Hantera resurser för Apache Spark-kluster i Azure HDInsight
Lär dig hur du kommer åt gränssnitt som Apache Ambari UI, Apache Hadoop YARN UI och Spark History Server som är associerade med ditt Apache Spark-kluster och hur du justerar klusterkonfigurationen för optimala prestanda.
Öppna Spark-historikservern
Spark History Server är webbgränssnittet för slutförda och köra Spark-program. Det är en förlängning av Sparks webbgränssnitt. Fullständig information finns i Spark History Server.
Öppna Yarn-användargränssnittet
Du kan använda YARN-användargränssnittet för att övervaka program som för närvarande körs i Spark-klustret.
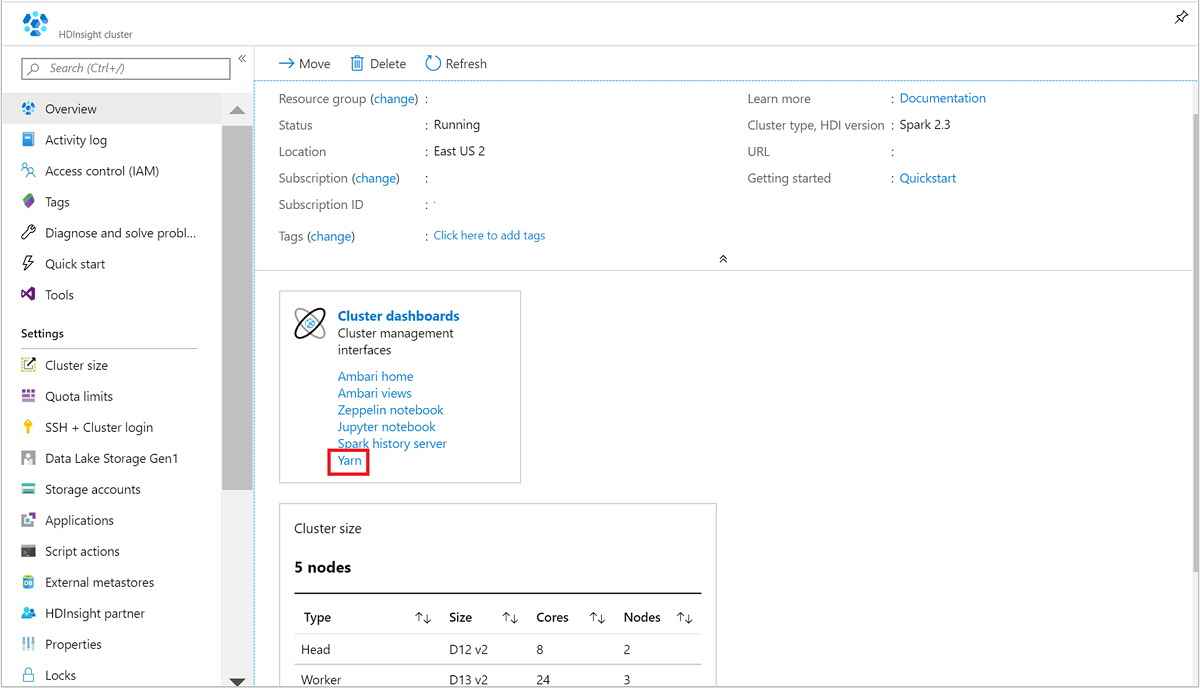
Öppna Spark-klustret från Azure Portal. Mer information finns i Lista och visa kluster.
Från Klusterinstrumentpaneler väljer du Yarn. När du uppmanas till det anger du administratörsautentiseringsuppgifterna för Spark-klustret.
Dricks
Du kan också starta YARN-användargränssnittet från Ambari-användargränssnittet. Från Ambari-användargränssnittet navigerar du till YARN>Quick Links>Active>Resource Manager-användargränssnittet.
