チュートリアル:IntelliJ を使用した HDInsight での Apache Spark の Scala Maven アプリケーションの作成
このチュートリアルでは、Apache Maven と IntelliJ IDEA を利用し、Scala で記述された Apache Spark アプリケーションを作成する方法について説明します。 この記事では、ビルド システムとして Apache Maven を使用し、 IntelliJ IDEA で提供されている Scala 用の既存の Maven アーキタイプから始めます。 IntelliJ IDEA での Scala アプリケーションには次の手順があります。
- ビルド システムとして Maven を使用します。
- プロジェクト オブジェクト モデル (POM) ファイルを更新して、Spark モジュールの依存関係を解決します。
- Scala でアプリケーションを作成します。
- HDInsight Spark クラスターに送信できる jar ファイルを生成します。
- Livy を使用して Spark クラスターでアプリケーションを実行します。
このチュートリアルでは、以下の内容を学習します。
- IntelliJ IDEA 用の Scala プラグインをインストールする
- IntelliJ を使用して Scala Maven アプリケーションを開発する
- スタンドアロンの Scala プロジェクトを作成する
前提条件
HDInsight での Apache Spark クラスター。 手順については、「 Create Apache Spark clusters in Azure HDInsight (Azure HDInsight での Apache Spark クラスターの作成)」を参照してください。
Oracle Java Development Kit。 このチュートリアルでは、Java バージョン 8.0.202 を使用します。
Java IDE。 この記事では、IntelliJ IDEA Community 2018.3.4 を使用します。
Azure Toolkit for IntelliJ。 「Azure Toolkit for IntelliJ のインストール」を参照してください。
IntelliJ IDEA 用の Scala プラグインをインストールする
