间接绘制和 GPU 剔除
D3D12ExecuteIndirect 示例演示如何使用间接命令来绘制内容。 它还演示如何在发出这些命令之前在计算着色器中的 GPU 上对其进行操作。
该示例创建描述 1024 个绘制调用的命令缓冲区。 每个绘制调用呈现带有随机颜色、位置和速度的三角形。 这些三角形在屏幕上不断地创建动画。 此示例中有两种模式。 在第一种模式下,计算着色器检查间接命令,并决定是否将该命令添加到描述应执行哪些命令的无序访问视图 (UAV)。 在第二种模式下,只需执行所有命令。 按空格键将在模式之间进行切换。
定义间接命令
我们首先定义应如何显示间接命令。 在此示例中,我们想要执行的命令用于:
- 1. (CBV) 更新常量缓冲区视图。
2. 绘制三角形。
这些绘制命令由 D3D12ExecuteIndirect 类定义中的以下结构表示。 按此结构中定义的顺序执行命令。
// Data structure to match the command signature used for ExecuteIndirect.
struct IndirectCommand
{
D3D12_GPU_VIRTUAL_ADDRESS cbv;
D3D12_DRAW_ARGUMENTS drawArguments;
};
| 调用流程 | 参数 |
|---|---|
| D3D12_GPU_VIRTUAL_ADDRESS (UINT64) | |
| D3D12_DRAW_ARGUMENTS |
若要随附于数据结构,还会创建命令签名,指示 GPU 如何解释传递给 ExecuteIndirect API 的数据。 此命令签名和大部分以下代码将添加到 LoadAssets 方法。
// Create the command signature used for indirect drawing.
{
// Each command consists of a CBV update and a DrawInstanced call.
D3D12_INDIRECT_ARGUMENT_DESC argumentDescs[2] = {};
argumentDescs[0].Type = D3D12_INDIRECT_ARGUMENT_TYPE_CONSTANT_BUFFER_VIEW;
argumentDescs[0].ConstantBufferView.RootParameterIndex = Cbv;
argumentDescs[1].Type = D3D12_INDIRECT_ARGUMENT_TYPE_DRAW;
D3D12_COMMAND_SIGNATURE_DESC commandSignatureDesc = {};
commandSignatureDesc.pArgumentDescs = argumentDescs;
commandSignatureDesc.NumArgumentDescs = _countof(argumentDescs);
commandSignatureDesc.ByteStride = sizeof(IndirectCommand);
ThrowIfFailed(m_device->CreateCommandSignature(&commandSignatureDesc, m_rootSignature.Get(), IID_PPV_ARGS(&m_commandSignature)));
}
| 调用流程 | 参数 |
|---|---|
| D3D12_INDIRECT_ARGUMENT_DESC | D3D12_INDIRECT_ARGUMENT_TYPE |
| D3D12_COMMAND_SIGNATURE_DESC | |
| CreateCommandSignature |
创建图形和计算根签名
我们还会创建图形和计算根签名。 图形根签名仅定义根 CBV。 请注意,定义命令签名时,我们在上面所示 D3D12_INDIRECT_ARGUMENT_DESC) (映射此根参数的索引。 计算根签名定义:
- 具有三个槽(两个 SRV 和一个 UAV)的常见描述符表:
- 一个 SRV 向计算着色器公开常量缓冲区
- 一个 SRV 向计算着色器公开命令缓冲区
- UAV 是计算着色器保存可见三角形的命令的位置
- 四个根常量:
- 三角形一侧的一半宽度
- 三角形顶点的 z 位置
- 同质空间中剔除平面的 +/- x 偏移量 [-1,1]
- 命令缓冲区中的间接命令数
// Create the root signatures.
{
CD3DX12_ROOT_PARAMETER rootParameters[GraphicsRootParametersCount];
rootParameters[Cbv].InitAsConstantBufferView(0, 0, D3D12_SHADER_VISIBILITY_VERTEX);
CD3DX12_ROOT_SIGNATURE_DESC rootSignatureDesc;
rootSignatureDesc.Init(_countof(rootParameters), rootParameters, 0, nullptr, D3D12_ROOT_SIGNATURE_FLAG_ALLOW_INPUT_ASSEMBLER_INPUT_LAYOUT);
ComPtr<ID3DBlob> signature;
ComPtr<ID3DBlob> error;
ThrowIfFailed(D3D12SerializeRootSignature(&rootSignatureDesc, D3D_ROOT_SIGNATURE_VERSION_1, &signature, &error));
ThrowIfFailed(m_device->CreateRootSignature(0, signature->GetBufferPointer(), signature->GetBufferSize(), IID_PPV_ARGS(&m_rootSignature)));
// Create compute signature.
