Identification des informations sensibles et classifiées de sécurité pour la conformité du gouvernement australien avec PSPF
Cet article fournit des conseils aux organisations gouvernementales australiennes sur l’utilisation de Microsoft Purview pour identifier les informations sensibles et classifiées de sécurité. Son objectif est d’aider ces organisations à renforcer leur approche de la sécurité des données et leur capacité à se conformer aux exigences décrites dans le Cadre de stratégie de sécurité de protection (PSPF) et le Manuel de sécurité des informations (ISM).
La clé de la protection des informations et de leur sécurisation contre la perte de données est d’abord de comprendre ce qu’il s’agit d’informations. Cet article explore les méthodes d’identification des informations dans un environnement Microsoft 365 d’une organisation. Ces approches sont souvent appelées les aspects de vos données de Microsoft Purview. Une fois identifiées, les informations peuvent être protégées via l’étiquetage automatique de confidentialité et la protection contre la perte de données (DLP).
Types d'informations sensibles
Les types d’informations sensibles (SIT) sont des classifieurs basés sur des modèles. Ils détectent les informations sensibles via des expressions régulières (RegEx) ou des mots clés.
Il existe de nombreux types de SIT qui sont pertinents pour les organisations gouvernementales australiennes :
- SITS prédéfini créé par Microsoft, dont plusieurs s’alignent sur les types de données australiens courants.
- Les SIT personnalisés sont créés en fonction des exigences de l’organisation.
- Les SIT d’entité nommée incluent des identificateurs complexes basés sur un dictionnaire, tels que des adresses physiques australiennes.
- Les SIT EDM (Exact Data Match) sont générés en fonction de données sensibles réelles.
- Les SIT d’empreintes digitales de document sont basés sur le format des documents plutôt que sur leur contenu.
- Les SIT pertinents pour la sécurité du réseau ou de l’information bien que techniquement prédéfinis SITs, ils ont une pertinence particulière pour les équipes cyber travaillant pour les organisations gouvernementales australiennes, et sont donc dignes de leur propre catégorie.
Types d’informations sensibles prédéfinis
Les types d’informations sensibles prédéfinis sont basés sur des types d’informations courants que les clients considèrent généralement comme sensibles. Celles-ci peuvent être génériques et avoir une pertinence globale (par exemple, des numéros de carte de crédit) ou avoir une pertinence locale (par exemple, les numéros de compte bancaire australien).
La liste complète des SIT prédéfinis de Microsoft se trouve dans les définitions d’entité de type d’informations sensibles
Les SIT spécifiques à l’Australie sont les suivants :
- Numéro de compte bancaire australien
- Numéro de permis de conduire australien
- Numéro de passeport australien
- Adresses physiques australiennes
- Numéro de fichier fiscal australien
- Numéro d’entreprise australien
- Numéro de société australienne
- Numéro de compte médical australien
Ces SIT se trouvent dans le portail de classification des données Microsoft Purview sous Classifieurs>Types d’informations sensibles.
Les SIT prédéfinis sont précieux pour les organisations qui commencent leur Information Protection ou leur parcours de gouvernance, car ils fournissent une longueur d’avance vers l’activation de fonctionnalités telles que DLP et l’étiquetage automatique. Les deux méthodes les plus simples pour utiliser ces SIT sont les suivantes :
Utilisation de sits prédéfinis via des modèles de stratégie DLP
Certains SIT prédéfinis sont inclus dans les modèles de stratégie DLP créés par Microsoft qui s’alignent sur les réglementations australiennes. Les modèles de stratégie DLP suivants qui s’alignent sur les exigences australiennes sont disponibles :
- Loi australienne sur la protection des données personnelles améliorée
- Données financières en Australie
- PCI Data Security Standard (PCI DSS)
- Australia Personally Identifiable Information (PII) Data
L’activation des stratégies DLP basées sur ces modèles permet la surveillance initiale des événements de perte de données, qui constituent un excellent point de départ pour les organisations qui introduisent Microsoft 365 DLP. Une fois déployées, ces stratégies fournissent des informations sur l’étendue d’un problème de perte de données au sein de l’organisation et peuvent aider à prendre des décisions sur les étapes suivantes.
