Tutoriel : configurer dbt pour Fabric Data Warehouse
S'applique à :✅ Warehouse dans Microsoft Fabric
Ce tutoriel vous guide tout au long de la configuration de dbt et du déploiement de votre premier projet dans un entrepôt Fabric.
Présentation
DBT (Data Build Tool) est une infrastructure open source qui simplifie la transformation des données et l’ingénierie d’analyse. Cette infrastructure se concentre sur les transformations basées sur SQL au sein de la couche d’analyse, en traitant SQL comme du code. dbt prend en charge la gestion de version, la modularisation, les tests et la documentation.
L’adaptateur dbt pour Microsoft Fabric permet de créer des projets dbt, que vous pouvez ensuite déployer sur un Fabric Data Warehouse.
Vous pouvez également modifier la plateforme cible pour le projet dbt en modifiant simplement l’adaptateur. Par exemple, vous pouvez mettre à niveau un projet créé pour un pool SQL dédié Azure Synapse en quelques secondes vers un Fabric Data Warehouse.
Composants prérequis de l’adaptateur dbt pour Microsoft Fabric
Suivez cette liste pour installer, puis configurer les composants prérequis de dbt :
Dernière version de l’adaptateur dbt-fabric du référentiel PyPI (Python Package Index) utilisant
pip install dbt-fabric.pip install dbt-fabricRemarque
En modifiant
pip install dbt-fabricenpip install dbt-synapseet en utilisant les instructions suivantes, vous pouvez installer l’adaptateur dbt pour le pool SQL dédié Synapse.Vérifiez bien que dbt-fabric et ses dépendances sont installés à l’aide de la commande
pip list:pip listCette commande doit renvoyer une longue liste des packages et des versions actuelles.
Si vous n’en avez pas encore, créez un entrepôt. Vous pouvez utiliser la capacité d’essai pour cet exercice : inscrivez-vous à l’essai gratuit de Microsoft Fabric, créez un espace de travail, puis créez un entrepôt.
Prise en main de l’adaptateur dbt-fabric
Ce tutoriel utilise Visual Studio Code, mais vous pouvez utiliser l’outil de votre choix.
Clonez le projet de démonstration jaffle_shop dbt sur votre ordinateur.
- Vous pouvez cloner un référentiel avec le contrôle de code source intégré de Visual Studio Code.
- Ou, par exemple, vous pouvez utiliser la commande
git clone:
git clone https://github.com/dbt-labs/jaffle_shop.gitOuvrez le dossier du projet
jaffle_shopdans Visual Studio Code.
Vous pouvez ignorer l’inscription si vous avez déjà créé un entrepôt.
Créez un fichier
profiles.yml. Ajoutez la configuration suivante àprofiles.yml. Ce fichier configure la connexion à votre entrepôt dans Microsoft Fabric à l’aide de l’adaptateur dbt-fabric.config: partial_parse: true jaffle_shop: target: fabric-dev outputs: fabric-dev: authentication: CLI database: <put the database name here> driver: ODBC Driver 18 for SQL Server host: <enter your SQL analytics endpoint here> schema: dbo threads: 4 type: fabricRemarque
Modifiez la valeur
typedefabricàsynapsepour basculer l’adaptateur de base de données vers Azure Synapse Analytics, si vous le souhaitez. Vous pouvez mettre à jour toute plateforme de données d’un projet dbt existant en modifiant l’adaptateur de base de données. Si vous souhaitez en savoir plus, veuillez consulter la liste dbt des plateformes de données prises en charge.Authentifiez-vous auprès d’Azure dans le terminal Visual Studio Code.
- Exécutez
az logindans le terminal Visual Studio Code si vous utilisez l’authentification Azure CLI. - Pour le principal du service ou une autre authentification Microsoft Entra ID (anciennement Azure Active Directory) dans Microsoft Fabric, veuillez consulter Configuration de dbt (Data Build Tool) et Configurations de ressources dbt. Pour plus d'informations sur l'authentification Microsoft Entra en tant qu’alternative à l'authentification SQL dans Microsoft Fabric.
