Självstudie: Validera data med SemPy och Great Expectations (GX)
I den här självstudien får du lära dig hur du använder SemPy tillsammans med Great Expectations (GX) för att utföra dataverifiering på Power BI-semantiska modeller.
Den här handledningen visar hur du:
- Verifiera begränsningar för en datauppsättning i din Fabric-arbetsyta med Great Expectations Fabric-datakälla (byggd på semantisk länk).
- Konfigurera en GX-datakontext, datatillgångar och förväntningar.
- Visa valideringsresultat med en GX-kontrollpunkt.
- Använd semantisk länk för att analysera rådata.
Förutsättningar
Skaffa en Microsoft Fabric-prenumeration. Eller registrera dig för en kostnadsfri Microsoft Fabric-utvärderingsversion.
Logga in på Microsoft Fabric.
Använd upplevelseväxlaren längst ned till vänster på startsidan för att växla till Fabric.

- Välj Arbetsytor i det vänstra navigeringsfönstret för att hitta och välja din arbetsyta. Den här arbetsytan blir din aktuella arbetsyta.
- Ladda ned pbix.pbix--filenExempel på detaljhandelsanalys.
- På din arbetsyta väljer du Importera>rapport eller sidnumrerad rapport>Från den här datorn för att ladda upp pbix.pb ix-filen detaljhandelsanalys till din arbetsyta.
Följ med i anteckningsboken
great_expectations_tutorial.ipynb är anteckningsboken som hör till denna handledning.
Om du vill öppna den medföljande notebook-filen för den här självstudien, följer du anvisningarna i Förbered ditt system för självstudier i datavetenskap och importerar anteckningsboken till din arbetsyta.
Om du hellre kopierar och klistrar in koden från den här sidan kan du skapa en ny notebook-fil.
Se till att bifoga ett lakehouse till notebooken innan du kör igång med kod.
Konfigurera anteckningsboken
I det här avsnittet konfigurerar du en notebook-miljö med nödvändiga moduler och data.
- Installera
SemPyoch relevantaGreat Expectations-bibliotek från PyPI med hjälp av den%pipin-line-installationsfunktionen i notebooken.
# install libraries
%pip install semantic-link 'great-expectations<1.0' great_expectations_experimental great_expectations_zipcode_expectations
# load %%dax cell magic
%load_ext sempy
- Utför nödvändiga importer av moduler som du behöver senare:
import great_expectations as gx
from great_expectations.expectations.expectation import ExpectationConfiguration
from great_expectations_zipcode_expectations.expectations import expect_column_values_to_be_valid_zip5
Konfigurera GX-datakontext och datakälla
För att komma igång med Great Expectations måste du först konfigurera en GX datakontext. Kontexten fungerar som en startpunkt för GX-åtgärder och innehåller alla relevanta konfigurationer.
context = gx.get_context()
Nu kan du lägga till din Fabric-datauppsättning i detta sammanhang som en datakälla för att börja interagera med datan. I den här självstudien används en standard semantisk Power BI-exempelmodell Pbix-fil med exempel på detaljhandelsanalys.
ds = context.sources.add_fabric_powerbi("Retail Analysis Data Source", dataset="Retail Analysis Sample PBIX")
Ange datatillgångar
Definiera datatillgångar för att ange den delmängd av data som du vill arbeta med. Tillgången kan vara så enkel som fullständiga tabeller eller vara lika komplex som en anpassad DAX-fråga (Data Analysis Expressions).
Här lägger du till flera tillgångar:
- Power BI-tabell
- Power BI-mått
- Anpassad DAX-fråga
- DMV-fråga (Dynamic Management View)
Power BI-tabell
Lägg till en Power BI-tabell som en datatillgång.
ds.add_powerbi_table_asset("Store Asset", table="Store")
Power BI-mått
Om datauppsättningen innehåller förkonfigurerade mått lägger du till måtten som tillgångar som följer ett liknande API som SemPys evaluate_measure.
ds.add_powerbi_measure_asset(
"Total Units Asset",
measure="TotalUnits",
groupby_columns=["Time[FiscalYear]", "Time[FiscalMonth]"]
)
DAX
Om du vill definiera egna mått eller ha mer kontroll över specifika rader kan du lägga till en DAX-tillgång med en anpassad DAX-fråga. Här definierar vi ett Total Units Ratio mått genom att dela upp två befintliga mått.
ds.add_powerbi_dax_asset(
"Total Units YoY Asset",
dax_string=
"""
EVALUATE SUMMARIZECOLUMNS(
'Time'[FiscalYear],
'Time'[FiscalMonth],
"Total Units Ratio", DIVIDE([Total Units This Year], [Total Units Last Year])
)
"""
)
DMV-fråga
I vissa fall kan det vara bra att använda DMV-beräkningar (Dynamic Management View) som en del av dataverifieringsprocessen. Du kan till exempel hålla reda på antalet överträdelser av referensintegritet i din datauppsättning. Mer information finns i Rensa data = snabbare rapporter.