Scala プラグインをインストールするには、次の手順を実行します。
IntelliJ IDEA を開きます。
ようこそ画面で [構成]>[プラグイン] の順に移動し、 [プラグイン] ウィンドウを開きます。
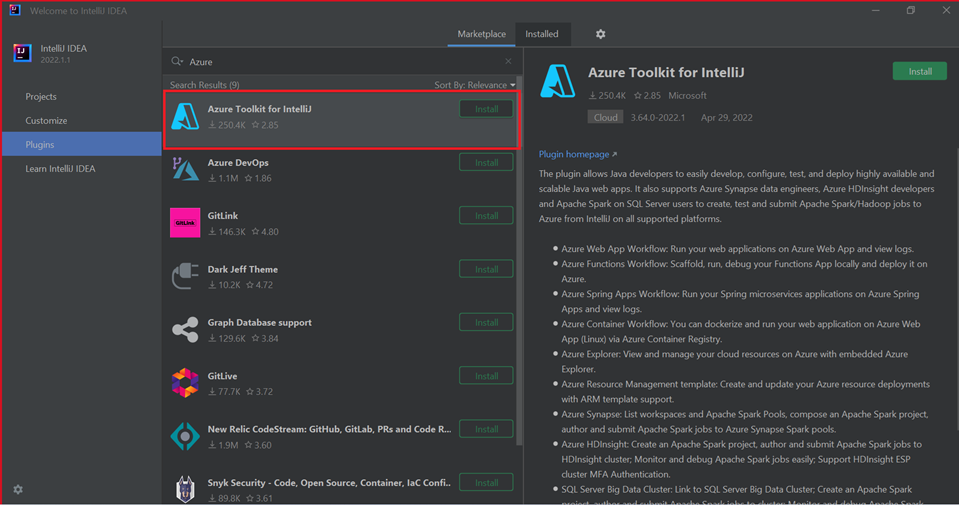
Azure Toolkit for IntelliJ に対して [インストール] を選択します。
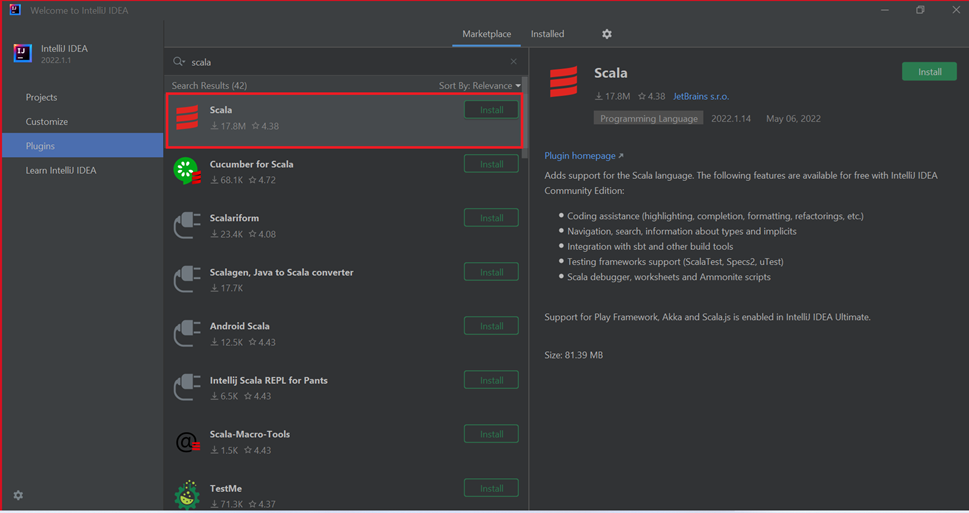
新しいウィンドウに表示される Scala プラグインの [インストール] を選択します。
プラグインが正常にインストールされたら、IDE を再起動する必要があります。
IntelliJ を使用してアプリケーションを作成する
IntelliJ IDEA を起動し、 [Create New Project](新しいプロジェクトの作成) を選択して、 [New Project](新しいプロジェクト) ウィンドウを開きます。
左側のウィンドウから [Apache Spark/HDInsight] を選択します。
メイン ウィンドウで [Spark Project (Scala)](Spark プロジェクト (Scala)) を選択します。
[Build tool](ビルド ツール) ドロップダウン ボックスの一覧で、次の値のいずれかを選択します。
- Scala プロジェクト作成ウィザードをサポートする場合は Maven。
- 依存関係を管理し、Scala プロジェクトをビルドする場合は SBT。
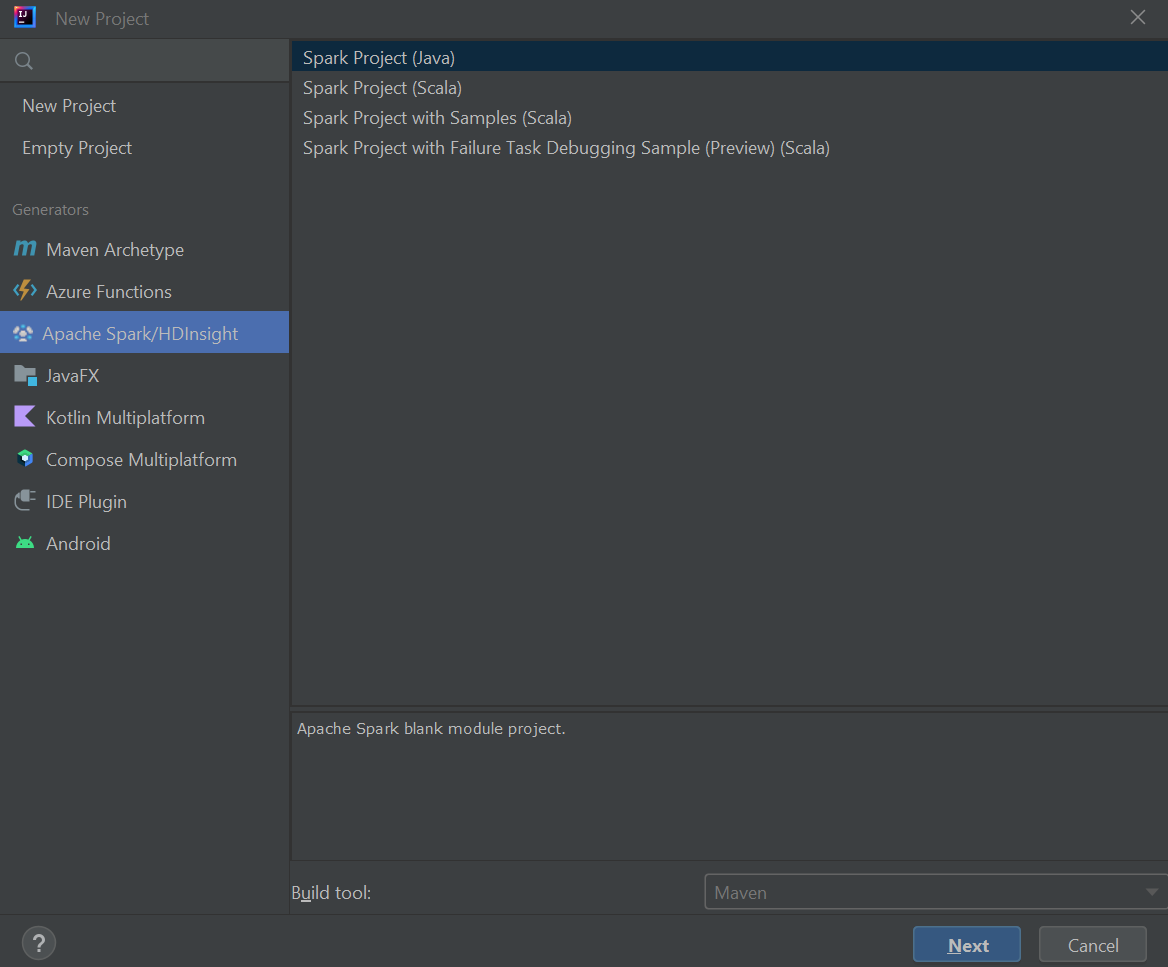
[次へ] を選択します。
[New Project](新しいプロジェクト) ウィンドウで、次の情報を指定します。
プロパティ 説明 プロジェクト名 名前を入力します。 プロジェクトの場所 プロジェクトを保存する場所を入力します。 Project SDK (プロジェクト SDK) IDEA を初めて使用するとき、このフィールドは空白です。 [New](新規作成) を選択し、自分の JDK に移動します。 Spark バージョン 作成ウィザードにより、Spark SDK と Scala SDK の適切なバージョンが統合されます。 Spark クラスターのバージョンが 2.0 より前の場合は、 [Spark 1.x] を選択します。 それ以外の場合は、 [Spark2.x] を選択します。 この例では、Spark 2.3.0 (Scala 2.11.8) を使用します。 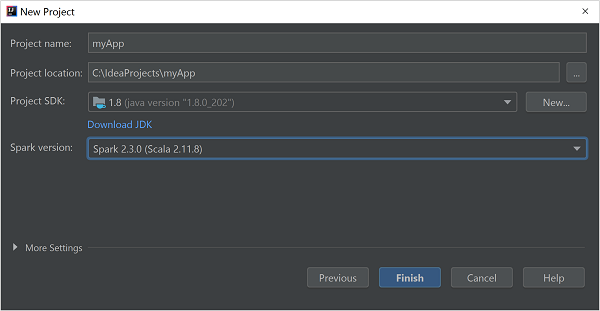
