Migration : Pools SQL dédiés Azure Synapse Analytics vers Fabric
S'applique à :✅ Entrepôt dans Microsoft Fabric
Cet article détaille la stratégie, les considérations et les méthodes de migration de l’entrepôt de données dans des pools SQL dédiés Azure Synapse Analytics vers Microsoft Fabric Warehouse.
Présentation de la migration
Microsoft a présenté Microsoft Fabric, une solution d’analyse SaaS tout-en-un pour les entreprises, qui offre une suite complète de services : Fabrique de données, Ingénieurs de données, Entrepôt de données, Sciences des données, Informations en temps réel et Power BI.
Cet article se concentre sur les options de migration de schéma (DDL), de migration de code de base de données (DML) et de migration des données. Microsoft propose plusieurs options et, ici, nous abordons chacune d’elles dans le détail afin de vous donner des conseils sur celles que vous avez intérêt à considérer pour votre scénario. Cet article utilise le point de référence du secteur TPC-DS pour les tests d’illustration et de performances. Votre résultat réel peut varier en fonction de nombreux facteurs, notamment du ou des types de données, de la largeur des tables, de la latence de la source de données, etc.
Préparation de la migration
Planifiez soigneusement votre projet de migration avant de démarrer et vérifiez que votre schéma, votre code et vos données sont compatibles avec Fabric Warehouse. Il existe certaines limitations à prendre en compte. Quantifiez le travail de refactorisation des éléments incompatibles, ainsi que toutes les autres ressources nécessaires avant toute livraison de la migration.
Un autre objectif clé de la planification consiste à ajuster votre conception pour vérifier que votre solution tire pleinement parti des performances de requêtes élevées offertes par Fabric Warehouse. Le développement d’entrepôts de données prenant en charge la mise à l’échelle introduit des modèles uniques de conception, ce qui signifie que les approches traditionnelles ne sont pas toujours les mieux indiquées. Passez en revue les recommandations sur les performances de Fabric Warehouse, car même si certains ajustements de la conception peuvent s’effectuer après la migration, l’apport de modifications à un stade plus précoce du processus vous économisera du temps et des efforts. La migration d’une technologie/d’un environnement vers une/un autre constitue toujours un effort majeur.
Le diagramme suivant illustre le cycle de vie de la migration en listant ses principaux piliers, à savoir Évaluer, Planifier et concevoir, Migrer, Superviser et gouverner, Optimiser et moderniser, ainsi que les tâches associées à chaque pilier afin de planifier et préparer une migration fluide.

Runbook pour la migration
Considérez les activités suivantes comme un runbook de planification pour votre migration depuis des pools SQL dédiés Synapse vers Fabric Warehouse.
- Évaluer
- Identifier les objectifs et les motivations. Établir les résultats précis souhaités.
- Découvrir, évaluer l’architecture existante et en définir la base de référence.
- Identifier les parties prenantes et commanditaires clés.
- Définir l’étendue de ce qui doit être migré.
- Commencer avec une petite migration simple, préparer plusieurs petites migrations.
- Commencer à superviser et documenter toutes les étapes du processus.
- Créez un inventaire des données et processus pour la migration.
- Définissez les modifications de modèle de données (le cas échéant).
- Configurer l’espace de travail Fabric.
- Quel est votre ensemble de compétences/Quelles sont vos préférences ?
- Automatisez autant que possible.
- Utiliser des outils et fonctionnalités Azure intégrés pour réduire l’effort de migration.
- Formez le personnel à un stade précoce sur la nouvelle plateforme.
- Identifier les besoins de mise à jour des compétences et les ressources de formation, comme Microsoft Learn.
- Planifier et concevoir
- Définir l’architecture souhaitée.
- Sélectionnez la méthode/les outils de migration pour effectuer les tâches suivantes :
- Extraction de données à partir de la source.
- Conversion de schéma (DDL), y compris de métadonnées pour les tables et les vues.
- Ingestion de données, y compris de données historiques.
- Si nécessaire, remanier le modèle de données, en exploitant les performances et la scalabilité de la nouvelle plateforme.
- Migration de code de base de données (DML).
- Migrez ou refactorisez les procédures stockées et les processus métier.
- Dresser l’inventaire des fonctionnalités de sécurité et des autorisations d’objet, puis les extraire de la source.
- Concevoir et envisager de remplacer/modifier les processus ETL/ELT existants pour la charge incrémentielle.
- Créer des processus ETL/ELT parallèles dans le nouvel environnement.
