Azure Toolkit for Eclipse を使用して HDInsight クラスター向けの Apache Spark アプリケーションを作成する
Azure Toolkit for Eclipse の HDInsight Tools を使用して Scala で記述された Apache Spark アプリケーションを開発し、Eclipse IDE から直接、Azure HDInsight Spark クラスターに送信します。 HDInsight Tools プラグインには、次のような複数の使い方があります。
- Scala Spark アプリケーションを開発して HDInsight Spark クラスターに送信する。
- Azure HDInsight Spark クラスター リソースにアクセスする。
- Scala Spark アプリケーションをローカルで開発して実行する。
前提条件
HDInsight 上の Apache Spark クラスター。 手順については、「 Create Apache Spark clusters in Azure HDInsight (Azure HDInsight での Apache Spark クラスターの作成)」を参照してください。
Java Developer キット (JDK) バージョン 8
Eclipse IDE。 この記事では、Java 開発者向けの Eclipse IDE を使用します。
必要なプラグインをインストールする
Azure Toolkit for Eclipse をインストールする
インストール手順については、「Azure Toolkit for Eclipse のインストール」を参照してください。
Scala プラグインをインストールする
Eclipse の起動時に、Scala プラグインがインストールされているかどうかを HDInsight Tools が自動的に検出します。 [OK] を選択して続行し、指示に従って Eclipse Marketplace からプラグインをインストールします。 インストールが完了したら、IDE を再起動します。
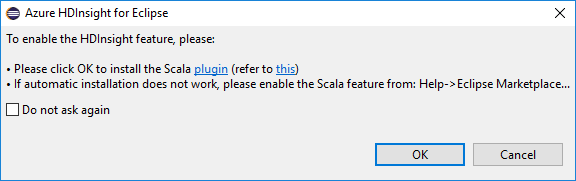
プラグインの確認
ヘルプ の>Eclipse Marketplace... に移動します。
[インストール] タブを選択します。
少なくとも次のように表示する必要があります:
- Azure Toolkit for Eclipse <バージョン>。
- Scala IDE <バージョン>。
Azure サブスクリプションにサインインします。
Eclipse IDE を起動します。
[ウィンドウ]>[表示ビュー]>[その他...]>[サインイン...] に移動します。
[表示ビュー] ダイアログで、 [Azure]>[Azure Explorer] に移動し、 [開く] を選択します。
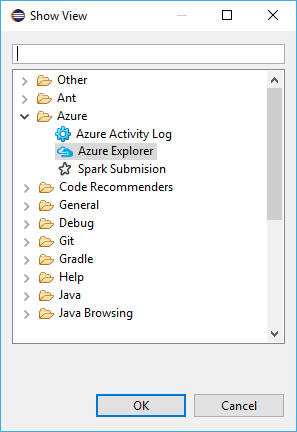
Azure Explorer で、 [Azure] ノードを右クリックし、 [サインイン] を選択します。
