Lakehouse-scenario från slutpunkt till slutpunkt: översikt och arkitektur
Microsoft Fabric är en allt-i-ett-analyslösning för företag som omfattar allt från dataflytt till datavetenskap, realtidsanalys och business intelligence. Det erbjuder en omfattande uppsättning tjänster, inklusive datasjö, datateknik och dataintegrering, allt på ett och samma ställe. Mer information finns i Vad är Microsoft Fabric?
I den här självstudien går vi igenom ett scenario från slutpunkt till slutpunkt från datainsamling till dataförbrukning. Det hjälper dig att skapa en grundläggande förståelse för Fabric, inklusive de olika upplevelserna och hur de integreras, samt de professionella och medborgarutvecklarupplevelser som ingår i arbetet med den här plattformen. Den här självstudien är inte avsedd att vara en referensarkitektur, en fullständig lista över funktioner och funktioner eller en rekommendation om specifika metodtips.
Lakehouse-scenario från slutpunkt till slutpunkt
Traditionellt har organisationer skapat moderna informationslager för sina transaktionella och strukturerade dataanalysbehov. Och data lakehouses för stordata (halv/ostrukturerade) dataanalysbehov. Dessa två system kördes parallellt, vilket skapade silor, dataduplicering och ökade totala ägandekostnader.
Med Infrastruktur med dess sammanslagning av datalager och standardisering i Delta Lake-format kan du eliminera silor, ta bort dataduplicering och drastiskt minska den totala ägandekostnaden.
Med den flexibilitet som erbjuds av Fabric kan du implementera antingen lakehouse- eller datalagerarkitekturer eller kombinera dem för att få ut det bästa av båda med enkel implementering. I den här självstudien ska du ta ett exempel på en detaljhandelsorganisation och bygga dess lakehouse från början till slut. Den använder arkitekturen medallion där bronslagret har rådata, silverskiktet har verifierade och deduplicerade data och guldskiktet har mycket förfinade data. Du kan använda samma metod för att implementera ett sjöhus för alla organisationer från vilken bransch som helst.
I den här självstudien beskrivs hur en utvecklare på det fiktiva wide world importers-företaget från detaljhandelsdomänen utför följande steg:
Logga in på ditt Power BI-konto och registrera dig för den kostnadsfria Utvärderingsversionen av Microsoft Fabric. Om du inte har någon Power BI-licens registrera dig för en kostnadsfri Fabric-licens så kan du sedan starta Fabric-utvärderingen.
Skapa och implementera ett lakehouse från slutpunkt till slutpunkt för din organisation:
- Skapa en infrastrukturarbetsyta.
- Skapa ett sjöhus.
- Mata in data, transformera data och läs in dem i lakehouse. Du kan också utforska OneLake, en kopia av dina data i lakehouse-läget och SQL-analysslutpunktsläget.
- Anslut till lakehouse med hjälp av SQL-analysslutpunkten och Skapa en Power BI-rapport med DirectLake för att analysera försäljningsdata över olika dimensioner.
- Du kan också orkestrera och schemalägga datainmatning och transformeringsflöde med en pipeline.
Rensa resurser genom att ta bort arbetsytan och andra objekt.
Arkitektur
Följande bild visar lakehouse-arkitekturen från slutpunkt till slutpunkt. De komponenter som ingår beskrivs i följande lista.
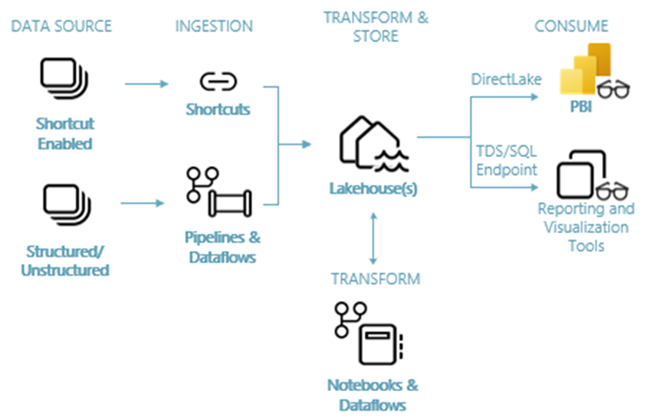
Datakällor: Infrastrukturresurser gör det snabbt och enkelt att ansluta till Azure Data Services, samt andra molnbaserade plattformar och lokala datakällor, för effektiv datainmatning.
