Självstudiekurs om Lakehouse: Förbereda och transformera data i lakehouse
I den här självstudien använder du notebook-filer med Spark-körning för att transformera och förbereda rådata i lakehouse.
Förutsättningar
Om du inte har ett sjöhus som innehåller data måste du:
Förbereda data
Från de föregående självstudierna har vi rådata som matas in från källan till avsnittet Filer i lakehouse. Nu kan du transformera dessa data och förbereda dem för att skapa Delta-tabeller.
Ladda ned anteckningsböckerna från mappen Lakehouse Tutorial Source Code .
Välj Dataingenjör ing längst ned till vänster på skärmen.

Välj Importera anteckningsbok från avsnittet Nytt överst på landningssidan.
Välj Ladda upp från fönstret Importera status som öppnas till höger på skärmen.
Välj alla anteckningsböcker som du laddade ned i det första steget i det här avsnittet.
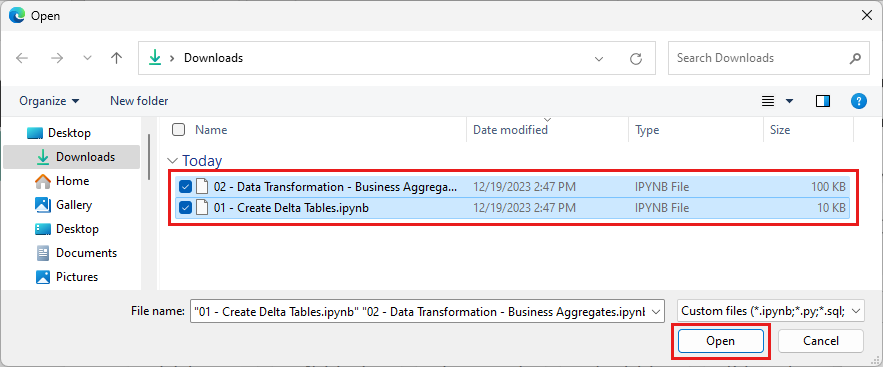
Välj Öppna. Ett meddelande som anger status för importen visas i det övre högra hörnet i webbläsarfönstret.
När importen har slutförts går du till objektvyn för arbetsytan och ser de nyligen importerade anteckningsböckerna. Välj wwilakehouse lakehouse för att öppna det.
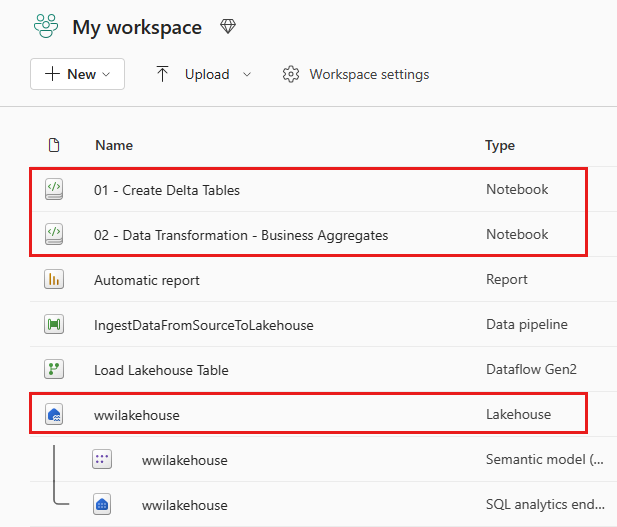
När wwilakehouse lakehouse har öppnats väljer du Öppna anteckningsbok>Befintlig anteckningsbok på den översta navigeringsmenyn.
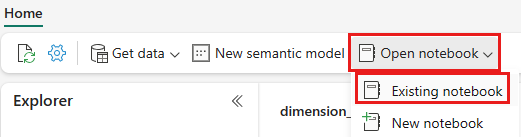
I listan över befintliga notebook-filer väljer du anteckningsboken 01 – Skapa deltatabeller och väljer Öppna.
I den öppna anteckningsboken i Lakehouse Explorer ser du att anteckningsboken redan är länkad till ditt öppnade lakehouse.