ds.add_powerbi_dax_asset(
"Referential Integrity Violation",
dax_string=
"""
SELECT
[Database_name],
[Dimension_Name],
[RIVIOLATION_COUNT]
FROM $SYSTEM.DISCOVER_STORAGE_TABLES
"""
)
Förväntningar
Om du vill lägga till specifika begränsningar i tillgångarna måste du först konfigurera Expectation Suites. När du har lagt till enskilda Förväntningar till varje svit kan du sedan uppdatera datakontexten som konfigurerats i början med den nya sviten. En fullständig lista över tillgängliga förväntningar finns i GX Expectation Gallery.
Börja med att lägga till en "Retail Store Suite" med två förväntningar:
- ett giltigt postnummer
- en tabell med radantal mellan 80 och 200
suite_store = context.add_expectation_suite("Retail Store Suite")
suite_store.add_expectation(ExpectationConfiguration("expect_column_values_to_be_valid_zip5", { "column": "PostalCode" }))
suite_store.add_expectation(ExpectationConfiguration("expect_table_row_count_to_be_between", { "min_value": 80, "max_value": 200 }))
context.add_or_update_expectation_suite(expectation_suite=suite_store)
TotalUnits mått
Lägg till en Retail Measure Suite med ett krav:
- Kolumnvärdena ska vara större än 50 000
suite_measure = context.add_expectation_suite("Retail Measure Suite")
suite_measure.add_expectation(ExpectationConfiguration(
"expect_column_values_to_be_between",
{
"column": "TotalUnits",
"min_value": 50000
}
))
context.add_or_update_expectation_suite(expectation_suite=suite_measure)
Total Units Ratio DAX
Lägg till en "Retail DAX Suite" med en förväntan:
- Kolumnvärden för Total Units Ratio ska vara mellan 0,8 och 1,5
suite_dax = context.add_expectation_suite("Retail DAX Suite")
suite_dax.add_expectation(ExpectationConfiguration(
"expect_column_values_to_be_between",
{
"column": "[Total Units Ratio]",
"min_value": 0.8,
"max_value": 1.5
}
))
context.add_or_update_expectation_suite(expectation_suite=suite_dax)
Överträdelser av referensintegritet (DMV)
Lägg till en "Retail DMV Suite" med ett förbehåll:
- Variabeln RIVIOLATION_COUNT ska vara 0
suite_dmv = context.add_expectation_suite("Retail DMV Suite")
# There should be no RI violations
suite_dmv.add_expectation(ExpectationConfiguration(
"expect_column_values_to_be_in_set",
{
"column": "RIVIOLATION_COUNT",
"value_set": [0]
}
))
context.add_or_update_expectation_suite(expectation_suite=suite_dmv)
Validering
Om du vill köra de angivna förväntningarna mot data skapar du först en Kontrollpunkt och lägger till den i kontexten. Mer information om kontrollpunktskonfiguration finns i arbetsflöde för dataverifiering.
checkpoint_config = {
"name": f"Retail Analysis Checkpoint",
"validations": [
{
"expectation_suite_name": "Retail Store Suite",
"batch_request": {
"datasource_name": "Retail Analysis Data Source",
"data_asset_name": "Store Asset",
},
},
{
"expectation_suite_name": "Retail Measure Suite",
"batch_request": {
"datasource_name": "Retail Analysis Data Source",
"data_asset_name": "Total Units Asset",
},
},
{
"expectation_suite_name": "Retail DAX Suite",
"batch_request": {
"datasource_name": "Retail Analysis Data Source",
"data_asset_name": "Total Units YoY Asset",
},
},
{
"expectation_suite_name": "Retail DMV Suite",
"batch_request": {
"datasource_name": "Retail Analysis Data Source",
"data_asset_name": "Referential Integrity Violation",
},
},
],
}
checkpoint = context.add_checkpoint(
**checkpoint_config
)
Kör nu kontrollpunkten och extrahera resultatet som en Pandas DataFrame för enkel formatering.
result = checkpoint.run()
Bearbeta och skriv ut dina resultat.
import pandas as pd
data = []
for run_result in result.run_results:
for validation_result in result.run_results[run_result]["validation_result"]["results"]:
row = {
"Batch ID": run_result.batch_identifier,
"type": validation_result.expectation_config.expectation_type,
"success": validation_result.success
}
row.update(dict(validation_result.result))
data.append(row)
result_df = pd.DataFrame.from_records(data)
result_df[["Batch ID", "type", "success", "element_count", "unexpected_count", "partial_unexpected_list"]]

Från dessa resultat kan du se att alla dina förväntningar klarade valideringen, förutom "Totalt antal enheter jämfört med föregående år" som du definierade via en anpassad DAX-fråga.
