Contrôle de la source avec Warehouse (aperçu)
Cet article explique comment l’intégration de Git et les pipelines de déploiement fonctionnent pour les entrepôts dans Microsoft Fabric. Découvrez comment configurer une connexion à votre dépôt, gérer vos entrepôts et les déployer dans différents environnements. Le contrôle de code source pour Fabric Warehouse est actuellement une fonctionnalité en préversion.
Vous pouvez utiliser l’intégration Git et les pipelines de déploiement pour différents scénarios :
- Utiliser des projets de base de données Git et SQL pour gérer les modifications incrémentielles, la collaboration d’équipe, l’historique des commits dans des objets de base de données individuels.
- Utiliser des pipelines de déploiement pour promouvoir les modifications de code dans différents environnements de préproduction et de production.
Intégration Git
L’intégration de Git dans Microsoft Fabric permet aux développeurs d’intégrer leurs processus de développement, leurs outils et leurs meilleures pratiques directement dans la plateforme Fabric. Elle permet aux développeurs qui développent dans Fabric de :
- Sauvegarder et versionner leur travail
- Revenir aux étapes précédentes si nécessaire
- Collaborer avec d’autres personnes ou travailler seul à l’aide de branches Git
- Appliquer les capacités des outils de contrôle de code source familiers pour gérer les éléments Fabric
Pour plus d’informations sur le processus d’intégration Git, consultez :
- Intégration de Git dans Fabric
- Concepts de base de l’intégration Git
- Prise en main de l’intégration Git (préversion)
Configurer une connexion au contrôle de code source
À partir de la page Paramètres de l’espace de travail, vous pouvez facilement configurer une connexion à votre dépôt pour commiter et synchroniser les modifications.
- Pour configurer la connexion, consultez Démarrer avec l’intégration de Git. Suivez les instructions pour vous connecter à un dépôt Git à Azure DevOps ou GitHub en tant que fournisseur Git.
- Une fois connectés, vos éléments, y compris les entrepôts, apparaissent dans le panneau Contrôle de code source.
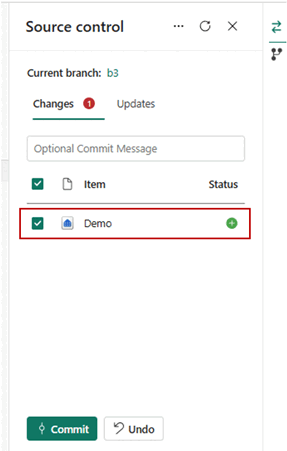
- Une fois que vous avez correctement connecté les instances de l’entrepôt au dépôt Git, vous voyez la structure des dossiers de l’entrepôt dans le dépôt. Vous pouvez maintenant exécuter des opérations telles que la création d’une demande de tirage.
Projets de base de données pour un entrepôt dans Git
L’image suivante est un exemple de structure de fichiers de chaque élément d’entrepôt dans le dépôt :

Lorsque vous commitez l’élément d’entrepôt dans le dépôt Git, l’entrepôt est converti au format de code source, en tant que projet de base de données SQL. Un projet SQL est une représentation locale d’objets SQL qui comprennent le schéma d’une base de données unique, comme des tables, des procédures stockées ou des fonctions. La structure de dossiers des objets de base de données est organisée par schéma/type d’objet. Chaque objet de l’entrepôt est représenté par un fichier .sql qui contient sa définition DDL (Data Definition Language). Les données de table d’entrepôt et les fonctionnalités de sécurité SQL ne sont pas incluses dans le projet de base de données SQL.
Les requêtes partagées sont également commitées dans le dépôt, et héritent du nom sous lequel elles sont enregistrées.
Télécharger le projet de base de données SQL d’un entrepôt dans Fabric
Avec l’extension Projets de base de données SQL disponible dans Azure Data Studio et Visual Studio Code, vous pouvez gérer un schéma d’entrepôt, et gérer les modifications d’objets Warehouse comme d’autres projets de base de données SQL.
Pour télécharger une copie locale du schéma de votre entrepôt, sélectionnez Télécharger le projet de base de données SQL dans le ruban.

La copie locale d’un projet de base de données qui contient la définition du schéma de l’entrepôt. Le projet de base de données peut être utilisé pour :
- Recréer le schéma de l’entrepôt dans un autre entrepôt.
- Développer davantage le schéma de l’entrepôt dans des outils clients tels qu’Azure Data Studio ou Visual Studio Code.