Inmatning: Du kan snabbt skapa insikter för din organisation med mer än 200 interna anslutningsappar. Dessa anslutningsappar är integrerade i Fabric-pipelinen och använder den användarvänliga dra och släpp-datatransformeringen med dataflödet. Med genvägsfunktionen i Infrastrukturresurser kan du dessutom ansluta till befintliga data, utan att behöva kopiera eller flytta dem.
Transformera och lagra: Infrastrukturresurser standardiseras i Delta Lake-format. Vilket innebär att alla Fabric-motorer kan komma åt och manipulera samma datauppsättning som lagras i OneLake utan att duplicera data. Det här lagringssystemet ger flexibiliteten att bygga sjöhus med hjälp av en medaljongarkitektur eller ett datanät, beroende på organisationens krav. Du kan välja mellan en upplevelse med låg kod eller ingen kod för datatransformering, med antingen pipelines/dataflöden eller notebook/Spark för en kod-första-upplevelse.
Förbruka: Power BI kan använda data från Lakehouse för rapportering och visualisering. Varje Lakehouse har en inbyggd TDS-slutpunkt som kallas SQL-analysslutpunkten för enkel anslutning och frågekörning av data i Lakehouse-tabellerna från andra rapporteringsverktyg. SQL-analysslutpunkten ger användarna funktionerna för SQL-anslutning.
Exempeldatauppsättning
I den här självstudien används exempeldatabasen Wide World Importers (WWI) som du importerar till lakehouse i nästa självstudie. För lakehouse-scenariot från slutpunkt till slutpunkt har vi genererat tillräckligt med data för att utforska skalnings- och prestandafunktionerna i Fabric-plattformen.
Wide World Importers (WWI) är en importör och distributör av varor i grossistledet från San Francisco Bay-området. Som grossist inkluderar WWI:s kunder främst företag som säljer vidare till individer. WWI säljer till detaljhandelskunder över hela USA inklusive specialbutiker, stormarknader, datorbutiker, turistattraktionbutiker och vissa individer. WWI säljer också till andra grossister via ett nätverk av agenter som marknadsför produkterna för WWI: s räkning. Mer information om företagets profil och drift finns i Wide World Importers-exempeldatabaser för Microsoft SQL.
I allmänhet hämtas data från transaktionssystem eller verksamhetsspecifika program till ett sjöhus. Men för enkelhetens skull i den här självstudien använder vi den dimensionsmodell som tillhandahålls av WWI som vår första datakälla. Vi använder dem som källa för att mata in data i ett sjöhus och transformera dem genom olika faser (brons, silver och guld) i en medaljongarkitektur.
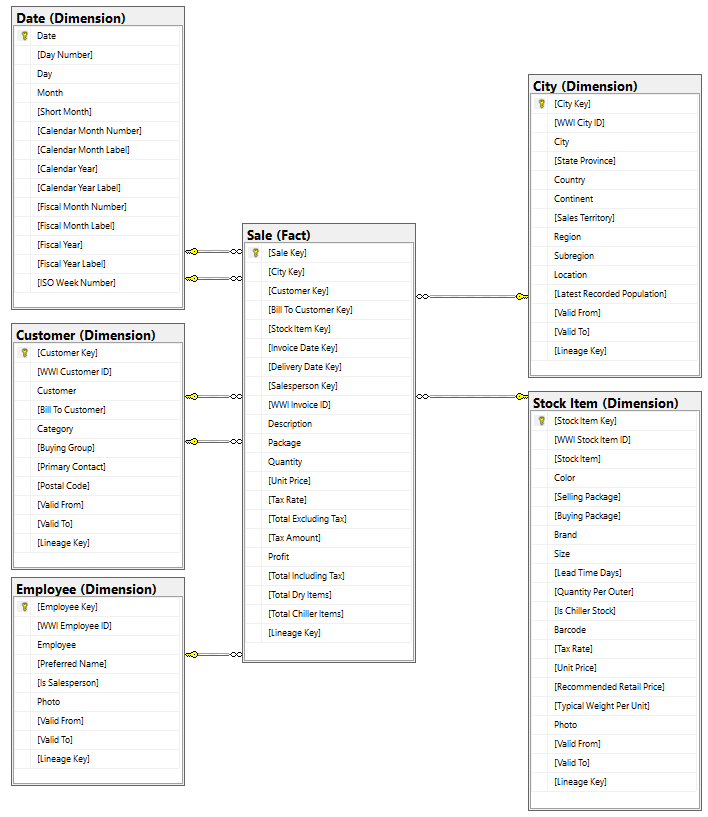
Datamodell
WWI-dimensionsmodellen innehåller många faktatabeller, men i den här självstudien använder vi tabellen Sales fact och dess korrelerade dimensioner. I följande exempel visas WWI-datamodellen:
Data- och transformeringsflöde
Som vi beskrev tidigare använder vi exempeldata från WWI-exempeldata (Wide World Importers) för att skapa det här sjöhuset från slutpunkt till slutpunkt. I den här implementeringen lagras exempeldata i ett Azure Data Storage-konto i Parquet-filformat för alla tabeller. Men i verkliga scenarier kommer data vanligtvis från olika källor och i olika format.