CD3DX12_DESCRIPTOR_RANGE ranges[2];
ranges[0].Init(D3D12_DESCRIPTOR_RANGE_TYPE_SRV, 2, 0);
ranges[1].Init(D3D12_DESCRIPTOR_RANGE_TYPE_UAV, 1, 0);
CD3DX12_ROOT_PARAMETER computeRootParameters[ComputeRootParametersCount];
computeRootParameters[SrvUavTable].InitAsDescriptorTable(2, ranges);
computeRootParameters[RootConstants].InitAsConstants(4, 0);
CD3DX12_ROOT_SIGNATURE_DESC computeRootSignatureDesc;
computeRootSignatureDesc.Init(_countof(computeRootParameters), computeRootParameters);
ThrowIfFailed(D3D12SerializeRootSignature(&computeRootSignatureDesc, D3D_ROOT_SIGNATURE_VERSION_1, &signature, &error));
ThrowIfFailed(m_device->CreateRootSignature(0, signature->GetBufferPointer(), signature->GetBufferSize(), IID_PPV_ARGS(&m_computeRootSignature)));
}
为计算着色器创建着色器资源视图 (SRV)
创建管道状态对象、顶点缓冲区、深度模具和常量缓冲区后,该示例则会创建常量缓冲区的着色器资源视图 (SRV),以便计算着色器可以访问常量缓冲区中的数据。
// Create shader resource views (SRV) of the constant buffers for the
// compute shader to read from.
D3D12_SHADER_RESOURCE_VIEW_DESC srvDesc = {};
srvDesc.Format = DXGI_FORMAT_UNKNOWN;
srvDesc.ViewDimension = D3D12_SRV_DIMENSION_BUFFER;
srvDesc.Shader4ComponentMapping = D3D12_DEFAULT_SHADER_4_COMPONENT_MAPPING;
srvDesc.Buffer.NumElements = TriangleCount;
srvDesc.Buffer.StructureByteStride = sizeof(ConstantBufferData);
srvDesc.Buffer.Flags = D3D12_BUFFER_SRV_FLAG_NONE;
CD3DX12_CPU_DESCRIPTOR_HANDLE cbvSrvHandle(m_cbvSrvUavHeap->GetCPUDescriptorHandleForHeapStart(), CbvSrvOffset, m_cbvSrvUavDescriptorSize);
for (UINT frame = 0; frame < FrameCount; frame++)
{
srvDesc.Buffer.FirstElement = frame * TriangleCount;
m_device->CreateShaderResourceView(m_constantBuffer.Get(), &srvDesc, cbvSrvHandle);
cbvSrvHandle.Offset(CbvSrvUavDescriptorCountPerFrame, m_cbvSrvUavDescriptorSize);
}
| 调用流程 | 参数 |
|---|---|
| D3D12_SHADER_RESOURCE_VIEW_DESC | |
| CD3DX12_CPU_DESCRIPTOR_HANDLE | GetCPUDescriptorHandleForHeapStart |
| CreateShaderResourceView |
创建间接命令缓冲区
我们会创建间接命令缓冲区,并使用以下代码定义其内容。 我们绘制相同的三角形顶点 1024 次,但使用每个绘制调用指向不同的常量缓冲区位置。
D3D12_GPU_VIRTUAL_ADDRESS gpuAddress = m_constantBuffer->GetGPUVirtualAddress();
UINT commandIndex = 0;
for (UINT frame = 0; frame < FrameCount; frame++)
{
for (UINT n = 0; n < TriangleCount; n++)
{
commands[commandIndex].cbv = gpuAddress;
commands[commandIndex].drawArguments.VertexCountPerInstance = 3;
commands[commandIndex].drawArguments.InstanceCount = 1;
commands[commandIndex].drawArguments.StartVertexLocation = 0;
commands[commandIndex].drawArguments.StartInstanceLocation = 0;
commandIndex++;
gpuAddress += sizeof(ConstantBufferData);
}
}
| 调用流程 | 参数 |
|---|---|
| D3D12_GPU_VIRTUAL_ADDRESS | GetGPUVirtualAddress |
将命令缓冲区上载到 GPU 后,我们还会创建 SRV 以便计算着色器进行读取。 这与常量缓冲区中创建的 SRV 非常相似。
// Create SRVs for the command buffers.
