Recommandations d’étiquetage automatique basées sur les services pour la conformité du gouvernement australien avec PSPF
Cet article fournit des conseils aux organisations gouvernementales australiennes sur les configurations permettant de protéger les informations classifiées en matière de sécurité grâce à l’utilisation de stratégies d’étiquetage automatique de confidentialité basées sur les services. Son objectif est d’aider les organisations gouvernementales à améliorer leur posture de sécurité des informations, en particulier dans les scénarios où des informations sont transmises entre les organisations gouvernementales. Les conseils de cet article ont été rédigés pour s’aligner au mieux sur les exigences décrites dans le Cadre des politiques de sécurité de protection (PSPF) (en particulier la politique 8 du PSPF Annexe F : Australian Government Email Protective Marquage Standard) et le Manuel de sécurité de l’information (ISM).
L’article précédent, Vue d’ensemble de l’étiquetage automatique, fournit des informations générales supplémentaires sur l’utilisation de l’étiquetage automatique dans un environnement de travail gouvernemental moderne et sur la façon dont elle contribue à réduire les risques de sécurité des données.
La fonctionnalité d’étiquetage automatique basée sur le service permet :
-
Analyse des e-mails à la recherche de contenu sensible et leur application d’étiquettes pendant le transport : les organisations gouvernementales australiennes peuvent utiliser cette fonctionnalité pour :
- Étiquetez les e-mails marqués reçus d’autres pspf (Protection Security Policy Framework) ou d’organisations équivalentes activées.
- Étiquetage des e-mails reçus d’organisations non compatibles PSPF via la détection d’informations sensibles ou d’autres identificateurs.
-
Analyse des éléments existants dans des emplacements SharePoint (SharePoint/OneDrive/Teams) à la recherche de marquages de protection ou de contenu sensible et leur application d’étiquettes : les organisations gouvernementales australiennes peuvent utiliser cette fonctionnalité pour :
- Étiquetez les données Microsoft 365 existantes au repos.
- Migrer à partir d’outils de classification ou de taxonomies hérités.
Étiquetage des e-mails pendant le transport
Cet article est une extension des concepts abordés dans les stratégies de marquage des e-mails où les méthodes d’application des marquages aux e-mails sont abordées.
Les stratégies d’étiquetage automatique basées sur le service configurées pour le service Exchange case activée pour les marquages sur les e-mails et appliquent les étiquettes appropriées. Les e-mails entrants peuvent avoir des marquages ou des étiquettes de confidentialité déjà appliqués par les organisations de l’expéditeur, mais ceux-ci n’appliquent pas, par défaut, les protections basées sur les étiquettes de votre organisation. La conversion de marquages ou d’étiquettes externes en étiquettes internes garantit que la protection contre la perte de données (DLP) et d’autres contrôles pertinents sont appliqués.
Dans le contexte du gouvernement australien, l’identification des caractéristiques du courrier électronique comprend généralement :
- X-Protective-Marking x-headers
- Marquages d’objet
- En-têtes et pieds de page textuels
configuration de stratégie basée sur Email
Les stratégies d’étiquetage automatique basées sur les services sont configurées dans le portail Microsoft Purview sous Information Protection Stratégies>>d’étiquetage automatique.
Les stratégies d’étiquetage automatique sont similaires aux stratégies DLP à créer, mais contrairement aux recommandations DLP, une seule stratégie d’étiquetage automatique est nécessaire pour chaque étiquette que nous souhaitons appliquer pour la configuration basée sur l’e-mail.
Les stratégies d’étiquetage automatique qui vérifient les marquages PSPF sont créées à partir du modèle de stratégie personnalisé et sont nommées en fonction de l’action. Par exemple, Étiqueter les Email NON OFFICIELs entrants. Les stratégies doivent également être appliquées au service Exchange uniquement pour garantir que les options requises, telles que subject, sont disponibles pour l’interface.
Pour atteindre un niveau élevé de maturité PSPF, des stratégies d’étiquetage automatique doivent être implémentées pour effectuer les opérations suivantes :
- Étiquette automatique basée sur les en-têtes x appliqués aux e-mails entrants.
- Étiquette automatique basée sur les marquages d’objet appliqués aux e-mails entrants.
- Étiquette automatique basée sur les types d’informations sensibles (SIT) présents dans le corps de l’e-mail entrant (facultatif).
Une stratégie d’étiquetage automatique est requise pour chaque étiquette, éventuellement avec plusieurs règles (une pour chacun des scénarios ci-dessus). Les paramètres permettant de remplacer automatiquement les étiquettes existantes ne sont pas nécessaires.
Vérification des règles pour les x-headers
Les règles créées pour case activée x-protective-marking x-header de courrier électronique doivent être nommées de manière appropriée, par exemple, « case activée for OFFICIAL x-header ».
Ils ont besoin d’une condition d’en-tête correspondant aux modèles avec un nom d’en-tête « x-protective-marking » et une valeur d’expression régulière (RegEx) qui peut correspondre à l’en-tête x-protective-marking sur les e-mails entrants. Par exemple, la syntaxe permettant d’identifier les éléments marqués comme « OFFICIAL : Confidentialité personnelle sensible » est la suivante :
X-Protective-Marking : SEC=OFFICIAL[-: ]Sensitive(?:,)? ACCESS=Personal-Privacy
Dans cette expression, [-: ] correspond à un trait d’union, un signe deux-points ou un espace, ce qui permet une certaine flexibilité dans la façon dont les en-têtes sont appliqués, en notant que le PSPF spécifie un signe deux-points.