Optimera kluster för Spark-program
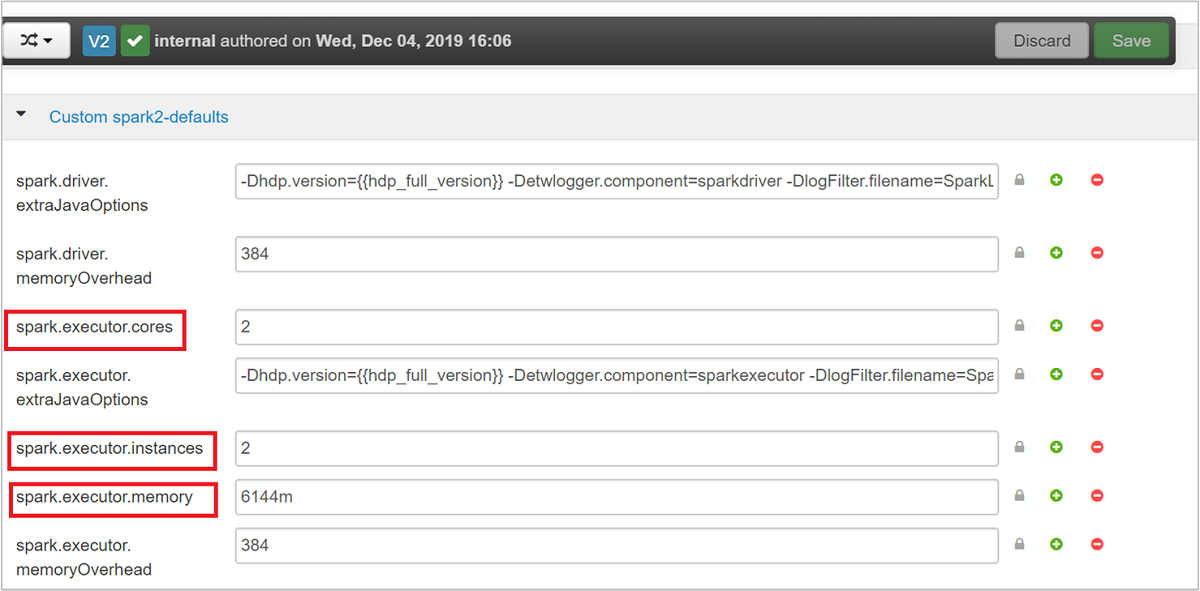
De tre nyckelparametrarna som kan användas för Spark-konfiguration beroende på programkrav är spark.executor.instances, spark.executor.coresoch spark.executor.memory. En körprocess är en process som startas för ett Spark-program. Den körs på arbetsnoden och ansvarar för att utföra programmets uppgifter. Standardantalet för exekutorer och körstorlekar för varje kluster beräknas baserat på antalet arbetsnoder och arbetsnodens storlek. Den här informationen lagras i spark-defaults.conf på klustrets huvudnoder.
De tre konfigurationsparametrarna kan konfigureras på klusternivå (för alla program som körs i klustret) eller kan anges för varje enskilt program också.
Ändra parametrarna med Ambari-användargränssnittet
Från Ambari-användargränssnittet navigerar du till Spark 2>Configs>Custom spark2-defaults.
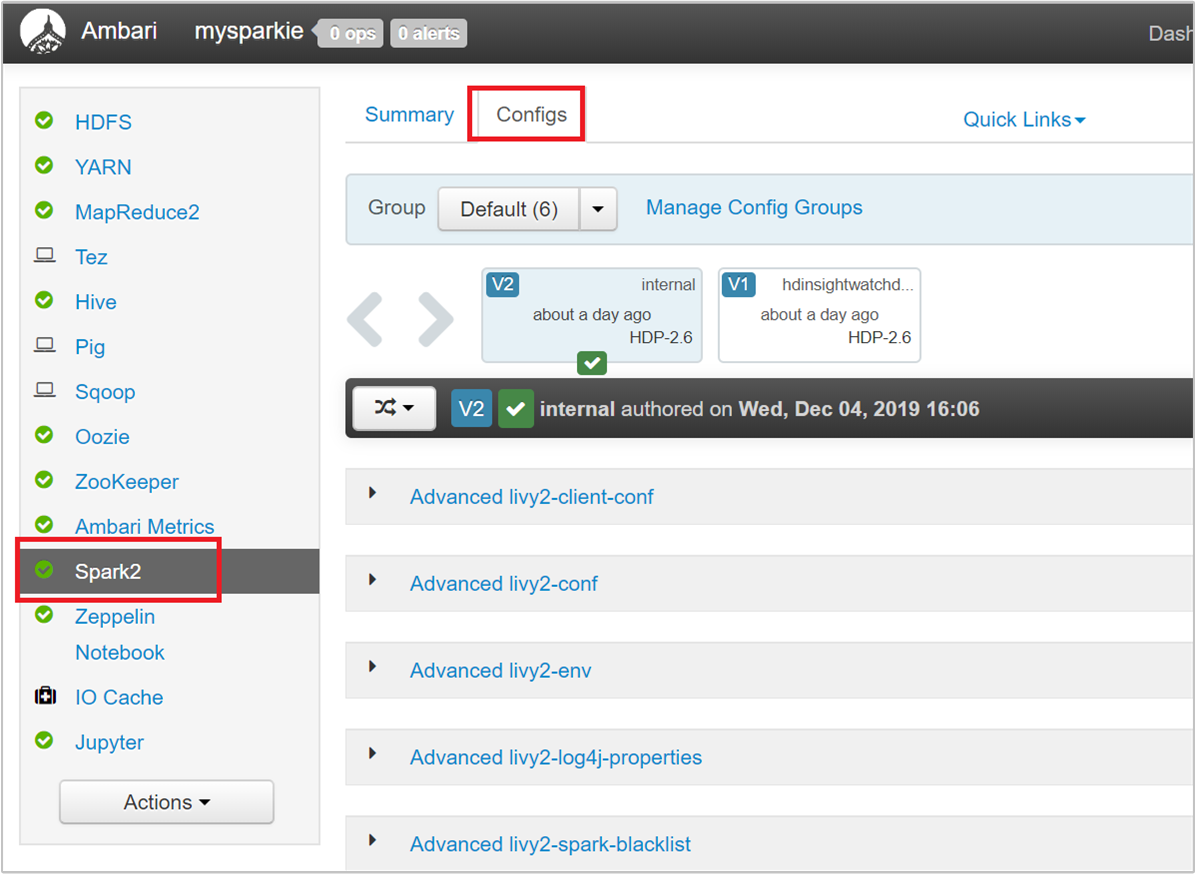
Standardvärdena är bra för att fyra Spark-program ska köras samtidigt i klustret. Du kan ändra dessa värden från användargränssnittet enligt följande skärmbild:
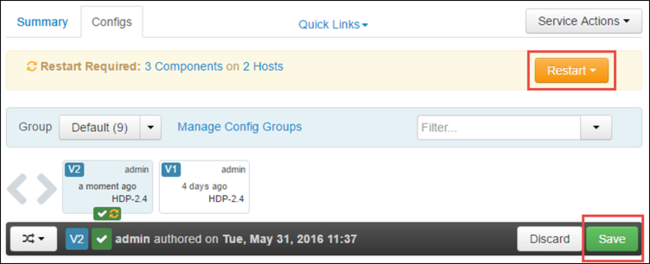
Spara konfigurationsändringarna genom att välja Spara . Överst på sidan uppmanas du att starta om alla berörda tjänster. Välj Starta om.
Ändra parametrarna för ett program som körs i Jupyter Notebook