D3D12_SHADER_RESOURCE_VIEW_DESC srvDesc = {};
srvDesc.Format = DXGI_FORMAT_UNKNOWN;
srvDesc.ViewDimension = D3D12_SRV_DIMENSION_BUFFER;
srvDesc.Shader4ComponentMapping = D3D12_DEFAULT_SHADER_4_COMPONENT_MAPPING;
srvDesc.Buffer.NumElements = TriangleCount;
srvDesc.Buffer.StructureByteStride = sizeof(IndirectCommand);
srvDesc.Buffer.Flags = D3D12_BUFFER_SRV_FLAG_NONE;
CD3DX12_CPU_DESCRIPTOR_HANDLE commandsHandle(m_cbvSrvUavHeap->GetCPUDescriptorHandleForHeapStart(), CommandsOffset, m_cbvSrvUavDescriptorSize);
for (UINT frame = 0; frame < FrameCount; frame++)
{
srvDesc.Buffer.FirstElement = frame * TriangleCount;
m_device->CreateShaderResourceView(m_commandBuffer.Get(), &srvDesc, commandsHandle);
commandsHandle.Offset(CbvSrvUavDescriptorCountPerFrame, m_cbvSrvUavDescriptorSize);
}
| 调用流程 | 参数 |
|---|---|
| D3D12_SHADER_RESOURCE_VIEW_DESC | |
| CD3DX12_CPU_DESCRIPTOR_HANDLE | GetCPUDescriptorHandleForHeapStart |
| CreateShaderResourceView |
创建计算 UAV
我们需要创建将存储计算工作的结果的 UAV。 当某个三角形被计算着色器视为对呈现器目标可见时,该三角形将附加到此 UAV,然后可由 ExecuteIndirect API 使用。
CD3DX12_CPU_DESCRIPTOR_HANDLE processedCommandsHandle(m_cbvSrvUavHeap->GetCPUDescriptorHandleForHeapStart(), ProcessedCommandsOffset, m_cbvSrvUavDescriptorSize);
for (UINT frame = 0; frame < FrameCount; frame++)
{
// Allocate a buffer large enough to hold all of the indirect commands
// for a single frame as well as a UAV counter.
commandBufferDesc = CD3DX12_RESOURCE_DESC::Buffer(CommandBufferSizePerFrame + sizeof(UINT), D3D12_RESOURCE_FLAG_ALLOW_UNORDERED_ACCESS);
CD3DX12_HEAP_PROPERTIES heapProps(D3D12_HEAP_TYPE_DEFAULT);
ThrowIfFailed(m_device->CreateCommittedResource(
&heapProps,
D3D12_HEAP_FLAG_NONE,
&commandBufferDesc,
D3D12_RESOURCE_STATE_COPY_DEST,
nullptr,
IID_PPV_ARGS(&m_processedCommandBuffers[frame])));
D3D12_UNORDERED_ACCESS_VIEW_DESC uavDesc = {};
uavDesc.Format = DXGI_FORMAT_UNKNOWN;
uavDesc.ViewDimension = D3D12_UAV_DIMENSION_BUFFER;
uavDesc.Buffer.FirstElement = 0;
uavDesc.Buffer.NumElements = TriangleCount;
uavDesc.Buffer.StructureByteStride = sizeof(IndirectCommand);
uavDesc.Buffer.CounterOffsetInBytes = CommandBufferSizePerFrame;
uavDesc.Buffer.Flags = D3D12_BUFFER_UAV_FLAG_NONE;
m_device->CreateUnorderedAccessView(
m_processedCommandBuffers[frame].Get(),
m_processedCommandBuffers[frame].Get(),
&uavDesc,
processedCommandsHandle);
processedCommandsHandle.Offset(CbvSrvUavDescriptorCountPerFrame, m_cbvSrvUavDescriptorSize);
}
| 调用流程 | 参数 |
|---|---|
| CD3DX12_CPU_DESCRIPTOR_HANDLE | GetCPUDescriptorHandleForHeapStart |
| CD3DX12_RESOURCE_DESC | D3D12_RESOURCE_FLAGS |
| CreateCommittedResource | |
| D3D12_UNORDERED_ACCESS_VIEW_DESC | |
| CreateUnorderedAccessView |
绘制帧
每当绘制帧时,如果我们处于正在调用计算着色器且正在由 GPU 处理间接命令的模式下时,将首先调度该工作来填充 ExecuteIndirect 的命令缓冲区。 以下代码段将添加到 PopulateCommandLists 方法。
// Record the compute commands that will cull triangles and prevent them from being processed by the vertex shader.