Le modèle de permet que (?:,)? les éléments soient mis en correspondance, qu’une virgule soit incluse ou non entre la classification de sécurité et IMM.
Règles de vérification des marquages d’objet
Les stratégies d’étiquetage automatique doivent inclure une deuxième règle, qui vérifie les marquages basés sur l’objet. Ces règles doivent être nommées de manière appropriée, par exemple, « Vérifier l’objet OFFICIEL ».
Les règles ont besoin d’une condition de l’objet correspond aux modèles avec une valeur d’une expression régulière appropriée. Par exemple :
\[SEC=OFFICIAL[-: ]Sensitive(?:,)? ACCESS=Personal-Privacy
Dans l’exemple précédent, le \ caractère d’échappement est requis pour garantir que les crochets sont traités comme faisant partie de l’objet de l’e-mail et non comme faisant partie de l’expression régulière.
Cette syntaxe n’inclut pas de crochet fermant (\]). Le raisonnement pour cela est abordé dans les approches pour plusieurs marqueurs de gestion de l’information (IMMs).
Vérification des règles pour les SIT
Pour identifier les informations sensibles , nous avons recommandé un ensemble de SIT pour identifier les marquages de protection. Ces SIT peuvent également être utilisés dans les stratégies d’étiquetage automatique s’appliquant à la messagerie électronique. Les SIT fournissent une troisième méthode d’identification des classifications d’e-mails entrants et aident également à corriger le déshabillage des en-têtes x.
Les règles logiques nécessitent une condition de contenu contient,typed’informations sensibles, puis que le SIT correspondant à la classification soit sélectionné.
Conseil
Les règles sit peuvent générer plus de faux positifs que les approches basées sur l’en-tête x ou le sujet. Les organisations gouvernementales qui débutent dans ce domaine peuvent envisager d’utiliser uniquement des règles basées sur l’en-tête x et l’objet, puis d’ajouter des règles basées sur sit lorsque cela est confortable.
Les discussions sur les classifications et les alertes générées par le service qui font référence ou incluent du contenu d’élément, comme les alertes DLP, sont des exemples de faux positifs. Pour cette raison, les règles d’étiquetage automatique basées sur SIT doivent faire l’objet de tests supplémentaires ou d’une période de surveillance prolongée avant l’implémentation complète afin d’extraire les faux positifs et d’appliquer des exceptions. Les exemples d’exceptions incluent le domaine « microsoft.com », à partir duquel les alertes basées sur le service sont envoyées.
L’inclusion de règles sit présente des avantages significatifs. Envisagez la justification du changement d’étiquette et le risque que les utilisateurs réduisent de manière malveillante l’étiquette appliquée à une conversation par e-mail. Si un e-mail PROTECTED est réduit à NON OFFICIEL, mais que nous pouvons détecter « [SEC=PROTECTED] » dans le corps de la conversation par e-mail, nous pouvons alors réappliquer automatiquement l’étiquette PROTECTED. Cela permet de revenir dans l’étendue des stratégies DLP PROTÉGÉES du locataire et d’autres contrôles. Il y a des situations où des articles sont intentionnellement reclassés dans un état inférieur, par exemple, une publication d’une note de presse budget, qui a été sous embargo jusqu’à un moment précis, de sorte que la configuration SIT doit prendre en compte ces cas d’usage dans l’organisation gouvernementale.
Les règles basées sur SIT peuvent également aider à prendre en charge les petites organisations gouvernementales qui génèrent des e-mails, mais dont la maturité de conformité est inférieure. Ces organisations peuvent ne pas avoir de méthodes de marquage plus avancées comme les en-têtes x.
Approches pour plusieurs imMs
Les marqueurs de gestion des informations (IMMs) proviennent de l’Australian Government Recordkeeping Metadata Standard (AGRkMS) et constituent un moyen facultatif d’identifier les informations soumises à des restrictions non liées à la sécurité. Comme introduit dans l’utilisation de plusieurs imMs, AGRkMS définit une valeur IMM ou « type de droits », qui est enregistrée en tant que propriété unique. Certaines organisations gouvernementales australiennes ont étendu leur utilisation des MPM par des taxonomies de classification qui permettent d’appliquer plusieurs MPM (par exemple, « PROTECTED Personal Privacy Legislative Secrety »).
L’utilisation de plusieurs imMs peut compliquer les configurations DLP et d’étiquetage automatique, car les expressions régulières qui vérifient les marquages appliqués aux éléments entrants doivent être plus complexes. Il existe également un risque que les e-mails marqués avec plusieurs messages instantanés, lorsqu’ils sont envoyés à des organisations externes, soient mal interprétés en recevant des passerelles de messagerie. Cela augmente le risque de perte d’informations. Pour ces raisons, les exemples inclus dans la taxonomie des étiquettes de confidentialité et les stratégies de marquage des e-mails ont appliqué des imMs uniques uniquement conformément aux règles AGRkMS.