[完了] を選びます。
スタンドアロンの Scala プロジェクトを作成する
IntelliJ IDEA を起動し、 [Create New Project](新しいプロジェクトの作成) を選択して、 [New Project](新しいプロジェクト) ウィンドウを開きます。
左側のウィンドウで、 [Maven] を選択します。
[Project SDK (プロジェクトのSDK)] を指定します。 空白の場合は、 [New](新規作成) を選択し、Java のインストール ディレクトリに移動します。
[Create from archetype](アーキタイプからの作成) チェック ボックスをオンにします。
アーキタイプの一覧から、
org.scala-tools.archetypes:scala-archetype-simpleを選択します。 このアーキタイプによって、正しいディレクトリ構造が作成され、Scala プログラムを作成するのに必要な既定の依存関係がダウンロードされます。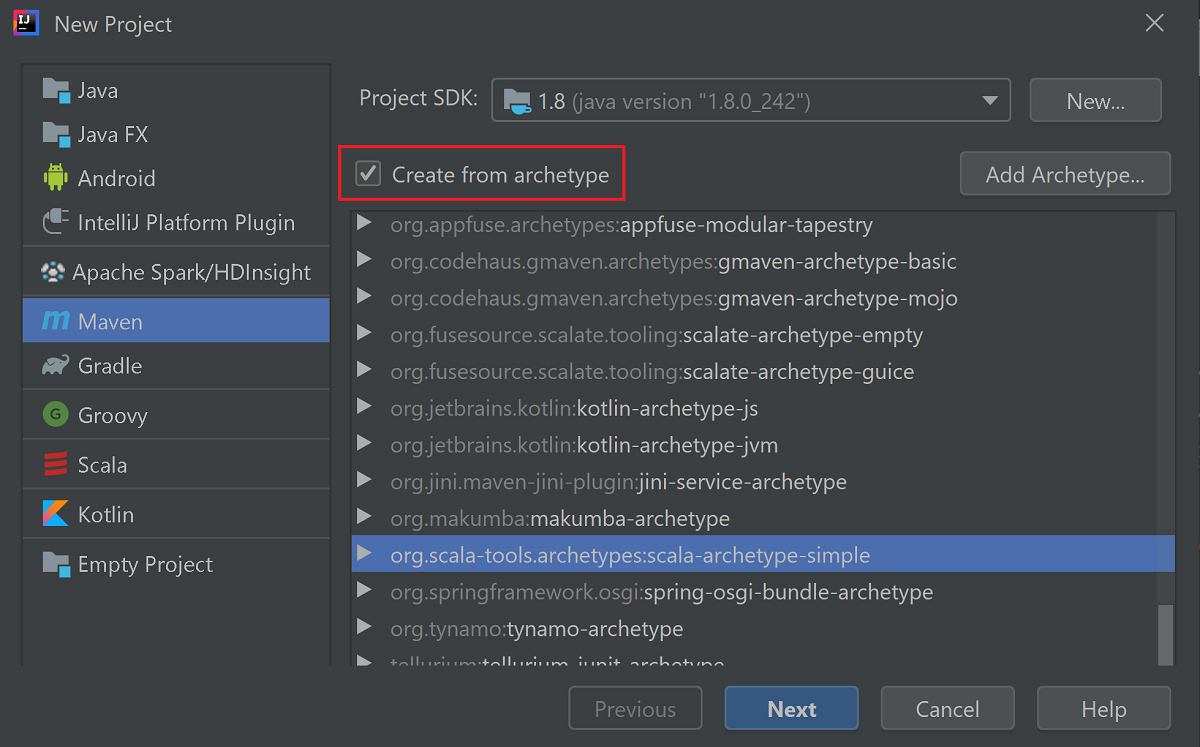
[次へ] を選択します。
[Artifact Coordinates](成果物の調整) を展開します。 [GroupId](グループ ID) および [ArtifactId](成果物 ID) に、適切な値を指定します。 [Name](名前) および [Location](場所) は自動的に設定されます。 このチュートリアルでは、次の値を使用しています。
- GroupId: com.microsoft.spark.example
- ArtifactId: SparkSimpleApp
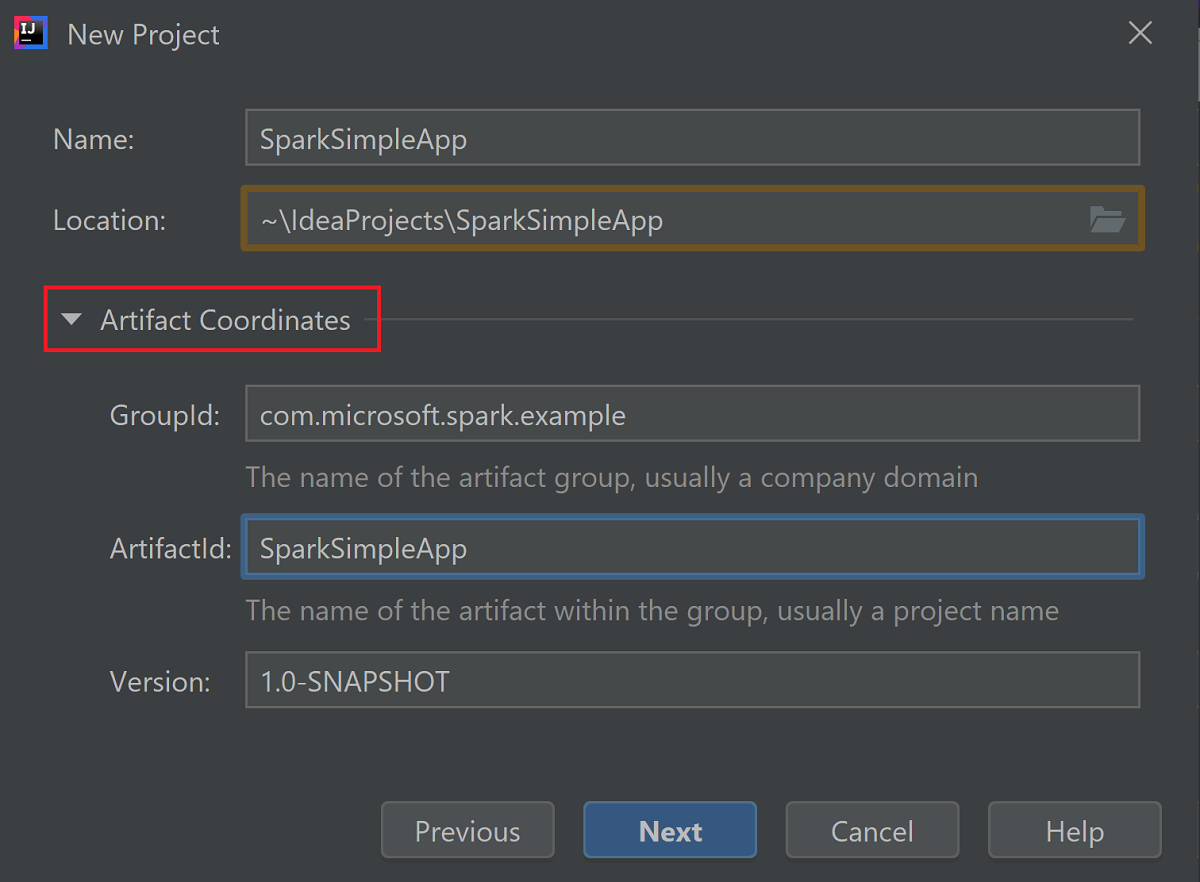
[次へ] を選択します。
設定を確認してから、 [Next] (次へ) を選択します。
プロジェクト名と場所を確認し、 [Finish] (完了) をクリックします。 プロジェクトのインポートには数分かかります。