if (m_enableCulling)
{
UINT frameDescriptorOffset = m_frameIndex * CbvSrvUavDescriptorCountPerFrame;
D3D12_GPU_DESCRIPTOR_HANDLE cbvSrvUavHandle = m_cbvSrvUavHeap->GetGPUDescriptorHandleForHeapStart();
m_computeCommandList->SetComputeRootSignature(m_computeRootSignature.Get());
ID3D12DescriptorHeap* ppHeaps[] = { m_cbvSrvUavHeap.Get() };
m_computeCommandList->SetDescriptorHeaps(_countof(ppHeaps), ppHeaps);
m_computeCommandList->SetComputeRootDescriptorTable(
SrvUavTable,
CD3DX12_GPU_DESCRIPTOR_HANDLE(cbvSrvUavHandle, CbvSrvOffset + frameDescriptorOffset, m_cbvSrvUavDescriptorSize));
m_computeCommandList->SetComputeRoot32BitConstants(RootConstants, 4, reinterpret_cast<void*>(&m_csRootConstants), 0);
// Reset the UAV counter for this frame.
m_computeCommandList->CopyBufferRegion(m_processedCommandBuffers[m_frameIndex].Get(), CommandBufferSizePerFrame, m_processedCommandBufferCounterReset.Get(), 0, sizeof(UINT));
D3D12_RESOURCE_BARRIER barrier = CD3DX12_RESOURCE_BARRIER::Transition(m_processedCommandBuffers[m_frameIndex].Get(), D3D12_RESOURCE_STATE_COPY_DEST, D3D12_RESOURCE_STATE_UNORDERED_ACCESS);
m_computeCommandList->ResourceBarrier(1, &barrier);
m_computeCommandList->Dispatch(static_cast<UINT>(ceil(TriangleCount / float(ComputeThreadBlockSize))), 1, 1);
}
ThrowIfFailed(m_computeCommandList->Close());
然后,我们将在 UAV(已启用 GPU 精选)或已满的命令缓冲区(已禁用 GPU 精选)中执行命令。
// Record the rendering commands.
{
// Set necessary state.
m_commandList->SetGraphicsRootSignature(m_rootSignature.Get());
ID3D12DescriptorHeap* ppHeaps[] = { m_cbvSrvUavHeap.Get() };
m_commandList->SetDescriptorHeaps(_countof(ppHeaps), ppHeaps);
m_commandList->RSSetViewports(1, &m_viewport);
m_commandList->RSSetScissorRects(1, m_enableCulling ? &m_cullingScissorRect : &m_scissorRect);
// Indicate that the command buffer will be used for indirect drawing
// and that the back buffer will be used as a render target.
D3D12_RESOURCE_BARRIER barriers[2] = {
CD3DX12_RESOURCE_BARRIER::Transition(
m_enableCulling ? m_processedCommandBuffers[m_frameIndex].Get() : m_commandBuffer.Get(),
m_enableCulling ? D3D12_RESOURCE_STATE_UNORDERED_ACCESS : D3D12_RESOURCE_STATE_NON_PIXEL_SHADER_RESOURCE,
D3D12_RESOURCE_STATE_INDIRECT_ARGUMENT),
CD3DX12_RESOURCE_BARRIER::Transition(
m_renderTargets[m_frameIndex].Get(),
D3D12_RESOURCE_STATE_PRESENT,
D3D12_RESOURCE_STATE_RENDER_TARGET)
};
m_commandList->ResourceBarrier(_countof(barriers), barriers);
CD3DX12_CPU_DESCRIPTOR_HANDLE rtvHandle(m_rtvHeap->GetCPUDescriptorHandleForHeapStart(), m_frameIndex, m_rtvDescriptorSize);
CD3DX12_CPU_DESCRIPTOR_HANDLE dsvHandle(m_dsvHeap->GetCPUDescriptorHandleForHeapStart());
m_commandList->OMSetRenderTargets(1, &rtvHandle, FALSE, &dsvHandle);
// Record commands.
const float clearColor[] = { 0.0f, 0.2f, 0.4f, 1.0f };
m_commandList->ClearRenderTargetView(rtvHandle, clearColor, 0, nullptr);
m_commandList->ClearDepthStencilView(dsvHandle, D3D12_CLEAR_FLAG_DEPTH, 1.0f, 0, 0, nullptr);
m_commandList->IASetPrimitiveTopology(D3D_PRIMITIVE_TOPOLOGY_TRIANGLESTRIP);
m_commandList->IASetVertexBuffers(0, 1, &m_vertexBufferView);
if (m_enableCulling)
{
// Draw the triangles that have not been culled.
