Använda externa paket med Jupyter Notebooks i Apache Spark-kluster i HDInsight
Lär dig hur du konfigurerar en Jupyter Notebook i Apache Spark-kluster i HDInsight för att använda externa, community-bidragna Apache maven-paket som inte ingår i klustret.
Du kan söka i Maven-lagringsplatsen efter den fullständiga listan över paket som är tillgängliga. Du kan också hämta en lista över tillgängliga paket från andra källor. En fullständig lista över community-bidragda paket finns till exempel på Spark Packages.
I den här artikeln får du lära dig hur du använder spark-csv-paketet med Jupyter Notebook.
Förutsättningar
Ett Apache Spark-kluster i HDInsight. Anvisningar finns i Skapa Apache Spark-kluster i Azure HDInsight.
Kunskaper om Jupyter Notebooks med Spark på HDInsight. Mer information finns i Läsa in data och köra frågor med Apache Spark i HDInsight.
URI-schemat för dina klusters primära lagring. Detta skulle vara
wasb://för Azure Storage,abfs://för Azure Data Lake Storage Gen2. Om säker överföring är aktiverad för Azure Storage eller Data Lake Storage Gen2 ärwasbs://URI:n ellerabfss://, respektive Se även, säker överföring.
Använda externa paket med Jupyter Notebooks
Navigera till
https://CLUSTERNAME.azurehdinsight.net/jupyterplatsen därCLUSTERNAMEär namnet på ditt Spark-kluster.Skapa en ny anteckningsbok. Välj Ny och välj sedan Spark.
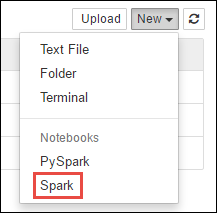
En ny anteckningsbok skapas och öppnas med namnet Untitled.pynb. Välj anteckningsbokens namn överst och ange ett eget namn.
Du använder magin
%%configureför att konfigurera notebook-filen så att den använder ett externt paket. I notebook-filer som använder externa paket kontrollerar du att du anropar magin%%configurei den första kodcellen. Detta säkerställer att kerneln är konfigurerad för att använda paketet innan sessionen startar.Viktigt!
Om du glömmer att konfigurera kerneln i den första cellen kan du använda
%%configuremed parametern-f, men det startar om sessionen och alla förlopp går förlorade.HDInsight-version Command För HDInsight 3.5 och HDInsight 3.6 %%configure{ "conf": {"spark.jars.packages": "com.databricks:spark-csv_2.11:1.5.0" }}För HDInsight 3.3 och HDInsight 3.4 %%configure{ "packages":["com.databricks:spark-csv_2.10:1.4.0"] }Kodfragmentet ovan förväntar sig maven-koordinaterna för det externa paketet i Maven Central Repository. I det här kodfragmentet
com.databricks:spark-csv_2.11:1.5.0är maven-koordinaten för spark-csv-paketet . Så här konstruerar du koordinaterna för ett paket.a. Leta upp paketet på Maven-lagringsplatsen. I den här artikeln använder vi spark-csv.
b. Från lagringsplatsen samlar du in värdena för GroupId, ArtifactId och Version. Kontrollera att de värden som du samlar in matchar klustret. I det här fallet använder vi ett Scala 2.11- och Spark 1.5.0-paket, men du kan behöva välja olika versioner för lämplig Scala- eller Spark-version i klustret. Du kan ta reda på Scala-versionen i klustret genom att köra
scala.util.Properties.versionStringpå Spark Jupyter-kerneln eller vid Spark-sändning. Du kan ta reda på Spark-versionen i klustret genom att körasc.versionpå Jupyter Notebooks.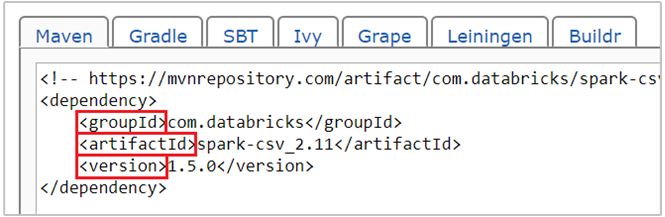
c. Sammanfoga de tre värdena, avgränsade med ett kolon (:).
com.databricks:spark-csv_2.11:1.5.0Kör kodcellen med magin
%%configure. Detta konfigurerar den underliggande Livy-sessionen så att den använder det paket som du angav. I de efterföljande cellerna i notebook-filen kan du nu använda paketet enligt nedan.val df = spark.read.format("com.databricks.spark.csv"). option("header", "true"). option("inferSchema", "true"). load("wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv")För HDInsight 3.4 och lägre bör du använda följande kodfragment.
val df = sqlContext.read.format("com.databricks.spark.csv"). option("header", "true"). option("inferSchema", "true"). load("wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv")Du kan sedan köra kodfragmenten, som du ser nedan, för att visa data från dataramen som du skapade i föregående steg.
df.show() df.select("Time").count()
Se även
Scenarier
- Apache Spark med BI: Utföra interaktiv dataanalys med Spark i HDInsight med BI-verktyg
- Apache Spark med Machine Learning: Använda Spark i HDInsight för att analysera byggnadstemperaturen med hjälp av HVAC-data
- Apache Spark med Machine Learning: Använda Spark i HDInsight för att förutsäga resultat av livsmedelsinspektion
- Analys av webbplatsloggar med Apache Spark i HDInsight
Skapa och köra program
- Skapa ett fristående program med hjälp av Scala
- Köra jobb via fjärranslutning på ett Apache Spark-kluster med hjälp av Apache Livy
Verktyg och tillägg
- Använda externa Python-paket med Jupyter Notebooks i Apache Spark-kluster i HDInsight Linux
- Använda HDInsight Tools-plugin för IntelliJ IDEA till att skapa och skicka Spark Scala-appar
- Använda HDInsight Tools-plugin-programmet för IntelliJ IDEA för att fjärrsöka Apache Spark-program
- Använda Apache Zeppelin-notebook-filer med ett Apache Spark-kluster i HDInsight
- Kernels tillgängliga för Jupyter Notebook i Apache Spark-kluster för HDInsight
- Installera Jupyter på datorn och ansluta till ett HDInsight Spark-kluster