プロジェクトがインポートされたら、左側のウィンドウで [SparkSimpleApp]>[src](ソース)>[test](テスト)>[scala]>[com]>[microsoft]>[spark]>[example](例) の順に移動します。 [MySpec] を右クリックし、 [Delete](削除) を選択します。このファイルはアプリケーションに必要ありません。 ダイアログ ボックスで [OK] を選択します。
以降の手順では、pom.xml を更新して、Spark Scala アプリケーションの依存関係を定義します。 これらの依存関係が自動的にダウンロードされ解決されるように、Maven を構成する必要があります。
[File](ファイル) メニューの [Settings](設定) を選択し、 [Settings](設定) ウィンドウを開きます。
[Settings](設定) ウィンドウで、 [Build, Execution, Deployment](ビルド、実行、デプロイ)>[Build Tools](構築ツール)>[Maven]>[Importing](インポート) の順に移動します。
[Import Maven projects automatically](Maven プロジェクトを自動的にインポートする) チェック ボックスをオンにします。
[Apply](適用) を選択し、次に [OK] を選択します。 元のプロジェクト ウィンドウが表示されます。
:::image type="content" source="./media/apache-spark-create-standalone-application/configure-maven-download.png" alt-text="Configure Maven for automatic downloads." border="true":::左側のウィンドウで、 [src](ソース)>[main]>[scala]>[com.microsoft.spark.example] の順に移動し、 [App] をダブルクリックして App.scala を開きます。
既存のサンプル コードを次のコードに置き換え、変更を保存します。 このコードは HVAC.csv (すべての HDInsight Spark クラスターで使用可能) からデータを読み取ります。 6 番目の列から 1 桁の数字のみが含まれる行を取得し、 クラスター用の既定のストレージ コンテナーの下にある /HVACOut に出力を書き込みます。