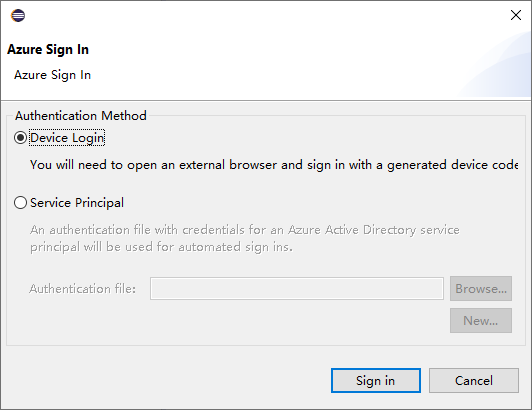
[Azure サインイン] ダイアログボックスで、[認証方法] を選択し、 [サインイン] を選択して、サインインプロセスを完了します。
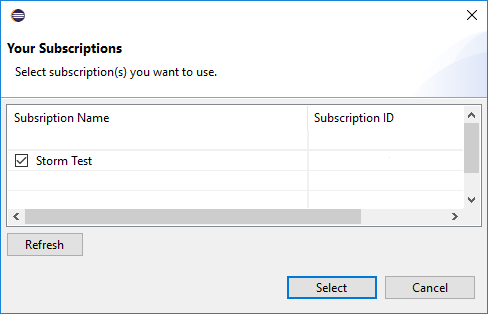
サインインすると、 [サブスクリプション] ダイアログボックスに、資格情報に関連付けられたすべての Azure サブスクリプションが一覧表示されます。 [選択] をクリックし、ダイアログボックスを閉じます。
Azure Explorer から、Azure>HDInsight に移動し、サブスクリプションの下にある HDInsight Spark クラスターを表示します。
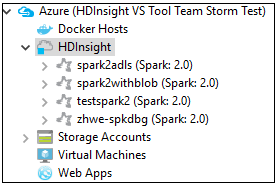
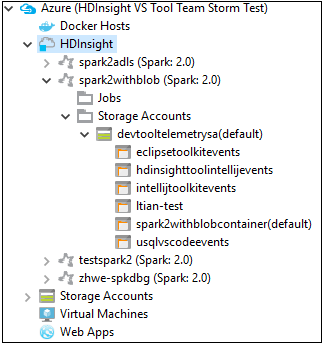
クラスター名のノードをさらに展開すると、そのクラスターに関連付けられているリソース (ストレージ アカウントなど) を表示できます。
クラスターのリンク
Ambari マネージド ユーザー名を使用して、通常のクラスターをリンクすることができます。 同様に、ドメイン参加済み HDInsight クラスターでは、user1@contoso.com などのドメインとユーザー名を使用して、リンクできます。
Azure Explorerで、 [HDInsight] を右クリックし、 [クラスターのリンク] を選択します。
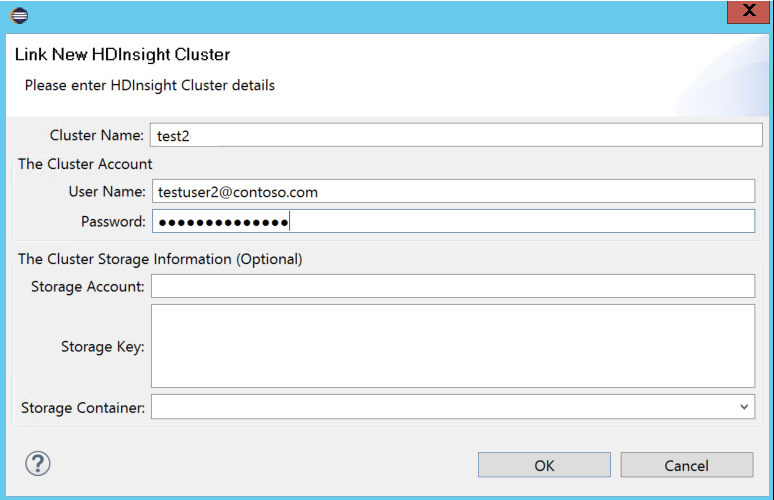
クラスター名、ユーザー名、および パスワードを入力し、 [OK] を選択します。 任意で、[ストレージ アカウント] と [ストレージ キー] を入力し、左のツリー ビューでストレージ エクスプローラーに [ストレージ コンテナー] を選択します。
Note
クラスターが Azure サブスクリプションにログインし、かつクラスターにリンクしていた場合、リンクされたストレージ キー、ユーザー名、パスワードを使用します。
キーボードのみを使用しているユーザーの場合、現在のフォーカスがストレージ キーにあるときは、Ctrl+TAB を使用して、ダイアログの次のフィールドにフォーカスを移動する必要があります。
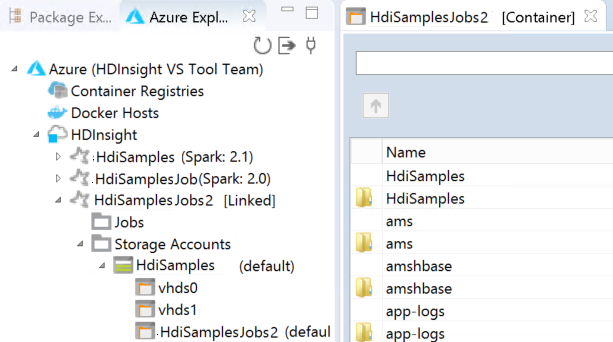
リンクされたクラスターは HDInsight の下に表示されます。 これでリンクされたクラスターにアプリケーションを送信できるようになりました。
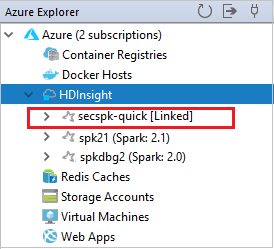
また、Azure 用エクスプローラーからクラスターのリンクを解除することもできます。

HDInsight Spark クラスター用の Spark Scala プロジェクトを設定する
Eclipse IDE ワークスペースで、 [ファイル]>[新しい>プロジェクト...] を選択します。