Organisations utilisant des machines imme uniques uniquement
Pour que les organisations qui utilisent des mims uniques uniquement pour prendre en charge les e-mails reçus d’organisations externes avec plusieurs imMs appliquées, les crochets fermants («\] ») ont été omis dans les règles d’étiquetage automatique basées sur l’objet. Cela nous permet d’étiqueter les e-mails en fonction du premier IMM appliqué à son objet. Cette approche garantit que les éléments sont protégés par le biais de contrôles basés sur des étiquettes, que votre taxonomie d’étiquettes s’aligne ou non entièrement sur les autres organisations gouvernementales qui peuvent vous envoyer des e-mails.
En ce qui concerne les approches basées sur les en-têtes x, celles qui appliquent plusieurs imMs à X-Protective-Marking x-headers sont susceptibles de le faire via l’approche suivante :
X-Protective-Marking : SEC=<Security Classification>, ACCESS=<First IMM>, ACCESS=<Second IMM>
S’il n’y a pas de crochets fermants inclus dans la syntaxe X-Protective-Marking, l’élément est étiqueté en fonction du premier IMM présent dans le marquage. L’élément serait ensuite protégé par le biais des premiers contrôles IMMs et les marquages visuels de la deuxième IMM seraient toujours en place sur l’élément.
Organisations appliquant plusieurs imMs
Pour ceux qui décident d’étendre leur taxonomie d’étiquette et d’autres configurations pour prendre en charge plusieurs imMs en dehors des règles AGRkMS, ils doivent s’assurer que leurs règles d’étiquetage automatique prennent en charge les éventuels conflits. Par exemple, une règle de vérification pour 'SEC=OFFICIAL :Sensitive, ACCESS=Legislative-Secrecy' doit exclure toutes les valeurs avec une deuxième IMM appliquée, car sinon les éléments pourraient être étiquetés de manière incorrecte avec le seul IMM.
Les exclusions peuvent être appliquées en ajoutant des exceptions aux règles d’étiquetage automatique. Par exemple :
Sauf si l’en-tête correspond aux modèles :
X-Protective-Marking : SEC=OFFICIAL:Sensitive, ACCESS=Legislative-Secrecy, ACCESS=Personal-Privacy
X-Protective-Marking : SEC=OFFICIAL:Sensitive, ACCESS=Legislative-Secrecy, ACCESS=Legislative-Secrecy
X-Protective-Marking : SEC=OFFICIAL:Sensitive, ACCESS=Legislative-Secrecy, ACCESS=Legal-Privilege
Vous pouvez également prendre en charge les exceptions dans l’expression régulière de la règle :
L’en-tête correspond aux modèles :
X-Protective-Marking :SEC=OFFICIAL[-: ]Sensitive, ACCESS=Legislative-Secrecy(?!, ACCESS=)
Pour les règles basées sur SIT, la syntaxe incluse dans l’exemple de syntaxe SIT pour détecter les marquages de protection ne prend en charge que les MMM uniques. Ces SIT doivent être modifiés pour éliminer les faux positifs et d’autres SIT doivent être ajoutés pour s’aligner sur les étiquettes supplémentaires.
Informations d’étiquetage automatique provenant de gouvernements étrangers
De nombreuses organisations gouvernementales australiennes traitent d’informations marquées ou classifiées provenant de gouvernements étrangers. Certaines de ces classifications étrangères ont une équivalence dans la taxonomie de classification PSPF, qui est définie dans pspf policy 7 : Security governance for international sharing. Les organisations qui communiquent avec les gouvernements étrangers peuvent utiliser les approches décrites dans ce guide pour traduire les marquages étrangers en leur équivalent PSPF.
Traitement des marquages du secret législatif
Le secret législatif ne doit pas être appliqué aux éléments sans indication des exigences de secret législatif spécifiques qui s’appliquent aux informations :
| Conditions requises | Détails |
|---|---|
| Politique 8 C.4 du PSPF - Marqueurs de gestion de l’information | Le secret législatif imm est utilisé pour attirer l’attention sur l’applicabilité d’une ou plusieurs dispositions spécifiques relatives au secret. Le Ministère des affaires intérieures recommande que le destinataire soit informé de la disposition spécifique en incluant un avis d’avertissement placé en haut ou en bas de chaque page d’un document ou dans le corps d’un courrier électronique qui identifie expressément les dispositions spécifiques en matière de confidentialité en vertu desquelles les informations sont couvertes. |
Microsoft recommande d’utiliser des étiquettes de secret législatif via une étiquette alignée directement sur la législation en question. Par exemple, considérez une structure d’étiquette de :
OFFICIAL Sensitive
- OFFICIAL Sensitive
- SECRET LÉGISLATIF SENSIBLE OFFICIEL
- EXEMPLE DE LOI SUR LE SECRET LÉGISLATIF SENSIBLE OFFICIEL
Avec une telle structure d’étiquette, les utilisateurs travaillant avec des informations relatives à l'« exemple de loi » appliqueraient l’étiquette « Official Sensitive Legislative Secrety Example Act » aux informations pertinentes. Les marquages visuels de cette étiquette doivent également indiquer l’acte en question. Par exemple, ils peuvent appliquer des en-têtes et des pieds de page de « OFFICIAL : Sensitive Legislative Secrety (Exemple de loi) ».