- Exécutez
Vous pouvez maintenant tester la connectivité. Pour tester la connectivité à votre entrepôt, exécutez
dbt debugdans le terminal Visual Studio Code.dbt debug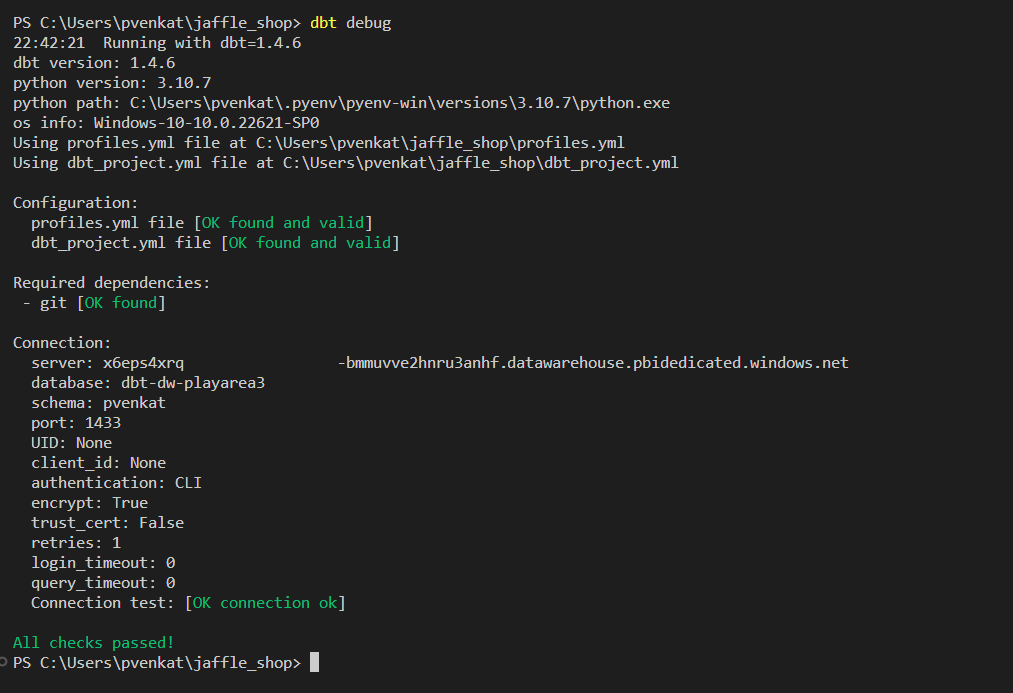
Toutes les vérifications ont donné satisfaction. Vous pouvez donc connecter votre entrepôt à l’aide de l’adaptateur dbt-fabric depuis le projet
jaffle_shopdbt.Maintenant, il est temps de tester le fonctionnement de l’adaptateur. Exécutez d’abord
dbt seedpour insérer des exemples de données dans l’entrepôt.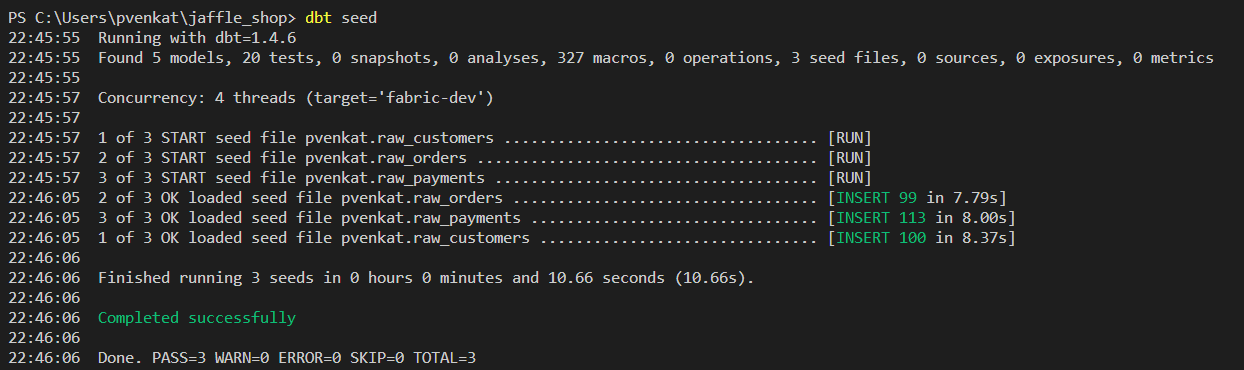
Exécutez
dbt runpour valider les données par rapport à certains tests.dbt run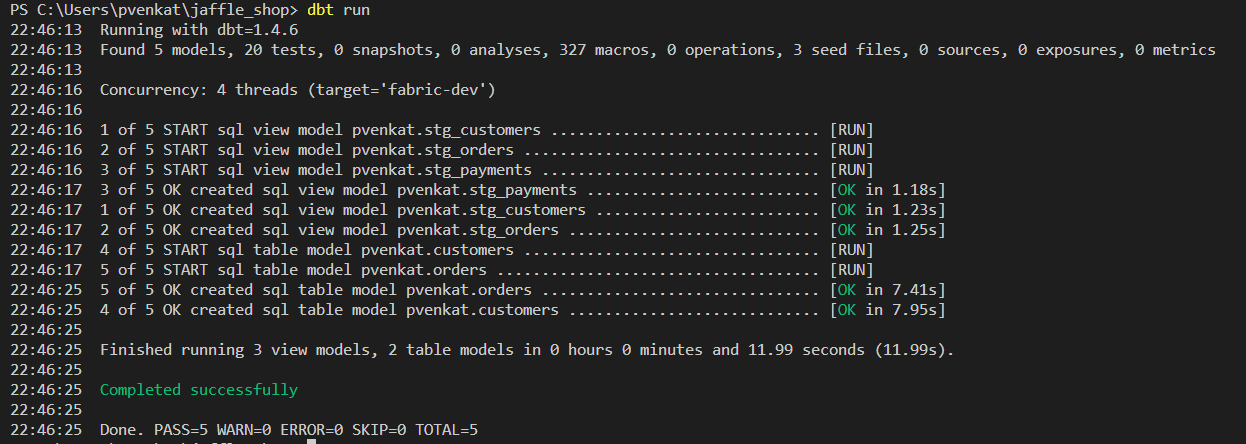
Exécutez
dbt testpour exécuter les modèles définis dans le projet dbt de la version de démonstration.dbt test




Vous avez maintenant déployé un projet dbt dans Fabric Data Warehouse.
Passer d’un entrepôt à l’autre
Vous pouvez en toute simplicité déplacer le projet dbt entre différents entrepôts. Un projet dbt sur n’importe quel entrepôt pris en charge peut être rapidement migré avec ce processus en trois étapes :
Installez le nouvel adaptateur. Si vous souhaitez en savoir plus, notamment sur l'installation, veuillez consulter la rubrique Adaptateurs dbt.
Mettez à jour la propriété
typedans le fichierprofiles.yml.Créez le projet.
dbt dans Fabric Data Factory
Lorsqu’il est intégré à Apache Airflow, un système de gestion de flux de travail populaire, dbt devient un outil puissant pour orchestrer les transformations de données. Les fonctionnalités de planification et de gestion des tâches d’Airflow permettent aux équipes de données d’automatiser les exécutions dbt. Il garantit des mises à jour régulières des données et maintient un flux cohérent de données de haute qualité pour l’analyse et la création de rapports. Cette approche combinée, qui utilise l’expertise de transformation de dbt et la gestion des flux de travail d’Airflow, offre des pipelines de données efficaces et robustes, ce qui aboutit à des prises de décision basées sur les données plus rapides et plus éclairées.