L’utilisation de ces modèles de stratégie est explorée plus en détail pour limiter la distribution des informations sensibles.
Utilisation de SIT prédéfinis dans l’étiquetage automatique de sensibilité
Si un élément contient un numéro de compte médical australien, un ou plusieurs termes médicaux et un nom complet, il peut être juste de supposer qu’il contient des informations médicales d’identification personnelle et qu’il pourrait constituer un dossier médical. Sur la base de cette hypothèse, nous pouvons suggérer à un utilisateur que l’article soit étiqueté « OFFICIAL : Confidentialité personnelle sensible », ou l’étiquette la plus appropriée dans votre organization pour l’identification et la protection des dossiers médicaux.
Pour plus d’informations sur les cas où cette fonctionnalité peut aider les organisations gouvernementales à respecter la conformité PSPF, consultez Application automatique des étiquettes de confidentialité et scénarios d’étiquetage automatique basés sur le client pour le gouvernement australien.
Types d’informations sensibles personnalisés
En plus des SIT prédéfinis, les organisations peuvent créer des SIT en fonction de leurs propres définitions d’informations sensibles. Voici quelques exemples d’informations pertinentes pour les organisations gouvernementales australiennes qui peuvent être identifiées par le biais d’un sit personnalisé :
- Marquages de protection
- ID d’autorisation ou ID d’application d’autorisation
- Classifications d’autres États ou territoires
- Classifications qui ne doivent pas apparaître sur la plateforme (par exemple, TOP SECRET)
- Réunions d’information ou correspondance des ministres
- Numéro de demande d’accès à l’information (FOI)
- Informations relatives à la probité
- Termes relatifs aux systèmes, projets ou applications sensibles
- Marquages de paragraphes
- Numéros d’enregistrement Trim ou Objective
Les SIT personnalisés sont constitués d’un identificateur principal, qui peut être basé sur une expression régulière ou des mots clés, un niveau de confiance et des éléments de prise en charge facultatifs.
Pour obtenir une explication plus détaillée des SIT et de leurs composants, consultez En savoir plus sur les types d’informations sensibles.
Expressions régulières (RegEx)
Les expressions régulières sont des identificateurs basés sur du code qui peuvent être utilisés pour identifier des modèles d’informations. Par exemple, si un numéro d’accès à l’information (FOI) est composé des lettres FOI suivies d’une année à quatre chiffres, d’un trait d’union et de trois autres chiffres (par exemple, FOI2023-123), il peut être représenté dans une expression régulière de :
[Ff][Oo][Ii]20[01234]\d{1}-\d{3}
Pour expliquer cette expression :
-
[Ff][Oo][Ii]correspond aux lettres majuscules ou minuscules F, O et I. -
20correspond au nombre 20 comme premier semestre de l’année à quatre chiffres. -
[0123]correspond à 0, 1, 2 ou 3 dans le troisième chiffre de notre valeur d’année à quatre chiffres, ce qui nous permet de faire correspondre les numéros foi de l’année 2000 à 2039. -
-correspond à un trait d’union. -
\d{3}correspond à trois chiffres.
Conseil
Copilot est très habile à générer des expressions régulières (RegEx). Vous pouvez utiliser le langage naturel pour demander à Copilot de générer regEx pour vous.
Liste de mots clés ou dictionnaire mot clé
Les listes de mots clés et les dictionnaires se composent de mots, de termes ou d’expressions susceptibles d’être inclus dans les éléments que vous cherchez à identifier. séance d’information du cabinet ou demande d’appel d’offres sont des termes qui pourraient être utiles comme mots clés.
Les mots clés peuvent être sensibles à la casse ou insensibles. La casse peut être utile pour éliminer les faux positifs. Par exemple, la minuscule official est plus susceptible d’être utilisée dans une conversation générale, mais les majuscules OFFICIAL ont une probabilité plus élevée de faire partie d’un marquage de protection.
Les dictionnaires de mots clés contenant des jeux de données volumineux peuvent également être chargés au format CSV ou TXT . Pour plus d’informations sur le chargement d’un dictionnaire mot clé, consultez Création d’un dictionnaire mot clé.
