Självstudie: Identifiera relationer i en semantisk modell med hjälp av semantisk länk
Den här självstudien visar hur du interagerar med Power BI från en Jupyter-anteckningsbok och identifierar relationer mellan tabeller med hjälp av SemPy-biblioteket.
I den här handledningen lär du dig att:
- Identifiera relationer i en semantisk modell (Power BI-datauppsättning) med hjälp av semantisk länks Python-bibliotek (SemPy).
- Använd komponenter i SemPy som stöder integrering med Power BI och hjälper till att automatisera datakvalitetsanalys. Dessa komponenter omfattar:
- FabricDataFrame – en Pandas-liknande struktur som utökas med ytterligare semantisk information.
- Funktioner för att hämta semantiska modeller från en Fabric-arbetsyta till din anteckningsbok.
- Funktioner som automatiserar utvärderingen av hypoteser om funktionella beroenden och som identifierar överträdelser av relationer i semantiska modeller.
Förutsättningar
Skaffa en Microsoft Fabric-prenumeration. Eller registrera dig för en kostnadsfri Microsoft Fabric-utvärderingsversion.
Logga in på Microsoft Fabric.
Använd upplevelseväxlaren längst ner till vänster på din startsida för att byta till Fabric.

Välj Arbetsytor i det vänstra navigeringsfönstret för att hitta och välja din arbetsyta. Den här arbetsytan blir din aktuella arbetsyta.
Ladda ned Customer Profitability Sample.pbix och Customer Profitability Sample (auto).pbix semantiska modeller från github-lagringsplatsen fabric-samples och ladda upp dem till din arbetsyta.
Följ med i anteckningsboken
Notebook-filen powerbi_relationships_tutorial.ipynb följer med denna handledning.
Om du vill öppna den medföljande notebook-filen för den här självstudien följer du anvisningarna i Förbereda systemet för självstudier för datavetenskap importera anteckningsboken till din arbetsyta.
Om du hellre kopierar och klistrar in koden från den här sidan kan du skapa en ny notebook-fil.
Se till att bifoga ett lakehouse till notebook- innan du börjar köra kod.
Konfigurera anteckningsboken
I det här avsnittet konfigurerar du en notebook-miljö med nödvändiga moduler och data.
Installera
SemPyfrån PyPI med hjälp av%pip:s inbyggda installationsfunktion i anteckningsboken.%pip install semantic-linkUtför nödvändiga importer av SemPy-moduler som du behöver senare:
import sempy.fabric as fabric from sempy.relationships import plot_relationship_metadata from sempy.relationships import find_relationships from sempy.fabric import list_relationship_violationsImportera Pandas för att framtvinga ett konfigurationsalternativ som hjälper till med utdataformatering:
import pandas as pd pd.set_option('display.max_colwidth', None)
Utforska semantiska modeller
I den här självstudien används en standardsemantisk modell med exempel Customer Profitability Sample.pbix. En beskrivning av semantikmodellen finns i exempel på kundlönsamhet för Power BI-.
Använd SemPys
list_datasets-funktion för att utforska semantiska modeller på din aktuella arbetsyta:fabric.list_datasets()
För resten av den här anteckningsboken kommer du att använda två versioner av den semantiska modellen 'Customer Profitability Sample'.
- exempel på kundlönsamhet: semantikmodellen som den kommer från Power BI-exempel med fördefinierade tabellrelationer
- exempel på kundlönsamhet (automatiskt): samma data, men relationer är begränsade till de som Power BI skulle identifiera automatiskt.
Extrahera en exempelmodell med sin fördefinierade semantiska modell
Läs in relationer som är fördefinierade och lagrade i den semantiska modellen för Exempel på kundlönsamhet med SemPys
list_relationships-funktion. Den här funktionen listar från tabellobjektmodellen:dataset = "Customer Profitability Sample" relationships = fabric.list_relationships(dataset) relationshipsVisualisera
relationshipsDataFrame som en graf med hjälp av SemPysplot_relationship_metadatafunktion:plot_relationship_metadata(relationships)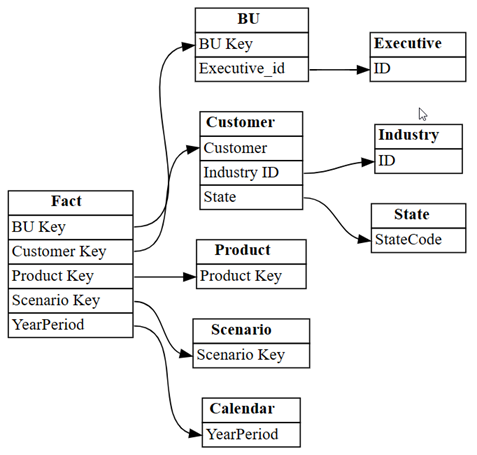

