Installera Jupyter Notebook på datorn och anslut till Apache Spark på HDInsight
I den här artikeln får du lära dig hur du installerar Jupyter Notebook med de anpassade PySpark-kärnorna (för Python) och Apache Spark (för Scala) med Spark-magi. Sedan ansluter du notebook-filen till ett HDInsight-kluster.
Det finns fyra viktiga steg för att installera Jupyter och ansluta till Apache Spark i HDInsight.
- Konfigurera Spark-kluster.
- Installera Jupyter Notebook.
- Installera PySpark- och Spark-kernels med Spark-magin.
- Konfigurera Spark-magi för åtkomst till Spark-kluster i HDInsight.
Mer information om anpassade kernels och Spark-magi finns i Kernels available for Jupyter Notebooks with Apache Spark Linux clusters on HDInsight (Kernels available for Jupyter Notebooks with Apache Spark Linux clusters on HDInsight).
Förutsättningar
Ett Apache Spark-kluster i HDInsight. Anvisningar finns i Skapa Apache Spark-kluster i Azure HDInsight. Den lokala notebook-filen ansluter till HDInsight-klustret.
Kunskaper om Jupyter Notebooks med Spark på HDInsight.
Installera Jupyter Notebook på datorn
Installera Python innan du installerar Jupyter Notebooks. Anaconda-distributionen installerar både Python och Jupyter Notebook.
Ladda ned installationsprogrammet för Anaconda för din plattform och kör installationen. När du kör installationsguiden måste du välja alternativet att lägga till Anaconda i path-variabeln. Se även Installera Jupyter med hjälp av Anaconda.
Installera Spark magic
Ange kommandot
pip install sparkmagic==0.13.1för att installera Spark magic för HDInsight-kluster version 3.6 och 4.0. Se även sparkmagisk dokumentation.Kontrollera att
ipywidgetsdet är korrekt installerat genom att köra följande kommando:jupyter nbextension enable --py --sys-prefix widgetsnbextension
Installera PySpark- och Spark-kernels
Identifiera var
sparkmagicinstalleras genom att ange följande kommando:pip show sparkmagicÄndra sedan arbetskatalogen till den plats som identifieras med kommandot ovan.
Från den nya arbetskatalogen anger du ett eller flera av kommandona nedan för att installera önskade kernel(er):
Kernel Command Spark jupyter-kernelspec install sparkmagic/kernels/sparkkernelSparkR jupyter-kernelspec install sparkmagic/kernels/sparkrkernelPySpark jupyter-kernelspec install sparkmagic/kernels/pysparkkernelPySpark3 jupyter-kernelspec install sparkmagic/kernels/pyspark3kernelValfritt. Ange kommandot nedan för att aktivera servertillägget:
jupyter serverextension enable --py sparkmagic
Konfigurera Spark-magi för att ansluta till HDInsight Spark-kluster
I det här avsnittet konfigurerar du Spark-magin som du installerade tidigare för att ansluta till ett Apache Spark-kluster.
Starta Python-gränssnittet med följande kommando:
pythonJupyter-konfigurationsinformationen lagras vanligtvis i användarnas hemkatalog. Ange följande kommando för att identifiera hemkatalogen och skapa en mapp med namnet .sparkmagic. Den fullständiga sökvägen matas ut.
import os path = os.path.expanduser('~') + "\\.sparkmagic" os.makedirs(path) print(path) exit()I mappen
.sparkmagicskapar du en fil med namnet config.json och lägger till följande JSON-kodfragment i den.{ "kernel_python_credentials" : { "username": "{USERNAME}", "base64_password": "{BASE64ENCODEDPASSWORD}", "url": "https://{CLUSTERDNSNAME}.azurehdinsight.net/livy" }, "kernel_scala_credentials" : { "username": "{USERNAME}", "base64_password": "{BASE64ENCODEDPASSWORD}", "url": "https://{CLUSTERDNSNAME}.azurehdinsight.net/livy" }, "custom_headers" : { "X-Requested-By": "livy" }, "heartbeat_refresh_seconds": 5, "livy_server_heartbeat_timeout_seconds": 60, "heartbeat_retry_seconds": 1 }Gör följande ändringar i filen:
Mallvärde Nytt värde {USERNAME} Klusterinloggning, standardvärdet är admin.{CLUSTERDNSNAME} Klusternamn {BASE64ENCODEDPASSWORD} Ett base64-kodat lösenord för ditt faktiska lösenord. Du kan generera ett base64-lösenord på https://www.url-encode-decode.com/base64-encode-decode/. "livy_server_heartbeat_timeout_seconds": 60Behåll om du använder sparkmagic 0.12.7(kluster v3.5 och v3.6). Om du användersparkmagic 0.2.3(kluster v3.4) ersätter du med"should_heartbeat": true.Du kan se en fullständig exempelfil på exempel config.json.