Niveau de confiance
Certains mots clés ou expressions régulières peuvent fournir une correspondance précise sans besoin d’affinement. L’expression liberté de l’information (FOI) incluse dans l’exemple précédent d’une valeur est peu susceptible d’apparaître dans une conversation générale et, lorsqu’elle apparaît dans la correspondance, est susceptible de correspondre à des informations pertinentes. Toutefois, si nous essayions de faire correspondre un numéro d’employé de la fonction publique australienne, qui est représenté sous la forme de huit chiffres numériques, notre correspondance est susceptible d’entraîner de nombreux faux positifs. Le niveau de confiance nous permet d’attribuer une probabilité que la présence de l’mot clé ou d’un modèle dans un élément tel qu’un e-mail ou un document, soit réellement ce que nous recherchons. Pour plus d’informations sur les niveaux de confiance, consultez Gestion des niveaux de confiance.
Éléments principaux et de prise en charge
Les SIT personnalisés ont également un concept d’éléments principaux et d’éléments de prise en charge. L’élément principal est le modèle clé que nous voulons détecter dans le contenu. Les éléments de prise en charge peuvent être ajoutés à un réplica principal pour générer un cas d’occurrence d’une valeur étant une correspondance précise. Par exemple, si vous essayez d’effectuer une correspondance sur la base d’un numéro d’employé à huit chiffres, nous pouvons utiliser des mots clés « numéro d’employé » ou « numéro AGSdu gouvernement australien » ou base de données APSED des employés de la fonction publique australienne comme élément de soutien pour accroître la confiance que la correspondance est pertinente. Pour plus d’informations sur la création d’éléments principaux et de prise en charge, consultez Présentation des éléments.
Proximité des caractères
La valeur finale que nous configurons généralement dans un SIT est la proximité des caractères. Il s’agit de la distance entre les éléments principaux et les éléments de support. Si nous prévoyons que le mot clé AGS soit proche de notre valeur numérique à huit chiffres, nous configurons une proximité de 10 caractères. Si les éléments principal et secondaire ne sont pas susceptibles d’apparaître les uns à côté des autres, nous définissons la valeur de proximité sur un plus grand nombre de caractères. Pour plus d’informations sur la création d’une proximité de caractères, consultez Comprendre la proximité.
SITs pour identifier les marquages de protection
Un moyen précieux pour les organisations gouvernementales australiennes d’utiliser des SIT personnalisés consiste à identifier les marquages de protection. Dans un organization Greenfield, une étiquette de confidentialité est appliquée à tous les éléments d’un environnement. Toutefois, la plupart des organisations gouvernementales disposent d’un étiquetage hérité nécessitant une modernisation de Microsoft Purview. Les SIT sont utilisés pour identifier et appliquer des marquages à :
- Fichiers hérités marqués
- Fichiers marqués générés par des entités externes
- Email conversations lancées et marquées en externe
- E-mails qui ont perdu leurs informations d’étiquette (x-headers)
- E-mails dont les étiquettes ont été incorrectement déclassées
Lorsqu’un tel marqueur est identifié, l’utilisateur est informé de la détection et une recommandation d’étiquette lui est fournie. S’ils acceptent la recommandation, les protections basées sur les étiquettes s’appliquent à l’élément. Ces concepts sont abordés plus en détail dans scénarios d’étiquetage automatique basés sur le client pour le gouvernement australien.
Les SIT basés sur la classification sont également utiles en DLP. Les exemples incluent :
- Un utilisateur reçoit des informations et les identifie comme sensibles par le biais de son marquage, mais ne souhaite pas les reclasser, car elles ne se traduisent pas en classification PSPF (par exemple, « OFFICIAL Sensitive NSW Government »). La construction d’une stratégie DLP pour protéger les informations jointes en fonction du marquage plutôt que de l’étiquette appliquée signifie que nous pouvons y appliquer une mesure de sécurité des données.
- Un utilisateur copie le texte d’une conversation par e-mail, qui inclut un marquage de protection. Ils collent les informations dans une conversation Teams avec un participant externe qui ne doit pas avoir accès aux informations. Via une stratégie DLP s’appliquant au service Teams, le marquage peut être détecté et la divulgation peut être évitée.