[新しいプロジェクト] ウィザードで、 [hdinsight プロジェクト]>Spark on HDInsight (Scala) を選択します。 [次へ] を選択します。
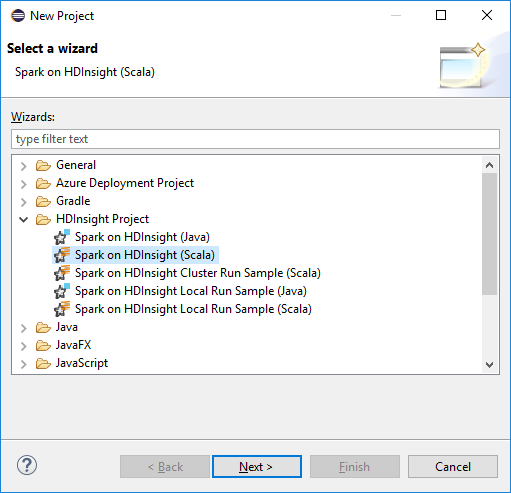
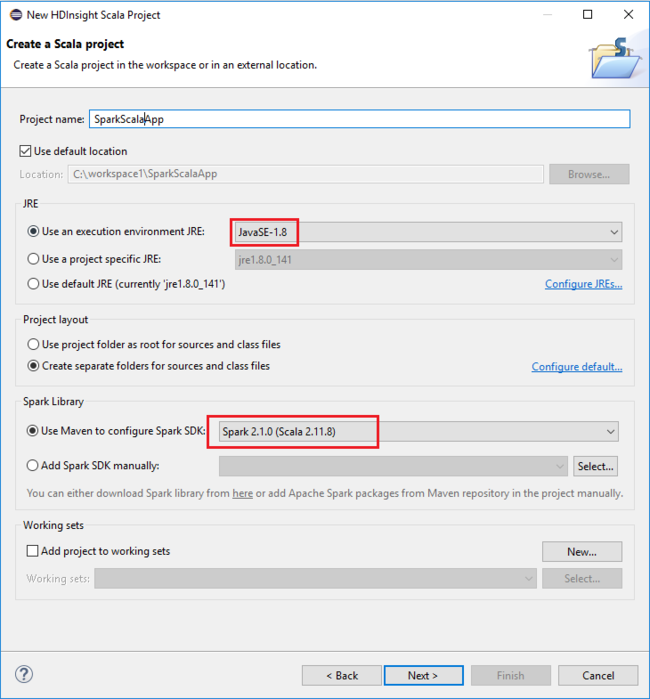
[New HDInsight Scala Project](新しい HDInsight Scala プロジェクト) ダイアログ ボックスで、次の値を指定し、 [Next](次へ) を選択します。
- プロジェクトの名前を入力します。
- [JRE] 領域で、 [Use an execution environment JRE](実行環境 JRE を使用する) が JavaSE-1.7 以降に設定されていることを確認します。
- [Spark Library](Spark ライブラリ) 領域では、 [Use Maven to configure Spark SDK](Maven を使用して Spark SDK を構成する) オプションを選択できます。 ツールにより Spark SDK と Scala SDK の適切なバージョンが統合されます。 また、手動で Spark SDK を手動で追加する オプションを選択して、ダウンロードし、Spark SDK を手動で追加することもできます。
次のダイアログボックスで、詳細を確認し、 [完了] を選択します。
HDInsight Spark クラスター向けの Scala アプリケーションを作成する
Package Explorer から、前に作成したプロジェクトを展開します。 src を右クリックし、 [新規]>[その他... ] を選択します。
[ウィザードの選択] ダイアログボックスで、 [Scala ウィザード]>[Scala オブジェクト] を選択します。 [次へ] を選択します。
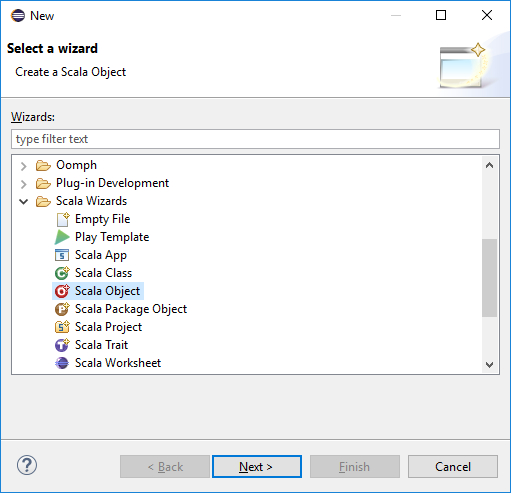
[Create New File] \(新しいファイルの作成) ダイアログ ボックスでオブジェクトの名前を入力し、 [Finish] \(完了) を選択します。 テキストエディターが開きます。
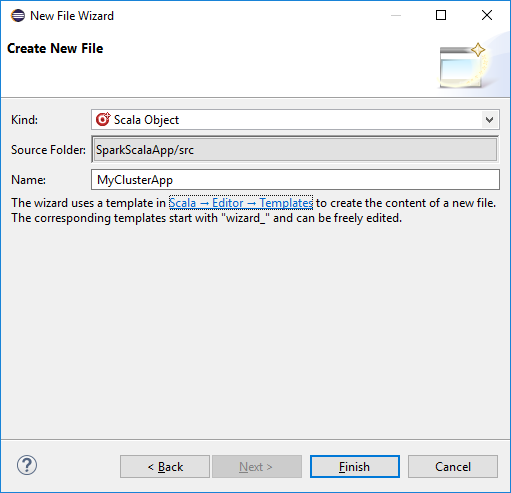
テキストエディターで、現在の内容を次のコードに置き換えます:
import org.apache.spark.SparkConf import org.apache.spark.SparkContext object MyClusterApp{ def main (arg: Array[String]): Unit = { val conf = new SparkConf().setAppName("MyClusterApp") val sc = new SparkContext(conf) val rdd = sc.textFile("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") //find the rows that have only one digit in the seventh column in the CSV val rdd1 = rdd.filter(s => s.split(",")(6).length() == 1) rdd1.saveAsTextFile("wasbs:///HVACOut") } }HDInsight Spark クラスターでアプリケーションを実行します。
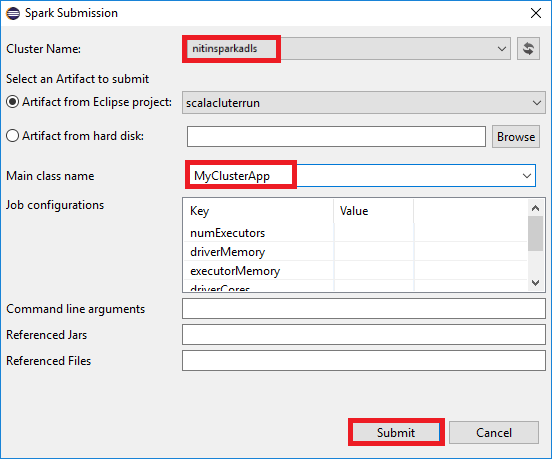
a. Package Explorer で、プロジェクト名を右クリックし、 [Submit Spark Application to HDInsight](HDInsight への Spark アプリケーションの送信) を選択します。
b. [Spark Submission](Spark 送信) ダイアログ ボックスで、次の値を入力し、 [Submit](送信) を選択します。
[Cluster Name (クラスター名)] で、アプリケーションを実行する HDInsight Spark クラスターを選択します。
Eclipse プロジェクトまたはハード ドライブからアーティファクトを選択します。 既定値は、Package Explorer から右クリックした項目によって異なります。
送信ウィザードの [Main class name](メイン クラス名) ボックスの一覧に、プロジェクトのすべてのオブジェクト名が表示されます。 実行するオブジェクトを選択または入力します。 ハード ドライブからアーティファクトを選択した場合は、メイン クラス名を手動で入力する必要があります。
この例のアプリケーションコードでは、コマンドライン引数を必要とせず、Jar またはファイルを参照することもないため、残りのテキストボックスは空のままにすることができます。
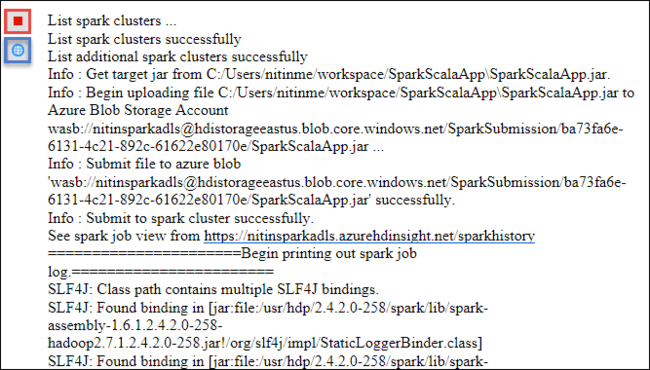
[Spark Submission (Spark 送信)] タブで、進行状況の表示が開始されます。 [Spark Submission](Spark 送信) ウィンドウにある赤いボタンを選択して、アプリケーションを停止することができます。 地球アイコン (図では青のボックスで示されています) を選択して、この特定のアプリケーションの実行に関するログを表示することもできます。
Azure Toolkit for Eclipse の HDInsight Tools を使用して HDInsight Spark クラスターにアクセスして管理する
HDInsight Tools を使用すると、ジョブの出力へのアクセスなど、さまざまな操作を実行できます。
ジョブ ビューにアクセスする
Azure Explorerで、 [HDInsight] 、[Spark クラスター名] の順に展開し、 [ジョブ] を選択します。