Det här diagrammet visar "grundsanningen" för relationer mellan tabeller i den här semantiska modellen, eftersom den återspeglar hur de definierades i Power BI av en ämnesexpert.
Identifiering av komplementrelationer
Om du började med relationer som Power BI automatiskt har identifierat skulle du ha en mindre uppsättning.
Visualisera de relationer som Power BI automatiskt har definierat i den semantiska modellen:
dataset = "Customer Profitability Sample (auto)" autodetected = fabric.list_relationships(dataset) plot_relationship_metadata(autodetected)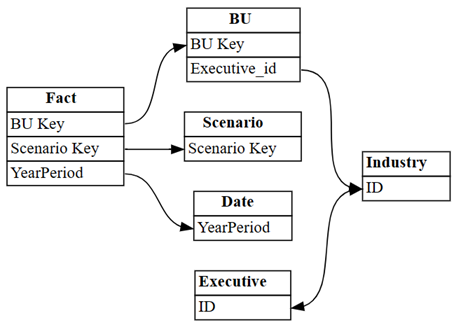
Power BI:s autodetektering missade många relationer. Dessutom är två av de automatiskt upptäckta relationerna semantiskt felaktiga:
-
Executive[ID]->Industry[ID] -
BU[Executive_id]->Industry[ID]
-
Skriv ut relationerna som en tabell:
autodetectedFelaktiga relationer till tabellen
Industryvisas i rader med index 3 och 4. Använd den här informationen om du vill ta bort dessa rader.Ignorera de felaktigt identifierade relationerna.
autodetected.drop(index=[3,4], inplace=True) autodetectedNu har du rätt, men ofullständiga relationer.
Visualisera dessa ofullständiga relationer med hjälp av
plot_relationship_metadata:plot_relationship_metadata(autodetected)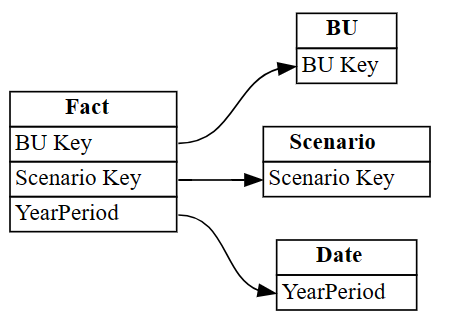
Läs in alla tabeller från den semantiska modellen med hjälp av SemPys funktioner
list_tablesochread_table:tables = {table: fabric.read_table(dataset, table) for table in fabric.list_tables(dataset)['Name']} tables.keys()Hitta relationer mellan tabeller med hjälp av
find_relationshipsoch granska loggutdata för att få insikter om hur den här funktionen fungerar:suggested_relationships_all = find_relationships( tables, name_similarity_threshold=0.7, coverage_threshold=0.7, verbose=2 )Visualisera nyligen identifierade relationer:
plot_relationship_metadata(suggested_relationships_all)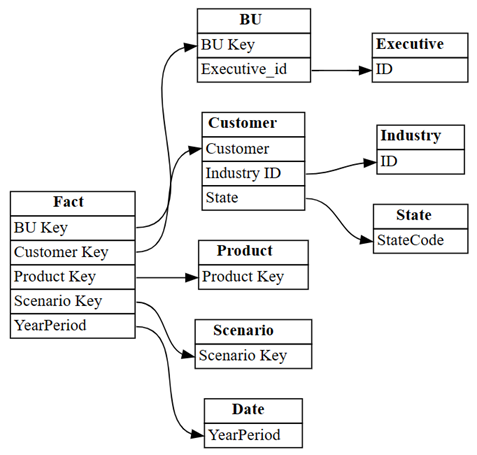
SemPy kunde identifiera alla relationer.
Använd parametern
excludeför att begränsa sökningen till ytterligare relationer som inte identifierades tidigare:additional_relationships = find_relationships( tables, exclude=autodetected, name_similarity_threshold=0.7, coverage_threshold=0.7 ) additional_relationships



Verifiera relationerna
Läs först in data från kundlönsamhetsexempel semantiska modellen:
dataset = "Customer Profitability Sample" tables = {table: fabric.read_table(dataset, table) for table in fabric.list_tables(dataset)['Name']} tables.keys()Sök efter överlappning av primär- och sekundärnyckelvärden med hjälp av funktionen
list_relationship_violations. Ange utdata för funktionenlist_relationshipssom indata tilllist_relationship_violations:list_relationship_violations(tables, fabric.list_relationships(dataset))Relationsöverträdelserna ger några intressanta insikter. Ett av sju värden i
Fact[Product Key]finns till exempel inte iProduct[Product Key]och den här saknade nyckeln är50.
Undersökande dataanalys är en spännande process, och det är även datarensning. Det finns alltid något som data döljer, beroende på hur du ser på dem, vad du vill fråga och så vidare. Semantisk länk ger dig nya verktyg som du kan använda för att uppnå mer med dina data.
Relaterat innehåll
Kolla in andra guider för semantiska länkar och SemPy.
- Självstudie: Rensa data med funktionella beroenden
- Självstudie: Analysera funktionella beroenden i en exempelsemantisk modell
- Självstudie: Extrahera och beräkna Power BI-mått från en Jupyter Notebook-
- Självstudie: Identifiera relationer i datauppsättningen Synthea med hjälp av semantisk länk
- Självstudie: Verifiera data med SemPy och Great Expectations (GX)