Anteckning
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
[Denna artikel är en förhandsversion av dokumentationen och kan komma att ändras.]
Obs
Detta innehåll uppdateras för närvarande.
Ostrukturerad anrikning av kliniska anteckningar (förhandsgranskning) använder Azure AI Language tjänsten Text Analytics for Health för att extrahera och lägga till struktur i ostrukturerade kliniska anteckningar för analys. Du kan distribuera och konfigurera denna funktion efter att du har implementerat vårddatalösningar i din Fabric-arbetsyta och aktiverat funktionen för vårddatagrunder.
Ostrukturerade kliniska anteckningar (förhandsgranskning) är en valfri funktion i vårddatalösningar i Microsoft Fabric. Du har flexibiliteten att bestämma om du vill använda den eller inte, beroende på dina specifika behov eller scenarier.
Förutsättningar
- Distribuera Healthcare-datalösningar i Microsoft Fabric.
- Installera grundläggande notebook-filer och pipelines i Distribuera vårddatagrunder.
Ange Azure språktjänst
Gå till Azure-portalen.
På startsidan väljer du Skapa en resurs, söker efter Resursgrupp och skapar en ny Azure resursgrupp.
Kontrollera att du har rollen Azure rollbaserad åtkomstkontroll (RBAC) Ägare eller Administratör för användaråtkomst i resursgruppen. Om du vill tilldela behörigheterna följer du stegen i Bevilja åtkomst.
När du har skapat resursgruppen går du tillbaka till startsidan, väljer Skapa en resurs, söker efter Språktjänst och distribuerar en ny Azure språktjänst till resursgruppen. Använd standardinställningarna.
Viktigt
Distribution av språktjänsten kräver att du godkänner villkoren för meddelande om ansvarsfull AI i Azure-portalen. Se till att du granskar dessa villkor när du lägger till språktjänsten i resursgruppen. Mer information finns i följande transparensanteckningar:
Distribuera ostrukturerade kliniska anteckningar (förhandsversion)
Du kan distribuera funktionen med hjälp av installationsmodulen som beskrivs i Datalösningar för hälso- och sjukvård: Distribuera vårddatagrunder. På inställningssidan anger du Azure Key Vault värde för att länka data i nyckelvalvet.
Om du inte använde installationsmodulen för att distribuera funktionen och vill använda funktionspanelen i stället följer du dessa steg:
Gå till startsidan för vårddatalösningar på Fabric.
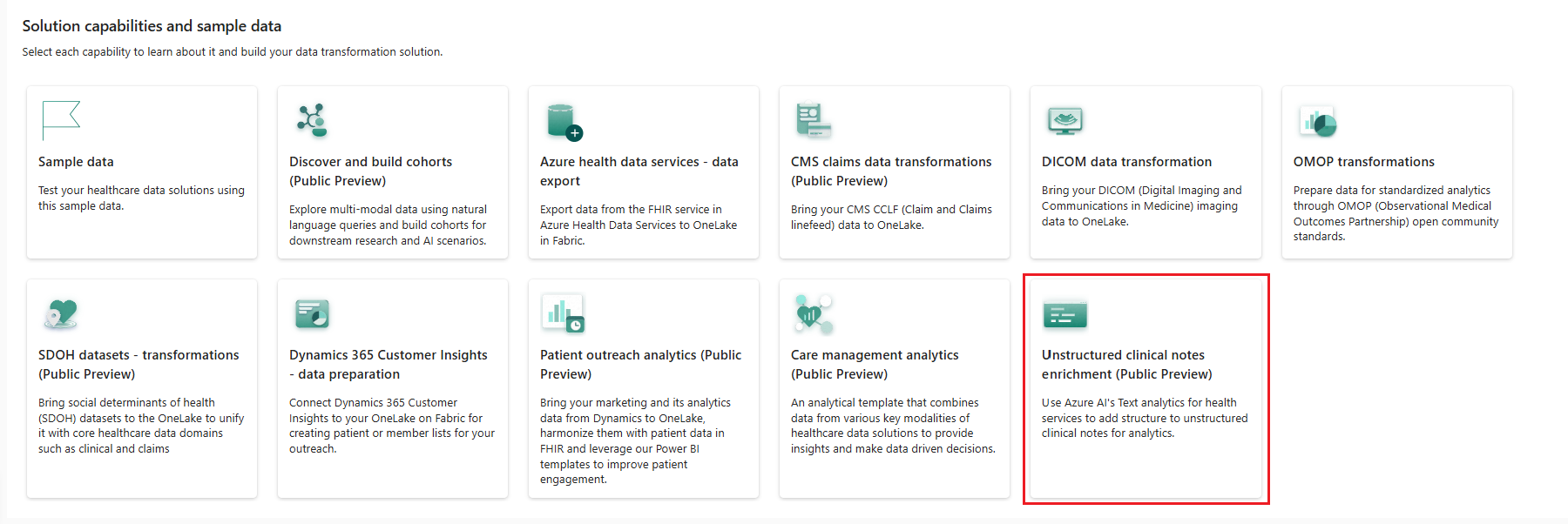
Välj panelen för berikning av ostrukturerade kliniska anteckningar (förhandsgranskning).
På funktionssidan väljer du Distribuera till arbetsyta.
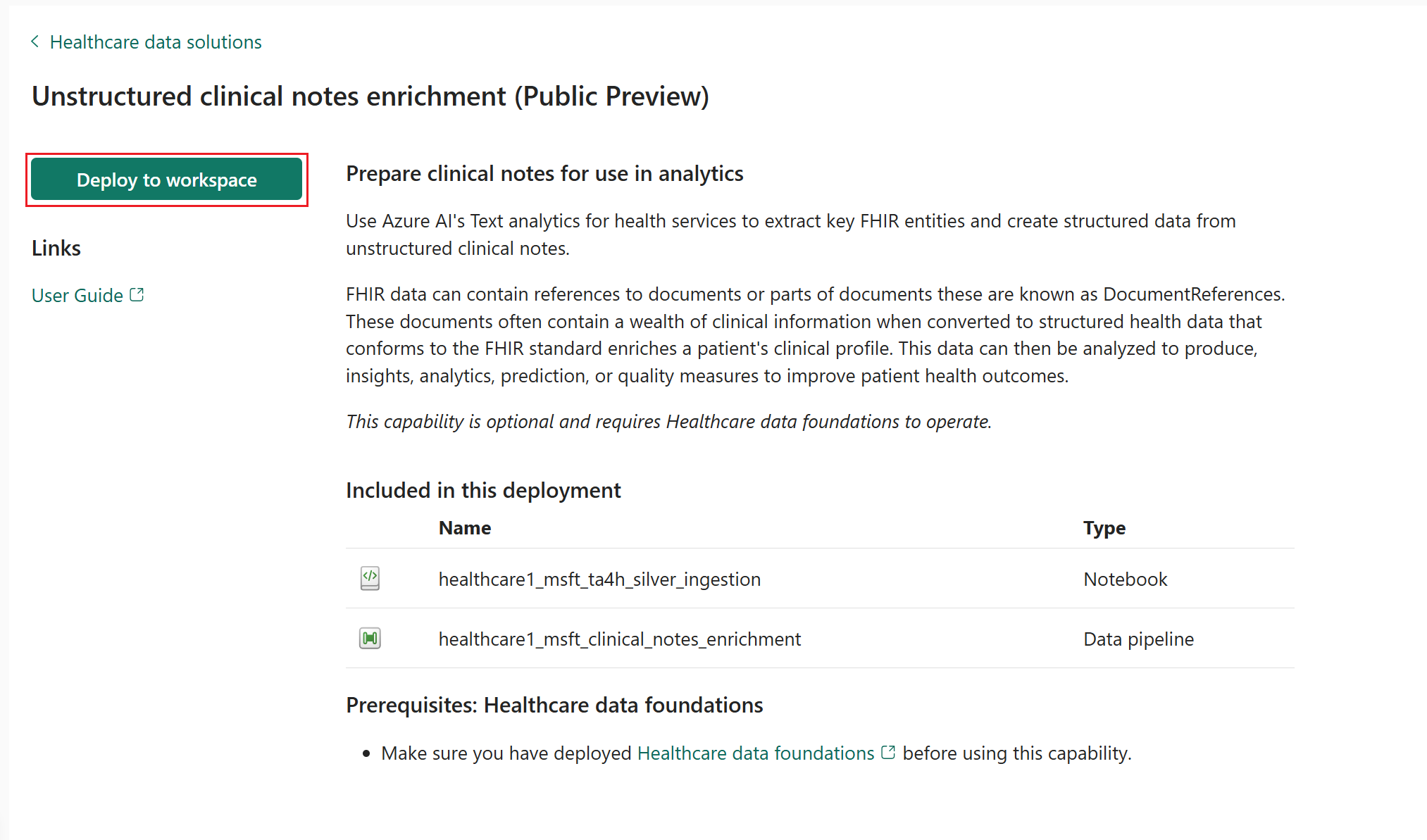
Distribution kan ta några minuter att slutföra. Stäng inte fliken eller webbläsaren medan distributionen pågår. Medan du väntar kan du arbeta på en annan flik.
När distributionen är klar kan du se ett meddelande i meddelandefältet.
Välj Hantera funktion i meddelandefältet för att gå till sidan Kapacitetshantering.
Här kan du visa, konfigurera och hantera de artefakter som distribueras med funktionen.


Artefakter
Möjligheten installerar ett notebook och datapipeline i din miljö för vårddatalösningar.
| Artefakt | Type | Beskrivning |
|---|---|---|
| healthcare#_msft_ta4h_silver_ingestion | Notebook-fil | Använder Azure Text Analytics for Health NLP API för att bearbeta och analysera ostrukturerade textdata. |