[ジョブ] ノードを選択します。 Java のバージョンが 1.8 より前である場合、HDInsight ツールは E(fx)clipse プラグインのインストールを求めるアラームを自動的に表示します。 [OK] を選択して続行し、ウィザードに従って Eclipse Marketplace からプラグインをインストールし、Eclipse を再起動します。
[ジョブ] ノードからジョブ ビューを開きます。 右側のウィンドウの [Spark Job View (Spark ジョブ ビュー)] タブに、クラスター上で実行されていたすべてのアプリケーションが表示されます。 詳細情報を確認したいアプリケーションの名前を選択します。
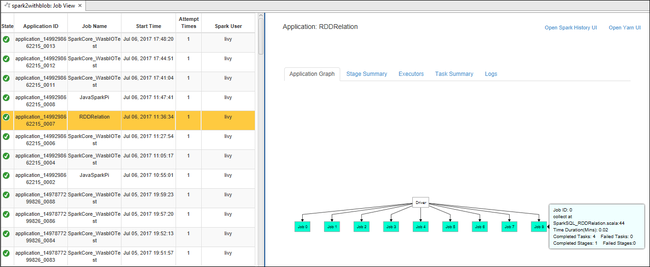
これで、以下のアクションを実行できます。
ジョブ グラフをポイントします。 すると、実行中のジョブに関する基本情報が表示されます。 ジョブ グラフを選択すると、各ジョブについて生成されるステージおよび情報を確認できます。
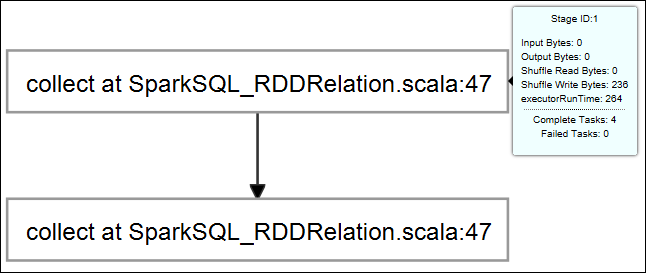
[Log](ログ) タブを選択して、Driver Stderr、Driver Stdout、Directory Info などの頻繁に使用されるログを表示します。
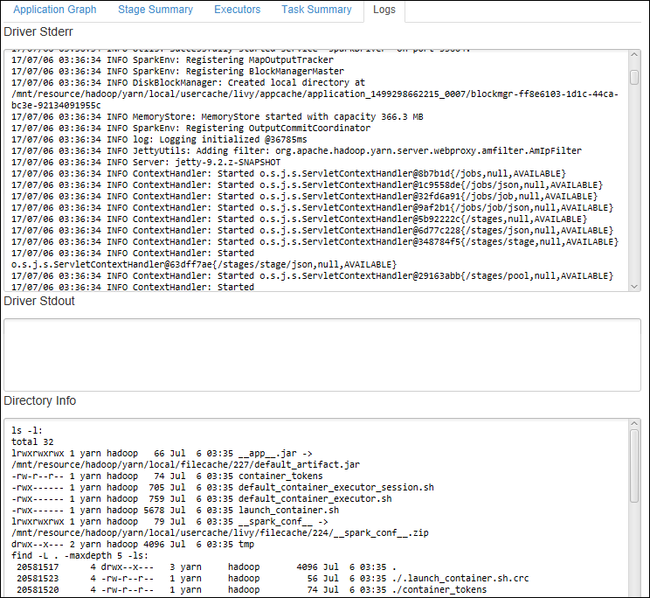
ウィンドウの上部にあるハイパーリンクを選択して、Spark 履歴 UI と Apache Hadoop YARN UI を (アプリケーション レベルで) 開きます。
クラスターのストレージ コンテナーにアクセスする
Azure Explorer で、 [HDInsight] ルート ノードを展開して、使用できる HDInsight Spark クラスターの一覧を表示します。
クラスター名を展開して、ストレージ アカウントと、クラスターの既定のストレージ コンテナーを表示します。
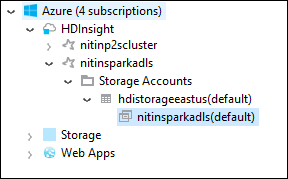
クラスターに関連付けられているストレージ コンテナー名を選択します。 右側のウィンドウで、HVACOut フォルダーをダブルクリックします。 part- ファイルのいずれかを開いて、アプリケーションの出力を確認します。
Spark 履歴サーバーにアクセスする
Azure Explorer で、Spark クラスター名を右クリックし、 [Open Spark History UI](Spark 履歴 UI を開く) を選択します。 入力を求められたら、クラスターの管理者資格情報を入力します。 これらは、クラスターのプロビジョニング時に指定したものです。
Spark 履歴サーバーのダッシュボードで、実行が終了したばかりのアプリケーションをアプリケーション名を使って探します。 上記のコードでは、
val conf = new SparkConf().setAppName("MyClusterApp")を使用してアプリケーション名を設定しました。 したがって、Spark アプリケーション名は MyClusterApp です。
