Fel vid felsökning av Spark-jobb med Azure Toolkit for IntelliJ (förhandsversion)
Den här artikeln innehåller stegvis vägledning om hur du använder HDInsight-verktyg i Azure Toolkit för IntelliJ för att köra Spark-felsökprogram .
Förutsättningar
Oracle Java Development Kit. Den här kursen använder Java version 8.0.202.
IntelliJ IDEA. Den här artikeln använder IntelliJ IDEA Community 2019.1.3.
Azure Toolkit for IntelliJ. Se Installera Azure Toolkit för IntelliJ.
Anslut till ditt HDInsight-kluster. Se Ansluta till ditt HDInsight-kluster.
Microsoft Azure Storage Explorer. Se Ladda ned Microsoft Azure Storage Explorer.
Skapa ett projekt med felsökningsmall
Skapa ett spark2.3.2-projekt för att fortsätta felsöka och felsöka exempelfilen i det här dokumentet.
Öppna IntelliJ IDEA. Öppna fönstret Nytt projekt .
a. Välj Azure Spark/HDInsight i den vänstra rutan.
b. Välj Spark Project with Failure Task Debugging Sample(Preview)(Scala) från huvudfönstret.
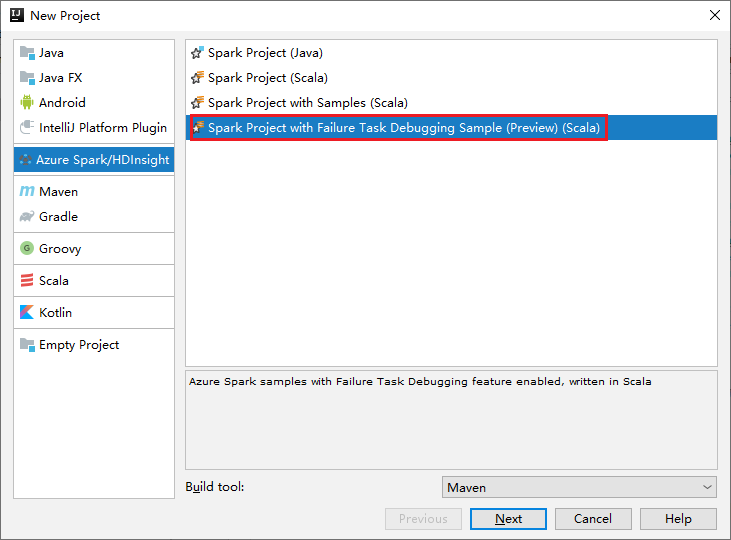
c. Välj Nästa.
Gör följande i fönstret Nytt projekt:
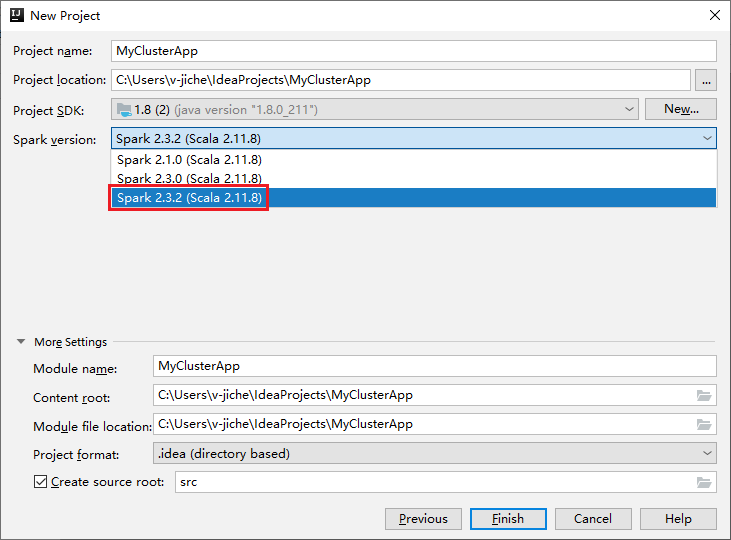
a. Ange ett projektnamn och en projektplats.
b. I listrutan Project SDK väljer du Java 1.8 för Spark 2.3.2-kluster.
c. I listrutan Spark-version väljer du Spark 2.3.2(Scala 2.11.8)..
d. Välj Slutför.