- Préparer un plan de migration détaillé.
- Mapper l’état actuel au nouvel état souhaité.
- Migrer
- Effectuer la migration du schéma, des données et du code.
- Extraction de données à partir de la source.
- Conversion de schéma (DDL)
- Ingestion des données
- Migration de code de base de données (DML).
- Si nécessaire, mettez temporairement à l’échelle les ressources de pools SQL dédiés pour faciliter la migration.
- Appliquer la sécurité et les autorisations.
- Migrer les processus ETL/ELT existants pour la charge incrémentielle.
- Migrer ou refactoriser les processus de charge incrémentielle ETL/ELT
- Tester et comparer les processus de charge incrémentielle parallèle.
- Adapter le plan de migration détaillé si nécessaire.
- Effectuer la migration du schéma, des données et du code.
- Superviser et gouverner
- Exécuter en parallèle, comparer à votre environnement source.
- Tester des applications, des plateformes décisionnelles et des outils de requête.
- Évaluez et optimisez les performances des requêtes.
- Superviser et gérer les coûts, la sécurité et les performances.
- Évaluation de benchmark et de gouvernance.
- Exécuter en parallèle, comparer à votre environnement source.
- Optimiser et moderniser
- Une fois que l’entreprise est prête, passer des applications et des plateformes de création de rapports principales à Fabric.
- Effectuer un scale-up/down des ressources à mesure que la charge de travail passe d’Azure Synapse Analytics à Microsoft Fabric.
- Créer un modèle reproductible à partir de l’expérience acquise pour les migrations futures. Itérer.
- Identifier les opportunités d’optimisation des coûts, de sécurité, de scalabilité et d’excellence opérationnelle
- Identifier les opportunités de modernisation de votre patrimoine de données à l’aide des dernières fonctionnalités Fabric.
- Une fois que l’entreprise est prête, passer des applications et des plateformes de création de rapports principales à Fabric.
« Lift-and-shift » ou modernisation ?
En règle générale, il existe deux types de scénarios de migration, quel que soit l’objectif et l’étendue de la migration planifiée : le lift-and-shift en l’état ou une approche par phases qui incorpore les modifications d’architecture et de code.
Opération lift-and-shift
Dans une migration lift-and-shift, un modèle de données existant est migré avec des modifications mineures apportées au nouvel entrepôt Fabric. Cette approche réduit les risques et la durée de la migration en diminuant le nouveau travail nécessaire pour profiter pleinement des avantages de la migration.
La migration lift-and-shift est adaptée à ces scénarios :
- Vous avez un environnement existant qui compte un petit nombre de datamarts à migrer.
- Vous avez un environnement existant avec des données qui se trouvent déjà dans un schéma en étoile ou en flocon bien conçu.
- Vous avez des contraintes de délai et de coût pour passer à Fabric Warehouse.
En résumé, cette approche fonctionne bien pour les charges de travail optimisées avec votre environnement de pools SQL dédiés Synapse actuel et elle ne nécessite donc pas de modifications majeures dans Fabric.
Moderniser dans le cadre d’une approche par phases avec des modifications architecturales
Si un entrepôt de données hérité a évolué sur une longue période, vous devrez peut-être le reconcevoir pour maintenir les niveaux de performances requis.
Vous pouvez également avoir envie de reconcevoir l’architecture pour tirer parti des nouveaux moteurs et fonctionnalités disponibles dans l’espace de travail Fabric.
Différences de conception : pools SQL dédiés Synapse et Fabric Warehouse
Tenez compte des différences suivantes entre l’entrepôt de données Azure Synapse et Microsoft Fabric, en comparant les pools SQL dédiés à Fabric Warehouse.
Considérations relatives aux tables
Lorsque vous migrez des tables entre différents environnements, seules les données brutes et les métadonnées sont généralement migrées physiquement. Les autres éléments de base de données du système source, tels que les index, ne sont généralement pas migrés, car ils peuvent être inutiles ou implémentés différemment dans le nouvel environnement.
Les optimisations des performances dans l’environnement source, comme les index, indiquent où vous pouvez ajouter une optimisation des performances dans un nouvel environnement, mais maintenant Fabric gère tout cela automatiquement.
Considérations relatives à T-SQL
Il existe plusieurs différences de syntaxe du langage de manipulation de données (DML) à connaître. Reportez-vous à Surface d’exposition T-SQL dans Microsoft Fabric. Envisagez également d’effectuer une évaluation de code lors du choix des méthodes de migration pour le code de base de données (DML).
