Felsöka Apache Spark-program i ett HDInsight-kluster med Azure Toolkit for IntelliJ via SSH
Den här artikeln innehåller stegvis vägledning om hur du använder HDInsight Tools i Azure Toolkit for IntelliJ för att fjärrfelsöka program i ett HDInsight-kluster.
Förutsättningar
Ett Apache Spark-kluster i HDInsight. Se Skapa ett Apache Spark-kluster.
För Windows-användare: När du kör det lokala Spark Scala-programmet på en Windows-dator kan du få ett undantag, enligt beskrivningen i SPARK-2356. Undantaget beror på att WinUtils.exe saknas i Windows.
Lös det här felet genom att ladda ned Winutils.exe till en plats som C:\WinUtils\bin. Lägg sedan till miljövariabeln HADOOP_HOME och ange värdet för variabeln till C:\WinUtils.
IntelliJ IDEA (Community-utgåvan är kostnadsfri.).
En SSH-klient. Mer information finns i Ansluta till HDInsight (Apache Hadoop) med hjälp av SSH.
Skapa ett Spark Scala-program
Starta IntelliJ IDEA och välj Skapa nytt projekt för att öppna fönstret Nytt projekt.
Välj Apache Spark/HDInsight i det vänstra fönstret.
Välj Spark-projekt med exempel (Scala) i huvudfönstret.
Från listrutan Byggverktyg väljer du något av följande:
- Maven för guidestöd när du skapar Scala-projekt.
- SBT för att hantera beroenden och bygga för Scala-projektet.
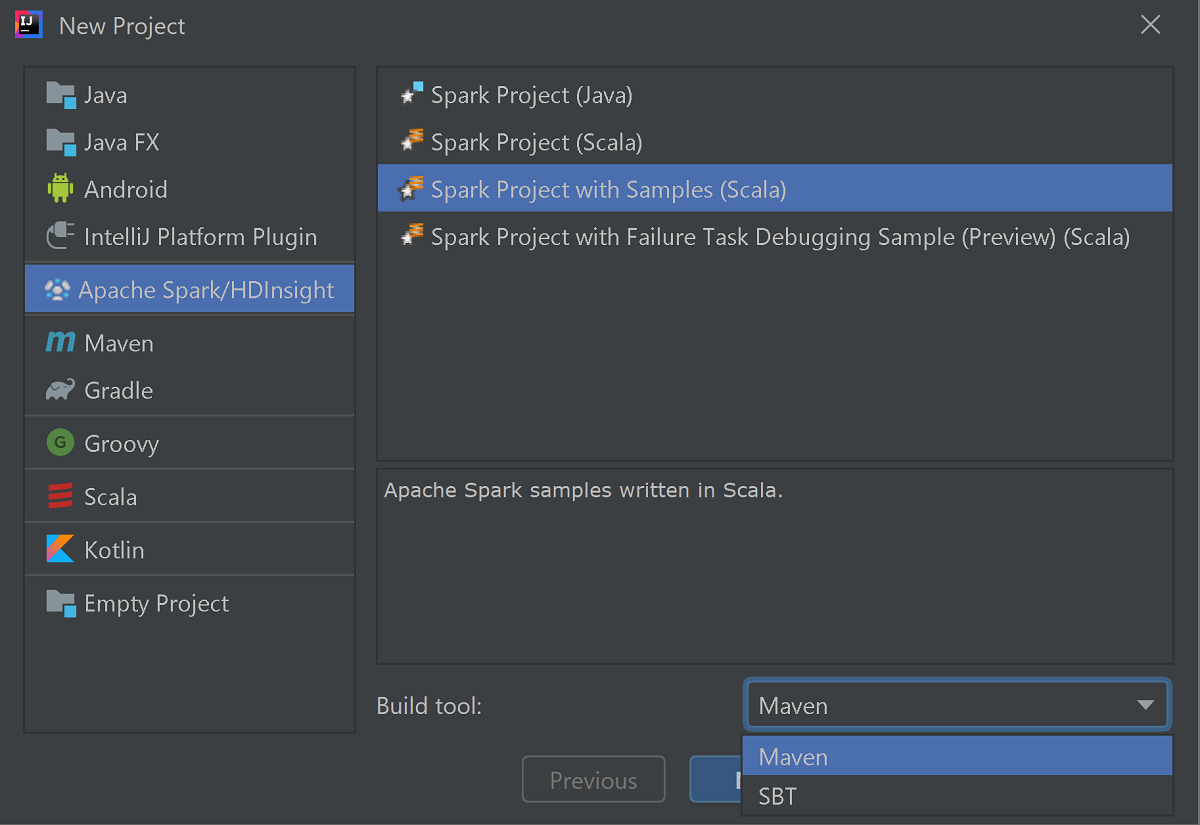
Välj Nästa.