Remarque
L’étiquette « OFFICIAL Sensitive Legislative Secrety Example Act » pourrait avoir son nom d’affichage d’étiquette abrégé en « OFFICIAL Sensitive Example Act » pour améliorer l’expérience utilisateur d’étiquetage. Toutefois, le marquage visuel de l’étiquette doit inclure tous les éléments afin de prendre en charge les approches de l’étiquetage automatique.
L’étiquette et les marquages fournissent une indication de la classification de sécurité des éléments, du fait qu’elles sont pertinentes pour les exigences législatives de secret et de la législation spécifique référencée. Les marquages appliqués dans cet ordre permettent également aux organisations externes qui reçoivent les informations mais qui n’ont pas l’étiquette « Exemple d’acte » configurée d’identifier et de traiter les informations conformément à leur étiquette de secret législatif. Le fait de considérer l’exemple de loi comme un secret législatif permet d’appliquer des protections aux informations jointes.
Le gouvernement organization produire l’information peut nécessiter de distinguer les éléments suivants :
- Leurs informations relatives à l’exemple d’acte,
- Informations relatives à d’autres lois ; et
- L’information produite à l’extérieur qui se rapporte à la législation que d’autres ministères travaillent avec.
Pour ce faire, l’administrateur divise les règles d’étiquetage automatique en deux et utilise un SIT pour identifier les informations relatives à l’exemple de loi :
| Nom de la règle | Condition | Étiquette à appliquer |
|---|---|---|
| Rechercher l’en-tête x du système d’exploitation LS | L’en-tête correspond au modèle :X-Protective-Marking : SEC=OFFICIAL[-: ]Sensitive, ACCESS=Legislative-Secrecy AND Groupe NOT Contenu contient : Type d’informations sensibles Exemple de mot clé ACT SIT contenant : (Example Act) |
SECRET LÉGISLATIF SENSIBLE OFFICIEL |
| Rechercher l’objet LS du système d’exploitation | Modèle de correspondance de l’objet :\[SEC=OFFICIAL[-: ]Sensitive(?:,)? ACCESS=Legislative-Secrecy AND Group NOT Le contenu contient : Type d’informations sensibles : Exemple de mot clé ACT SIT contenant : (Example Act) |
SECRET LÉGISLATIF SENSIBLE OFFICIEL |
| Vérifier l’exemple d’en-tête x de l’acte de système d’exploitation | L’en-tête correspond au modèle :X-Protective-Marking : SEC=OFFICIAL[-: ]Sensitive, ACCESS=Legislative-Secrecy AND Contenu contient : Type d’informations sensibles Exemple de mot clé ACT SIT contenant : (Example Act) |
OFFICIAL Sensitive Example Act |
| Rechercher l’objet de l’exemple d’acte de système d’exploitation | Modèle de correspondance de l’objet :\[SEC=OFFICIAL[-: ]Sensitive(?:,)? ACCESS=Legislative-Secrecy AND Le contenu contient : Type d’informations sensibles : Exemple de mot clé ACT SIT contenant : (Example Act) |
OFFICIAL Sensitive Example Act |
Exemple de configuration de l’étiquetage automatique basé sur l’e-mail
Les exemples de stratégies d’étiquetage automatique répertoriés ici appliquent automatiquement des étiquettes de confidentialité aux e-mails entrants en fonction du marquage appliqué par des organisations gouvernementales externes.
Les exemples de stratégies suivants ne doivent pas être l’intégralité d’une configuration d’étiquetage automatique d’une organisation, car d’autres scénarios tels que l’étiquetage des éléments existants au repos doivent également être pris en compte.
Nom de la stratégie : Étiqueter les Email NON OFFICIELs entrants
| Nom de la règle | Condition | Étiquette à appliquer |
|---|---|---|
| Rechercher un x-header non officiel | L’en-tête correspond au modèle :X-Protective-Marking : SEC=UNOFFICIAL |
OFFICIEUX |
| Rechercher l’objet NON OFFICIEL | Modèle de correspondance de l’objet :\[SEC=UNOFFICIAL\] |
OFFICIEUX |
Nom de la stratégie : Étiqueter les Email OFFICIAL entrants
Cette stratégie doit s’assurer que les éléments marqués comme OFFICIEL ne sont pas étiquetés de manière incorrecte comme ÉTANT SENSIBLES OFFICIELs. Pour ce faire, il utilise l’opérande non RegEx (?!) pour les x-headers et les crochets fermants (\]) dans les objets de l’e-mail :
| Nom de la règle | Condition | Étiquette à appliquer |
|---|---|---|
| Rechercher l’en-tête x OFFICIAL | L’en-tête correspond au modèle :X-Protective-Marking : SEC=OFFICIAL(?![-: ]Sensitive) |
FONCTIONNAIRE |
| Rechercher l’objet OFFICIAL | Modèle de correspondance de l’objet :\[SEC=OFFICIAL\] |
FONCTIONNAIRE |
Nom de la stratégie : Étiqueter les Email sensibles OFFICIAL entrants
Cette stratégie doit s’assurer que les éléments marqués avec des messages instantanés supplémentaires (confidentialité personnelle, etc.) ou des mises en garde ne sont pas étiquetés de manière incorrecte comme ÉTANT SENSIBLES. Pour ce faire, il recherche les messages instantanés ou les mises en garde appliquées à l’en-tête x et aux crochets fermants (\]) dans l’objet.