Selon les différences de parité au moment de la migration, vous devrez peut-être réécrire certaines parties de votre code DML T-SQL.
Différences de mappage des types de données
Il existe plusieurs différences de types de données dans Fabric Warehouse. Pour plus d’informations, consultez Types de données dans Microsoft Fabric.
Le tableau suivant indique le mappage des types de données pris en charge entre des pools SQL dédiés Synapse et Fabric Warehouse.
| Pools SQL dédiés Synapse | Fabric Warehouse |
|---|---|
| devise | decimal(19,4) |
| SMALLMONEY | decimal(10,4) |
| smalldatetime | datetime2 |
| datetime | datetime2 |
| NCHAR | char |
| NVARCHAR | varchar |
| tinyint | smallint |
| binary | varbinary |
| datetimeoffset* | datetime2 |
* Datetime2 ne stocke pas les informations de décalage de fuseau horaire supplémentaires enregistrées. Étant donné que le type de données datetimeoffset n’est actuellement pas pris en charge dans Fabric Warehouse, les données de décalage de fuseau horaire doivent être extraites dans une colonne distincte.
Méthodes de schéma, de code et de migration de données
Passez en revue les options et identifiez celle qui correspond à votre scénario, aux ensembles de compétences du personnel et aux caractéristiques de vos données. Les options choisies dépendent de votre expérience, de vos préférences et des avantages inhérents à chacun des outils. Notre objectif est de continuer à développer des outils de migration qui atténuent les frictions et l’intervention manuelle nécessaire afin de fluidifier cette expérience de migration.
Ce tableau récapitule les informations liées au schéma de données (DDL), au code de base de données (DML) et aux méthodes de migration de données. Nous développons plus en détail chaque scénario inclus dans cet article. Le lien correspondant figure dans la colonne Option.
| Numéro d’option | Option | Action | Compétence/Préférence | Scénario |
|---|---|---|---|---|
| 1 | Data Factory | Conversion de schéma (DDL) Extraction de données Ingestion de données |
ADF/Pipeline | Migration tout-en-un simplifiée d’un seul schéma (DDL) et de données. Recommandé pour les tables de dimension. |
| 2 | Data Factory avec partition | Conversion de schéma (DDL) Extraction de données Ingestion de données |
ADF/Pipeline | Utilisation d’options de partitionnement pour augmenter le parallélisme de lecture/écriture qui fournit un débit 10 fois plus élevé que celui de l’option 1. Recommandé pour les tables de faits. |
| 3 | Data Factory avec code accéléré | Conversion de schéma (DDL) | ADF/Pipeline | Convertissez et migrez d’abord le schéma (DDL), puis utilisez CETAS pour extraire et COPY/Data Factory pour ingérer des données afin d’obtenir des performances d’ingestion globales optimales. |
| 4 | Code accéléré de procédures stockées | Conversion de schéma (DDL) Extraction de données Évaluation du code |
T-SQL | Utilisateur SQL qui se sert de l’IDE avec un contrôle plus précis sur les tâches sur lesquelles il souhaite travailler. Utilisez COPY/Data Factory pour ingérer des données. |
| 5 | Extension SQL Database Project pour Azure Data Studio | Conversion de schéma (DDL) Extraction de données Évaluation du code |
Projet SQL | Projet SQL Database pour le déploiement avec intégration de l’option 4. Utilisez COPY ou Data Factory pour ingérer des données. |
| 6 | CREATE EXTERNAL TABLE AS SELECT (CETAS) | Extraction de données | T-SQL | Extraction de données rentable et hautement performante dans Azure Data Lake Storage (ADLS) Gen2. Utilisez COPY/Data Factory pour ingérer des données. |
| 7 | Migrer à l’aide de dbt | Conversion de schéma (DDL) Conversion de code de base de données (DML) |
dbt | Les utilisateurs dbt existants peuvent utiliser l’adaptateur Fabric dbt pour convertir leurs DDL et DML. Vous devez ensuite migrer des données à l’aide d’autres options figurant dans ce tableau. |
Choisir une charge de travail pour la migration initiale
Lorsque vous déterminez où démarrer le projet de migration du pool SQL dédié Synapse vers Fabric Warehouse, choisissez une zone de charge de travail dans laquelle vous pouvez :
- Prouver la viabilité de la migration vers Fabric Warehouse en tirant rapidement parti des avantages du nouvel environnement. Commencer avec une petite migration simple, préparer plusieurs petites migrations.