Dricks
Pulsslag skickas för att säkerställa att sessioner inte läcker ut. När en dator försätts i viloläge eller stängs av skickas inte pulsslag, vilket resulterar i att sessionen rensas. Om du vill inaktivera det här beteendet för kluster v3.4 kan du ange Livy-konfigurationen
livy.server.interactive.heartbeat.timeouttill0från Ambari-användargränssnittet. För kluster v3.5 tas inte sessionen bort om du inte anger 3.5-konfigurationen ovan.Starta Jupyter. Använd följande kommando från kommandotolken.
jupyter notebookKontrollera att du kan använda Spark-magin som är tillgänglig med kernels. Utför följande steg.
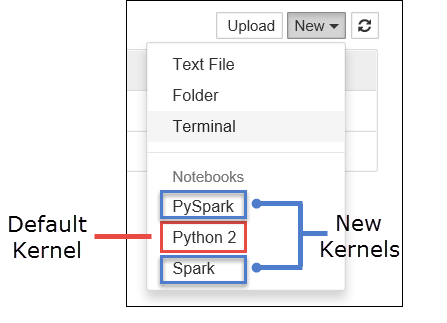
a. Skapa en ny anteckningsbok. Välj Nytt i det högra hörnet. Du bör se standardkärnan Python 2 eller Python 3 och de kernels som du har installerat. De faktiska värdena kan variera beroende på dina installationsval. Välj PySpark.
Viktigt!
När du har valt Nytt granskar du gränssnittet för eventuella fel. Om du ser felet
TypeError: __init__() got an unexpected keyword argument 'io_loop'kan det uppstå ett känt problem med vissa versioner av Tornado. I så fall stoppar du kerneln och nedgraderar sedan Tornado-installationen med följande kommando:pip install tornado==4.5.3.b. Kör följande kodfragment.
%%sql SELECT * FROM hivesampletable LIMIT 5Om du kan hämta utdata testas anslutningen till HDInsight-klustret.
Om du vill uppdatera notebook-konfigurationen för att ansluta till ett annat kluster uppdaterar du config.json med den nya uppsättningen värden, enligt steg 3 ovan.
Varför ska jag installera Jupyter på datorn?
Anledningar till att installera Jupyter på datorn och sedan ansluta den till ett Apache Spark-kluster i HDInsight:
- Ger dig möjlighet att skapa dina notebook-filer lokalt, testa programmet mot ett kluster som körs och sedan ladda upp notebook-filerna till klustret. Om du vill ladda upp anteckningsböckerna till klustret kan du antingen ladda upp dem med hjälp av Den Jupyter Notebook som körs eller klustret eller spara dem i
/HdiNotebooksmappen i lagringskontot som är associerat med klustret. Mer information om hur notebook-filer lagras i klustret finns i Var lagras Jupyter Notebooks? - Med notebook-filerna tillgängliga lokalt kan du ansluta till olika Spark-kluster baserat på dina programkrav.
- Du kan använda GitHub för att implementera ett källkontrollsystem och ha versionskontroll för notebook-filerna. Du kan också ha en samarbetsmiljö där flera användare kan arbeta med samma notebook-fil.
- Du kan arbeta med notebook-filer lokalt utan att ens ha ett kluster upp. Du behöver bara ett kluster för att testa dina notebook-filer mot, inte för att manuellt hantera dina notebook-filer eller en utvecklingsmiljö.
- Det kan vara enklare att konfigurera din egen lokala utvecklingsmiljö än att konfigurera Jupyter-installationen i klustret. Du kan dra nytta av all programvara som du har installerat lokalt utan att konfigurera ett eller flera fjärrkluster.
Varning
Med Jupyter installerat på den lokala datorn kan flera användare köra samma notebook-fil på samma Spark-kluster samtidigt. I sådana fall skapas flera Livy-sessioner. Om du stöter på ett problem och vill felsöka det blir det en komplex uppgift att spåra vilken Livy-session som tillhör vilken användare.