Selvstudium: Analysér funktionelle afhængigheder i en semantisk model
I dette selvstudium bygger du videre på tidligere arbejde udført af en Power BI-analytiker og gemt i form af semantiske modeller (Power BI-datasæt). Ved hjælp af SemPy (prøveversion) i Synapse Data Science-oplevelsen i Microsoft Fabric analyserer du funktionelle afhængigheder, der findes i kolonner i en DataFrame. Denne analyse hjælper med at finde problemer med kvaliteten af ikke-banale data for at få mere nøjagtig indsigt.
I dette selvstudium lærer du, hvordan du:
- Anvend domænekendskab for at formulere hypoteser om funktionelle afhængigheder i en semantisk model.
- Bliv fortrolig med komponenterne i Python-biblioteket for semantiske links (SemPy), der understøtter integration med Power BI og hjælper med at automatisere analyse af datakvalitet. Disse komponenter omfatter:
- FabricDataFrame – en pandaslignende struktur, der er forbedret med yderligere semantiske oplysninger.
- Nyttige funktioner til at trække semantiske modeller fra et Fabric-arbejdsområde ind i din notesbog.
- Nyttige funktioner, der automatiserer evalueringen af hypoteser om funktionelle afhængigheder, og som identificerer overtrædelser af relationer i dine semantiske modeller.
Forudsætninger
Få et Microsoft Fabric-abonnement. Du kan også tilmelde dig en gratis Microsoft Fabric-prøveversion.
Log på Microsoft Fabric.
Brug oplevelsesskifteren nederst til venstre på startsiden til at skifte til Fabric.

Vælg arbejdsområder i navigationsruden til venstre for at finde og vælge dit arbejdsområde. Dette arbejdsområde bliver dit aktuelle arbejdsområde.
Download Customer Profitability Sample.pbix semantiske model fra GitHub-lageret med stofeksempler.
I dit arbejdsområde skal du vælge Importér>rapport eller Sideinddelt rapport>Fra denne computer for at uploade filen Eksempel på kunderentabilitet.pbix- til dit arbejdsområde.
Følg med i notesbogen
Notesbogen powerbi_dependencies_tutorial.ipynb følger med dette selvstudium.
Hvis du vil åbne den medfølgende notesbog til dette selvstudium, skal du følge vejledningen i Forbered dit system til selvstudier om datavidenskab importere notesbogen til dit arbejdsområde.
Hvis du hellere vil kopiere og indsætte koden fra denne side, kan du oprette en ny notesbog.
Sørg for at vedhæfte et lakehouse til notesbogen, før du begynder at køre kode.
Konfigurer notesbogen
I dette afsnit skal du konfigurere et notesbogmiljø med de nødvendige moduler og data.
Installér
SemPyfra PyPI ved hjælp af funktionen%pipindbygget installation i notesbogen:%pip install semantic-linkUdfør den nødvendige import af moduler, som du skal bruge senere:
import sempy.fabric as fabric from sempy.dependencies import plot_dependency_metadata
Indlæs og forbehandler dataene
I dette selvstudium bruges en semantisk standardmodel Eksempel på kunderentabilitet.pbix-. Du kan få en beskrivelse af den semantiske model under eksempel på kunderentabilitet for Power BI.
Indlæs Power BI-dataene i FabricDataFrames ved hjælp af SemPys
read_tablefunktion:dataset = "Customer Profitability Sample" customer = fabric.read_table(dataset, "Customer") customer.head()Indlæs tabellen
Statei en FabricDataFrame:state = fabric.read_table(dataset, "State") state.head()Selvom outputtet af denne kode ligner en pandas DataFrame, har du faktisk initialiseret en datastruktur kaldet en
FabricDataFrame, der understøtter nogle nyttige handlinger oven på pandas.Kontrollér datatypen for
customer:type(customer)Resultatet bekræfter, at
customerer af typensempy.fabric._dataframe._fabric_dataframe.FabricDataFrame.'Deltag i
customerogstateDataFrames:customer_state_df = customer.merge(state, left_on="State", right_on="StateCode", how='left') customer_state_df.head()
Identificer funktionelle afhængigheder
En funktionel afhængighed manifesterer sig som en en til mange-relation mellem værdierne i to (eller flere) kolonner i en DataFrame. Disse relationer kan bruges til automatisk at registrere problemer med datakvaliteten.
Kør SemPys
find_dependenciesfunktion på den flettede DataFrame for at identificere eventuelle eksisterende funktionelle afhængigheder mellem værdier i kolonnerne:dependencies = customer_state_df.find_dependencies() dependenciesVisualiser de identificerede afhængigheder ved hjælp af SemPys
plot_dependency_metadatafunktion:plot_dependency_metadata(dependencies)
Som forventet viser diagrammet over funktionelle afhængigheder, at kolonnen
Customerbestemmer nogle kolonner, f.eks.City,Postal CodeogName.Overraskende nok viser grafen ikke en funktionel afhængighed mellem
CityogPostal Code, sandsynligvis fordi der er mange overtrædelser i relationerne mellem kolonnerne. Du kan bruge SemPysplot_dependency_violationsfunktion til at visualisere overtrædelser af afhængigheder mellem bestemte kolonner.