För program som körs i Jupyter Notebook kan du använda magin %%configure för att göra konfigurationsändringarna. Helst måste du göra sådana ändringar i början av programmet innan du kör din första kodcell. Detta säkerställer att konfigurationen tillämpas på Livy-sessionen när den skapas. Om du vill ändra konfigurationen i ett senare skede i programmet måste du använda parametern -f . Men genom att göra det går alla framsteg i programmet förlorade.
Följande kodfragment visar hur du ändrar konfigurationen för ett program som körs i Jupyter.
%%configure
{"executorMemory": "3072M", "executorCores": 4, "numExecutors":10}
Konfigurationsparametrar måste skickas som en JSON-sträng och måste finnas på nästa rad efter magin, som du ser i exempelkolumnen.
Ändra parametrarna för ett program som skickas med spark-submit
Följande kommando är ett exempel på hur du ändrar konfigurationsparametrarna för ett batchprogram som skickas med .spark-submit
spark-submit --class <the application class to execute> --executor-memory 3072M --executor-cores 4 –-num-executors 10 <location of application jar file> <application parameters>
Ändra parametrarna för ett program som skickas med cURL
Följande kommando är ett exempel på hur du ändrar konfigurationsparametrarna för ett batchprogram som skickas med cURL.
curl -k -v -H 'Content-Type: application/json' -X POST -d '{"file":"<location of application jar file>", "className":"<the application class to execute>", "args":[<application parameters>], "numExecutors":10, "executorMemory":"2G", "executorCores":5' localhost:8998/batches
Kommentar
Kopiera JAR-filen till ditt klusterlagringskonto. Kopiera inte JAR-filen direkt till huvudnoden.