I nästa nytt projektfönster anger du följande information:
Egendom beskrivning Projektnamn Ange ett namn. Den här genomgången använder myApp.Projektplats Ange önskad plats för att spara projektet. Projekt-SDK Om det är tomt väljer du Nytt... och navigerar till din JDK. Spark-version Skapandeguiden integrerar rätt version för Spark SDK och Scala SDK. Om Sparks klusterversion är äldre än 2.0 väljer du Spark 1.x. Annars väljer du Spark 2.x.. I det här exemplet används Spark 2.3.0 (Scala 2.11.8). 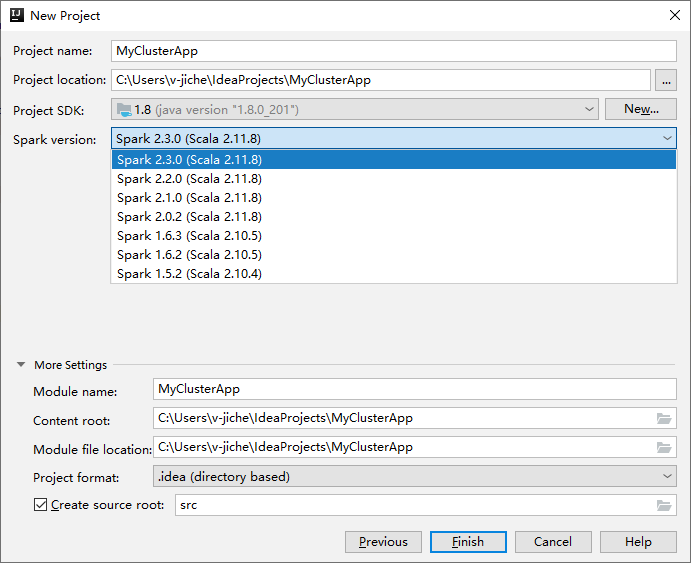
Välj Slutför. Det kan ta några minuter innan projektet blir tillgängligt. Titta på det nedre högra hörnet för förlopp.
Expandera ditt projekt och navigera till src>main>scala>sample. Dubbelklicka på SparkCore_WasbIOTest.
Utföra lokal körning
I skriptet SparkCore_WasbIOTest högerklickar du på skriptredigeraren och väljer sedan alternativet Kör "SparkCore_WasbIOTest" för att utföra lokal körning.
När den lokala körningen har slutförts kan du se att utdatafilen sparas i din aktuella projektutforskare data>default.
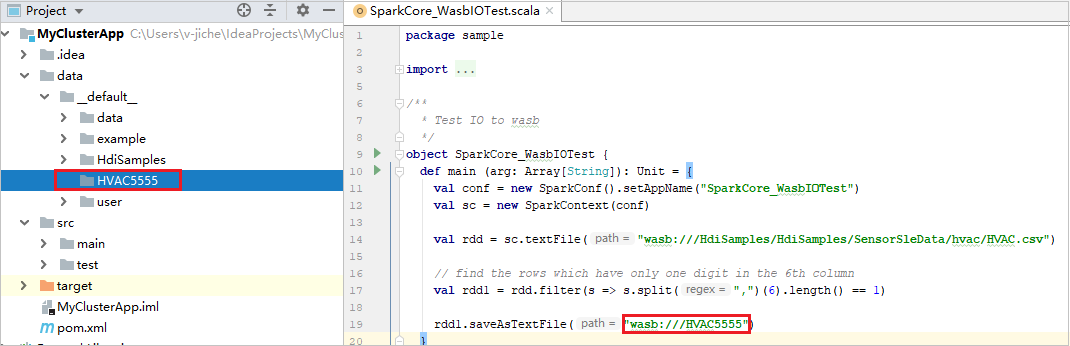
Våra verktyg har konfigurerat standardkonfigurationen för lokal körning automatiskt när du utför den lokala körningen och den lokala felsökningen. Öppna konfigurationen [Spark på HDInsight] XXX i det övre högra hörnet. Du kan se [Spark på HDInsight]XXX som redan har skapats under Apache Spark i HDInsight. Växla till fliken Lokalt kör .
