チュートリアル:Azure HDInsight で Apache Spark 機械学習アプリケーションを作成する
このチュートリアルでは、Jupyter Notebook を使用して、Azure HDInsight 用の Apache Spark 機械学習アプリケーションを作成する方法について説明します。
MLlib は、一般的な学習アルゴリズムとユーティリティで構成される Spark の適応性のある機械学習ライブラリです。 (分類、回帰、クラスタリング、協調フィルタリング、次元削減。さらに、基になっている最適化プリミティブ)。
このチュートリアルでは、以下の内容を学習します。
- Apache Spark 機械学習アプリケーションを開発する
前提条件
HDInsight での Apache Spark クラスター。 Apache Spark クラスターの作成に関するページを参照してください。
HDInsight の Spark での Jupyter Notebook の使用方法を熟知していること。 詳細については、HDInsight の Apache Spark を使用したデータの読み込みとクエリの実行に関するページを参照してください。
データ セットを理解する
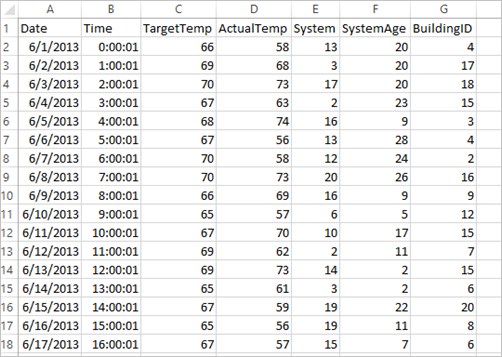
このアプリケーションでは、すべてのクラスターにおいて既定で利用可能なサンプル HVAC.csv データを使用します。 ファイルは \HdiSamples\HdiSamples\SensorSampleData\hvac にあります。 データは、HVAC (Heating, Ventilating, Air Conditioning: 冷暖房空調設備) システムがインストールされているいくつかのビルの目標温度と実際の温度を示します。 [System] 列はシステム ID を表し、 [SystemAge] 列は HVAC システムがビルに設置されてからの年数を表します。 目標温度、指定されたシステム ID、およびシステムの経過年数に基づいて、ビルが暑くなるか寒くなるかを予測できます。
Spark MLlib を使用した Spark Machine Learning アプリケーションの開発
このアプリケーションは、Spark の ML パイプラインを使用してドキュメントの分類を実行します。 ML パイプラインは、DataFrame の上に構築された高レベル API の統一されたセットを提供します。 DataFrame は、ユーザーが実用的な機械学習パイプラインを作成して調整するのに役立ちます。 パイプラインでは、ドキュメントを単語に分割し、単語を数値特徴ベクトルに変換して、最後に特徴ベクトルとラベルを使用して予測モデルを作成します。 アプリケーションを作成するには、次の手順を実行します。
PySpark カーネルを使用して Jupyter Notebook を作成します。 手順については、「Jupyter Notebook ファイルの作成」を参照してください。
このシナリオに必要な型をインポートします。 次のスニペットを空のセルに貼り付けて、 Shift + Enterキーを押します。
from pyspark.ml import Pipeline from pyspark.ml.classification import LogisticRegression from pyspark.ml.feature import HashingTF, Tokenizer from pyspark.sql import Row import os import sys from pyspark.sql.types import * from pyspark.mllib.classification import LogisticRegressionWithLBFGS from pyspark.mllib.regression import LabeledPoint from numpy import arrayデータ (hvac.csv) を読み込み、解析し、それを使用してモデルをトレーニングします。
# Define a type called LabelDocument LabeledDocument = Row("BuildingID", "SystemInfo", "label") # Define a function that parses the raw CSV file and returns an object of type LabeledDocument def parseDocument(line): values = [str(x) for x in line.split(',')] if (values[3] > values[2]): hot = 1.0 else: hot = 0.0 textValue = str(values[4]) + " " + str(values[5]) return LabeledDocument((values[6]), textValue, hot) # Load the raw HVAC.csv file, parse it using the function data = sc.textFile("/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") documents = data.filter(lambda s: "Date" not in s).map(parseDocument) training = documents.toDF()このコード スニペットでは、実際の温度と目標温度とを比較する関数を定義します。 実際の温度の方が高い場合、ビルは暑く、値 1.0で示されます。 それ以外の場合、ビルは寒く、値 0.0 で示されます。
tokenizer、hashingTF、lrという 3 つのステージで構成される Spark 機械学習パイプラインを構成します。tokenizer = Tokenizer(inputCol="SystemInfo", outputCol="words") hashingTF = HashingTF(inputCol=tokenizer.getOutputCol(), outputCol="features") lr = LogisticRegression(maxIter=10, regParam=0.01) pipeline = Pipeline(stages=[tokenizer, hashingTF, lr])パイプラインとそのしくみの詳細については、Apache Spark 機械学習パイプラインに関するページを参照してください。
パイプラインをトレーニング ドキュメントに適合させます。