Kommentar
Infrastrukturresurser tillhandahåller V-beställningsfunktionen för att skriva optimerade Delta Lake-filer. V-ordningen förbättrar ofta komprimering med tre till fyra gånger och upp till 10 gånger prestandaacceleration över Delta Lake-filerna som inte är optimerade. Spark i Fabric optimerar dynamiskt partitioner samtidigt som filer genereras med en standardstorlek på 128 MB. Målfilens storlek kan ändras enligt arbetsbelastningskraven med hjälp av konfigurationer.
Med funktionen optimera skrivning minskar Apache Spark-motorn antalet skrivna filer och syftar till att öka den enskilda filstorleken för de skrivna data.
Innan du skriver data som Delta lake-tabeller i avsnittet Tabeller i lakehouse använder du två infrastrukturresurser (V-ordning och Optimera skrivning) för optimerad dataskrivning och för bättre läsprestanda. Om du vill aktivera dessa funktioner i sessionen anger du dessa konfigurationer i den första cellen i notebook-filen.
Om du vill starta anteckningsboken och köra alla celler i följd väljer du Kör alla i det övre menyfliksområdet (under Start). Om du bara vill köra kod från en specifik cell väljer du ikonen Kör som visas till vänster om cellen vid hovring eller trycker på SKIFT + RETUR på tangentbordet medan kontrollen finns i cellen.
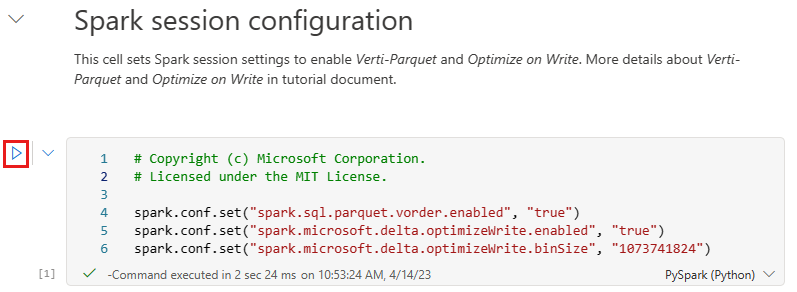
När du körde en cell behövde du inte ange den underliggande Spark-poolen eller klusterinformationen eftersom Fabric tillhandahåller dem via livepoolen. Varje Infrastrukturarbetsyta levereras med en Standard Spark-pool, kallad Live Pool. Det innebär att när du skapar notebook-filer behöver du inte bekymra dig om att ange några Spark-konfigurationer eller klusterinformation. När du kör det första notebook-kommandot är den aktiva poolen igång om några sekunder. Spark-sessionen upprättas och den börjar köra koden. Efterföljande kodkörning är nästan omedelbar i den här notebook-filen medan Spark-sessionen är aktiv.
Därefter läser du rådata från avsnittet Filer i lakehouse och lägger till fler kolumner för olika datumdelar som en del av omvandlingen. Slutligen använder du partitionen By Spark API för att partitioneras data innan du skriver dem som Delta-tabellformat baserat på de nyligen skapade datadelskolumnerna (År och Kvartal).
from pyspark.sql.functions import col, year, month, quarter table_name = 'fact_sale' df = spark.read.format("parquet").load('Files/wwi-raw-data/WideWorldImportersDW/parquet/full/fact_sale_1y_full') df = df.withColumn('Year', year(col("InvoiceDateKey"))) df = df.withColumn('Quarter', quarter(col("InvoiceDateKey"))) df = df.withColumn('Month', month(col("InvoiceDateKey"))) df.write.mode("overwrite").format("delta").partitionBy("Year","Quarter").save("Tables/" + table_name)När faktatabellerna har lästs in kan du gå vidare till att läsa in data för resten av dimensionerna. I följande cell skapas en funktion för att läsa rådata från avsnittet Filer i lakehouse för vart och ett av tabellnamnen som skickas som en parameter. Därefter skapas en lista över dimensionstabeller. Slutligen loopar den igenom listan över tabeller och skapar en Delta-tabell för varje tabellnamn som läse från indataparametern. Observera att skriptet släpper kolumnen med namnet
Photoi det här exemplet eftersom kolumnen inte används.from pyspark.sql.types import * def loadFullDataFromSource(table_name): df = spark.read.format("parquet").load('Files/wwi-raw-data/WideWorldImportersDW/parquet/full/' + table_name) df = df.drop("Photo") df.write.mode("overwrite").format("delta").save("Tables/" + table_name) full_tables = [ 'dimension_city', 'dimension_customer', 'dimension_date', 'dimension_employee', 'dimension_stock_item' ] for table in full_tables: loadFullDataFromSource(table)Om du vill verifiera de skapade tabellerna högerklickar du och väljer uppdatera på wwilakehouse lakehouse. Tabellerna visas.