Udforsk dataene for kvalitetsproblemer
Tegn en graf med SemPys
plot_dependency_violationsvisualiseringsfunktion.customer_state_df.plot_dependency_violations('Postal Code', 'City')
Afbildningen af afhængighedsovertrædelser viser værdier for
Postal Codei venstre side og værdier forCityi højre side. En kant forbinder enPostal Codei venstre side med enCityi højre side, hvis der er en række, der indeholder disse to værdier. Kanterne anmærkes med antallet af sådanne rækker. Der er f.eks. to rækker med postnummeret 20004, den ene med byen "North Tower" og den anden med byen "Washington".Desuden viser afbildningen et par overtrædelser og mange tomme værdier.
Bekræft antallet af tomme værdier for
Postal Code:customer_state_df['Postal Code'].isna().sum()50 rækker har NA for postnummer.
Slip rækker med tomme værdier. Find derefter afhængigheder ved hjælp af funktionen
find_dependencies. Bemærk den ekstra parameterverbose=1, der giver et indblik i SemPys interne funktioner:customer_state_df2=customer_state_df.dropna() customer_state_df2.find_dependencies(verbose=1)Den betingede entropi for
Postal CodeogCityer 0,049. Denne værdi angiver, at der er funktionelle afhængighedsovertrædelser. Før du retter fejlene, skal du hæve grænsen for betinget entropi fra standardværdien for0.01til0.05, bare for at se afhængighederne. Lavere tærskler resulterer i færre afhængigheder (eller højere selektivitet).Hæv tærsklen for betinget entropi fra standardværdien for
0.01til0.05:plot_dependency_metadata(customer_state_df2.find_dependencies(threshold=0.05))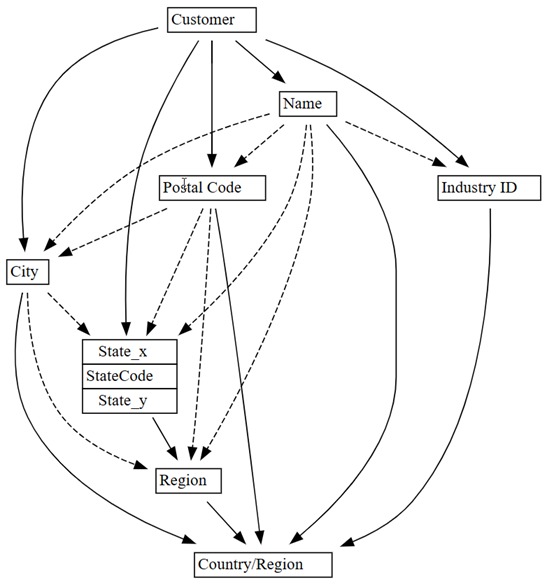
Hvis du anvender domænekendskab til, hvilket objekt der bestemmer værdier for andre objekter, virker grafen over afhængigheder nøjagtig.
Udforsk flere problemer med datakvaliteten, der blev registreret. En stiplet pil joinforbinder f.eks.
CityogRegion, hvilket angiver, at afhængigheden kun er omtrentlig. Denne omtrentlige relation kan betyde, at der er en delvis funktionel afhængighed.customer_state_df.list_dependency_violations('City', 'Region')Se nærmere på hver af de tilfælde, hvor en ikke-
Regionværdi forårsager en overtrædelse:customer_state_df[customer_state_df.City=='Downers Grove']Resultatet viser Downers Grove by, der forekommer i Illinois og Nebraska. Downer's Grove er dog en by i Illinois, ikke Nebraska.
Se byen Fremont:
customer_state_df[customer_state_df.City=='Fremont']Der er en by kaldet Fremont i Californien. Men for Texas returnerer søgemaskinen Premont, ikke Fremont.
Det er også mistænkeligt at se overtrædelser af afhængigheden mellem
NameogCountry/Region, som det fremgår af den stiplede linje i den oprindelige graf over afhængighedsovertrædelser (før rækkerne med tomme værdier slippes).customer_state_df.list_dependency_violations('Name', 'Country/Region')Det ser ud til, at én kunde, SDI Design er til stede i to områder – USA og Canada. Denne forekomst er muligvis ikke en semantisk overtrædelse, men kan blot være et ualmindeligt tilfælde. Alligevel er det værd at se nærmere på:
Se nærmere på kundens SDI Design:
customer_state_df[customer_state_df.Name=='SDI Design']Yderligere inspektion viser, at det faktisk er to forskellige kunder (fra forskellige brancher) med samme navn.

Udforskning af dataanalyser er en spændende proces, og det samme er datarensning. Der er altid noget, som dataene skjuler, afhængigt af hvordan du ser på dem, hvad du vil spørge om osv. Semantisk link giver dig nye værktøjer, som du kan bruge til at opnå mere med dine data.
Relateret indhold
Tjek andre selvstudier for semantisk link / SemPy:
- selvstudium: Ryd op i data med funktionelle afhængigheder
- selvstudium: Udtræk og beregn Power BI-målinger fra en Jupyter-notesbog
- selvstudium: Find relationer i en semantisk model ved hjælp af semantisk link
- selvstudium: Find relationer i datasættet Synthea ved hjælp af semantisk link
- selvstudium: Valider data ved hjælp af GX- (SemPy and Great Expectations)