package com.microsoft.spark.example import org.apache.spark.SparkConf import org.apache.spark.SparkContext /** * Test IO to wasb */ object WasbIOTest { def main (arg: Array[String]): Unit = { val conf = new SparkConf().setAppName("WASBIOTest") val sc = new SparkContext(conf) val rdd = sc.textFile("wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") //find the rows which have only one digit in the 7th column in the CSV val rdd1 = rdd.filter(s => s.split(",")(6).length() == 1) rdd1.saveAsTextFile("wasb:///HVACout") } }左ウィンドウで pom.xml をダブルクリックします。
<project>\<properties>に、以下のセグメントを追加します。<scala.version>2.11.8</scala.version> <scala.compat.version>2.11.8</scala.compat.version> <scala.binary.version>2.11</scala.binary.version><project>\<dependencies>に、以下のセグメントを追加します。<dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_${scala.binary.version}</artifactId> <version>2.3.0</version> </dependency>Save changes to pom.xml.jar ファイルを作成します。 IntelliJ IDEA では、JAR をプロジェクトのアーティファクトとして作成できます。 手順は次のとおりです。
[File](ファイル) メニューの [Project Structure](プロジェクトの構造) を選択します。
[Project Structure](プロジェクトの構造) ウィンドウで、 [Artifacts](成果物)>プラス記号 (+)>[JAR]>[From modules with dependencies](依存関係を持つモジュールから) の順に移動します。
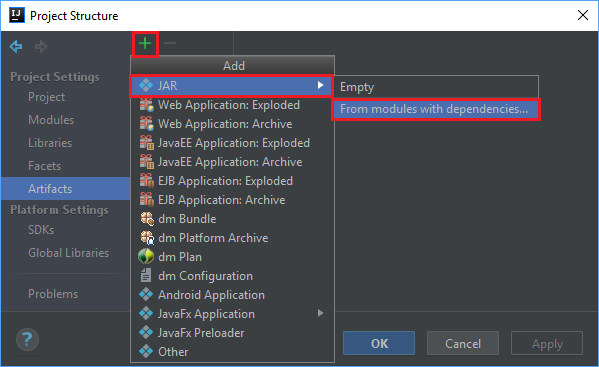
[Create JAR from Modules](モジュールから JAR を作成) ウィンドウで、 [Main Class](メイン クラス) ボックスのフォルダー アイコンを選択します。
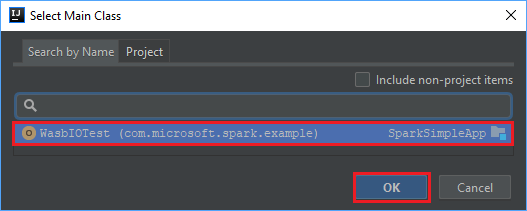
[Select Main Class](メイン クラスの選択) ウィンドウで、既定で表示されるクラスを選択し、 [OK] を選択します。
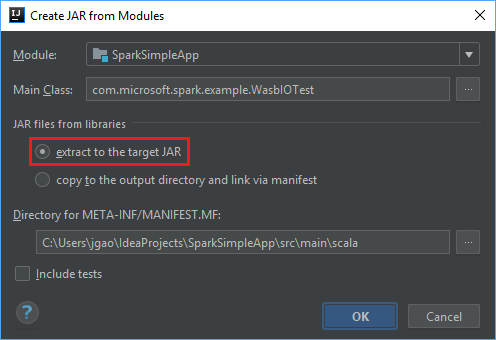
[Create JAR from Modules](モジュールから JAR を作成) ウィンドウで、 [extract to the target JAR](ターゲット JAR に抽出する) オプションが選択されていることを確認し、 [OK] を選択します。 これにより、すべての依存関係を持つ 1 つの JAR が作成されます。
[Output Layout (出力レイアウト)] タブに、Maven プロジェクトの一部として取り込まれたすべての jar が一覧表示されます。 Scala アプリケーションと直接的な依存関係がないものについては、選択し削除できます。 ここで作成するアプリケーションの場合は、最後の 1 つ (SparkSimpleApp compile output) を除き、あとはすべて削除することができます。 削除する jar を選択し、マイナス記号 ( - ) を選択します。
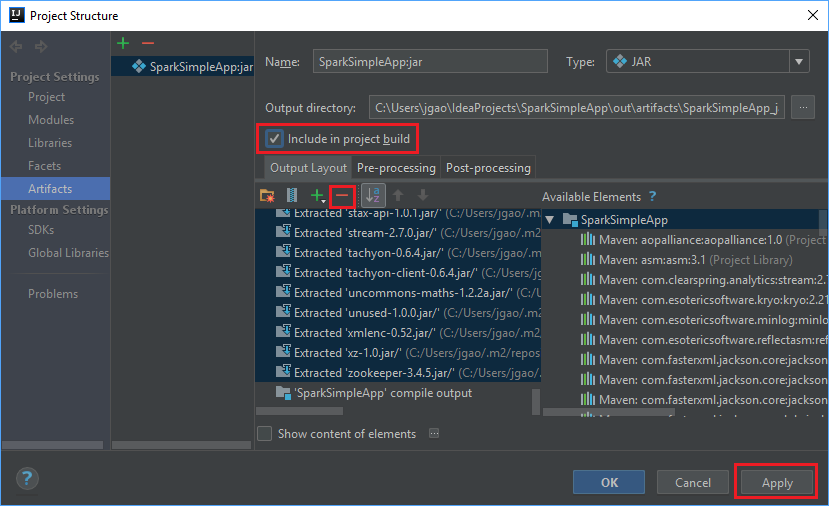
[Include in project build](プロジェクト ビルドに含める) ボックスがオンになっていることを確認します。 このオプションをオンにすることで、プロジェクトがビルドまたは更新されるたびに jar が確実に作成されます。 [Apply](適用) 、 [OK] の順に選択します。
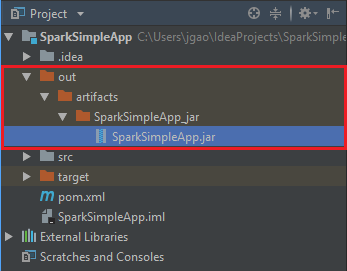