- Laisser à votre personnel technique interne le temps d’acquérir une expérience suffisante avec les processus et outils qu’il utilisera pour migrer vers d’autres zones.
- Créer un modèle pour d’autres migrations propres à l’environnement Synapse source et aux outils et processus en place.
Conseil
Créer un inventaire des objets qui ont besoin d’être migrés et documenter le processus de migration du début à la fin pour qu’il puisse être répété pour d’autres charges de travail ou pools SQL dédiés.
Le volume des données migrées dans une migration initiale doit être suffisamment important pour illustrer les fonctionnalités et les avantages de l’environnement Fabric Warehouse, mais pas trop non plus pour illustrer rapidement la valeur. La valeur typique se situe dans la plage de 1 à 10 téraoctets.
Migration avec Fabric Data Factory
Dans cette section, nous décrivons les options en utilisant Data Factory destiné aux personnes qui travaillent avec peu de code/sans code et qui connaissent Azure Data Factory et Synapse Pipeline. Cette option d’interface utilisateur par glisser-déposer fournit une étape simple pour convertir le DDL et migrer les données.
Fabric Data Factory peut effectuer les tâches suivantes :
- Convertir le schéma (DDL) en syntaxe Fabric Warehouse.
- Créer le schéma (DDL) sur Fabric Warehouse.
- Migrez les données vers Fabric Warehouse.
Option 1. Migration de schéma/données – Assistant Copie et Activité Copy ForEach
Cette méthode utilise l’Assistant Copie Data Factory pour se connecter au pool SQL dédié source, convertir la syntaxe DDL du pool SQL dédié en Fabric et copier des données dans Fabric Warehouse. Vous pouvez sélectionner 1 ou plusieurs tables cibles (pour le jeu de données TPC-DS, il existe 22 tables). Cela génère l’activité ForEach qui permet de parcourir en boucle la liste des tables sélectionnées dans l’interface utilisateur et de générer 22 threads d’activité Copy parallèles.
- 22 requêtes SELECT (une pour chaque table sélectionnée) ont été générées et exécutées dans le pool SQL dédié.
- Vérifiez que vous disposez de la classe de ressource et de la DWU appropriées pour permettre l’exécution des requêtes générées. Dans ce cas, vous avez besoin d’un minimum de DWU1000 avec
staticrc10pour permettre à un maximum de 32 requêtes de gérer 22 requêtes envoyées. - La copie directe de données Data Factory à partir du pool SQL dédié vers Fabric Warehouse nécessite une mise en lots. Le processus d’ingestion se compose de deux phases.
- La première phase consiste à extraire les données du pool SQL dédié dans ADLS. Elle est appelée mise en lots.
- La seconde phase consiste à ingérer les données depuis la mise en lots dans Fabric Warehouse. La plupart du temps dédié à l’ingestion des données a trait à la phase de mise en lots. En résumé, la mise en lots a un impact considérable sur les performances de l’ingestion.
Utilisation recommandée
L’utilisation de l’Assistant Copie pour générer un ForEach fournit une interface utilisateur simple pour convertir le DDL et ingérer les tables sélectionnées du pool SQL dédié vers Fabric Warehouse en une seule étape.
Toutefois, cette méthode n’est pas optimale avec le débit global. L’obligation d’utiliser une mise en lots, le besoin de paralléliser la lecture et l’écriture pour l’étape « Source vers mise en lots » constituent les principaux facteurs de la latence des performances. Il est recommandé d’utiliser cette option uniquement pour les tables de dimension.
Option 2. Migration de données/DDL – Pipeline de données avec option de partition
Pour améliorer le débit de chargement de tables de faits plus volumineuses à l’aide du pipeline de données Fabric, il est recommandé d’utiliser l’activité Copy pour chaque table de faits avec l’option de partition. Celle-ci donne les meilleures performances avec l’activité Copy.
Vous avez la possibilité d’utiliser le partitionnement physique de la table source, le cas échéant. Si la table n’a pas de partitionnement physique, vous devez spécifier la colonne de partition et fournir des valeurs min/max pour utiliser un partitionnement dynamique. Dans la capture d’écran suivante, les options Source du pipeline de données spécifient une plage dynamique de partitions basée sur la colonne ws_sold_date_sk.
