Använd berikande av ostrukturerade kliniska anteckningar (förhandsversion) i vårddatalösningar
[Denna artikel är en förhandsversion av dokumentationen och kan komma att ändras.]
Obs
Detta innehåll uppdateras för närvarande.
Ostrukturerad anrikning av kliniska anteckningar (förhandsgranskning) använder Azure AI Language tjänsten Text Analytics for Health för att extrahera FHIR-entiteter (elektronisk standard för utbyte av vårdinformation) från ostrukturerade kliniska anteckningar. Det skapar strukturerade data från dessa kliniska anteckningar. Du kan sedan analysera dessa strukturerade data för att få insikter, förutsägelser och kvalitetsmått som syftar till att förbättra patienthälsan.
Mer information om funktionen och hur du distribuerar och konfigurerar den finns i:
- Översikt över ostrukturerade kliniska anteckningar (förhandsversion)
- Distribuera och konfigurera Berikande av ostrukturerade kliniska anteckningar (förhandsversion)
Berikande av ostrukturerade kliniska anteckningar (förhandsversion) är direkt beroende av funktionen för vårddatagrunder. Se till att du har konfigurerat och kört pipelines för grunderna för vårddatagrunder först.
Förutsättningar
- Distribuera Healthcare-datalösningar i Microsoft Fabric
- Installera grundläggande notebook-filer och pipelines i Distribuera vårddatagrunder.
- Konfigurera språktjänsten Azure enligt beskrivningen i Konfigurera Azure språktjänsten.
- Distribuera och konfigurera Berikande av ostrukturerade kliniska anteckningar (förhandsversion)
- Distribuera och konfigurera OMOP-omvandlingar. Steget är valfritt.
NLP inmatningstjänst
Notebook-filen healthcare#_msft_ta4h_silver_ingestion kör modulen NLPIngestionService i biblioteket med vårddatalösningar för att anropa tjänsten Text Analytics for Health. Den här tjänsten extraherar ostrukturerade kliniska anteckningar från FHIR-resursen DocumentReference.Content för att skapa plana utdata. Mer information finns i Granska notebook-konfigurationen.
Datalagring i silverlager
Efter NLP API-analysen (naturlig språkbearbetning) lagras den strukturerade och tillplattade utdata i följande inbyggda tabeller i sjöhuset healthcare#_msft_silver:
- nlpentity: Innehåller de tillplattade entiteter som extraherats från de ostrukturerade kliniska anteckningarna. Varje rad är en enda term som extraheras från den ostrukturerade texten när textanalysen har utförts.
- nlprelationship: Tillhandahåller relationen mellan de extraherade entiteterna.
- nlpfhir: Innehåller FHIR-utdatapaketet som en JSON-sträng.
För att spåra den senast uppdaterade tidsstämpeln använder NLPIngestionService fältet parent_meta_lastUpdated i alla de tre silversjöhustabellerna. Den här spårningen säkerställer att källdokumentet DocumentReference, som är den överordnade resursen, först lagras så att referensintegriteten bibehålls. Den här processen hjälper till att förhindra inkonsekvenser i data och överblivna resurser.
Viktigt
För närvarande returnerar Text Analytics for Health vokabulärer som anges i UMLS Metathesaurus Vocabulary Documentation. Vägledning om dessa vokabulärer finns i Importera data från UMLS.
I förhandsversionen använder vi terminologierna SNOMED-CT (Systematized Nomenclature of Medicine - Clinical Terms), LOINC (Logical Observation Identifiers, Names, and Codes) och RxNorm om ingår i exempeldatauppsättningen OMOP baserat på vägledning från Observational Health Data Sciences and Informatics (OHDSI).
OMOP-omvandling
Vårddatalösningar i Microsoft Fabric ger också en annan funktion för omvandlingar av Observational Medical Outcomes Partnership (OMOP). När du kör den här funktionen omvandlar den underliggande omvandlingen från silversjöhus till OMOP guldsjöhus även strukturerade och plana utdata från den ostrukturerade kliniska anteckningsanalysen. Omvandlingen läser från tabellen nlpentity i silversjöhus och mappar utdata till tabellen NOTE_NLP i OMOP guldsjöhus.
Mer information finns i: Översikt av OMOP omvandlinger.
Här är schemat för strukturerade NLP-utdata, med motsvarande NOTE_NLP kolumnmappning till OMOP Common Data Model:
| Plana affärsdokument | Beskrivning | Note_NLP-mappning | Sampla data |
|---|---|---|---|
| ID | Unik identifierare för entiteten. Sammansatt nyckel för parent_id, offset och length. |
note_nlp_id |
1380 |
| parent_id | En sekundärnyckel till den plana text documentreferencecontent som termen extraherades från. | note_id |
625 |
| text | Entitetstext som visas i dokumentet. | lexical_variant |
Inga kända allergier |
| Förskjutning | Teckenförskjutning av den extraherade termen i texten documentreferencecontent. | offset |
294 |
| data_source_entity_id | ID för entiteten i den angivna källkatalogen. | note_nlp_concept_id och note_nlp_source_concept_id |
37396387 |
| nlp_last_executed | Datumet för bearbetningen av textanalysen documentreferencecontent. | nlp_date_time och nlp_date |
2023-05-17T00:00:00.0000000 |
| modell | Namn och version för NLP-systemet (namnet på NLP-systemet Text Analytics for Health och versionen). | nlp_system |
MSFT TA4H |

Tjänstbegränsningar för Text Analytics for Health
- Maximalt antal tecken per dokument är begränsat till 125 000.
- Den maximala storleken på dokument som ingår i hela begäran är begränsad till 1 MB.
- Maximalt antal dokument per begäran är begränsat till:
- 25 för det webbaserade API:et.
- 1 000 för behållaren.