Cet exemple recherche une mise en garde pour NATIONAL CABINET, car il s’agit du seul avertissement défini pour une utilisation en combinaison avec OFFICIAL Sensitive dans cette configuration recommandée. Si votre organization utilise d’autres mises en garde dans sa taxonomie, la mise en garde doit également être prise en compte dans l’expression pour vous assurer que l’étiquette appropriée est appliquée aux éléments reçus.
| Nom de la règle | Condition | Étiquette à appliquer |
|---|---|---|
| Rechercher l’en-tête x du système d’exploitation | L’en-tête correspond au modèle :X-Protective-Marking : OFFICIAL[:\- ]\s?Sensitive(?!, ACCESS)(?!, CAVEAT=SH[-: ]NATIONAL[- ]CABINET) |
OFFICIAL Sensitive |
| Rechercher l’objet du système d’exploitation | Modèle de correspondance de l’objet :\[SEC=OFFICIAL[-: ]Sensitive\] |
OFFICIAL Sensitive |
Nom de la stratégie : Étiqueter l’Email de confidentialité personnelle sensible officielle entrante
| Nom de la règle | Condition | Étiquette à appliquer |
|---|---|---|
| Rechercher l’en-tête x PP du système d’exploitation | L’en-tête correspond au modèle :X-Protective-Marking : SEC=OFFICIAL[-: ]Sensitive, ACCESS=Personal-Privacy |
Confidentialité personnelle sensible officielle |
| Rechercher l’objet PP du système d’exploitation | Modèle de correspondance de l’objet :\[SEC=OFFICIAL[-: ]Sensitive(?:,)? ACCESS=Personal-Privacy |
Confidentialité personnelle sensible officielle |
Nom de la stratégie : Étiqueter les Email de privilèges juridiques sensibles officiels entrants
| Nom de la règle | Condition | Étiquette à appliquer |
|---|---|---|
| Rechercher l’en-tête x-header du système d’exploitation LP | L’en-tête correspond au modèle :X-Protective-Marking : SEC=OFFICIAL[-: ]Sensitive, ACCESS=Legal-Privilege |
Official : Privilège juridique sensible |
| Rechercher l’objet OS LP | Modèle de correspondance de l’objet :\[SEC=OFFICIAL[-: ]Sensitive(?:,)? ACCESS=Legal-Privilege |
Official : Privilège juridique sensible |
Nom de la stratégie : Étiqueter le secret législatif sensible officiel entrant
| Nom de la règle | Condition | Étiquette à appliquer |
|---|---|---|
| Rechercher l’en-tête x du système d’exploitation LS | L’en-tête correspond au modèle :X-Protective-Marking : SEC=OFFICIAL[-: ]Sensitive, ACCESS=Legislative-Secrecy |
SECRET LÉGISLATIF SENSIBLE OFFICIEL |
| Rechercher l’objet LS du système d’exploitation | Modèle de correspondance de l’objet :\[SEC=OFFICIAL[-: ]Sensitive(?:,)? ACCESS=Legislative-Secrecy |
SECRET LÉGISLATIF SENSIBLE OFFICIEL |
Nom de la stratégie : Étiqueter le CABINET NATIONAL SENSIBLE OFFICIEL ENTRANT
| Nom de la règle | Condition | Étiquette à appliquer |
|---|---|---|
| Rechercher l’en-tête x du contrôleur de système d’exploitation | L’en-tête correspond au modèle :X-Protective-Marking : SEC=OFFICIAL[-: ]Sensitive, CAVEAT=SH[-: ]NATIONAL[- ]CABINET |
CABINET NATIONAL SENSIBLE OFFICIEL |
| Rechercher l’objet NC du système d’exploitation | Modèle de correspondance de l’objet :\[SEC=OFFICIAL[-: ]Sensitive(?:,)? CAVEAT=SH[-: ]NATIONAL[- ]CABINET |
CABINET NATIONAL SENSIBLE OFFICIEL |
Nom de la stratégie : Étiqueter les Email PROTECTED entrants
Cette stratégie garantit que les éléments marqués avec des imMs ou des avertissements supplémentaires ne sont pas étiquetés de manière incorrecte comme PROTECTED. Pour ce faire, il recherche les messages instantanés ou les mises en garde appliquées à l’en-tête x et aux crochets fermants (\]) dans l’objet.