Apache Ambari ポータルを起動する
Azure Explorer で、Spark クラスター名を右クリックし、 [Open Cluster Management Portal (Ambari)](クラスター管理ポータルを開く (Ambari)) を選択します。
入力を求められたら、クラスターの管理者資格情報を入力します。 これらは、クラスターのプロビジョニング時に指定したものです。
Azure サブスクリプションの管理
Azure Toolkit for Eclipse の HDInsight ツールの既定では、すべての Azure サブスクリプションからの Spark クラスターが一覧表示されます。 必要に応じて、クラスターにアクセスするサブスクリプションを指定できます。
Azure Explorer で、 [Azure] ルート ノードを右クリックし、 [Manage Subscriptions](サブスクリプションの管理) を選択します。
ダイアログ ボックスで、アクセスしないサブスクリプションのチェック ボックスをオフにし、 [Close](閉じる) を選択します。 Azure サブスクリプションからサインアウトする場合は、 [Sign Out](サインアウト) を選択することもできます。
Spark Scala アプリケーションのローカルでの実行
Azure Toolkit for Eclipse の HDInsight Tools を使用すると、ワークステーション上で Spark Scala アプリケーションをローカルに実行することができます。 通常、そのようなアプリケーションは、ストレージ コンテナーなどのクラスター リソースにアクセスする必要がなく、ローカルで実行しテストすることができます。
前提条件
Windows コンピューターでローカルの Spark Scala アプリケーションを実行中に、SPARK-2356 で説明されている例外が発生する場合があります。 この例外は、Windows 上に WinUtils.exe がないことが原因で発生します。
このエラーを解決するには、C:\WinUtils\bin などの場所に Winutils.exe が必要です。次に、環境変数 HADOOP_HOME を追加し、この変数の値を C:\WinUtils に設定します。
ローカル Spark Scala アプリケーションの実行
Eclipse を起動し、プロジェクトを作成します。 [新しいプロジェクト] ダイアログ ボックスで、次の選択を行い、 [Next](次へ) を選択します。
[新しいプロジェクト] ウィザードで、 [HDInsight プロジェクト]>[Spark on HDInsight Local Run Sample (Scala)] を選択します。 [次へ] を選択します。
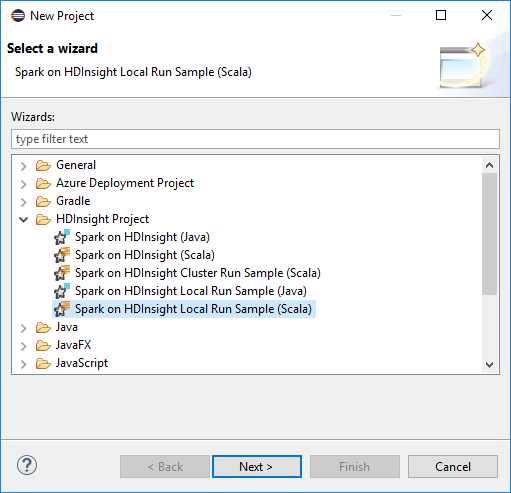