Ändra dessa parametrar på en Spark Thrift Server
Spark Thrift Server ger JDBC/ODBC åtkomst till ett Spark-kluster och används för att hantera Spark SQL-frågor. Verktyg som Power BI, Tableau och så vidare använder ODBC-protokollet för att kommunicera med Spark Thrift Server för att köra Spark SQL-frågor som ett Spark-program. När ett Spark-kluster skapas startas två instanser av Spark Thrift Server, en på varje huvudnod. Varje Spark Thrift-server visas som ett Spark-program i YARN-användargränssnittet.
Spark Thrift Server använder spark-dynamisk körallokering och används därför spark.executor.instances inte. Spark Thrift Server använder spark.dynamicAllocation.maxExecutors i stället och spark.dynamicAllocation.minExecutors för att ange antalet exekutorer. Konfigurationsparametrarna spark.executor.coresoch spark.executor.memory används för att ändra körstorleken. Du kan ändra dessa parametrar enligt följande steg:
Expandera kategorin Advanced spark2-thrift-sparkconf för att uppdatera parametrarna
spark.dynamicAllocation.maxExecutorsochspark.dynamicAllocation.minExecutors.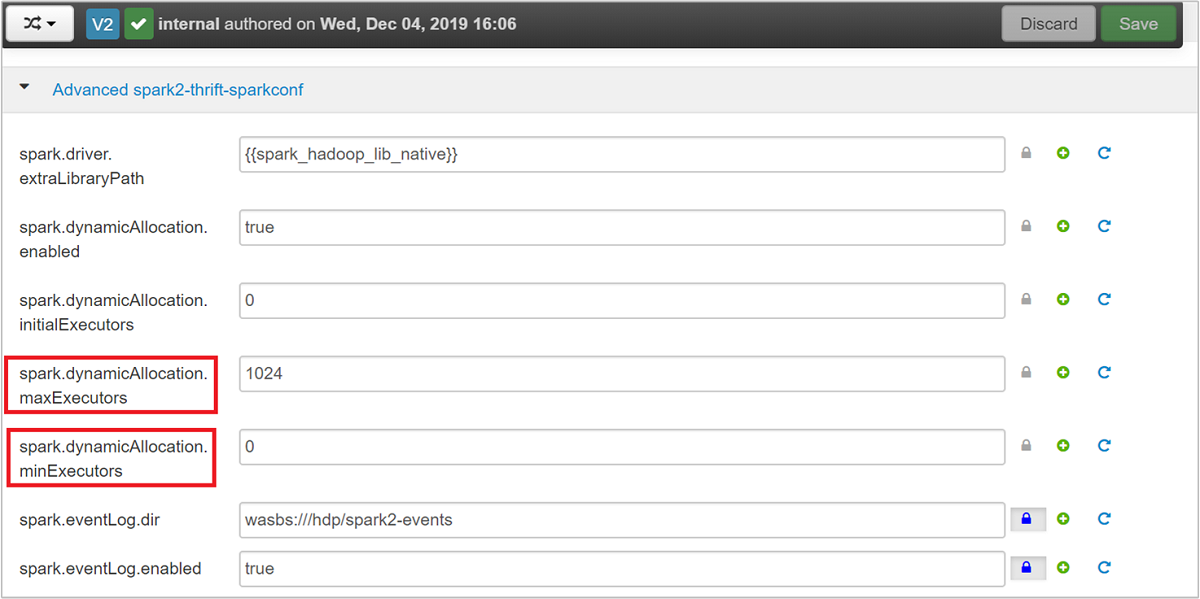