model = pipeline.fit(training)トレーニング ドキュメントを検証してアプリケーションでの進行状況をチェックポイントします。
training.show()次のように出力されます。
+----------+----------+-----+ |BuildingID|SystemInfo|label| +----------+----------+-----+ | 4| 13 20| 0.0| | 17| 3 20| 0.0| | 18| 17 20| 1.0| | 15| 2 23| 0.0| | 3| 16 9| 1.0| | 4| 13 28| 0.0| | 2| 12 24| 0.0| | 16| 20 26| 1.0| | 9| 16 9| 1.0| | 12| 6 5| 0.0| | 15| 10 17| 1.0| | 7| 2 11| 0.0| | 15| 14 2| 1.0| | 6| 3 2| 0.0| | 20| 19 22| 0.0| | 8| 19 11| 0.0| | 6| 15 7| 0.0| | 13| 12 5| 0.0| | 4| 8 22| 0.0| | 7| 17 5| 0.0| +----------+----------+-----+生の CSV ファイルと照らして出力を比較します。 たとえば、CSV ファイルの最初の行のデータは次のとおりです。

実際の温度は目標温度より低く、ビルが寒いことを示します。 最初の行の label の値は 0.0 であり、ビルが暑くないことを意味します。
トレーニング済みのモデルを実行するようにデータ セットを準備します。 これを行うには、システム ID とシステムの経過年数 (トレーニング出力に SystemInfo として示されている) を渡します。 このモデルは、そのシステム ID とシステム経過年数のビルが、暑くなる (1.0 で示される) か、または寒くなる (0.0 で示される) かを予測します。
# SystemInfo here is a combination of system ID followed by system age Document = Row("id", "SystemInfo") test = sc.parallelize([("1L", "20 25"), ("2L", "4 15"), ("3L", "16 9"), ("4L", "9 22"), ("5L", "17 10"), ("6L", "7 22")]) \ .map(lambda x: Document(*x)).toDF()最後に、テスト データで予測を行います。
# Make predictions on test documents and print columns of interest prediction = model.transform(test) selected = prediction.select("SystemInfo", "prediction", "probability") for row in selected.collect(): print (row)次のように出力されます。
Row(SystemInfo=u'20 25', prediction=1.0, probability=DenseVector([0.4999, 0.5001])) Row(SystemInfo=u'4 15', prediction=0.0, probability=DenseVector([0.5016, 0.4984])) Row(SystemInfo=u'16 9', prediction=1.0, probability=DenseVector([0.4785, 0.5215])) Row(SystemInfo=u'9 22', prediction=1.0, probability=DenseVector([0.4549, 0.5451])) Row(SystemInfo=u'17 10', prediction=1.0, probability=DenseVector([0.4925, 0.5075])) Row(SystemInfo=u'7 22', prediction=0.0, probability=DenseVector([0.5015, 0.4985]))予測の最初の行を見てみます。 ID が 20 でシステムの経過年数が 25 年の HVAC システムでは、ビルが暑い (prediction=1.0) ことがわかります。 DenseVector の 1 番目の値 (0.49999) は予測 0.0 に対応し、2 番目の値 (0.5001) は予測 1.0 に対応します。 出力では、2 番目の値はわずかに高いだけですが、モデルは prediction=1.0を示します。
Notebook をシャットダウンしてリソースを解放します。 そのためには、Notebook の [ファイル] メニューの [Close and Halt] (閉じて停止) をクリックします。 このアクションにより Notebook がシャットダウンされ、Notebook が閉じます。
Spark Machine Learning での Anaconda scikit-learn ライブラリの使用
HDInsight の Apache Spark クラスターには、Anaconda ライブラリが含まれます。 これには、機械学習用の scikit-learn ライブラリも含まれます。 ライブラリには、Jupyter Notebook からサンプル アプリケーションを直接作成するために使用できるさまざまなデータ セットも含まれます。 scikit-learn ライブラリの使用例については、「https://scikit-learn.org/stable/auto_examples/index.html」を参照してください。
リソースをクリーンアップする
このアプリケーションを引き続き使用しない場合は、次の手順で作成したクラスターを削除します。
Azure portal にサインインします。
上部の検索ボックスに「HDInsight」と入力します。
[サービス] の下の [HDInsight クラスター] を選択します。
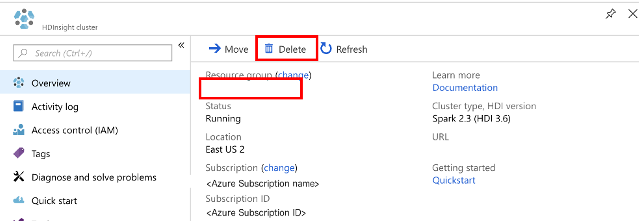
表示される HDInsight クラスターの一覧で、このチュートリアル用に作成したクラスターの横にある [...] を選択します。
[削除] を選択します。 はいを選択します。
次のステップ
このチュートリアルでは、Jupyter Notebook を使用して、Azure HDInsight 用の Apache Spark 機械学習アプリケーションを作成する方法について説明しました。 次のチュートリアルに進み、Spark ジョブに IntelliJ IDEA を使用する方法を学習してください。