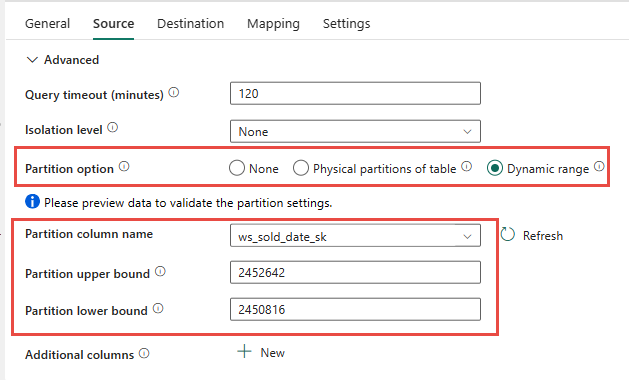
Bien que l’utilisation de la partition puisse augmenter le débit lors de la phase de mise en lots, il existe des éléments à considérer pour apporter les ajustements appropriés :
- Selon votre plage de partitions, tous les emplacements d’accès concurrentiel risquent d’être utilisés, car plus de 128 requêtes peuvent être générées sur le pool SQL dédié.
- Vous devez effectuer une mise à l’échelle vers DWU6000 au minimum pour permettre à toutes les requêtes d’être exécutées.
- Par exemple, pour la table
web_salesTPC-DS, 163 requêtes ont été soumises au pool SQL dédié. Pour DWU6000, 128 requêtes ont été exécutées alors que 35 requêtes ont été mises en file d’attente. - La partition dynamique sélectionne automatiquement la partition par spécification de plages de valeurs. Dans ce cas, il s’agit d’une plage de 11 jours pour chaque requête SELECT envoyée au pool SQL dédié. Par exemple :
WHERE [ws_sold_date_sk] > '2451069' AND [ws_sold_date_sk] <= '2451080') ... WHERE [ws_sold_date_sk] > '2451333' AND [ws_sold_date_sk] <= '2451344')
Utilisation recommandée
Pour des tables de faits, nous vous recommandons d’utiliser Data Factory avec l’option de partitionnement afin d’augmenter le débit.
Toutefois, les lectures parallélisées accrues nécessitent un pool SQL dédié pour effectuer une mise à l’échelle vers une DWU plus élevée afin de permettre l’exécution des requêtes d’extraction. En tirant parti du partitionnement, l’amélioration du débit est dix fois meilleure que sans aucune option de partition. Vous pouvez augmenter la DWU pour obtenir un débit supplémentaire par le biais de ressources de calcul, mais le pool SQL dédié autorise un maximum de 128 requêtes actives.
Remarque
Pour plus d’informations sur le mappage DWU Synapse vers Fabric, consultez Blog : Mappage de pools SQL dédiés Azure Synapse au calcul de l’entrepôt de données Fabric.
Option 3. Migration DDL – Activité Copy ForEach de l’Assistant Copie
Les deux options de migration des données précédentes sont intéressantes pour les bases de données plus petites. Si vous avez besoin d’un débit plus élevé, nous vous recommandons d’utiliser une autre option :
- Extrayez les données depuis le pool SQL dédié vers ADLS, ce qui atténue la surcharge des performances de mise en lots.
- Utilisez Data Factory ou la commande COPY pour ingérer les données dans Fabric Warehouse.
Utilisation recommandée
Vous pouvez continuer à utiliser Data Factory pour convertir votre schéma (DDL). À l’aide de l’Assistant Copie, vous pouvez sélectionner la table spécifique ou Toutes les tables. Par nature, le schéma et les données sont migrées en une seule étape, en extrayant le schéma sans aucune ligne, à l’aide d’une condition false, TOP 0 dans l’instruction de requête.
L’exemple de code suivant couvre la migration de schéma (DDL) avec Data Factory.
Exemple de code : Migration de schéma (DDL) avec Data Factory
Vous pouvez utiliser des pipelines de données Fabric pour migrer facilement votre DDL (schémas) pour des objets de table à partir de toute base de données Azure SQL source ou pool SQL dédié. Ce pipeline de données migre le schéma (DDL) pour les tables de pools SQL dédiés sources vers Fabric Warehouse.