| healthcare#_msft_clinical_notes_enrichment | Datapipeline | Kör sekventiellt en serie notebook-filer för att extrahera viktiga FHIR-entiteter (Fast Healthcare Interoperability Resources) från ostrukturerade kliniska anteckningar, strukturera data och lagra resultaten i silversjöhus. |
Granska notebook-konfigurationen
Notebook-filen healthcare#_msft_ta4h_silver_ingestion kör modulen NLPIngestionService i biblioteket med vårddatalösningar och använder tjänster Azure Text Analytics for Health. Den här tjänsten är ett API för naturlig språkbehandling (NLP) som används för att bearbeta och analysera ostrukturerad textdata. Resultaten lagras i sjöhuset healthcare#_msft_silver.
Följande är de viktigaste konfigurationsparametrarna för den här notebook-filen:
NLP-konfiguration: Gör att du kan anpassa NLP-inställningarna så att de överensstämmer med specifika användarkrav.
enable_text_analytics_logs: Växla värdet tillTrueellerFalseför att aktivera eller inaktivera API-loggarna. Standardvärdet anges tillFalse. Mer information om hur du aktiverar loggning, se Aktivera loggar.nlp_source_table_name: Identifierar källtabellen för tjänsten Text Analytics for Health som ska bearbetas.nlp_document_limit: Anger gränsen för antalet dokument som tjänsten Text Analytics for Health kan bearbeta. Standardvärdet är inställt på10med en maximal reserv på 1 000 dokument. Du kan justera detta värde efter behov. Tänk dock på kostnadskonsekvenserna, vilket förklaras i Prismodell.
Den här notebook-filen distribueras med förkonfigurerade värden som krävs för att köra den associerade datapipelinen. Vissa konfigurationsparametrar ärver från den globala konfigurationen. Som standard behöver du inte göra några ändringar i notebook-konfigurationsfiler. Om det behövs kan du öppna notebook och granska konfigurationen.