| Nom de la règle | Condition | Étiquette à appliquer |
|---|---|---|
| Rechercher protected x-header | L’en-tête correspond au modèle :X-Protective-Marking : SEC=PROTECTED(?!, ACCESS)(?!, CAVEAT=SH[-: ]CABINET)(?!, CAVEAT=SH[-: ]NATIONAL[- ]CABINET) |
PROTÉGÉ |
| Rechercher l’objet PROTÉGÉ | Modèle de correspondance de l’objet :\[SEC=PROTECTED\] |
PROTÉGÉ |
Nom de la stratégie : Étiqueter le Email de confidentialité personnelle protected entrant
| Nom de la règle | Condition | Étiquette à appliquer |
|---|---|---|
| Rechercher l’en-tête x PP PROTÉGÉ | Modèle de correspondance de l’objet :X-Protective-Marking : SEC=PROTECTED(?:,)? ACCESS=Personal-Privacy |
Protection de la confidentialité personnelle |
| Rechercher l’objet PP PROTÉGÉ | L’en-tête correspond au modèle :\[SEC=PROTECTED(?:,)? ACCESS=Personal-Privacy |
Protection de la confidentialité personnelle |
Nom de la stratégie : Étiqueter les Email de privilèges juridiques PROTECTED entrants
| Nom de la règle | Condition | Étiquette à appliquer |
|---|---|---|
| Rechercher protected LP x-header | L’en-tête correspond au modèle :X-Protective-Marking : SEC=PROTECTED(?:,)? ACCESS=Legal-Privilege |
PROTECTED Legal Privilege |
| Rechercher l’objet LP PROTÉGÉ | Modèle de correspondance de l’objet :\[SEC=PROTECTED(?:,)? ACCESS=Legal-Privilege |
PROTECTED Legal Privilege |
Nom de la stratégie : Étiqueter le Email de secret législatif PROTECTED entrant
| Nom de la règle | Condition | Étiquette à appliquer |
|---|---|---|
| Rechercher protected LS x-header | L’en-tête correspond au modèle :X-Protective-Marking : SEC=PROTECTED(?:,)? ACCESS=Legislative-Secrecy |
PROTÉGÉ Secret législatif |
| Rechercher l’objet LS PROTÉGÉ | Modèle de correspondance de l’objet :\[SEC=PROTECTED(?:,)? ACCESS=Legislative-Secrecy |
PROTÉGÉ Secret législatif |
Nom de la stratégie : Étiqueter le Email PROTECTED CABINET entrant
| Nom de la règle | Condition | Étiquette à appliquer |
|---|---|---|
| Rechercher l’en-tête x-en-tête P C | L’en-tête correspond au modèle :X-Protective-Marking : SEC=PROTECTED, CAVEAT=SH[-: ]CABINET |
CABINET PROTÉGÉ |
| Rechercher le sujet C PROTÉGÉ | Modèle de correspondance de l’objet :\[SEC=PROTECTED(?:,)? CAVEAT=SH[-: ]CABINET |
CABINET PROTÉGÉ |
Nom de la stratégie : Étiqueter le Email national protégé entrant
| Nom de la règle | Condition | Étiquette à appliquer |
|---|---|---|
| Rechercher l’en-tête x-header P NC | L’en-tête correspond au modèle :X-Protective-Marking : SEC=PROTECTED, CAVEAT=SH[-: ]NATIONAL[- ]CABINET |
CABINET NATIONAL PROTÉGÉ |
| Rechercher le sujet P NC | Modèle de correspondance de l’objet :\[SEC=PROTECTED(?:,)? CAVEAT=SH[-: ]NATIONAL[- ]CABINET |
CABINET NATIONAL PROTÉGÉ |
L’étiquetage automatique basé sur SIT est créé en suivant les conseils de vérification des règles pour les SIT.
Étiquetage des éléments existants au repos
Les stratégies d’étiquetage automatique peuvent être configurées pour analyser les éléments résidant dans les emplacements OneDrive et SharePoint (y compris les sites d’équipe sous-jacents Teams) à la recherche de marquages de protection ou d’informations sensibles. Les stratégies peuvent cibler les emplacements OneDrive individuels d’utilisateurs spécifiques, un ensemble de sites SharePoint ou l’ensemble du service.
Les stratégies peuvent être configurées pour rechercher chacune des méthodes d’identification des informations qui ont été introduites sous Identification des informations sensibles. Cela comprend :
- Les SIT prédéfinis, tels que ceux créés par Microsoft pour l’identification des informations relatives à l’Australian Privacy Act ou à l’Australian Health Records Act.
- Les SIT personnalisés qui peuvent être créés pour identifier le gouvernement ou organization des informations spécifiques, telles que les ID d’autorisation, le numéro de demande d’accès à l’information (FOI), etc.
- Exact Data Match SITs qui ont été générés en fonction des exportations réelles d’informations.
- Toute combinaison de sits prédéfinis, personnalisés et/ou exacts de correspondance de données susceptibles d’identifier avec précision des informations sensibles.
Il existe également des fonctionnalités de prédicat contextuel récemment publiées qui peuvent être configurées pour identifier les éléments en fonction de la propriété du document, de l’extension de fichier ou du nom du document. Ces prédicats sont utiles pour les organisations souhaitant prendre en compte les classifications qui ont été appliquées via des outils de classification non-Microsoft, qui appliquent généralement des propriétés de document aux éléments. Pour plus d’informations sur le prédicat contextuel, consultez découvrir comment Protection des données Microsoft Purview détecte et protège vos données les plus sensibles.
Le cas d’usage principal de ces fonctionnalités consiste à s’assurer que l’étiquette correcte est appliquée aux informations existantes. Cela garantit que :
- Les informations héritées, notamment celles chargées à partir d’emplacements locaux, sont protégées via les contrôles basés sur les étiquettes de Microsoft Purview.