- Un utilisateur rétrograde incorrectement une étiquette de confidentialité sur une conversation par e-mail (par erreur ou par erreur de l’utilisateur). Comme les marquages de protection appliqués à l’e-mail précédemment sont visibles dans le corps de l’e-mail, Microsoft Purview détecte que les marquages actuels et précédents sont mal alignés. Selon la configuration, l’action journalise l’événement, avertit l’utilisateur ou bloque l’e-mail.
- Un e-mail marqué est envoyé à un destinataire externe qui utilise une plateforme ou un client de messagerie non entreprise. La plateforme ou le client supprime les métadonnées de l’e-mail (x-headers), ce qui empêche l’e-mail de réponse du destinataire externe d’avoir une étiquette de confidentialité appliquée lorsqu’il arrive à la boîte aux lettres utilisateur de l’organization. La détection du marquage précédent via un sit permet de réappliquer l’étiquette en toute transparence ou de recommander à l’utilisateur de réappliquer l’étiquette à sa réponse suivante.
Dans chacun de ces scénarios, les SIT basés sur la classification peuvent être utilisés pour détecter les marquages de protection appliqués et atténuer la violation potentielle des données.
Exemple de syntaxe SIT pour détecter les marquages de protection
Les expressions régulières suivantes peuvent être utilisées dans les SIT personnalisés pour identifier les marquages de protection.
Importante
La création de sits pour identifier les marquages de protection aide à la conformité pspf. Les SIT basés sur la classification sont également utilisés dans les scénarios DLP et d’étiquetage automatique.
| Nom SIT | Expression régulière |
|---|---|
| Expression régulièrenon officielle 1 | UNOFFICIAL |
| EXPRESSION RÉGULIÈRE OFFICIELLE1,2 | (?<!UN)OFFICIAL |
| EXPRESSION RÉGULIÈRE SENSIBLE OFFICIELLE1,3,4,5 | OFFICIAL[:- ]\s?Sensitive(?!(?:\s\|\/\/\|\s\/\/\s)[Pp]ersonal[- ][Pp]rivacy)(?!(?:\s\|\/\/\|\s\/\/\s)[Ll]egislative[- ][Ss]ecrecy)(?!(?:\s\|\/\/\|\s\/\/\s)[Ll]egal[- ][Pp]rivilege)(?!(?:\s\|\/\/\|\s\/\/\s)NATIONAL[ -]CABINET) |
| OFFICIAL Sensitive Personal Privacy Regex1,4,5 | OFFICIAL[:- ]\s?Sensitive(?:\s\|\/\/\|\s\/\/\s\|,\sACCESS=)Personal[ -]Privacy |
| OFFICIAL Sensitive Legal Privilege Regex1,4,5 | OFFICIAL[:- ]\s?Sensitive(?:\s\|\/\/\|\s\/\/\s\|,\sACCESS=)Legal[ -]Privilege |
| OFFICIAL Sensible Secret législatif Regex1,4,5 | OFFICIAL[:- ]\s?Sensitive(?:\s\|\/\/\|\s\/\/\s\|,\sACCESS=)Legislative[ -]Secrecy |
| REGEX OFFICIEL CABINET NATIONAL SENSIBLE1,4,5 | OFFICIAL[:- ]\s?Sensitive(?:\s\|\/\/\|\s\/\/\s\|,\sCAVEAT=SH:)NATIONAL[ -]CABINET |
| Expression régulière PROTÉGÉE1,3,5 | PROTECTED(?!,\sACCESS=)(?!(?:\s\|\/\/\|\s\/\/\s)[Pp]ersonal[- ][Pp]rivacy)(?!(?:\s\|\/\/\|\s\/\/\s)[Ll]egislative[- ][Ss]ecrecy)(?!(?:\s\|\/\/\|\s\/\/\s)[Ll]egal[- ][Pp]rivilege)(?!(?:\s\|\/\/\|\s\/\/\s)NATIONAL[ -]CABINET)(?!(?:\s\|\/\/\|\s\/\/\s)CABINET) |
| PROTECTED Personal Privacy Regex1,5 | PROTECTED(?:\s\|\/\/\|\s\/\/\s\|,\sACCESS=)Personal[ -]Privacy |
| Protected Legal Privilege Regex1,5 | PROTECTED(?:\s\|\/\/\|\s\/\/\s\|,\sACCESS=)Legal[ -]Privilege |
| PROTECTED Secret législatif Regex1,5 | PROTECTED(?:\s\|\/\/\|\s\/\/\s\|,\sACCESS=)Legislative[ -]Secrecy |
| PROTECTED NATIONAL CABINET REGEX1,5 | PROTECTED(?:\s\|\/\/\|\s\/\/\s\|,\sCAVEAT=SH:)NATIONAL[ -]CABINET |
| PROTECTED CABINET Regex1,5 | PROTECTED(?:\s\|\/\/\|\s\/\/\s\|,\sCAVEAT=SH:)CABINET |
Lors de l’évaluation des exemples SIT précédents, notez la logique d’expression suivante :
- 1 Ces expressions correspondent aux marquages appliqués aux deux documents (par exemple, OFFICIAL : Sensitive NATIONAL CABINET) et aux e-mails (par exemple, '[SEC=OFFICIAL :Sensitive, CAVEAT=NATIONAL-CABINET]').