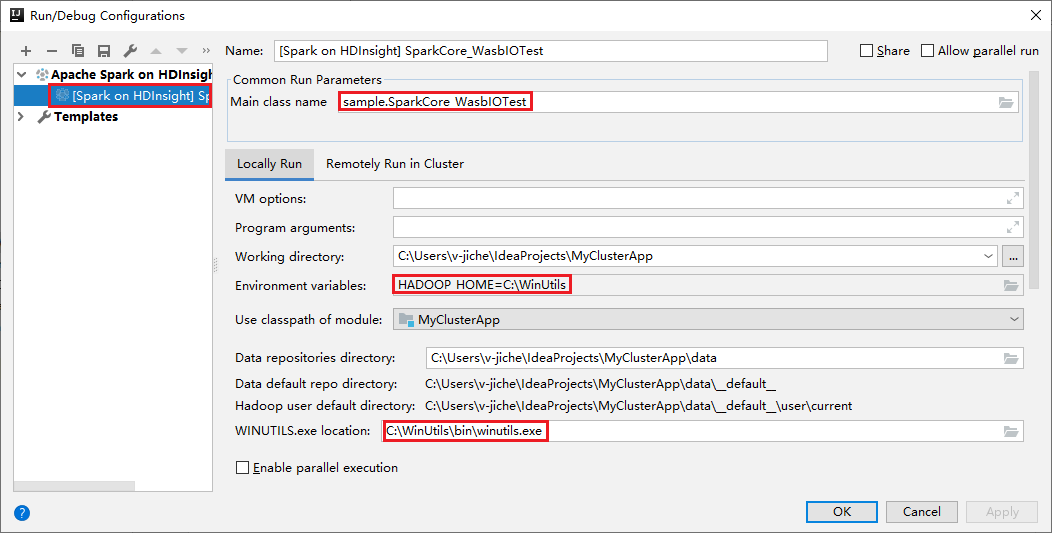
- Miljövariabler: Om du redan har angett systemmiljövariabeln HADOOP_HOME till C:\WinUtils kan den automatiskt identifiera att du inte behöver lägga till den manuellt.
- WinUtils.exe Plats: Om du inte har angett systemmiljövariabeln kan du hitta platsen genom att klicka på dess knapp.
- Välj bara något av två alternativ och de behövs inte på macOS och Linux.
Du kan också ange konfigurationen manuellt innan du utför lokal körning och lokal felsökning. I föregående skärmbild väljer du plustecknet (+). Välj sedan alternativet Apache Spark på HDInsight . Ange information för Namn, Huvudklassnamn för att spara, och klicka sedan på lokala körningsknappen.
Utföra lokal felsökning
Öppna skriptet SparkCore_wasbloTest och ange brytpunkter.
Högerklicka på skriptredigeraren och välj sedan alternativet Felsök "[Spark på HDInsight]XXX" för att utföra lokal felsökning.
Utföra fjärrkörning
Gå till Kör>redigera konfigurationer.... På den här menyn kan du skapa eller redigera konfigurationerna för fjärrfelsökning.
I dialogrutan Kör/felsöka konfigurationer väljer du plustecknet (+). Välj sedan alternativet Apache Spark på HDInsight .
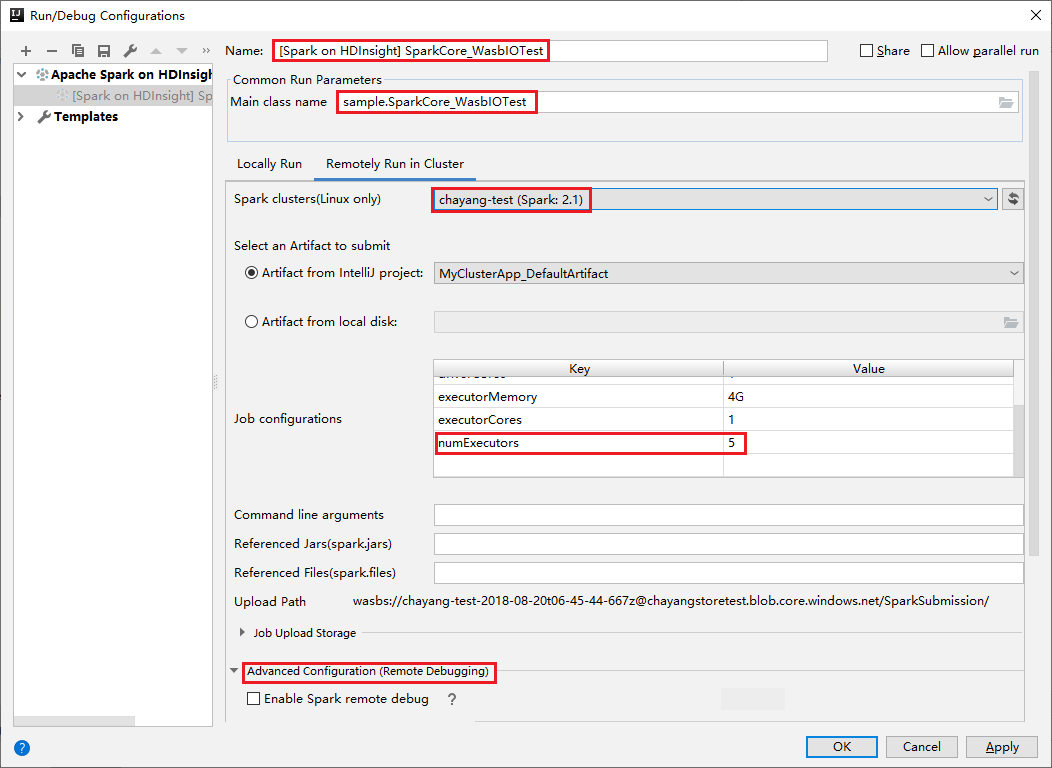
Växla till fliken Fjärrkörning i kluster . Ange information för Namn, Spark-kluster och Huvudklassnamn. Klicka sedan på Avancerad konfiguration (fjärrfelsökning). Våra verktyg stöder felsökning med körverktyg. numExecutors, standardvärdet är 5. Det är bäst att du inte anger högre än 3.