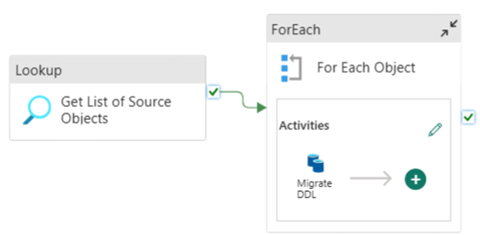
Conception de pipeline : paramètres
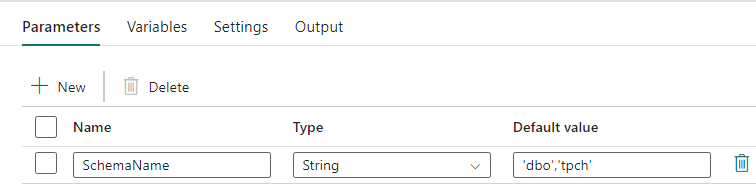
Ce pipeline de données accepte un paramètre SchemaName, ce qui vous permet de spécifier les schémas à migrer. Le schéma dbo est celui par défaut.
Dans le champ valeur par défaut, entrez la liste séparée par des virgules des schémas de table indiquant les schémas à migrer : 'dbo','tpch' pour fournir deux schémas, dbo et tpch.
Conception de pipeline : activité LookUp
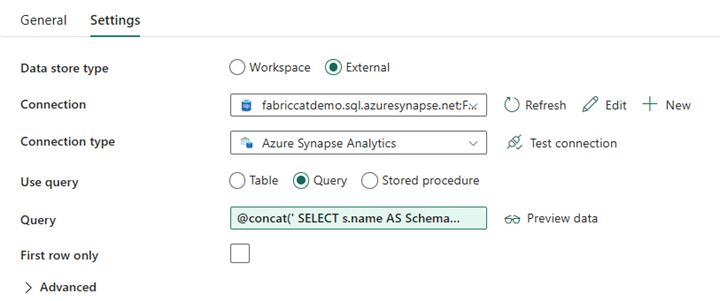
Créez une activité LookUp et définissez la connexion pour qu’elle pointe vers votre base de données source.
Sous l’onglet Paramètres :
Définissez Type de magasin de données sur Externe.
La connexion correspond à votre pool SQL dédié Azure Synapse. Le type de connexion correspond à Azure Synapse Analytics.
Le paramètre Utiliser la requête est défini sur Requête.
Le champ Requête doit être généré à l’aide d’une expression dynamique, ce qui permet au paramètre SchemaName d’être utilisé dans une requête qui retourne la liste des tables sources cibles. Sélectionnez Requête, puis Ajouter du contenu dynamique.
Cette expression au sein de l’activité LookUp génère une instruction SQL pour interroger les vues système afin de récupérer la liste des schémas et tables. Référence le paramètre SchemaName pour autoriser le filtrage sur les schémas SQL. La sortie correspondante est un tableau de schémas et tables SQL qui seront utilisés comme entrée dans l’activité ForEach.
Utilisez le code suivant pour retourner la liste de toutes les tables utilisateur avec leur nom de schéma.
@concat(' SELECT s.name AS SchemaName, t.name AS TableName FROM sys.tables AS t INNER JOIN sys.schemas AS s ON t.type = ''U'' AND s.schema_id = t.schema_id AND s.name in (',coalesce(pipeline().parameters.SchemaName, 'dbo'),') ')
Conception de pipeline : boucle ForEach
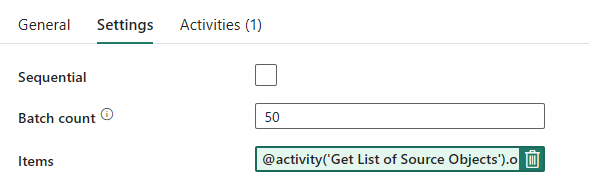
Pour la boucle ForEach, configurez les options suivantes sous l’onglet Paramètres :
- Désactivez Séquentiel pour permettre l’exécution simultanée de plusieurs itérations.
- Définissez le paramètre Nombre de lots sur
50, en limitant le nombre maximal d’itérations simultanées. - Le champ Éléments a besoin d’utiliser du contenu dynamique pour référencer la sortie de l’activité LookUp. Utilisez l’extrait de code suivant :
@activity('Get List of Source Objects').output.value
Conception de pipeline : activité Copy au sein de la boucle ForEach
Au sein de l’activité ForEach, ajoutez une activité Copy. Cette méthode utilise le langage d’expression dynamique dans les pipelines de données pour générer un SELECT TOP 0 * FROM <TABLE> afin de migrer uniquement le schéma sans données dans Fabric Warehouse.
Sous l’onglet Source :
- Définissez Type de magasin de données sur Externe.
- La connexion correspond à votre pool SQL dédié Azure Synapse. Le type de connexion correspond à Azure Synapse Analytics.
- Définissez le paramètre Utiliser la requête sur Requête.