-
2 L’apparence négative dans OFFICIAL Regex (
(?<!UN)) empêche les éléments non officiels d’être mis en correspondance avec official. -
3L’expression regex sensible officielle et l’expression régulière PROTÉGÉE utilisent des têtes de regard négatives (
(?!)) pour s’assurer qu’un marqueur imm (Information Management Markers) ou une mise en garde n’est pas appliqué après la classification de sécurité. Cela permet d’éviter que les éléments avec des mims ou des mises en garde soient identifiés comme étant la version non-IMM ou mise en garde de la classification. -
4 L’utilisation de
[:\- ]dans OFFICIAL : Sensitive est destinée à permettre une flexibilité dans le format de ce marquage et est importante en raison de l’utilisation des deux-points dans les en-têtes x. -
5
(?:\s\|\/\/\|\s\/\/\s)est utilisé pour identifier l’espace entre les composants de marquage et permet un espace simple, un espace double, une double barre oblique ou une double barre oblique avec des espaces. Ceci est destiné à permettre les différentes interprétations du format de marquage PSPF qui existe entre les organisations gouvernementales australiennes.
Types d’informations sensibles d’entité nommée
Les SIT d’entité nommée sont des identificateurs basés sur des dictionnaires et des modèles complexes créés par Microsoft, qui peuvent être utilisés pour détecter des informations telles que :
- noms de Personnes
- Adresses physiques
- Conditions médicales
Les SIT d’entité nommée peuvent être utilisés de manière isolée, mais ils peuvent également être utiles en tant qu’éléments de support. Par exemple, un terme médical existant dans un e-mail peut ne pas être utile comme indication que l’élément contient des informations sensibles. Toutefois, un terme médical associé à une valeur susceptible d’indiquer un numéro de client ou de patient, ainsi qu’un prénom et un nom de famille, fournirait une indication forte que l’élément est sensible.
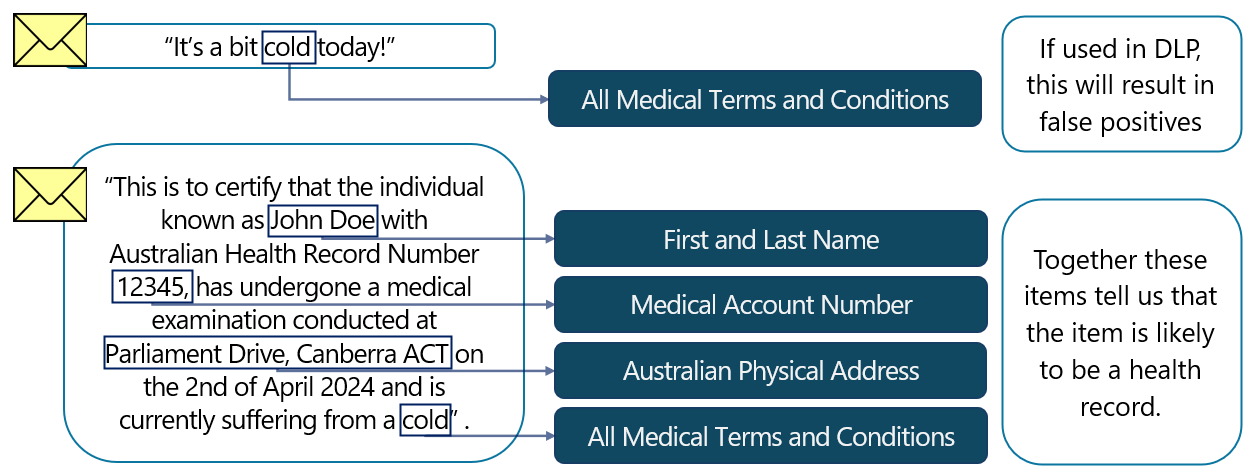
Les SIT d’entité nommée peuvent être associés à des SIT personnalisés, utilisés comme éléments de prise en charge ou même inclus avec d’autres SIT dans les stratégies DLP.