プロジェクトの詳細を指定するために、前のセクション「HDInsight Spark クラスター用の Spark Scala プロジェクトを設定する」の手順 3. から 6. に従います。
テンプレートは、コンピューターでローカルに実行することができるサンプル コード (LogQuery) を src フォルダーの下に追加します。
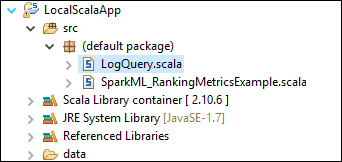
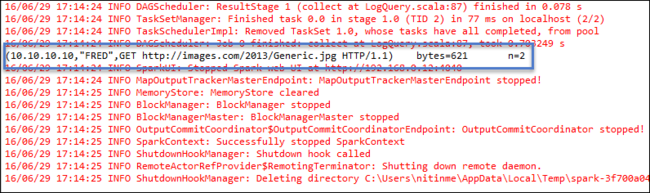
LogQuery.scala を右クリックし、 [実行]>1 つのアプリケーション を選択します。 次のような出力が [コンソール] タブに表示されます。
読み取り専用ロール
ユーザーが読み取り専用ロールのアクセス許可を使用してジョブをクラスターに送信する場合、Ambari の資格情報が必要です。
コンテキスト メニューからクラスターをリンクする
読み取り専用ロールのアカウントでサインインします。
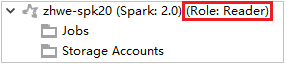
Azure Explorer で [HDInsight] を展開し、自分のサブスクリプションにある HDInsight クラスターを表示します。 "Role:Reader" とマークされているクラスターには、読み取り専用ロールのアクセス許可しかありません。
読み取り専用ロールのアクセス許可があるクラスターを右クリックします。 コンテキスト メニューで [Link this cluster](このクラスターをリンク) を選択して、クラスターをリンクします。 Ambari のユーザー名とパスワードを入力します。
クラスターが正常にリンクされると、HDInsight が更新されます。 クラスターのステージはリンク状態になります。
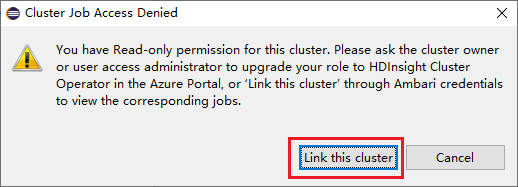
ジョブ ノードを展開してクラスターをリンクする
Jobs ノードをクリックします。 [Cluster Job Access Denied](拒否されたクラスター ジョブ アクセス) ウィンドウが表示されます。
[Link this cluster](このクラスターをリンク) をクリックして、クラスターをリンクします。
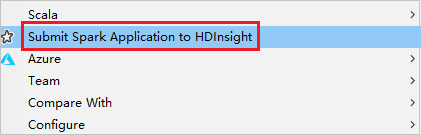
[Spark Submission](Spark 送信) ウィンドウからクラスターをリンクする
HDInsight プロジェクトを作成します。
パッケージを右クリックします。 次に、 [Submit Spark Application to HDInsight](HDInsight への Spark アプリケーションの送信) を選択します。
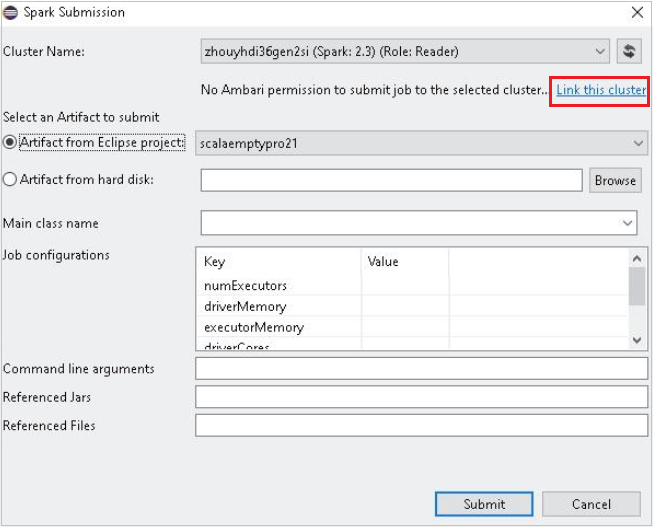
クラスター名に対する閲覧者専用のロールアクセス許可を持つクラスターを選択します。 警告メッセージが表示されます。 [Link this cluster](このクラスターをリンク) をクリックして、クラスターをリンクできます。