m_commandList->ExecuteIndirect(
m_commandSignature.Get(),
TriangleCount,
m_processedCommandBuffers[m_frameIndex].Get(),
0,
m_processedCommandBuffers[m_frameIndex].Get(),
CommandBufferSizePerFrame);
}
else
{
// Draw all of the triangles.
m_commandList->ExecuteIndirect(
m_commandSignature.Get(),
TriangleCount,
m_commandBuffer.Get(),
CommandBufferSizePerFrame * m_frameIndex,
nullptr,
0);
}
// Indicate that the command buffer may be used by the compute shader
// and that the back buffer will now be used to present.
barriers[0].Transition.StateBefore = D3D12_RESOURCE_STATE_INDIRECT_ARGUMENT;
barriers[0].Transition.StateAfter = m_enableCulling ? D3D12_RESOURCE_STATE_COPY_DEST : D3D12_RESOURCE_STATE_NON_PIXEL_SHADER_RESOURCE;
barriers[1].Transition.StateBefore = D3D12_RESOURCE_STATE_RENDER_TARGET;
barriers[1].Transition.StateAfter = D3D12_RESOURCE_STATE_PRESENT;
m_commandList->ResourceBarrier(_countof(barriers), barriers);
ThrowIfFailed(m_commandList->Close());