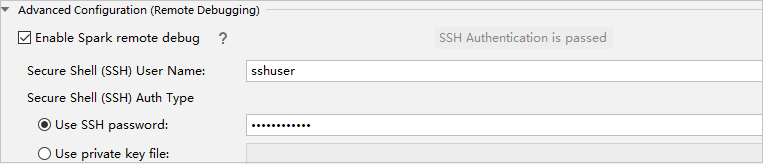
I delen Avancerad konfiguration (fjärrfelsökning) väljer du Aktivera Fjärrfelsökning i Spark. Ange SSH-användarnamnet och ange sedan ett lösenord eller använd en privat nyckelfil. Om du vill utföra fjärrfelsökning måste du ange det. Du behöver inte ange det om du bara vill använda fjärrkörning.
Konfigurationen sparas nu med det namn som du angav. Om du vill visa konfigurationsinformationen väljer du konfigurationsnamnet. Om du vill göra ändringar väljer du Redigera konfigurationer.
När du har slutfört konfigurationsinställningarna kan du köra projektet mot fjärrklustret eller utföra fjärrfelsökning.

Klicka på knappen Koppla från så att insändningsloggarna inte visas i den vänstra panelen. Den körs dock fortfarande på serverdelen.
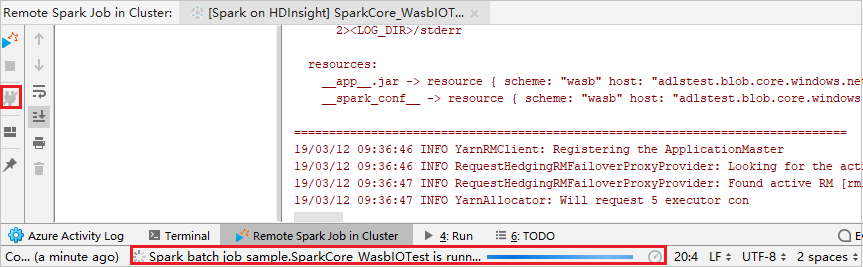
Utföra fjärrfelsökning
Konfigurera brytpunkter och klicka sedan på ikonen Fjärrfelsökning . Skillnaden med fjärröverföring är att SSH-användarnamn/lösenord måste konfigureras.

När programkörningen når brytpunkten visas fliken Driver och två Executor-flikar i Debuggar-fönstret. Välj ikonen Återuppta program för att fortsätta köra koden, som sedan når nästa brytpunkt. Du måste växla till rätt Executor-flik för att hitta den målexekutor som ska felsökas. Du kan visa körningsloggarna på motsvarande konsolflik .
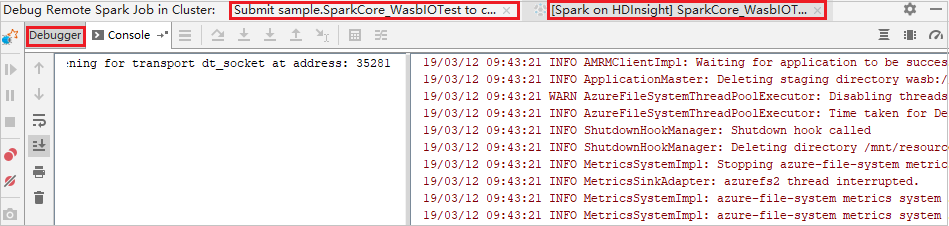
Utföra fjärrfelsökning och felkorrigering
Konfigurera två brytpunkter och välj sedan felsökningsikonen för att starta fjärrfelsökningsprocessen.