Följande bild visar källan, målet och datatransformeringen:
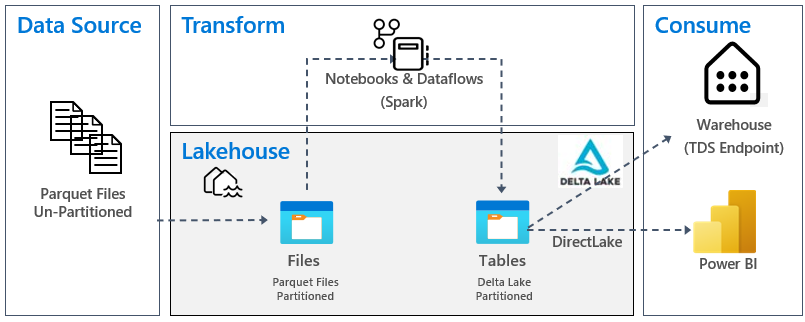
Datakälla: Källdata är i Parquet-filformat och i en icke-partitionerad struktur. Den lagras i en mapp för varje tabell. I den här självstudien konfigurerar vi en pipeline för att mata in fullständiga historiska data eller engångsdata till lakehouse.
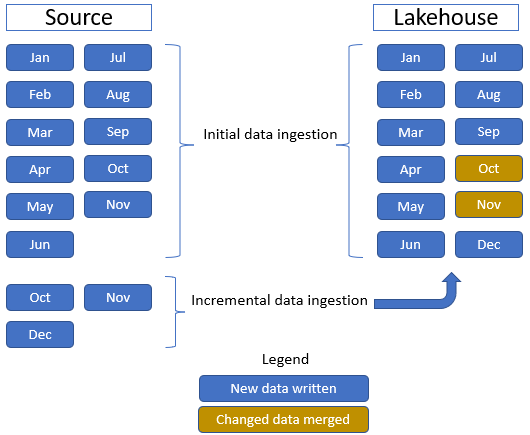
I den här självstudien använder vi tabellen Försäljning fakta, som har en överordnad mapp med historiska data i 11 månader (med en undermapp för varje månad) och en annan mapp som innehåller inkrementella data i tre månader (en undermapp för varje månad). Under den inledande datainmatningen matas 11 månaders data in i lakehouse-tabellen. Men när inkrementella data tas emot innehåller de uppdaterade data för okt och nov och nya data för dec. Okt- och Nov-data sammanfogas med befintliga data och de nya dec-data skrivs till lakehouse-tabellen enligt följande bild:
Lakehouse: I den här självstudien skapar du ett sjöhus, matar in data i filavsnittet i lakehouse och skapar sedan delta lake-tabeller i avsnittet Tabeller i lakehouse.
Transformera: För förberedelse och transformering av data ser du två olika metoder. Vi demonstrerar användningen av Notebooks/Spark för användare som föredrar en kod-första upplevelse och använder pipelines/dataflöde för användare som föredrar en lågkods- eller kodfri upplevelse.
Förbruka: För att demonstrera dataförbrukning kan du se hur du kan använda DirectLake-funktionen i Power BI för att skapa rapporter, instrumentpaneler och direkt fråga efter data från lakehouse. Dessutom visar vi hur du kan göra dina data tillgängliga för rapporteringsverktyg från tredje part med hjälp av TDS/SQL-analysslutpunkten. Med den här slutpunkten kan du ansluta till lagret och köra SQL-frågor för analys.