingTF(inputCol=tokenizer.getOutputCol(), outputCol="features")
lr = LogisticRegression(maxIter=10, regParam=0.01)
pipeline = Pipeline(stages=[tokenizer, hashingTF, lr])
model = pipeline.fit(labeledData)
別のデータセットを使用してモデルを評価する
前に作成したモデルを使用すると、新しい検査結果を予測できます。 予測はどのくらい違反が観察されたかに基づきます。 データセット Food_Inspections1.csv でこのモデルをトレーニングしました。 2 つ目のデータセット Food_Inspections2.csv を使用して、新しいデータでこのモデルの強度を "評価" できます。 この 2 つ目のデータ セット (Food_Inspections2.csv) は、クラスターに関連付けられている既定のストレージ コンテナーに存在しています。
次のコードを実行して、モデルによって生成された予測を含む、新しいデータフレーム predictionsDf を作成します。 このスニペットでは、データフレームに基づいた Predictions と呼ばれる一時テーブルも作成します。
testData = sc.textFile('wasbs:///HdiSamples/HdiSamples/FoodInspectionData/Food_Inspections2.csv')\ .map(csvParse) \ .map(lambda l: (int(l[0]), l[1], l[12], l[13])) testDf = spark.createDataFrame(testData, schema).where("results = 'Fail' OR results = 'Pass' OR results = 'Pass w/ Conditions'") predictionsDf = model.transform(testDf) predictionsDf.registerTempTable('Predictions') predictionsDf.columns次のテキストのような結果が表示されます。
['id', 'name', 'results', 'violations', 'words', 'features', 'rawPrediction', 'probability', 'prediction']予測のいずれかを確認します。 このスニペットを実行します。
predictionsDf.take(1)テスト データ セットの最初のエントリの予測が表示されます。
model.transform()メソッドは、同じスキーマを持つ新しいデータに同じ変換を適用し、データの分類方法の予測に到達します。 予測の精度を把握するための統計を実行できます。numSuccesses = predictionsDf.where("""(prediction = 0 AND results = 'Fail') OR (prediction = 1 AND (results = 'Pass' OR results = 'Pass w/ Conditions'))""").count() numInspections = predictionsDf.count() print ("There were", numInspections, "inspections and there were", numSuccesses, "successful predictions") print ("This is a", str((float(numSuccesses) / float(numInspections)) * 100) + "%", "success rate")出力は次のテキストのようになります。
There were 9315 inspections and there were 8087 successful predictions This is a 86.8169618894% success rateSpark でロジスティック回帰を使用すると、英語の違反の記述におけるリレーションシップのモデルが得られます。 また、特定の事業が飲食施設検査に合格するか、不合格になるかもわかります。
予測を視覚化する
このテスト結果の理解に役立つ最終的なグラフを作成します。
まず、先ほど作成した一時テーブル Predictions からさまざまな予測や結果を抽出します。 次のクエリでは、出力を true_positive、false_positive、true_negative、false_negative に分けています。 このクエリでは、
-qを使用して視覚化を無効にし、%%localマジックで使用できるデータフレームとして出力を保存 (-oを使用) します。%%sql -q -o true_positive SELECT count(*) AS cnt FROM Predictions WHERE prediction = 0 AND results = 'Fail'%%sql -q -o false_positive SELECT count(*) AS cnt FROM Predictions WHERE prediction = 0 AND (results = 'Pass' OR results = 'Pass w/ Conditions')%%sql -q -o true_negative SELECT count(*) AS cnt FROM Predictions WHERE prediction = 1 AND results = 'Fail'%%sql -q -o false_negative SELECT count(*) AS cnt FROM Predictions WHERE prediction = 1 AND (results = 'Pass' OR results = 'Pass w/ Conditions')最後に、次のスニペットを使用して、 Matplotlibを使ってプロットを生成します。
%%local %matplotlib inline import matplotlib.pyplot as plt labels = ['True positive', 'False positive', 'True negative', 'False negative'] sizes = [true_positive['cnt'], false_positive['cnt'], false_negative['cnt'], true_negative['cnt']] colors = ['turquoise', 'seagreen', 'mediumslateblue', 'palegreen', 'coral'] plt.pie(sizes, labels=labels, autopct='%1.1f%%', colors=colors) plt.axis('equal')次の出力が表示されます。
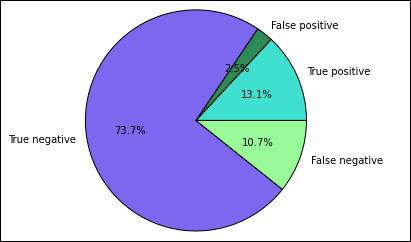
このグラフでは、「positive」の結果は食品検査の不合格を指し、「negative」の結果は、食品検査の合格を指します。
Notebook をシャットダウンする
アプリケーションの実行後は、ノートブックをシャットダウンしてリソースを解放する必要があります。 そのためには、Notebook の [ファイル] メニューの [Close and Halt] (閉じて停止) をクリックします。 このアクションにより Notebook がシャットダウンされ、Notebook が閉じます。