ストレージ アカウントを表示する
読み取り専用ロールのアクセス許可があるクラスターで、Storage Accounts ノードをクリックします。 [Storage Access Denied](拒否されたストレージ アクセス) ウィンドウが表示されます。
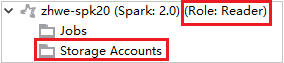
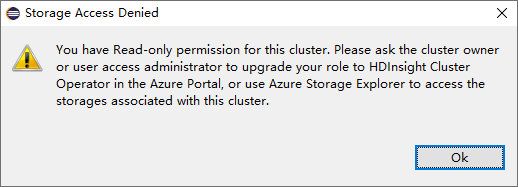
リンクされたクラスターで、Storage Accounts ノードをクリックします。 [Storage Access Denied](拒否されたストレージ アクセス) ウィンドウが表示されます。
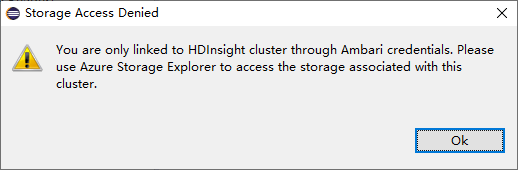
既知の問題
クラスターをリンクする を使用する場合は、ストレージの資格情報を入力することをお勧めします。
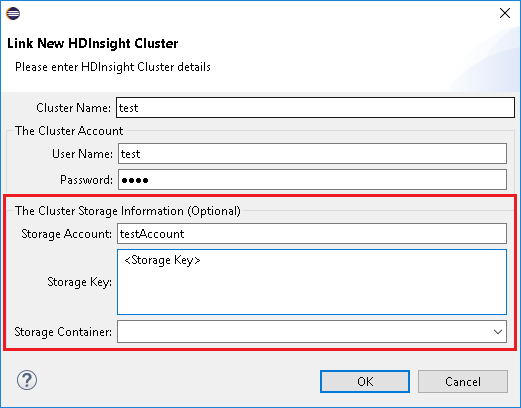
ジョブの送信には、2 つのモードがあります。 ストレージ資格情報が入力されると、バッチ モードが使用され、ジョブが送信されます。 入力されない場合、対話モードが使用されます。 クラスターがビジー状態の場合、以下のエラーが表示されることがあります。


関連項目
シナリオ
- Apache Spark と BI:HDInsight と BI ツールで Spark を使用した対話型データ分析の実行
- Apache Spark と Machine Learning: HDInsight で Spark を使用して、HVAC データを使用して建物の温度を分析する
- Apache Spark と Machine Learning:HDInsight で Spark を使用して食品の検査結果を予測する
- HDInsight 上での Apache Spark を使用した Web サイト ログ分析
アプリケーションの作成と実行
ツールと拡張機能
- Azure Toolkit for IntelliJ を使用して Spark Scala アプリケーションを作成して送信する
- Azure Toolkit for IntelliJ を使用して VPN 経由で Apache Spark アプリケーションをリモートでデバッグする
- Azure Toolkit for IntelliJ を使用して SSH 経由で Apache Spark アプリケーションをリモートでデバッグする
- HDInsight 上の Apache Spark クラスターで Apache Zeppelin Notebook を使用する
- HDInsight 用の Apache Spark クラスター内の Jupyter Notebook で使用可能なカーネル
- Jupyter Notebook で外部のパッケージを使用する
- Jupyter をコンピューターにインストールして HDInsight Spark クラスターに接続する