Publier un projet de base de données SQL dans un nouvel entrepôt
Pour publier le schéma de l’entrepôt dans un nouvel entrepôt :
- Créez un entrepôt dans votre espace de travail Fabric.
- Dans la page de lancement du nouvel entrepôt, sous Générer un entrepôt, sélectionnez Projet de base de données SQL.
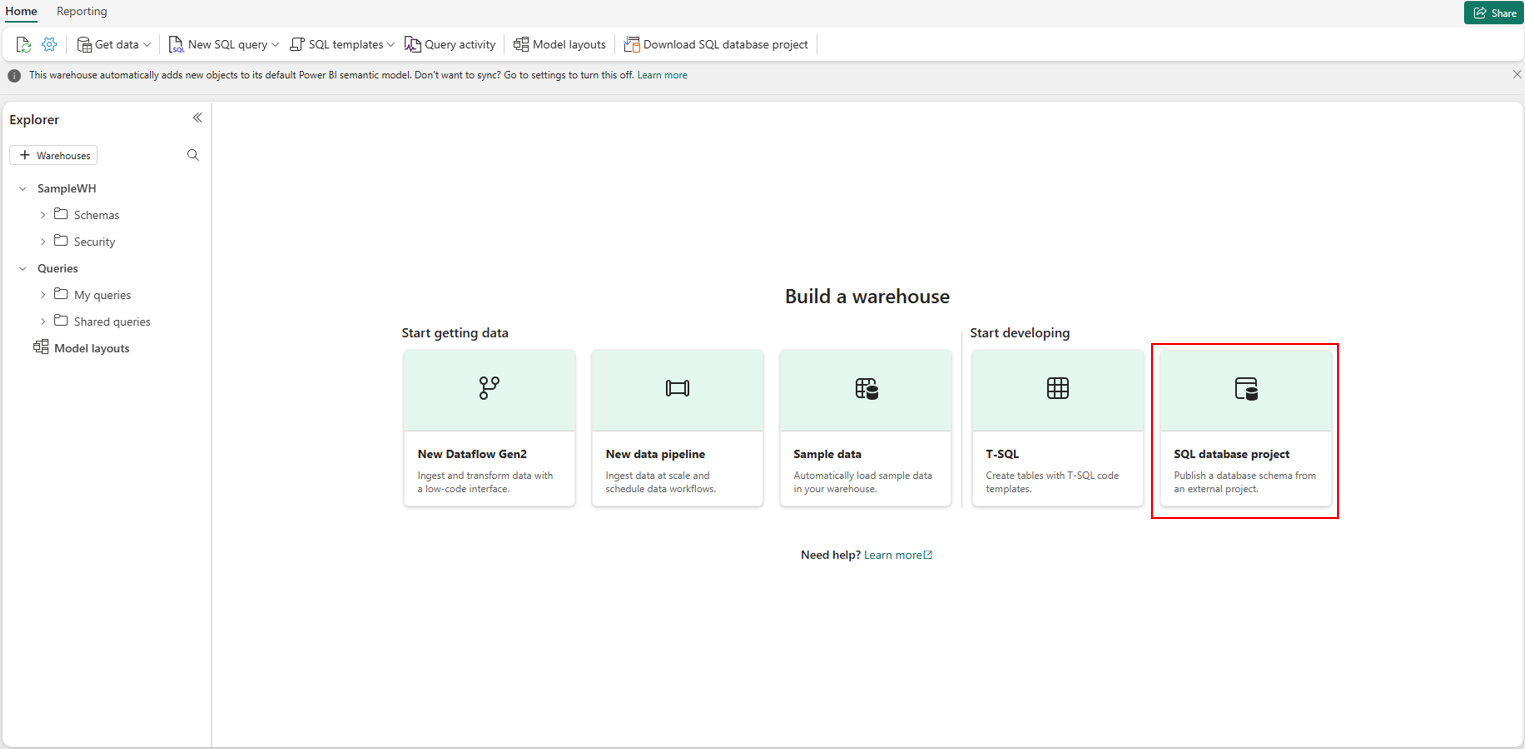
- Sélectionnez le fichier .zip téléchargé à partir de l’entrepôt existant.
- Le schéma de l’entrepôt est publié dans le nouvel entrepôt.

Pipelines de déploiement
Vous pouvez également utiliser des pipelines de déploiement pour déployer votre code d’entrepôt dans différents environnements : développement, test, et production. Les pipelines de déploiement n’exposent pas de projet de base de données.
Effectuez les étapes suivantes pour exécuter votre déploiement d’entrepôt à l’aide du pipeline de déploiement.