Expandera kategorin Anpassad spark2-thrift-sparkconf för att uppdatera parametrarna
spark.executor.coresochspark.executor.memory.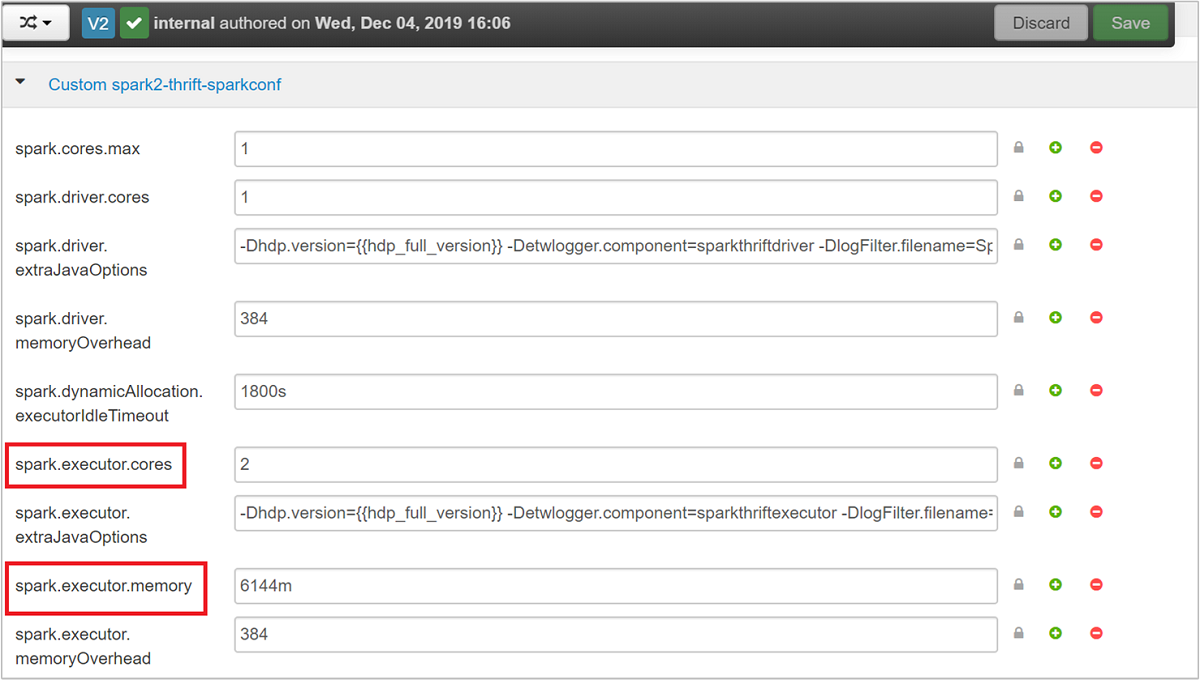
Ändra drivrutinsminnet för Spark Thrift Server
Spark Thrift Server-drivrutinsminnet är konfigurerat till 25 % av RAM-storleken för huvudnoden, förutsatt att huvudnodens totala RAM-storlek är större än 14 GB. Du kan använda Ambari-användargränssnittet för att ändra drivrutinsminneskonfigurationen, enligt följande skärmbild:
Från Ambari-användargränssnittet går du till Spark2>Configs>Advanced spark2-env. Ange sedan värdet för spark_thrift_cmd_opts.
Återta Spark-klusterresurser
På grund av dynamisk Spark-allokering är de enda resurser som förbrukas av sparsamhetsservern resurserna för de två programhanterare. Om du vill frigöra dessa resurser måste du stoppa Thrift Server-tjänsterna som körs i klustret.
Välj Spark2 i det vänstra fönstret i Ambari-användargränssnittet.
På nästa sida väljer du Spark 2 Thrift-servrar.
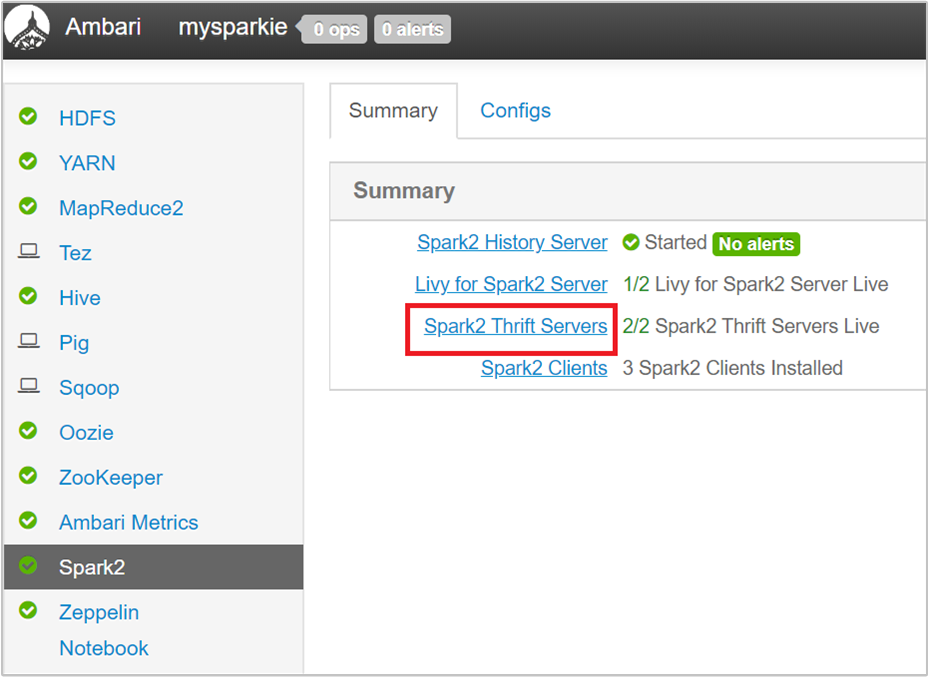
Du bör se de två huvudnoderna där Spark 2 Thrift Server körs. Välj en av huvudnoderna.