Välj src>main>scala för att öppna koden i projektet. I det här exemplet används skriptet AgeMean_Div().
Köra ett Spark Scala/Java-program i ett HDInsight-kluster
Skapa ett Spark Scala/Java-program och kör sedan programmet på ett Spark-kluster genom att utföra följande steg:
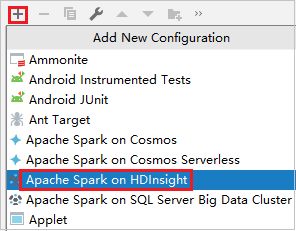
Klicka på Lägg till konfiguration för att öppna fönstret Kör/felsöka konfigurationer .

I dialogrutan Kör/felsöka konfigurationer väljer du plustecknet (+). Välj sedan alternativet Apache Spark på HDInsight .
Växla till fliken Fjärrkörning i kluster . Ange information för Namn, Spark-kluster och Huvudklassnamn. Våra verktyg stöder felsökning med körverktyg. NumExecutors, standardvärdet är 5 och du bör inte ange högre än 3. För att minska körningstiden kan du lägga till spark.yarn.maxAppAttempts i jobbkonfigurationer och ange värdet till 1. Spara konfigurationen genom att klicka på OK .
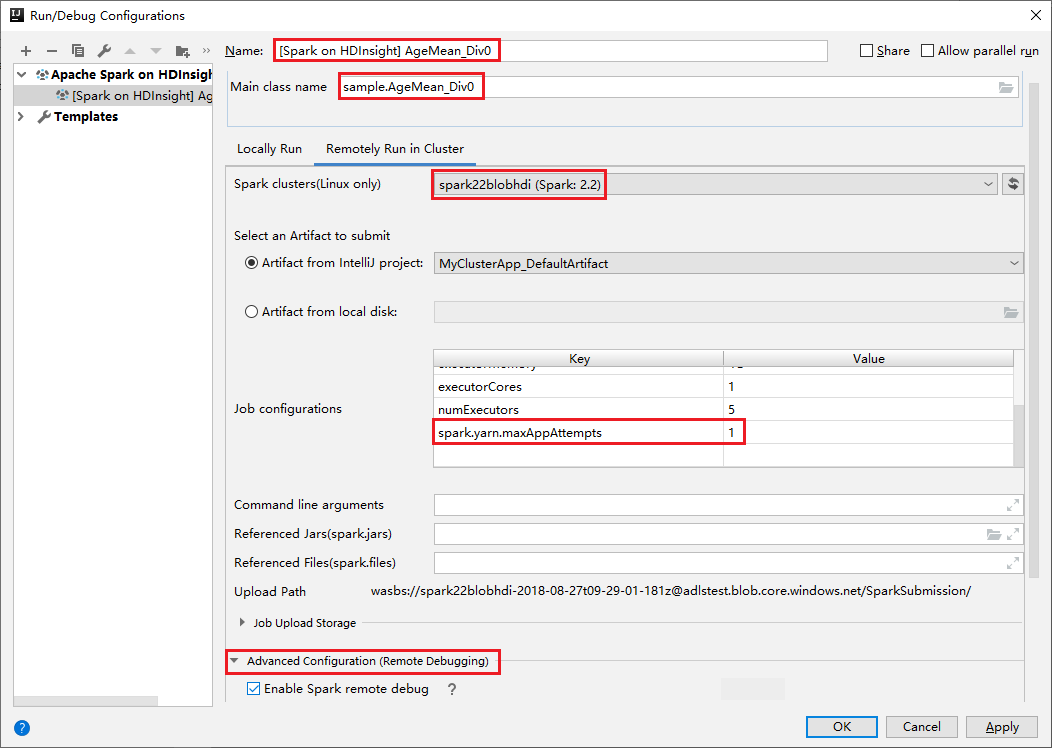
Konfigurationen sparas nu med det namn som du angav. Om du vill visa konfigurationsinformationen väljer du konfigurationsnamnet. Om du vill göra ändringar väljer du Redigera konfigurationer.