Aktivera loggar
Följ dessa steg för att aktivera loggning av begäranden och svar för API:et Text Analytics for Health:
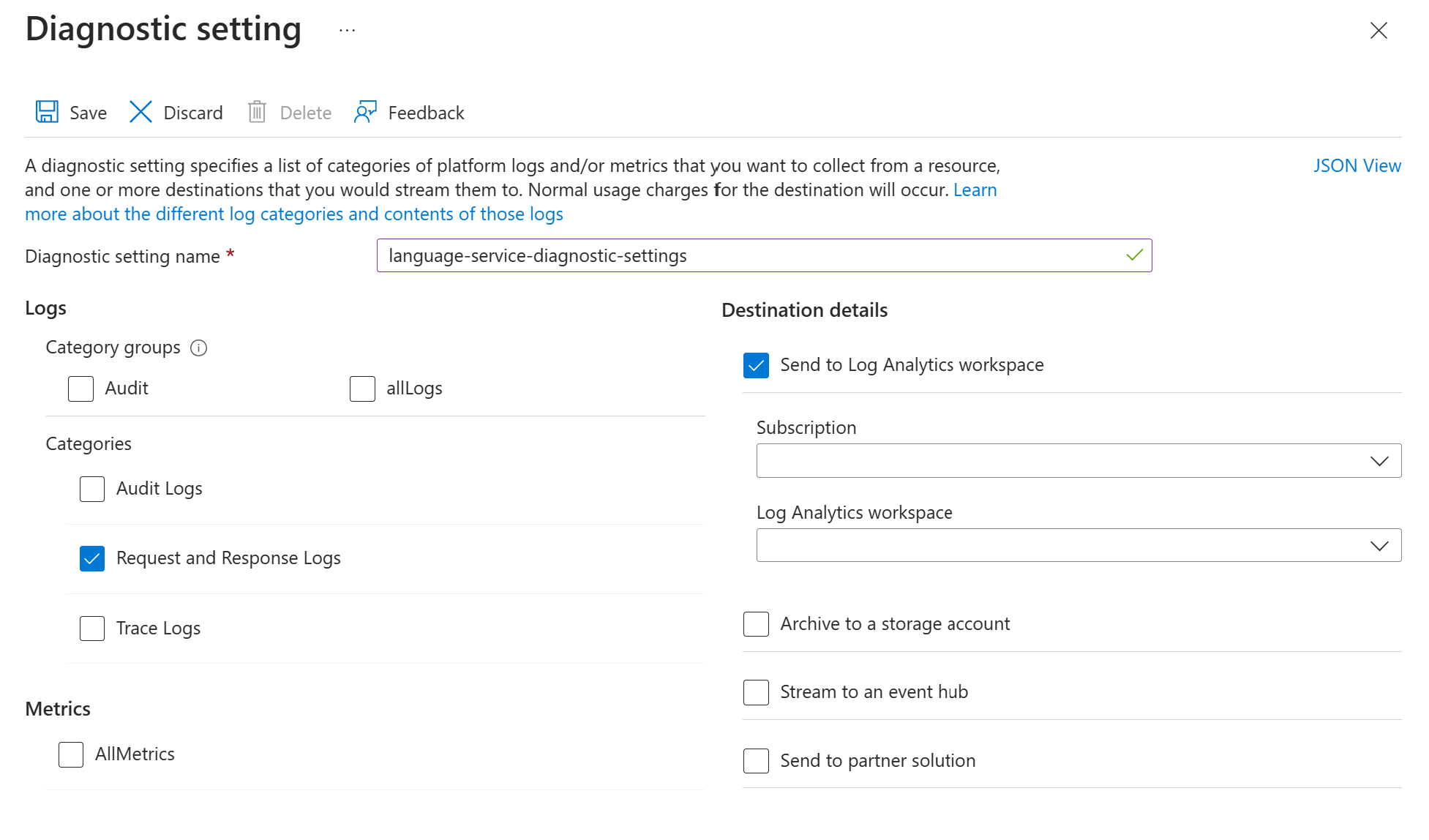
Aktivera diagnostikinställningarna för din Azure språktjänstresurs med hjälp av anvisningarna i Aktivera diagnostisk loggning för Azure AI Services. Den här resursen är samma språktjänst som du skapade under distributionssteget Konfigurera Azure-språktjänst.
- Ange ett namn på diagnostikinställningen.
- Ange kategorin till Begärande- och svarsloggar.
- För målinformation väljer du Skicka till Log Analytics-arbetsyta och väljer den Log Analytics-arbetsyta som krävs. Om du inte har någon arbetsyta följer du anvisningarna för att skapa en.
- Spara inställningarna.
Gå till avsnittet NLP-konfiguration i notebook för NLP-inmatningstjänsten. Uppdatera värdet på konfigurationsparametern
enable_text_analytics_logstillTrue. För mer information om den här notebook-filen, seGranska konfiguration av notebook-filen.

Visa loggar i Azure Log Analytics
Så här utforskar du logganalysdata:
- Navigera till din Log Analytics-arbetsyta.
- Leta upp och välj Loggar. Från den här sidan kan du köra frågor mot dina loggar.
Exempelfråga
Följande är en grundläggande Kusto-fråga som du kan använda för att utforska dina loggdata. Den här exempelfrågan hämtar alla misslyckade begäranden från Azure Cognitive Services-resursprovidern under den senaste dagen, grupperade efter feltyp:
AzureDiagnostics
| where TimeGenerated > ago(1d)
| where Category == "RequestResponse"
| where ResourceProvider == "MICROSOFT.COGNITIVESERVICES"
| where tostring(ResultSignature) startswith "4" or tostring(ResultSignature) startswith "5"
| summarize NumberOfFailedRequests = count() by ResultSignature