- Dans le champ Requête, collez la requête de contenu dynamique et utilisez cette expression qui retourne zéro ligne, uniquement le schéma de table :
@concat('SELECT TOP 0 * FROM ',item().SchemaName,'.',item().TableName)

Sous l’onglet Destination :
- Définissez Type de magasin de données sur Espace de travail.
- Le type de magasin de données Espace de travail correspond à Data Warehouse et Data Warehouse est défini sur Fabric Warehouse.
- Le schéma et le nom de la table de destination sont définis à l’aide du contenu dynamique.
- Le schéma référence le champ de l’itération actuelle, SchemaName avec l’extrait de code :
@item().SchemaName - Table référence TableName avec l’extrait de code :
@item().TableName
- Le schéma référence le champ de l’itération actuelle, SchemaName avec l’extrait de code :

Conception de pipeline : Récepteur
Pour Récepteur, pointez vers votre entrepôt et référencez le nom du schéma source et de la table.
Une fois que vous avez exécuté ce pipeline, vous voyez votre entrepôt de données rempli avec chaque table de votre source, avec le schéma approprié.
Migration à l’aide de procédures stockées dans un pool SQL dédié Synapse
Cette option utilise des procédures stockées pour effectuer la migration Fabric.
Vous pouvez obtenir les exemples de code sur microsoft/fabric-migration sur GitHub.com. Ce code est partagé en open source. N’hésitez donc pas à apporter votre contribution pour soutenir la communauté.
Ce que peuvent faire les procédures stockées de migration :
- Convertir le schéma (DDL) en syntaxe Fabric Warehouse.
- Créer le schéma (DDL) sur Fabric Warehouse.
- Extraire des données du pool SQL dédié Synapse vers ADLS.
- Marquer la syntaxe Fabric non prise en charge pour les codes T-SQL (procédures stockées, fonctions, vues).
Utilisation recommandée
Il s’agit d’une excellente option pour ceux qui :
- connaissent bien T-SQL ;
- veulent utiliser un environnement de développement intégré comme SQL Server Management Studio (SSMS) ;
- veulent un contrôle plus précis sur les tâches sur lesquelles ils souhaitent travailler.
Vous pouvez exécuter la procédure stockée propre à la conversion de schéma (DDL), l’extraction de données ou l’évaluation de code T-SQL.
Pour la migration des données, vous devez utiliser COPY INTO ou Data Factory pour ingérer les données dans Fabric Warehouse.
Migration à l’aide de projets SQL Database
Microsoft Fabric Data Warehouse est pris en charge dans l’extension des projets SQL Database disponible dans Azure Data Studio et Visual Studio Code.
Cette extension est disponible dans Azure Data Studio et Visual Studio Code. Cette fonctionnalité active des fonctionnalités de contrôle de code source, de test de base de données et de validation de schéma.
Pour plus d’informations sur le contrôle de code source pour les entrepôts dans Microsoft Fabric, notamment les pipelines d’intégration et de déploiement Git, consultez Contrôle de code source avec Warehouse.
Utilisation recommandée
Il s’agit d’une excellente option pour ceux qui préfèrent utiliser un projet SQL Database pour leur déploiement. Cette option intégrait essentiellement les procédures stockées de migration Fabric dans le projet SQL Database pour offrir une expérience de migration fluide.
Un projet SQL Database permet de :
- Convertir le schéma (DDL) en syntaxe Fabric Warehouse.
- Créer le schéma (DDL) sur Fabric Warehouse.
- Extraire des données du pool SQL dédié Synapse vers ADLS.
- Marquer la syntaxe non prise en charge pour les codes T-SQL (procédures stockées, fonctions, vues).
Pour la migration des données, vous utilisez alors COPY INTO ou Data Factory pour ingérer les données dans Fabric Warehouse.
Outre la capacité de prise en charge Azure Data Studio ajoutée à Microsoft Fabric, l’équipe CAT de Microsoft Fabric a fourni un ensemble de scripts PowerShell pour gérer l’extraction, la création et le déploiement de schémas (DDL) et de code de base de données (DML) par le biais d’un projet SQL Database. Pour obtenir une procédure pas à pas de l’utilisation du projet SQL Database avec nos scripts PowerShell, consultez microsoft/fabric-migration sur GitHub.com.
Pour plus d’informations sur les projets SQL Database, consultez Bien démarrer avec l’extension des projets SQL Database et Générer et publier un projet.