- Les fichiers marqués avec des classifications historiques ou via des outils non-Microsoft ont une étiquette appliquée et sont donc protégés par des contrôles basés sur des étiquettes.
Configuration de stratégie basée sur SharePoint
Les stratégies d’étiquetage automatique basées sur SharePoint sont configurées dans le portail de conformité Microsoft Purview sous Information Protection > stratégies > d’étiquetage automatique.
Les stratégies doivent cibler les services basés sur SharePoint. Étant donné qu’une stratégie est requise pour chaque étiquette de confidentialité appliquée automatiquement, les stratégies doivent être nommées de manière appropriée. Par exemple, « SPO - label OFFICIAL Sensitive PP items. »
Les stratégies peuvent utiliser des SIT personnalisés construits pour identifier les éléments marqués. Par exemple, un sit incluant une expression de registre de la suivante identifie les marquages OFFICIELs de confidentialité personnelle sensible appliqués par les marquages visuels textuels appliqués en haut et en bas des documents ou par les marquages d’objet de courrier électronique :
OFFICIAL[:\- ]\s?Sensitive(?:\s|\/\/|\s\/\/\s|,\sACCESS=)Personal[ -]Privacy
Un ensemble complet de SIT alignés sur les marquages réutilisables du gouvernement australien a été fourni dans un exemple de syntaxe SIT pour détecter les marquages de protection.
La stratégie d’étiquetage automatique contient une règle avec des conditions de contenu contenant des types d’informations sensibles*, suivie du sit qui s’aligne sur le marquage de protection.
Une fois créée, cette stratégie s’exécute en mode simulation, ce qui permet aux administrateurs de valider la configuration avant toute application automatisée d’étiquettes.
Une fois activée, la stratégie fonctionne en arrière-plan en appliquant des étiquettes, jusqu’à 25 000 documents bureau par jour.
Exemples de stratégies d’étiquetage automatique basées sur SharePoint
Les scénarios et exemples de configurations suivants atténuent les risques liés aux informations en veillant à ce que tous les éléments se trouvent dans l’étendue des contrôles de sécurité des données appropriés.
Déploiement de l’étiquetage post-sensibilité de l’étiquetage automatique
Une fois qu’une organization a déployé l’étiquetage de confidentialité, des étiquettes de confidentialité sont appliquées à tous les documents créés à partir de ce point. Cela est dû à la configuration d’étiquetage obligatoire . Toutefois, les éléments créés avant ce stade sont menacés. Pour résoudre ce problème, les organisations peuvent déployer un ensemble de stratégies d’étiquetage automatique qui recherchent les marquages appliqués aux documents. Si un marquage qui s’aligne sur une étiquette de confidentialité est identifié, la stratégie termine cette activité d’étiquetage.
Ces exemples de stratégie d’étiquetage automatique utilisent les SIT définis dans l’exemple de syntaxe SIT pour détecter les marquages de protection. Les stratégies d’étiquetage automatique doivent inclure une condition de contenu contient,type d’informations sensibles, puis inclure le SIT aligné sur l’étiquette des stratégies :
| Nom de la stratégie | S’ASSEOIR | Étiquette de confidentialité |
|---|---|---|
| SPO - étiqueter les éléments NON OFFICIELS | REGEX SIT NON OFFICIEL | OFFICIEUX |
| SPO - étiqueter les éléments OFFICIAL | OFFICIAL Regex SIT | FONCTIONNAIRE |
| SPO : étiqueter les éléments sensibles OFFICIELs | OFFICIAL Sensitive Regex SIT | OFFICIAL Sensitive |
| SPO : étiqueter les éléments PP sensibles OFFICIELs | OFFICIAL Sensitive Personal Privacy Regex SIT | Confidentialité personnelle sensible officielle |
| SPO : étiqueter les éléments LP sensibles OFFICIAL | OFFICIAL Sensitive Legal Privilege Regex SIT | Official : Privilège juridique sensible |
| SPO : étiqueter les éléments LS sensibles OFFICIELs | OFFICIAL Sensible Secret législatif Regex SIT | SECRET LÉGISLATIF SENSIBLE OFFICIEL |
| SPO : étiqueter les éléments NC sensibles OFFICIELs | OFFICIAL SENSIBLE NATIONAL CABINET REGEX SIT | CABINET NATIONAL SENSIBLE OFFICIEL |
| SPO : étiqueter les éléments PROTÉGÉS | PROTECTED Regex SIT | PROTÉGÉ |
| SPO : étiqueter les éléments PP PROTÉGÉS | PROTECTED Personal Privacy Regex SIT | Protection de la confidentialité personnelle |
| SPO : étiqueter les éléments PROTECTED LP | PROTECTED Legal Privilege Regex SIT | PROTECTED Legal Privilege |
| SPO : étiqueter les éléments LS PROTÉGÉS | PROTECTED Secret législatif Regex SIT | PROTÉGÉ Secret législatif |
| SPO : étiqueter les éléments NC PROTÉGÉS | PROTECTED NATIONAL CABINET Regex SIT | CABINET NATIONAL PROTÉGÉ |
| SPO : étiqueter les éléments C PROTÉGÉS | PROTECTED CABINET Regex SIT | CABINET PROTÉGÉ |
Étiquetage automatique des éléments avec des classifications historiques
Comme indiqué dans les recommandations basées sur les marquages historiques, les exigences de marquage du gouvernement australien changent occasionnellement. En 2018, les exigences du PSPF ont été simplifiées, ce qui comprenait la consolidation de plusieurs marqueurs de limitation de diffusion (DML) en un seul marquage « OFFICIAL : Sensible ». L’annexe E de la Politique 8 du PSPF fournit une liste complète des classifications et des marquages historiques, ainsi que leurs exigences actuelles en matière de manipulation. Certaines de ces DLR historiques ont des marquages équivalents dans l’infrastructure actuelle. D’autres exigences en matière de gestion s’appliquent toujours. Les étiquettes peuvent être utiles pour aider les organisations à s’assurer qu’elles sont en mesure de répondre à leurs exigences de gestion.
