Distribuera och konfigurera OMOP-omvandlingar i vårddatalösningar
Obs
Detta innehåll uppdateras för närvarande.
OMOP-omvandlingar möjliggör dataförberedelse för standardiserad analys via öppna communitystandarder för Observational Medical Outcomes Partnership (OMOP). Du kan använda den här funktionen efter att du har distribuerat vårddatalösningar och funktionen vårddatagrunder till din Fabric-arbetsyta.
OMOP-omvandlingar är en valfri funktion under vårddatalösningar i Microsoft Fabric. Du har flexibiliteten att bestämma om du vill använda den eller inte, beroende på dina specifika behov eller scenarier.
Förutsättningar
- Distribuera Healthcare-datalösningar i Microsoft Fabric.
- Installera grundläggande notebook-filer och pipelines i Distribuera vårddatagrunder.
Distribuera OMOP-omvandlingar
Du kan distribuera funktionen med hjälp av installationsmodulen som beskrivs i Datalösningar för hälso- och sjukvård: Distribuera vårddatagrunder. Urvalssteget för exempeldata i den här modulen distribuerar dock inte exempeldata för den här funktionen. Exempeldata för OMOP-omvandlingar installeras exklusivt i din miljö med vårddatalösningar när du har distribuerat funktionen.
Om du inte använde installationsmodulen för att distribuera funktionen och vill använda funktionspanelen i stället följer du dessa steg:
Gå till startsidan för vårddatalösningar på Fabric.
Välj panelen OMOP-omvandlingar.
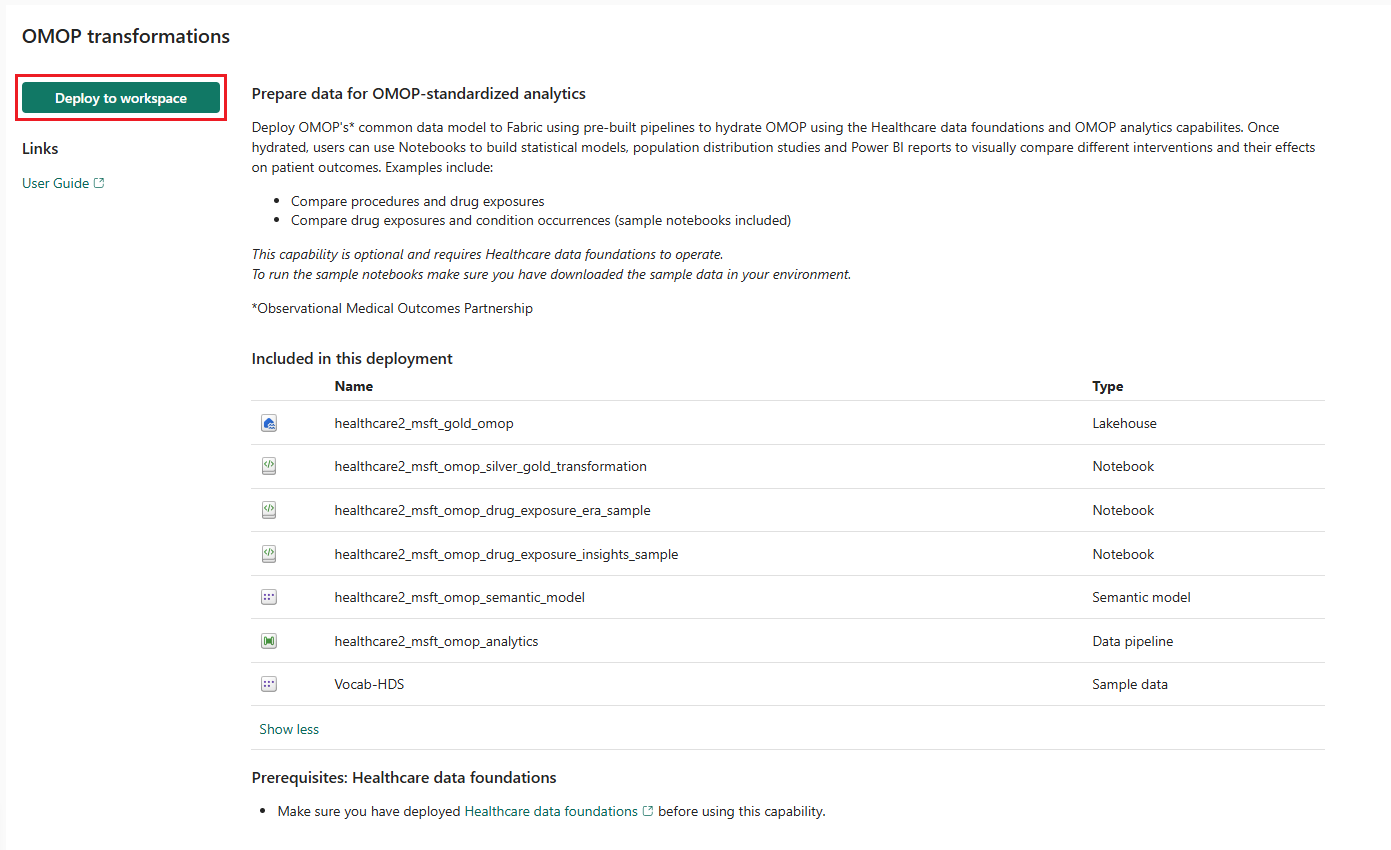
På funktionssidan väljer du Distribuera till arbetsyta.
Distribution kan ta några minuter att slutföra. Stäng inte fliken eller webbläsaren medan distributionen pågår. Medan du väntar kan du arbeta på en annan flik.
När distributionen är klar kan du se ett meddelande i meddelandefältet.
Välj Hantera funktion i meddelandefältet för att gå till sidan Kapacitetshantering.
Här kan du visa, konfigurera och hantera de artefakter som distribueras med funktionen.


Artefakter
Funktionen installerar följande artefakter i din miljön för vårddatalösningar:
| Artefakt | Type |