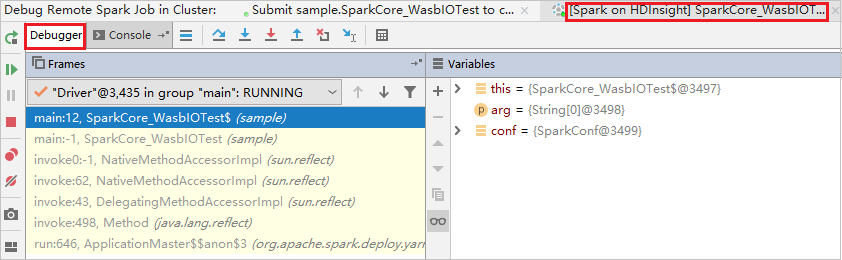
Koden stoppas vid den första brytpunkten och parameter- och variabelinformationen visas i fönstret Variabler .
Välj ikonen Återuppta program för att fortsätta. Koden stoppas vid den andra punkten. Undantaget fångas som förväntat.
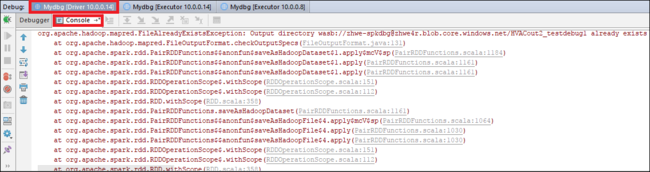
Välj ikonen Återuppta program igen. Fönstret HDInsight Spark-inlämning visar ett fel om att jobbkörningen misslyckades.
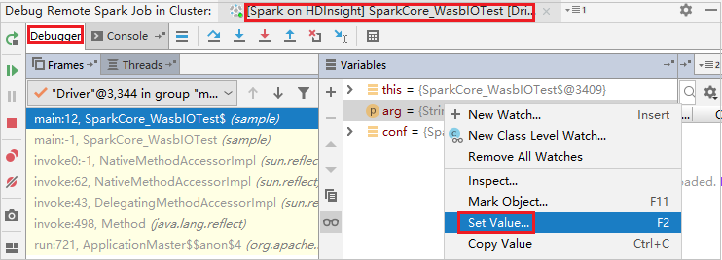
Om du vill uppdatera variabelvärdet dynamiskt med hjälp av felsökningsfunktionen IntelliJ väljer du Felsöka igen. Fönstret Variabler visas igen.
Högerklicka på målet på fliken Felsök och välj sedan Ange värde. Ange sedan ett nytt värde för variabeln. Välj Retur för att sedan spara värdet.
Välj ikonen Återuppta program för att fortsätta att köra programmet. Den här gången fångas inget undantag. Du kan se att projektet körs utan undantag.
Nästa steg
Scenarier
- Apache Spark med BI: Utföra interaktiv dataanalys med hjälp av Spark i HDInsight med BI-verktyg
- Apache Spark med Machine Learning: Använda Spark i HDInsight för att analysera byggnadstemperaturen med hjälp av HVAC-data
- Apache Spark med Machine Learning: Använda Spark i HDInsight för att förutsäga resultat av livsmedelsinspektion
- Analys av webbplatsloggar med Apache Spark i HDInsight
Skapa och köra program
- Skapa ett fristående program med hjälp av Scala
- Köra jobb via fjärranslutning på ett Apache Spark-kluster med hjälp av Apache Livy
Verktyg och tillägg
- Använda Azure Toolkit for IntelliJ för att skapa Apache Spark-program för ett HDInsight-kluster
- Använd Azure Toolkit for IntelliJ för att felsöka Apache Spark-applikationer via VPN
- Använda HDInsight-verktyg i Azure Toolkit for Eclipse för att skapa Apache Spark-program
- Använd Apache Zeppelin-notebooks med ett Apache Spark-kluster på HDInsight
- Kernels för Jupyter Notebook tillgängliga i HDInsights Apache Spark-kluster
- Använda externa paket med Jupyter Notebooks
- Installera Jupyter på datorn och ansluta till ett HDInsight Spark-kluster