Migration de données avec CETAS
La commande T-SQL CREATE EXTERNAL TABLE AS SELECT (CETAS) offre la méthode optimale la plus rentable pour extraire des données de pools SQL dédiés Synapse vers Azure Data Lake Storage (ADLS) Gen2.
Ce que la commande CETAS peut faire :
- Extraire des données dans ADLS.
- Cette option nécessite que les utilisateurs créent le schéma (DDL) sur Fabric Warehouse avant d’ingérer les données. Considérez les options décrites dans cet article pour migrer le schéma (DDL).
Les avantages de cette option sont les suivants :
- Une seule requête par table est envoyée sur le pool SQL dédié Synapse source. Ainsi, tous les emplacements d’accès concurrentiel ne sont pas utilisés, ce qui ne bloque pas les ETL/requêtes de production du client simultanés.
- Aucune mise à l’échelle vers DWU6000 n’est nécessaire, car un seul emplacement d’accès concurrentiel est utilisé pour chaque table, si bien que les clients peuvent utiliser des DWU inférieures.
- L’extraction est exécutée en parallèle sur tous les nœuds de calcul, ce qui est essentiel pour l’amélioration des performances.
Utilisation recommandée
Utilisez CETAS pour extraire les données dans ADLS sous forme de fichiers Parquet. Les fichiers Parquet offrent l’avantage d’un stockage de données efficace avec une compression en colonnes qui nécessite moins de bande passante pour parcourir le réseau. De plus, étant donné que Fabric a stocké les données au format parquet Delta, l’ingestion de données sera 2,5 fois plus rapide que le format de fichier texte, en l’absence de surcharge due à la conversion au format Delta pendant l’ingestion.
Pour augmenter le débit CETAS :
- Ajoutez des opérations CETAS parallèles, ce qui augmente l’utilisation des emplacements d’accès concurrentiel, mais autorise un débit plus élevé.
- Mettez à l’échelle la DWU sur le pool SQL dédié Synapse.
Migration par le biais de dbt
Dans cette section, nous décrivons l’option dbt pour les clients qui utilisent déjà dbt dans leur environnement de pools SQL dédiés Synapse actuel.
Ce que peut faire dbt :
- Convertir le schéma (DDL) en syntaxe Fabric Warehouse.
- Créer le schéma (DDL) sur Fabric Warehouse.
- Convertir le code de base de données (DML) en syntaxe Fabric.
Le framework dbt génère les DDL et DML (scripts SQL) à la volée à chaque exécution. Avec des fichiers de modèle exprimés dans des instructions SELECT, les DDL/DML peuvent être traduits instantanément en n’importe quelle plateforme cible en modifiant le profil (chaîne de connexion) et le type d’adaptateur.
Utilisation recommandée
Le framework dbt est une approche de type « code first ». Les données doivent être migrées à l’aide des options listées dans ce document, comme CETAS ou COPY/Data Factory.
L’adaptateur DBT pour l’entrepôt de données Microsoft Fabric permet aux projets DBT existants qui ciblaient différentes plateformes comme des pools SQL dédiés Synapse, Snowflake, Databricks, Google Big Query ou Amazon Redshift d’être migrés vers Fabric Warehouse avec une simple modification de configuration.
Pour bien démarrer avec un projet dbt ciblant Fabric Warehouse, consultez Tutoriel : Configurer dbt pour Fabric Data Warehouse. Ce document liste également une option permettant de se déplacer entre différents entrepôts/plateformes.
Ingestion des données dans Fabric Warehouse
Pour une ingestion dans Fabric Warehouse, utilisez COPY INTO ou Fabric Data Factory, selon vos préférences. Les deux méthodes correspondent aux options recommandées les plus performantes, car leur débit est équivalent, compte tenu du prérequis qui implique que les fichiers sont déjà extraits dans Azure Data Lake Storage (ADLS) Gen2.
Plusieurs facteurs sont à prendre en compte pour pouvoir concevoir votre processus en vue de performances maximales :
- Avec Fabric, il n’existe aucune contention des ressources lors du chargement de plusieurs tables depuis ADLS vers Fabric Warehouse simultanément. Par conséquent, il n’existe aucune dégradation des performances lors du chargement de threads parallèles. Le débit d’ingestion maximal sera uniquement limité par la puissance de calcul de votre capacité Fabric.
- La gestion des charges de travail Fabric assure la séparation des ressources allouées à la charge et à la requête. Il n’existe aucune contention des ressources pendant l’exécution simultanée des requêtes et du chargement des données.