}
如果处于 GPU 精选模式,我们将使图形命令队列在开始执行间接命令之前等待完成计算工作。 在 OnRender 方法中,将添加以下代码段。
// Execute the compute work.
if (m_enableCulling)
{
ID3D12CommandList* ppCommandLists[] = { m_computeCommandList.Get() };
m_computeCommandQueue->ExecuteCommandLists(_countof(ppCommandLists), ppCommandLists);
m_computeCommandQueue->Signal(m_computeFence.Get(), m_fenceValues[m_frameIndex]);
// Execute the rendering work only when the compute work is complete.
m_commandQueue->Wait(m_computeFence.Get(), m_fenceValues[m_frameIndex]);
}
// Execute the rendering work.
ID3D12CommandList* ppCommandLists[] = { m_commandList.Get() };
m_commandQueue->ExecuteCommandLists(_countof(ppCommandLists), ppCommandLists);
| 调用流程 | 参数 |
|---|---|
| ID3D12CommandList | |
| ExecuteCommandLists | |
| 信号 | |
| Wait | |
| ID3D12CommandList | |
| ExecuteCommandLists |
运行示例
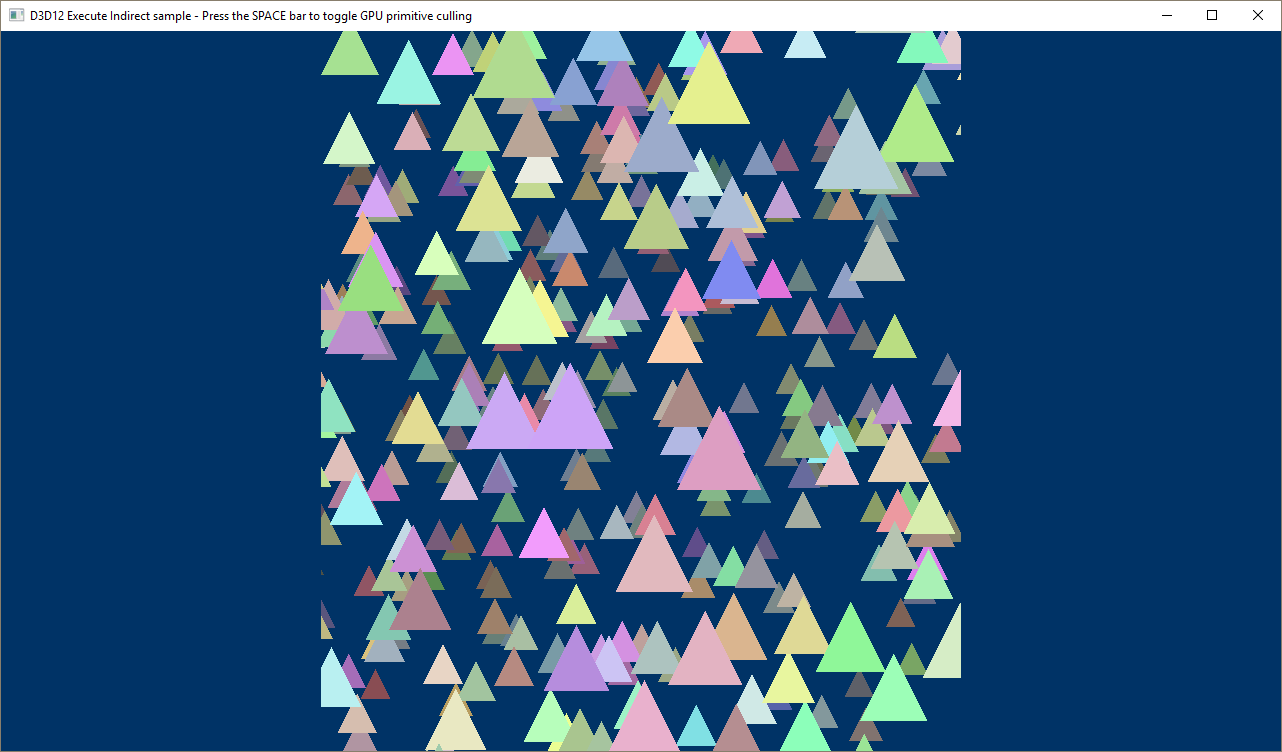
带有 GPU 基元精选的示例。
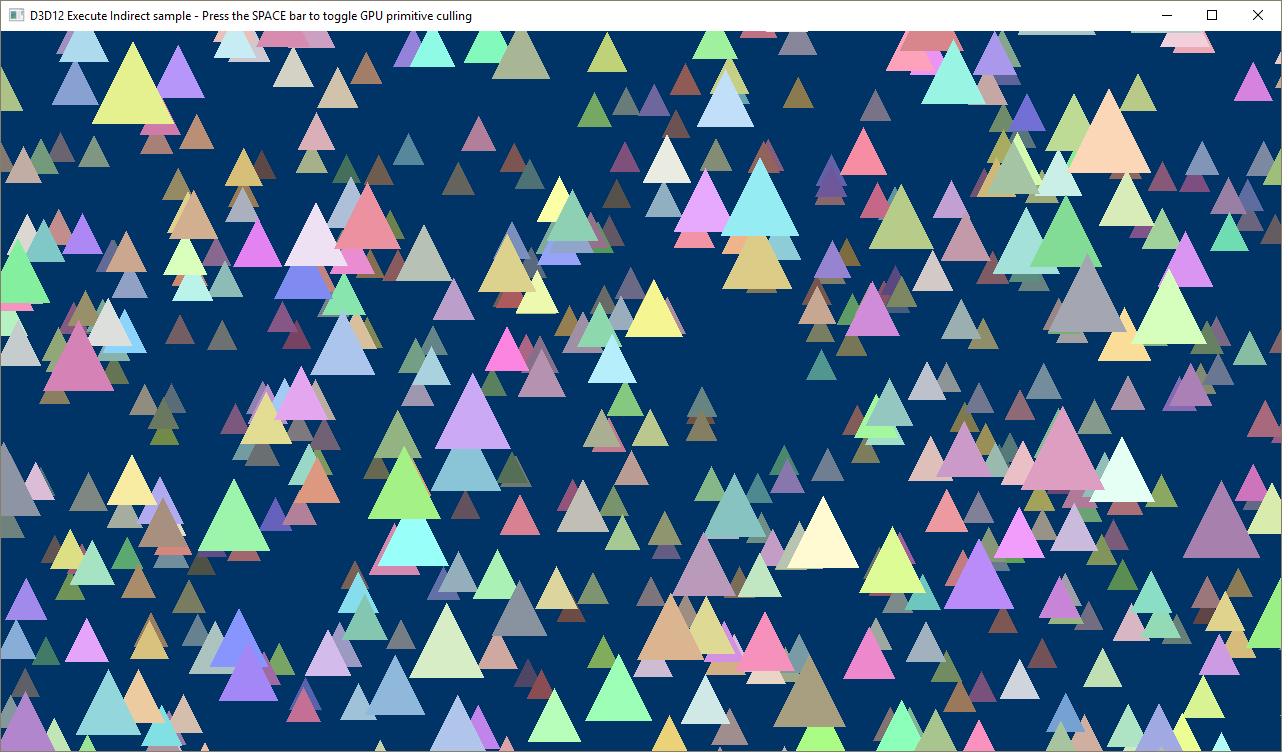
不带 GPU 基元精选的示例。
相关主题