- Créez un pipeline de déploiement ou ouvrez un pipeline de déploiement existant. Pour plus d’informations, consultez Bien démarrer avec les pipelines de déploiement.
- Affectez des espaces de travail à différentes phases en fonction de vos objectifs de déploiement.
- Sélectionnez, affichez et comparez des éléments, y compris des entrepôts entre différentes phases, comme illustré dans l’exemple suivant.
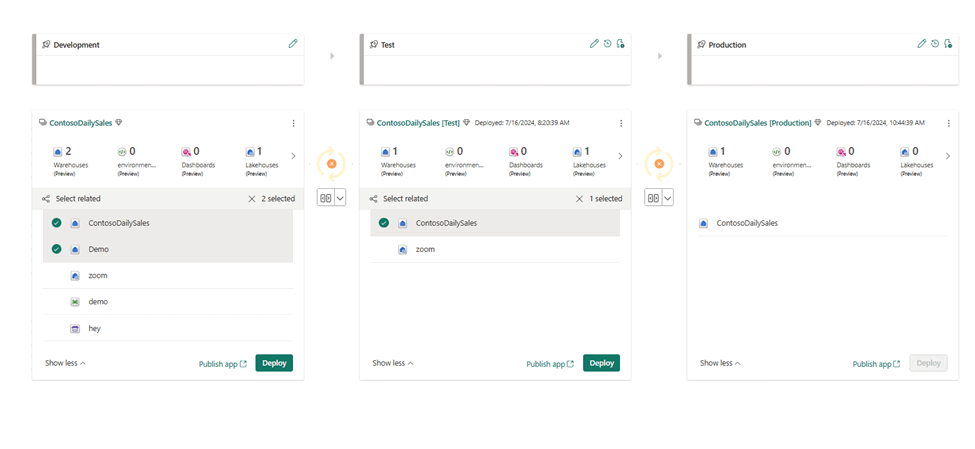
- Sélectionnez Déployer pour déployer vos entrepôts dans les phases Développement, Test, et Production.

Pour plus d’informations sur le processus des pipelines de déploiement Fabric, consultez Vue d’ensemble des pipelines de déploiement Fabric.
Limitations dans le contrôle de code source
- Les fonctionnalités de sécurité SQL doivent être exportées/migrées à l’aide d’une approche basée sur des scripts. Envisagez l’utilisation d’un script post-déploiement dans un projet de base de données SQL, que vous pouvez configurer en ouvrant le projet avec l’extension Projets de base de données SQL disponible dans Azure Data Studio.
Limitations de l’intégration Git
- Actuellement, si vous utilisez
ALTER TABLEpour ajouter une contrainte ou une colonne dans le projet de base de données, la table est supprimée et recréée lors du déploiement, ce qui entraîne une perte de données. Vous pouvez adopter la solution de contournement suivante pour conserver la définition de table et les données :- Créez une nouvelle copie de la table dans l’entrepôt, à l’aide de
CREATE TABLEetINSERT,CREATE TABLE AS SELECT, ou Cloner la table. - Modifiez la nouvelle définition de table avec de nouvelles contraintes ou colonnes, comme vous le souhaitez, à l’aide de
ALTER TABLE. - Supprimez l’ancienne table.
- Renommez la nouvelle table avec le nom de l’ancienne table à l’aide de sp_rename.
- Modifiez la définition de l’ancienne table dans le projet de base de données SQL exactement de la même façon. Le projet de base de données SQL de l’entrepôt dans le contrôle de code source et l’entrepôt dynamique doivent maintenant correspondre.
- Créez une nouvelle copie de la table dans l’entrepôt, à l’aide de
- Actuellement, vous ne devez pas créer de flux de données Gen2 avec une destination de sortie vers l’entrepôt. Le commit et la mise à jour à partir de Git seraient bloqués par un nouvel élément nommé
DataflowsStagingWarehousequi apparaît dans le dépôt. - Le point de terminaison d’analytique SQL n’est pas pris en charge avec l’intégration Git.
Limitations des pipelines de déploiement
- Actuellement, si vous utilisez
ALTER TABLEpour ajouter une contrainte ou une colonne dans le projet de base de données, la table est supprimée et recréée lors du déploiement, ce qui entraîne une perte de données. - Actuellement, vous ne devez pas créer de flux de données Gen2 avec une destination de sortie vers l’entrepôt. Le déploiement serait bloqué par un nouvel élément nommé
DataflowsStagingWarehousequi apparaît dans le pipeline de déploiement. - Le point de terminaison d’analytique SQL n’est pas pris en charge dans les pipelines de déploiement.