Selvstudium: Find relationer i en semantisk model ved hjælp af semantisk link
I dette selvstudium illustreres det, hvordan du interagerer med Power BI fra en Jupyter-notesbog og registrerer relationer mellem tabeller ved hjælp af SemPy-biblioteket.
I dette selvstudium lærer du, hvordan du:
- Find relationer i en semantisk model (Power BI-datasæt) ved hjælp af Python-biblioteket for semantiske links (SemPy).
- Brug komponenter i SemPy, der understøtter integration med Power BI, og som hjælper med at automatisere analyse af datakvalitet. Disse komponenter omfatter:
- FabricDataFrame – en pandaslignende struktur, der er forbedret med yderligere semantiske oplysninger.
- Funktioner til at trække semantiske modeller fra et Fabric-arbejdsområde ind i din notesbog.
- Funktioner, der automatiserer evalueringen af hypoteser om funktionelle afhængigheder, og som identificerer overtrædelser af relationer i dine semantiske modeller.
Forudsætninger
Få et Microsoft Fabric-abonnement. Du kan også tilmelde dig en gratis Microsoft Fabric-prøveversion.
Log på Microsoft Fabric.
Brug oplevelsesskifteren nederst til venstre på startsiden til at skifte til Fabric.

Vælg arbejdsområder i navigationsruden til venstre for at finde og vælge dit arbejdsområde. Dette arbejdsområde bliver dit aktuelle arbejdsområde.
Download Customer Profitability Sample.pbix- og Eksempel på kunderentabilitet (auto).pbix semantiske modeller fra GitHub-lageret med stofeksempler og upload dem til dit arbejdsområde.
Følg med i notesbogen
Notesbogen powerbi_relationships_tutorial.ipynb følger med dette selvstudium.
Hvis du vil åbne den medfølgende notesbog til dette selvstudium, skal du følge vejledningen i Forbered dit system til selvstudier om datavidenskab importere notesbogen til dit arbejdsområde.
Hvis du hellere vil kopiere og indsætte koden fra denne side, kan du oprette en ny notesbog.
Sørg for at vedhæfte et lakehouse til notesbogen, før du begynder at køre kode.
Konfigurer notesbogen
I dette afsnit skal du konfigurere et notesbogmiljø med de nødvendige moduler og data.
Installér
SemPyfra PyPI ved hjælp af funktionen%pipindbygget installation i notesbogen:%pip install semantic-linkUdfør den nødvendige import af SemPy-moduler, som du skal bruge senere:
import sempy.fabric as fabric from sempy.relationships import plot_relationship_metadata from sempy.relationships import find_relationships from sempy.fabric import list_relationship_violationsImportér pandas for at gennemtvinge en konfigurationsindstilling, der hjælper med outputformatering:
import pandas as pd pd.set_option('display.max_colwidth', None)
Udforsk semantiske modeller
I dette selvstudium bruges en semantisk standardmodel Customer Profitability Sample.pbix. Du kan få en beskrivelse af den semantiske model under eksempel på kunderentabilitet for Power BI.
Brug SemPys
list_datasetsfunktion til at udforske semantiske modeller i dit aktuelle arbejdsområde:fabric.list_datasets()
I resten af denne notesbog bruger du to versioner af semantikmodellen Customer Profitability Sample:
- eksempel på kunderentabilitet: den semantiske model, som den kommer fra Power BI-eksempler med foruddefinerede tabelrelationer
- eksempel på kunderentabilitet (automatisk): de samme data, men relationer er begrænset til dem, som Power BI automatisk ville registrere.
Udtræk en semantisk eksempelmodel med dens foruddefinerede semantiske model
Indlæs relationer, der er foruddefineret og gemt i Eksempel på kunderentabilitet semantisk model, ved hjælp af SemPy's
list_relationshipsfunktion. Denne funktion viser en liste fra tabelobjektmodellen:dataset = "Customer Profitability Sample" relationships = fabric.list_relationships(dataset) relationshipsVisualiser
relationshipsDataFrame som en graf ved hjælp af SemPysplot_relationship_metadatafunktion:plot_relationship_metadata(relationships)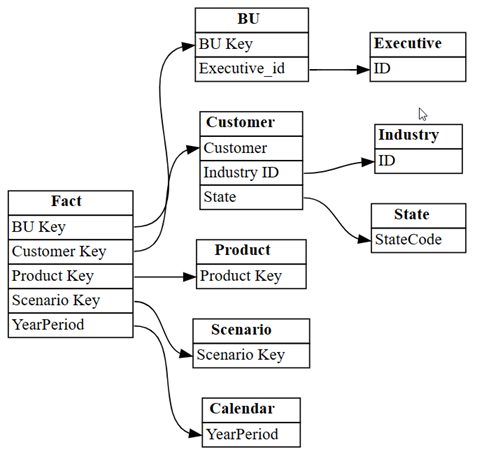