jar を作成するには、 [Build](ビルド)>[Build Artifacts](ビルド成果物)>[Build](ビルド) の順に移動します。 プロジェクトは 30 秒ほどでコンパイルされます。 出力 jar が \out\artifacts の下に作成されます。
Apache Spark クラスターでアプリケーションを実行する
クラスターでアプリケーションを実行するには、次のアプローチを使用できます。
クラスターに関連付けられている Azure Storage Blob にアプリケーション jar をコピーします。 コピーには、AzCopy コマンドライン ユーティリティを使用できます。 他にも、データのアップロードに使用できるクライアントが多数あります。 詳細については、HDInsight での Apache Hadoop ジョブ用データのアップロードに関するページを参照してください。
Spark クラスターに、Apache Livy を使用してリモートからアプリケーション ジョブを送信します。 HDInsight の Spark クラスターには、Spark ジョブをリモートで送信するための REST エンドポイントを公開する Livy が含まれています。 詳細については、HDInsight の Spark クラスターで Apache Livy を使用してリモートから Apache Spark ジョブを送信する方法に関するページを参照してください。
リソースをクリーンアップする
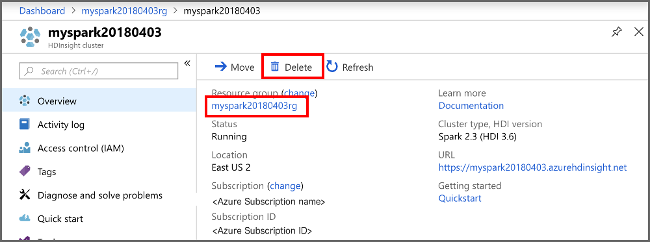
このアプリケーションを引き続き使用しない場合は、次の手順で作成したクラスターを削除します。
Azure portal にサインインします。
上部の検索ボックスに「HDInsight」と入力します。
[サービス] の下の [HDInsight クラスター] を選択します。
表示される HDInsight クラスターの一覧で、このチュートリアル用に作成したクラスターの横にある [...] を選択します。
[削除] を選択します。 はいを選択します。
次のステップ
この記事では、Apache Spark Scala アプリケーションの作成方法について説明しました。 Livy を使用して HDInsight Spark クラスター上でこのアプリケーションを実行する方法を確認するには、次の記事に進みます。