Pour plus d’informations sur les SIT d’entités nommées, consultez en savoir plus sur les entités nommées.
Correspondance exacte des données avec les types d’informations sensibles
Les SIT EDM (Exact Data Match) sont générés en fonction des données réelles. Les valeurs numériques, telles que les ID de client numériques, sont difficiles à faire correspondre via des SIT standard en raison de conflits avec d’autres valeurs numériques telles que les numéros de téléphone. Les éléments de prise en charge améliorent la correspondance afin de réduire les faux positifs.
Exact Data Match aide les organisations gouvernementales australiennes qui disposent de systèmes, qui contiennent des données relatives aux employés, aux clients ou aux citoyens, à identifier avec précision ces informations.
Pour plus d’informations sur l’implémentation des SIT EDM, consultez En savoir plus sur les types d’informations sensibles basés sur la correspondance exacte des données.
Création d’une empreinte numérique de document
L’empreinte digitale de document est une technique d’identification des informations qui, au lieu de rechercher des valeurs contenues dans un élément, examine plutôt le format et la structure de l’élément. Essentiellement, cela nous permet de convertir un formulaire standard en un type d’informations sensibles qui peut être utilisé pour identifier des informations.
Les organisations gouvernementales peuvent utiliser la méthode d’identification des empreintes digitales des documents pour identifier les éléments qui ont été générés via un flux de travail ou des formulaires soumis par d’autres organisations ou des membres du public.
Pour plus d’informations sur l’implémentation de l’empreinte digitale des documents, consultez Empreintes digitales de document.
Types d’informations sensibles liées au réseau ou à la sécurité
Il existe de nombreuses utilisations pour les SIT au-delà de l’identification des informations classifiées de sécurité ou autrement sensibles. L’une de ces utilisations est la détection des informations d’identification. Les SIT prédéfinis sont fournis pour les types d’informations d’identification suivants :
- Informations d’identification de connexion de l’utilisateur
- Microsoft Entra ID jetons d’accès client
- Azure Batch clés d’accès partagé
- Signatures d’accès partagé au compte stockage Azure
- Clé secrète client/clés API
Ces SIT prédéfinis sont utilisés indépendamment et sont également regroupés dans un sit appelé Toutes les informations d’identification. Le SIT de toutes les informations d’identification est utile pour les équipes cyber qui l’utilisent dans :
- Stratégies DLP pour identifier et empêcher les mouvements latéraux par des utilisateurs malveillants ou des attaquants externes.
- Stratégies d’étiquetage automatique pour appliquer le chiffrement aux éléments qui ne doivent pas contenir d’informations d’identification, verrouiller les utilisateurs des fichiers et autoriser les actions de correction à commencer.
- Stratégies DLP pour empêcher les utilisateurs de partager leurs informations d’identification avec d’autres utilisateurs par rapport aux stratégies organization.
- Pour mettre en surbrillance les éléments stockés dans des emplacements SharePoint ou Exchange, qui conservent de manière inappropriée les informations d’identification.
Des SIT prédéfinis existent également pour les adresses réseau (IPv4 et IPv6) et sont utiles pour sécuriser les éléments contenant des informations réseau ou empêcher les utilisateurs de partager des adresses IP par e-mail, conversation Teams ou messages de canal.