När du har slutfört konfigurationsinställningarna kan du köra projektet mot fjärrklustret.

Du kan kontrollera program-ID:t från utdatafönstret.

Ladda ned misslyckad jobbprofil
Om jobböverföringen misslyckas kan du ladda ned den misslyckade jobbprofilen till den lokala datorn för ytterligare felsökning.
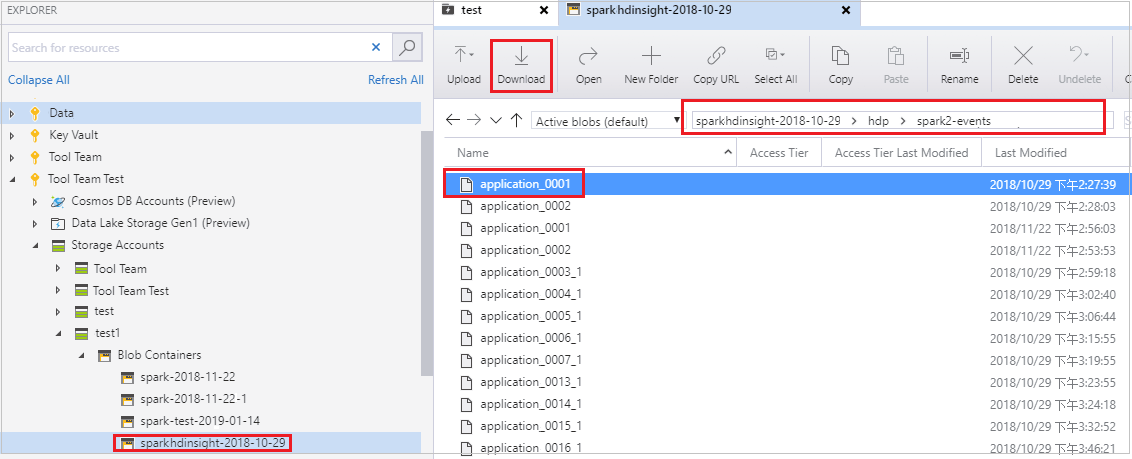
Öppna Microsoft Azure Storage Explorer, leta upp HDInsight-kontot för klustret för det misslyckade jobbet, ladda ned de misslyckade jobbresurserna från motsvarande plats: \hdp\spark2-events\.spark-failures\<application ID> till en lokal mapp. I aktivitetsfönstret visas nedladdningsstatusen.
Konfigurera lokal felsökningsmiljö och felsök vid fel
Öppna det ursprungliga projektet eller skapa ett nytt projekt och associera det med den ursprungliga källkoden. För närvarande stöds endast spark2.3.2-versionen för felsökning av fel.