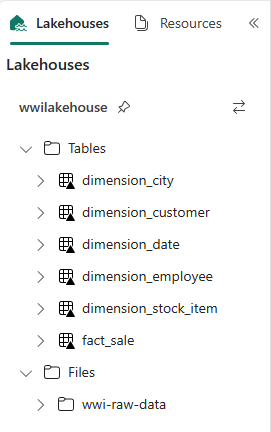
Gå till objektvyn på arbetsytan igen och välj wwilakehouse lakehouse för att öppna den.
Öppna nu den andra anteckningsboken. I lakehouse-vyn väljer du Öppna anteckningsbok>Befintlig anteckningsbok i menyfliksområdet.
I listan över befintliga notebook-filer väljer du anteckningsboken 02 – Datatransformering – Business för att öppna den.
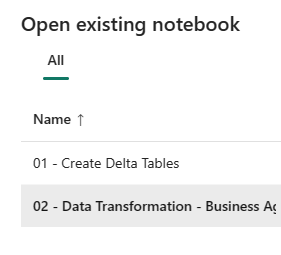
I den öppna anteckningsboken i Lakehouse Explorer ser du att anteckningsboken redan är länkad till ditt öppnade lakehouse.
En organisation kan ha datatekniker som arbetar med Scala/Python och andra datatekniker som arbetar med SQL (Spark SQL eller T-SQL), som alla arbetar med samma kopia av data. Infrastrukturresurser gör det möjligt för dessa olika grupper, med varierande erfarenhet och önskemål, att arbeta och samarbeta. De två olika metoderna transformerar och genererar företagsaggregeringar. Du kan välja den som passar dig eller blanda och matcha dessa metoder baserat på dina önskemål utan att kompromissa med prestandan:
Metod nr 1 – Använd PySpark för att koppla och aggregera data för att generera företagsaggregeringar. Den här metoden är att föredra framför någon med en programmeringsbakgrund (Python eller PySpark).
Metod nr 2 – Använd Spark SQL för att koppla och aggregera data för att generera företagsaggregeringar. Den här metoden är att föredra framför någon med SQL-bakgrund och övergå till Spark.
Metod nr 1 (sale_by_date_city) – Använd PySpark för att koppla och aggregera data för att generera företagsaggregeringar. Med följande kod skapar du tre olika Spark-dataramar, som var och en refererar till en befintlig Delta-tabell. Sedan ansluter du dessa tabeller med hjälp av dataramarna, grupperar efter för att generera aggregering, byter namn på några av kolumnerna och skriver den slutligen som en Delta-tabell i avsnittet Tabeller i lakehouse för att spara med data.
I den här cellen skapar du tre olika Spark-dataramar, som var och en refererar till en befintlig Delta-tabell.
df_fact_sale = spark.read.table("wwilakehouse.fact_sale") df_dimension_date = spark.read.table("wwilakehouse.dimension_date") df_dimension_city = spark.read.table("wwilakehouse.dimension_city")Lägg till följande kod i samma cell för att ansluta dessa tabeller med hjälp av de dataramar som skapades tidigare. Gruppera efter för att generera sammansättning, byt namn på några av kolumnerna och skriv den slutligen som en Delta-tabell i avsnittet Tabeller i lakehouse.