Diagnostik
Med hjälp av semantisk länk kan du hämta källdata för att förstå vilka exakta år som ligger utom räckhåll. Semantisk länk ger en infogad magi för att köra DAX-frågor. Använd semantisk länk för att köra samma fråga som du skickade till GX-datatillgången och visualisera de resulterande värdena.
%%dax "Retail Analysis Sample PBIX"
EVALUATE SUMMARIZECOLUMNS(
'Time'[FiscalYear],
'Time'[FiscalMonth],
"Total Units Ratio", DIVIDE([Total Units This Year], [Total Units Last Year])
)
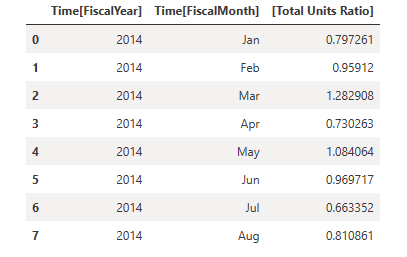
Spara dessa resultat i en DataFrame.
df = _
Rita resultatet.
import matplotlib.pyplot as plt
df["Total Units % Change YoY"] = (df["[Total Units Ratio]"] - 1)
df.set_index(["Time[FiscalYear]", "Time[FiscalMonth]"]).plot.bar(y="Total Units % Change YoY")
plt.axhline(0)
plt.axhline(-0.2, color="red", linestyle="dotted")
plt.axhline( 0.5, color="red", linestyle="dotted")
None
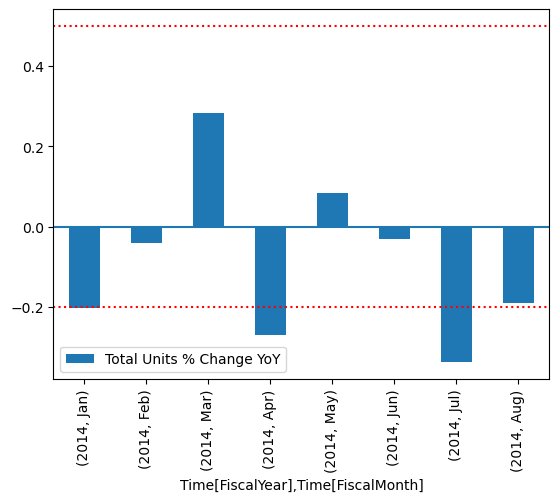
Från diagrammet kan du se att april och juli var något utom räckhåll och sedan kan vidta ytterligare åtgärder för att undersöka.
Lagra GX-konfiguration
När data i datamängden ändras över tid kanske du vill köra GX-valideringarna igen som du precis har utfört. För närvarande existerar datakontexten (som innehåller de anslutna datatillgångarna, förväntningssviterna och kontrollpunkten) tillfälligt, men den kan konverteras till en filkontext för framtida användning. Du kan också instansiera en filkontext (se Instansiera en datakontext).
context = context.convert_to_file_context()
Nu när du har sparat kontexten kopierar du katalogen gx till ditt lakehouse.
Viktig
Den här cellen förutsätter att du lagt till ett lakehouse till anteckningsboken. Om det inte finns något anslutet lakehouse, visas inget fel, men du kommer inte heller senare att kunna få tillgång till kontexten. Om du lägger till ett lakehouse nu startas kerneln om, så du måste köra hela notebook-filen igen för att komma tillbaka till den här punkten.
# copy GX directory to attached lakehouse
!cp -r gx/ /lakehouse/default/Files/gx
Nu kan framtida kontexter skapas med context = gx.get_context(project_root_dir="<your path here>") för att använda alla konfigurationer från den här handledningen.
I en ny notebook-fil bifogar du till exempel samma lakehouse och använder context = gx.get_context(project_root_dir="/lakehouse/default/Files/gx") för att hämta kontexten.
Relaterat innehåll
Kolla in andra handledningar för semantisk länk eller SemPy:
- Självstudie: Rensa data med funktionella beroenden
- Självstudie: Analysera funktionella beroenden i en exempelsemantisk modell
- Självstudie: Extrahera och beräkna Power BI-mått från en Jupyter Notebook-
- Självstudie: Identifiera relationer i en semantisk modell med hjälp av semantisk länk
- Självstudie: Identifiera relationer i datauppsättningen Synthea med hjälp av semantisk länk