Il existe deux approches possibles :
- Appliquez un équivalent moderne de l’étiquette historique.
- Implémentez l’étiquette d’historique de manière transparente. Incluez DLP et d’autres stratégies pour protéger les informations, mais ne publiez pas l’étiquette pour les utilisateurs.
Pour mettre en œuvre la première de ces approches, une stratégie de mappage doit être développée qui aligne les marquages historiques sur les marques actuelles par le organization. Cet alignement peut être complexe, car tous les marquages n’ont pas d’équivalent actuel et certains obligeront les organisations gouvernementales à prendre des décisions sur la question de savoir si des MPM doivent être appliquées aux éléments existants. Le tableau suivant est fourni à titre d’exemple uniquement.
| Marquage historique | Étiquette de confidentialité |
|---|---|
| Pour usage officiel uniquement (FOUO) | OFFICIAL Sensitive |
| Sensible | OFFICIAL Sensitive |
| Sensible : Juridique | Official : Privilège juridique sensible |
| Sensible : Personnel | Confidentialité personnelle sensible officielle |
| Sensible : Cabinet | CABINET PROTÉGÉ |
Une fois que les organisations ont défini un mappage, des SIT doivent être créés pour identifier les marquages historiques. Pour les marquages tels que « For Official Use Only (FOUO), cela est aussi simple que de créer un mot clé SIT incluant ce terme. Toutefois, cette approche peut ne pas convenir pour des marquages moins descriptifs tels que « Sensible », ce qui est susceptible d’entraîner de nombreux faux positifs.
Les organisations gouvernementales doivent évaluer les données héritées pour déterminer s’il existe d’autres caractéristiques qui pourraient être utilisées pour identifier plus précisément les marques historiques, telles que les exclusions de responsabilité, les propriétés de document ou d’autres marqueurs qui peuvent être présents sur les éléments historiques.
Après l’analyse des données héritées, la création de sits pour identifier les éléments marqués et le déploiement de la stratégie d’étiquetage automatique, les administrateurs peuvent exécuter une simulation pour déterminer la précision de l’application d’étiquette et le délai d’exécution attendu. L’étiquetage automatique de l’application en fichiers hérités peut alors s’exécuter en arrière-plan, supervisé par les administrateurs de l’organisation Microsoft 365.
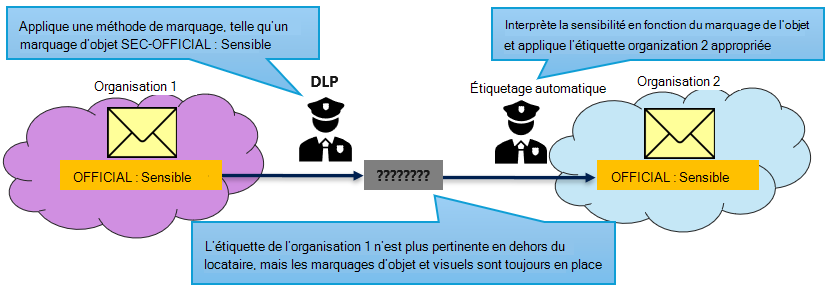
Étiquetage automatique suite au changement de machinery of Government
Les changements d’appareil gouvernemental impliquent généralement le déplacement des responsabilités et des ressources entre les organisations gouvernementales. Lorsqu’une fonction passe d’une organization à une autre, il est courant que les informations relatives à cette fonction nécessitent également une remise. Étant donné que les étiquettes de confidentialité ne sont pertinentes que dans un seul environnement Microsoft 365, lorsque des éléments sont passés à un deuxième organization, leur étiquette appliquée n’est pas reportée. Les marquages de protection s’appliquent toujours, mais les contrôles tels que les alertes DLP basées sur les étiquettes et les données hors de place sont susceptibles de glisser. Pour résoudre ce problème, les stratégies d’étiquetage automatique peuvent être exécutées sur le contenu reçu de sources externes pour garantir que les étiquettes appropriées sont appliquées en fonction des marquages de protection existants de l’élément.
La configuration pour y parvenir est la même que celle décrite dans la section Déploiement de l’étiquetage post-sensibilité de l’étiquetage automatique. La seule exception est que les stratégies sont ciblées sur les emplacements spécifiques où les éléments reçus sont stockés.