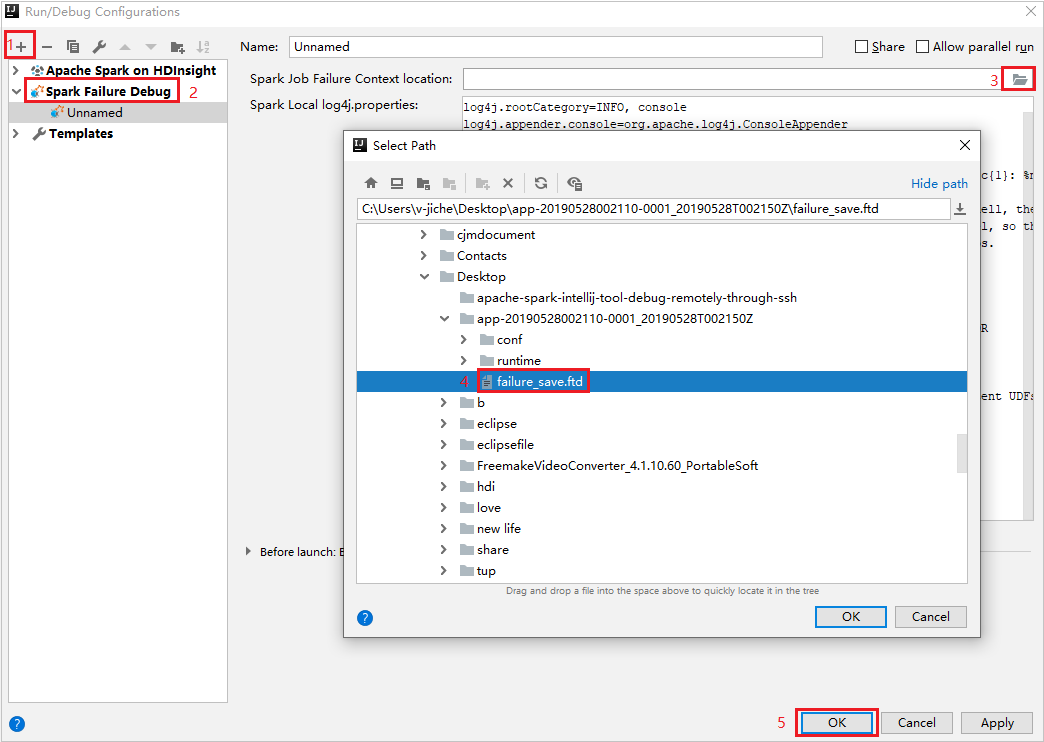
I IntelliJ IDEA skapar du en Spark Failure Debug-konfigurationsfil , väljer FTD-filen från de tidigare nedladdade misslyckade jobbresurserna för fältet Plats för Spark-jobbfelkontext.
Klicka på den lokala körningsknappen i verktygsfältet. Felet visas i fönstret Kör.
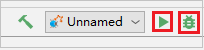
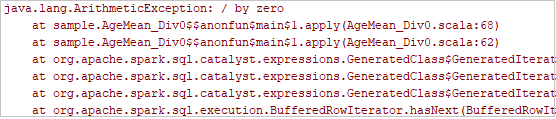
Ange brytpunkt som loggen anger och klicka sedan på den lokala felsökningsknappen för att utföra lokal felsökning precis som dina vanliga Scala-/Java-projekt i IntelliJ.
Om projektet har slutförts efter felsökningen kan du skicka det misslyckade jobbet på nytt till din spark i HDInsight-klustret.
Nästa steg
Scenarier
- Apache Spark med BI: Gör interaktiv dataanalys med hjälp av Spark i HDInsight med BI-verktyg
- Apache Spark med Machine Learning: Använda Spark i HDInsight för att analysera byggnadstemperaturen med hjälp av HVAC-data
- Apache Spark med Machine Learning: Använda Spark i HDInsight för att förutsäga resultat av livsmedelsinspektion
- Analys av webbplatsloggar med Apache Spark i HDInsight
Skapa och köra program
- Skapa ett fristående program med hjälp av Scala
- Köra jobb via fjärranslutning på ett Apache Spark-kluster med hjälp av Apache Livy
Verktyg och tillägg
- Använda Azure Toolkit for IntelliJ för att skapa Apache Spark-program för ett HDInsight-kluster
- Använda Azure Toolkit for IntelliJ för att fjärrsöka Apache Spark-program via VPN
- Använda HDInsight-verktyg i Azure Toolkit for Eclipse för att skapa Apache Spark-program
- Använda Apache Zeppelin-notebook-filer med ett Apache Spark-kluster i HDInsight
- Kernels tillgängliga för Jupyter Notebook i Apache Spark-klustret för HDInsight
- Använda externa paket med Jupyter Notebooks
- Installera Jupyter på datorn och ansluta till ett HDInsight Spark-kluster