Classifieurs entraînables
Les classifieurs pouvant être entraînés sont des modèles Machine Learning qui peuvent être entraînés pour reconnaître des informations sensibles. Comme avec les SIT, Microsoft fournit des classifieurs préentraînés. Un extrait de classifieurs préentraînés qui sont pertinents pour les organisations gouvernementales australiennes est répertorié dans le tableau suivant :
| Catégorie de classifieur | Exemples de classifieurs pouvant être formés |
|---|---|
| Financier | Relevés bancaires, budget, rapports d’audit financier, états financiers, impôts, état des comptes, estimations budgétaires (BE), état des activités commerciales (BAS). |
| Professionnel | Procédures opérationnelles, accords de non-divulgation, approvisionnement, mots de code de projet, Budget des dépenses du Sénat (SE), Questions sur avis (QoN). |
| Ressources humaines | CV, dossiers de mesures disciplinaires des employés, contrat de travail, autorisations de l’Australian Government Security Vetting Agency (AGSVA), Programme de prêts pour l’enseignement supérieur (HELP), carte d’identité militaire, autorisation de travail étranger (FWA). |
| Médical | Soins de santé, formulaires médicaux, Dossier MyHealth. |
| Informations juridiques | Affaires juridiques, contrats, contrats de licence. |
| Technique | Fichiers de développement logiciel, documents de projet, fichiers de conception réseau. |
| Comportemental | langage offensant, blasphèmes, menace, harcèlement ciblé, discrimination, collusion réglementaire, plainte des clients. |
Voici quelques exemples de la façon dont les organisations gouvernementales peuvent utiliser ces classifieurs prédéfinis :
- Les règles d’entreprise peuvent imposer que certains éléments de la catégorie RH, tels que les CV, doivent être marqués comme « OFFICIEL : Confidentialité personnelle sensible » car ils contiennent des informations personnelles sensibles. Pour ces éléments, une recommandation d’étiquette peut être configurée via l’étiquetage automatique basé sur le client.
- Les fichiers de conception de réseau, en particulier pour les réseaux sécurisés, doivent être traités avec soin pour éviter toute compromission. Celles-ci peuvent être dignes d’une étiquette PROTÉGÉE ou, au moins, de stratégies DLP empêchant la divulgation non autorisée à des utilisateurs non autorisés.
- Les classifieurs comportementaux sont intéressants et bien qu’ils n’aient pas de corrélation directe avec les marquages de protection ou les exigences DLP, ils peuvent toujours avoir une valeur métier élevée. Par exemple, les équipes rh peuvent être informées des incidents de harcèlement et/ou être en mesure d’effectuer un filtre de correspondance marquée par le biais de la conformité des communications.
Les organisations peuvent également entraîner leurs propres classifieurs. Les classifieurs peuvent être formés en leur fournissant des ensembles d’échantillons positifs et négatifs. Le classifieur traite les exemples et génère un modèle de prédiction. Une fois la formation terminée, les classifieurs peuvent être utilisés pour l’application d’étiquettes de confidentialité, de stratégies de conformité des communications et de stratégies d’étiquetage de rétention. L’utilisation de classifieurs dans les stratégies DLP est disponible en préversion.
Pour plus d’informations sur les classifieurs pouvant être entraînés, consultez en savoir plus sur les classifieurs pouvant être entraînés.
Utilisation d’informations sensibles identifiées
Une fois que les informations sont identifiées via SIT ou classifieur (par le biais des aspects relatifs à vos données de Microsoft Purview), nous pouvons utiliser ces connaissances pour nous aider à mener à bien les trois autres piliers de la gestion des informations Microsoft 365, à savoir :
- Protéger vos données,
- Empêcher la perte de données, et
- Gouverner vos données.