Apache Airflow est une plateforme open source utilisée pour créer, planifier et superviser par programmation des workflows de données complexes. Elle vous permet de définir un ensemble de tâches, appelées opérateurs, qui peuvent être combinées en graphes orientés acyclique (DAG) pour représenter des pipelines de données.
Pour plus d’informations sur l’opérationnalisation de dbt avec votre entrepôt, consultez Transformer des données à l’aide de dbt avec Data Factory dans Microsoft Fabric.
À propos de l’installation
Points importants à prendre en compte lors de l’utilisation de l’adaptateur dbt-fabric :
Passez en revue les limitations actuelles dans l’entrepôt de données Microsoft Fabric.
Fabric prend en charge l’authentification Microsoft Entra ID (anciennement Azure Active Directory) pour les principaux d’utilisateur, les identités d’utilisateur et les principaux de service. Le mode d’authentification recommandé pour travailler de manière interactive sur l’entrepôt est l’interface CLI (interface de ligne de commande) et l’utilisation de principaux de service pour l’automatisation.
Étudiez les commandes T-SQL (Transact-SQL) non prises en charge dans Fabric Data Warehouse.
L’adaptateur dbt-fabric prend en charge certaines commandes T-SQL en utilisant
Create Table as Select(CTAS),DROPet des commandesCREATEtelles queALTER TABLE ADD/ALTER/DROP COLUMN,MERGE,TRUNCATE,sp_rename.Veuillez consulter la rubrique Types de données non pris en charge si vous souhaitez en savoir plus sur les types de données pris en charge et non pris en charge.
Vous pouvez consigner les problèmes sur l’adaptateur dbt-fabric en consultant Problèmes · microsoft/dbt-fabric · GitHub.