sale_by_date_city = df_fact_sale.alias("sale") \ .join(df_dimension_date.alias("date"), df_fact_sale.InvoiceDateKey == df_dimension_date.Date, "inner") \ .join(df_dimension_city.alias("city"), df_fact_sale.CityKey == df_dimension_city.CityKey, "inner") \ .select("date.Date", "date.CalendarMonthLabel", "date.Day", "date.ShortMonth", "date.CalendarYear", "city.City", "city.StateProvince", "city.SalesTerritory", "sale.TotalExcludingTax", "sale.TaxAmount", "sale.TotalIncludingTax", "sale.Profit")\ .groupBy("date.Date", "date.CalendarMonthLabel", "date.Day", "date.ShortMonth", "date.CalendarYear", "city.City", "city.StateProvince", "city.SalesTerritory")\ .sum("sale.TotalExcludingTax", "sale.TaxAmount", "sale.TotalIncludingTax", "sale.Profit")\ .withColumnRenamed("sum(TotalExcludingTax)", "SumOfTotalExcludingTax")\ .withColumnRenamed("sum(TaxAmount)", "SumOfTaxAmount")\ .withColumnRenamed("sum(TotalIncludingTax)", "SumOfTotalIncludingTax")\ .withColumnRenamed("sum(Profit)", "SumOfProfit")\ .orderBy("date.Date", "city.StateProvince", "city.City") sale_by_date_city.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save("Tables/aggregate_sale_by_date_city")Metod nr 2 (sale_by_date_employee) – Använd Spark SQL för att koppla och aggregera data för att generera företagsaggregeringar. Med följande kod skapar du en tillfällig Spark-vy genom att ansluta till tre tabeller, gruppera efter för att generera aggregering och byta namn på några av kolumnerna. Slutligen läser du från den tillfälliga Spark-vyn och skriver den slutligen som en Delta-tabell i avsnittet Tabeller i lakehouse för att spara med data.
I den här cellen skapar du en tillfällig Spark-vy genom att ansluta till tre tabeller, gruppera efter för att generera aggregering och byta namn på några av kolumnerna.
%%sql CREATE OR REPLACE TEMPORARY VIEW sale_by_date_employee AS SELECT DD.Date, DD.CalendarMonthLabel , DD.Day, DD.ShortMonth Month, CalendarYear Year ,DE.PreferredName, DE.Employee ,SUM(FS.TotalExcludingTax) SumOfTotalExcludingTax ,SUM(FS.TaxAmount) SumOfTaxAmount ,SUM(FS.TotalIncludingTax) SumOfTotalIncludingTax ,SUM(Profit) SumOfProfit FROM wwilakehouse.fact_sale FS INNER JOIN wwilakehouse.dimension_date DD ON FS.InvoiceDateKey = DD.Date INNER JOIN wwilakehouse.dimension_Employee DE ON FS.SalespersonKey = DE.EmployeeKey GROUP BY DD.Date, DD.CalendarMonthLabel, DD.Day, DD.ShortMonth, DD.CalendarYear, DE.PreferredName, DE.Employee ORDER BY DD.Date ASC, DE.PreferredName ASC, DE.Employee ASCI den här cellen läser du från den tillfälliga Spark-vyn som skapades i föregående cell och skriver den slutligen som en Delta-tabell i avsnittet Tabeller i lakehouse.
sale_by_date_employee = spark.sql("SELECT * FROM sale_by_date_employee") sale_by_date_employee.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save("Tables/aggregate_sale_by_date_employee")Om du vill verifiera de skapade tabellerna högerklickar du och väljer Uppdatera på wwilakehouse lakehouse. Aggregeringstabellerna visas.
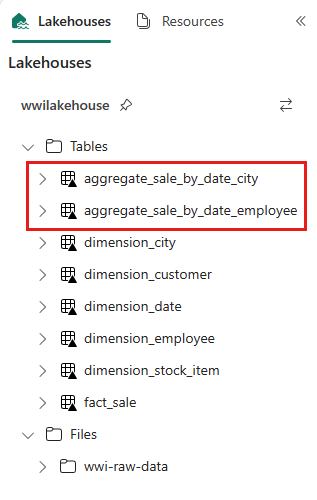
De två metoderna ger ett liknande resultat. För att minimera behovet av att lära dig en ny teknik eller kompromissa med prestanda väljer du den metod som bäst passar din bakgrund och dina önskemål.
Du kanske märker att du skriver data som Delta lake-filer. Den automatiska tabellidentifierings- och registreringsfunktionen i Fabric hämtar och registrerar dem i metaarkivet. Du behöver inte uttryckligen anropa CREATE TABLE instruktioner för att skapa tabeller som ska användas med SQL.