Le tableau suivant fournit des avantages et des exemples de la façon dont la connaissance d’un élément contenant des informations sensibles peut aider à gérer les informations sur la plateforme Microsoft 365 :
| Fonctionnalité | Exemple d’utilisation |
|---|---|
| Protection contre la perte de données | Facilite la gestion en réduisant les risques de déversement de données. |
| Étiquetage de confidentialité | Recommande d’appliquer l’étiquette de confidentialité appropriée. Une fois étiquetées, les protections liées aux étiquettes s’appliquent aux informations. |
| Étiquetage de rétention | Applique automatiquement une étiquette de rétention, ce qui permet de répondre aux exigences en matière d’archivage ou de gestion des enregistrements. |
| Explorer de contenu | Affichez l’emplacement où se trouvent les éléments contenant des informations sensibles dans les services Microsoft 365, notamment SharePoint, Teams, OneDrive et Exchange. |
| Gestion des risques internes | Surveillez l’activité des utilisateurs autour des informations sensibles, établissez un niveau de risque utilisateur en fonction du comportement et transmettez les comportements suspects aux équipes concernées. |
| Conformité des communications | Filtrez la correspondance à haut risque, y compris toute conversation ou tout e-mail contenant du contenu sensible ou suspect. La conformité des communications peut aider à s’assurer que les obligations de probité sont respectées par le gouvernement australien. |
| Microsoft Priva | Détectez le stockage d’informations sensibles, y compris les données personnelles dans des emplacements tels que OneDrive, et guidez les utilisateurs sur le stockage correct des informations. |
| eDiscovery | Surfacez les informations sensibles dans le cadre des processus RH ou FOI et appliquez des conservations aux informations qui pourraient faire partie d’une demande ou d’une enquête active. |
Explorer de contenu
L’Explorateur de contenu Microsoft 365 permet à vos responsables de la conformité, de la sécurité et de la confidentialité d’obtenir un aperçu rapide mais complet de l’emplacement des informations sensibles dans un environnement Microsoft 365. Cet outil permet aux utilisateurs autorisés de parcourir les emplacements et les éléments par type d’informations. Le service indexe et expose les éléments résidant dans Exchange, OneDrive et SharePoint. Les éléments situés dans les sites d’équipe SharePoint sous-jacents Teams sont également visibles.
Grâce à cet outil, nous pouvons sélectionner un type d’informations sensibles ou une étiquette de confidentialité, afficher le nombre d’éléments qui s’alignent sur chacun des services Microsoft 365 :
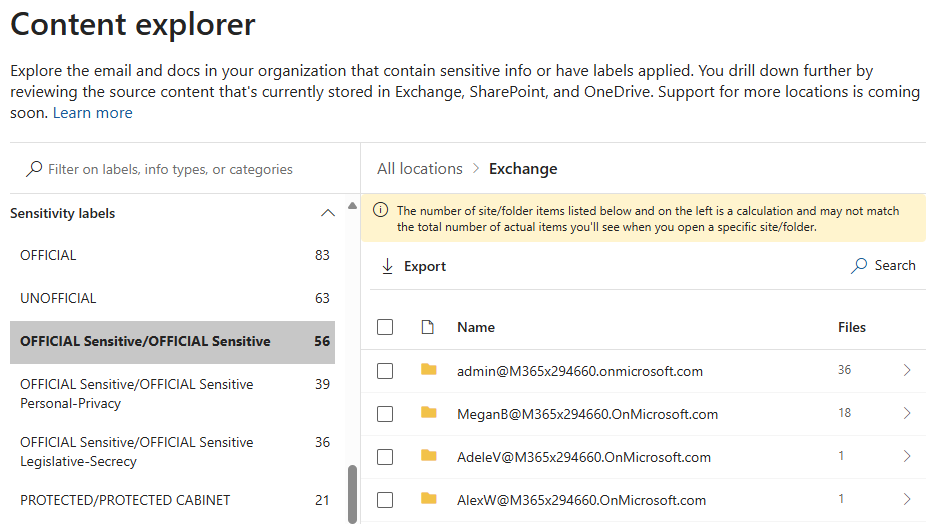
L’Explorateur de contenu peut fournir des informations précieuses sur les emplacements où se trouvent des éléments de sécurité classifiés ou sensibles dans un environnement. Il est peu probable qu’une telle vue consolidée de l’emplacement des informations soit possible via des systèmes locaux.
Pour les organisations qui incluent des étiquettes qui ne sont pas autorisées dans le compte de l’organization (par exemple, SECRET ou TOP SECRET) ainsi que des stratégies d’étiquetage automatique associées pour appliquer les étiquettes, l’Explorateur de contenu peut trouver des informations qui ne doivent pas être stockées sur la plateforme. Comme l’Explorateur de contenu peut également exposer des SIT, une approche similaire peut être obtenue via des SIT pour identifier les marquages de protection.
Pour plus d’informations sur content Explorer, consultez Prise en main de l’Explorateur de contenu.