Denne graf viser "sandheden" for relationer mellem tabeller i denne semantiske model, da den afspejler, hvordan de blev defineret i Power BI af en emneekspert.
Registrering af komplementrelationer
Hvis du startede med relationer, som Power BI automatisk har registreret, har du et mindre sæt.
Visualiser de relationer, som Power BI automatisk har registreret i den semantiske model:
dataset = "Customer Profitability Sample (auto)" autodetected = fabric.list_relationships(dataset) plot_relationship_metadata(autodetected)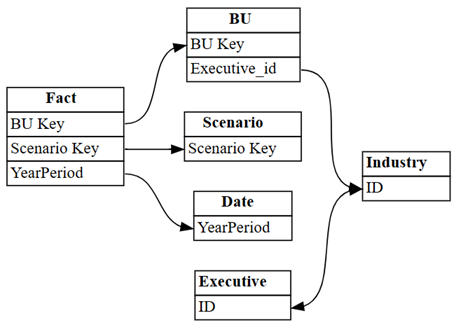
Power BI's automatiske registrering mistede mange relationer. Desuden er to af de automatisk valgte relationer semantisk forkerte:
-
Executive[ID]->Industry[ID] -
BU[Executive_id]->Industry[ID]
-
Udskriv relationerne som en tabel:
autodetectedDer vises forkerte relationer til tabellen
Industryi rækker med indeks 3 og 4. Brug disse oplysninger til at fjerne disse rækker.Fjern de forkert identificerede relationer.
autodetected.drop(index=[3,4], inplace=True) autodetectedNu har du korrekte, men ufuldstændige relationer.
Visualiser disse ufuldstændige relationer ved hjælp af
plot_relationship_metadata:plot_relationship_metadata(autodetected)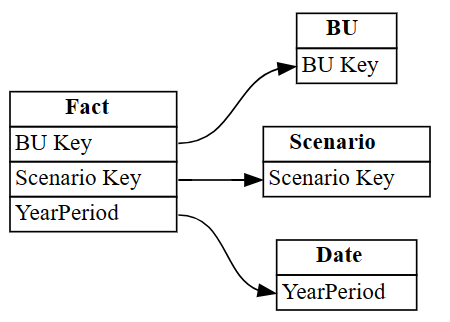
Indlæs alle tabellerne fra den semantiske model ved hjælp af SemPys
list_tablesogread_tablefunktioner:tables = {table: fabric.read_table(dataset, table) for table in fabric.list_tables(dataset)['Name']} tables.keys()Find relationer mellem tabeller ved hjælp af
find_relationships, og gennemse logoutputtet for at få indsigt i, hvordan denne funktion fungerer:suggested_relationships_all = find_relationships( tables, name_similarity_threshold=0.7, coverage_threshold=0.7, verbose=2 )Visualiser nyligt fundne relationer:
plot_relationship_metadata(suggested_relationships_all)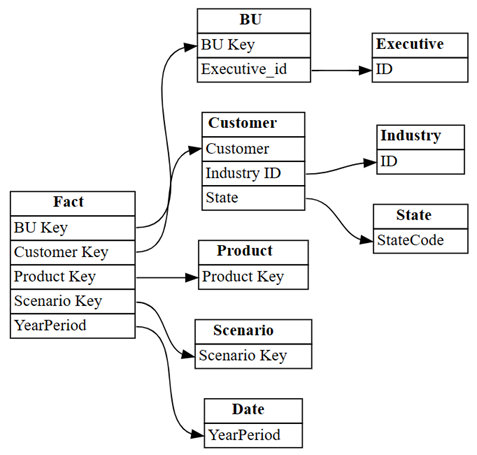
SemPy kunne registrere alle relationer.
Brug parameteren
excludetil at begrænse søgningen til yderligere relationer, der ikke tidligere blev identificeret:additional_relationships = find_relationships( tables, exclude=autodetected, name_similarity_threshold=0.7, coverage_threshold=0.7 ) additional_relationships



Valider relationerne
Først skal du indlæse dataene fra Eksempel på kunderentabilitet semantisk model:
dataset = "Customer Profitability Sample" tables = {table: fabric.read_table(dataset, table) for table in fabric.list_tables(dataset)['Name']} tables.keys()Kontrollér, om der er overlapning mellem primære og fremmede nøgleværdier ved hjælp af funktionen
list_relationship_violations. Angiv outputtet for denlist_relationshipsfunktion som input tillist_relationship_violations:list_relationship_violations(tables, fabric.list_relationships(dataset))Relationsovertrædelserne giver nogle interessante indsigter. En ud af syv værdier i
Fact[Product Key]findes f.eks. ikke iProduct[Product Key], og denne manglende nøgle er50.
Udforskning af dataanalyser er en spændende proces, og det samme er datarensning. Der er altid noget, som dataene skjuler, afhængigt af hvordan du ser på dem, hvad du vil spørge om osv. Semantisk link giver dig nye værktøjer, som du kan bruge til at opnå mere med dine data.
Relateret indhold
Tjek andre selvstudier for semantisk link / SemPy:
- selvstudium: Ryd op i data med funktionelle afhængigheder
- selvstudium: Analysér funktionelle afhængigheder i en semantisk eksempelmodel
- selvstudium: Udtræk og beregn Power BI-målinger fra en Jupyter-notesbog
- selvstudium: Find relationer i datasættet Synthea ved hjælp af semantisk link
- selvstudium: Valider data ved hjælp af GX- (SemPy and Great Expectations)