|---|---|
| healthcare#_msft_gold_omop | Sjöhus |
| healthcare#_msft_omop_silver_gold_transformation | Notebook-fil |
| healthcare#_msft_omop_drug_exposure_era_sample | Notebook-fil |
| healthcare#_msft_omop_drug_exposure_insights_sample | Notebook-fil |
| healthcare#_msft_omop_analytics | Datapipeline |
| healthcare#_msft_omop_semantic_model | Semantisk modell |
| Vocab-HDS | Sampla data |
Granska notebook-filen OMOP silver
Notebook-filen healthcare#_msft_omop_silver_gold_transformation använder OMOP API:er som levereras som en del av biblioteket vårddatalösningar för dataomvandling. Notebook-filen omvandlar resurser i datasjö healthcare#_msft_silver i OMOP Common Data Model. Omvandlad data infogas sedan i OMOP sjöhuset.
Notebook-filen distribueras med förkonfigurerade värden som krävs för att köra datapipelinen för OMOP-omvandlingen. Vissa konfigurationsparametrar ärver från den globala konfigurationen och kan åsidosättas på notebook-nivå. Som standard behöver du inte göra några ändringar i notebook-konfigurationsfiler. Om det behövs kan du granska eller ändra konfigurationen genom att välja respektive notebook-fil och konfigurationsfiler i din miljö.
Mer information om notebook-körningen finns i Använda OMOP-omvandlingen.
Granska OMOP semantisk modell
OMOP semantisk modell healthcare#_msft_omop_semantic_model är en specialbyggd semantisk modell baserad på OMOP guldsjöhuset. Den innehåller några viktiga relationer OMOP CDM version 5.4 mellan följande OMOP-tabeller:
- Plats
- Person
- Observation
- Procedure_Occurrence
- Condition_Occurrence
- Obs
- Drug_Exposure
- Visit_Ocurrence
- Image_Occurrence
- Mått
Dessa relationer från den minimala uppsättning som behövs för att generera Power BI-rapporter i funktionen Identifiera och skapa kohorter (förhandsversion) i vårddatalösningar. Du kan använda den här semantiska modellen som grund och lägga till fler OMOP-tabeller och relationer från OMOP sjöhuset för att skapa anpassade Power BI-rapporter från dina OMOP standardsjöhusdata.
Konfigurera exempelnotebook för läkemedelsexponeringsperioden
Exempelnotebook healthcare#_msft_omop_drug_exposure_era_sample visar hur du genererar tabellposten drug_era i OMOP med PySpark-språket(Python) i en Azure Synapse Analytics notebook, främst i undersökande syfte. Genereringen av tabellposter drug_era följer exempelskriptet exempelskript OHDSI-läkemedel, som är anpassat för att fungera med PySpark i Azure Synapse Analytics. Generatorkoden för läkemedel ingår i det anpassade Python-biblioteket, som paketeras som en hjulfil (WHL) och laddas upp till en Apache Spark-pool för enkel åtkomst.
Innan du kör notebook-filen bör du tänka på följande krav:
Kontrollera att OMOP databasen har giltiga data i följande tabeller:
- drug_exposure
- koncept
- concept_ancestor
Du kan generera dessa data med hjälp av exempeldata eller dina egna data genom att köra FHIR till OMOP datapipelinen.
Se till att det anpassade bibliotekshjulspaketet är kopplat till den Spark-pool som du använder för att köra den här notebook-filen.
Den viktigaste konfigurationsparametern för den här notebook-filen är omop_database_name. Den här parametern identifierar namnet på OMOP-databasen som innehåller data för att generera tabellen drug_era. Uppdatera bara det här värdet om OMOP databasen skiljer sig från standardvärdet i den globala konfigurationsfilen.
Om tabellen OMOP drug_exposure fylls i med giltiga data anropar den här notebook-filen modulen DrugEraGenerator som sammanfogar tidsperioder som en person exponeras för en aktiv läkemedelsingrediens, vilket möjliggör en lucka på 30 dagar. Modulen DrugEraGenerator tar bort alla befintliga drug_era-poster och genererar nya poster, baserat på den senaste OMOP-data.
Mer information om notebook-körningen finns i Använda exempelnotebook-filer för OMOP-omvandling.
Konfigurera exempelnotebook för läkemedelsexponeringsinsikter
Exempelnotebook-filen healthcare#_msft_omop_drug_exposure_insights_sample visar en undersökande analys av tabellen drug_era med PySpark i en Azure Synapse Analytics-notebook. Analysen genererar ett histogram som visar patienternas sekundära läkemedelsexponering för aktiva substanser, stratifierat efter kön och ålder för ett specifikt år. Tabellen drug_era genereras med hjälp av ett anpassat bibliotek DrugEraGenerator som den tidigare notebook-filen healthcare#_msft_omop_drug_exposure_era_sample anropar. Denna analys utökar DEX03: Fördelning av ålder, stratifierad efter läkemedel genom att inkludera stratifiering baserad på både kön och ålder.
Innan du kör notebook-filen bör du tänka på följande krav:
- Om du vill redigera notebook-konfigurationen måste du göra en kopia av den här notebook-filen. Uppdatera inte notebook-filen direkt.
- Se till att tabellen drug_era innehåller data genom att köra notebook-filen läkemedelsexponering. När du kör den här notebook-filen ersätts alla befintliga poster drug_era med nya poster, baserat på de senaste OMOP-data.
- Använd den här notebook-filen som den är för undersökande analys och skapa en kopia för att utföra anpassad analys.
Följande är de viktigaste konfigurationsparametrarna för notebook-filen. Du kan ändra dessa parametrar för alternativ explorativ analys av patientläkemedelsexponeringar:
primary_drug_concept_id: Den primära exponeringen av den aktiva substansen för patienter.secondary_drug_concept_id: Den sekundära exponeringen av den aktiva substansen för patienter.year: Målåret under vilket patienter var aktivt exponerade för både primära och sekundära läkemedel.
Mer information om notebook-körningen finns i Använda exempelnotebook-filer för OMOP-omvandling.