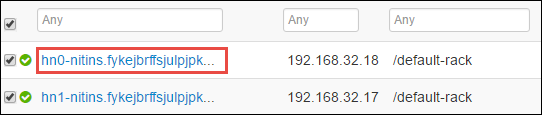
På nästa sida visas alla tjänster som körs på huvudnoden. Välj listrutan bredvid Spark 2 Thrift Server i listan och välj sedan Stoppa.
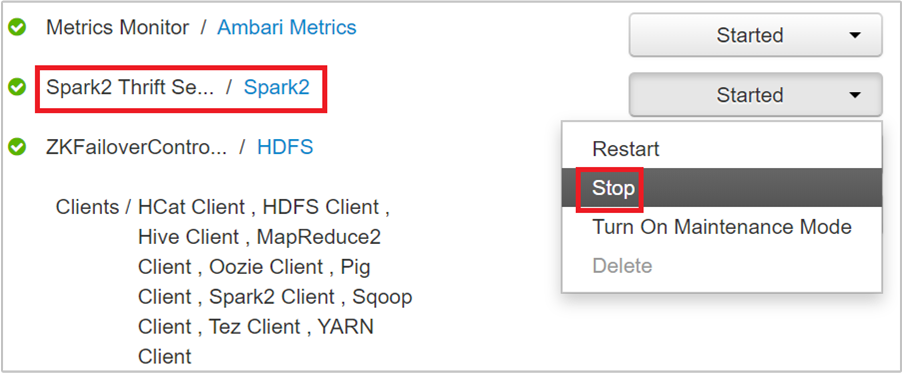
Upprepa även de här stegen på den andra huvudnoden.
Starta om Jupyter-tjänsten
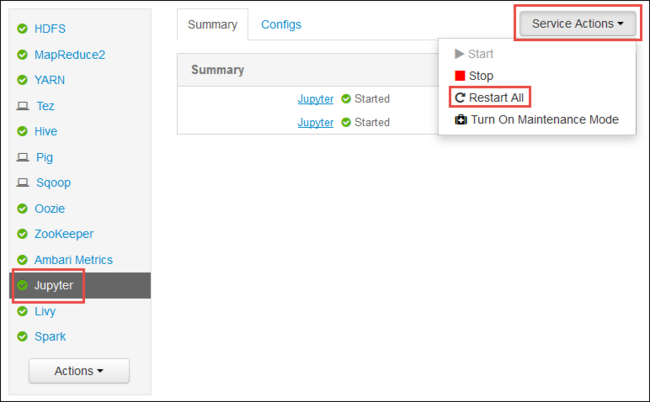
Starta webbgränssnittet för Ambari som du ser i början av artikeln. I det vänstra navigeringsfönstret väljer du Jupyter, serviceåtgärder och sedan Starta om alla. Detta startar Jupyter-tjänsten på alla huvudnoder.
Övervaka resurser
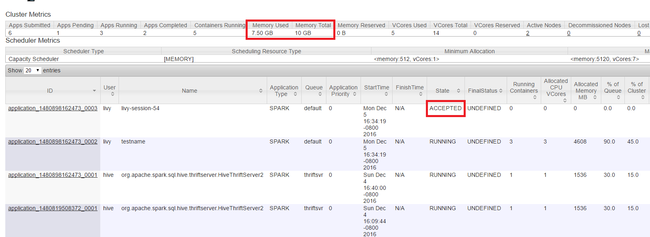
Starta Yarn-användargränssnittet enligt beskrivningen i början av artikeln. I tabellen Klustermått överst på skärmen kontrollerar du värdena för kolumnerna Minnesanvändning och Totalt minne . Om de två värdena är nära kanske det inte finns tillräckligt med resurser för att starta nästa program. Samma sak gäller för kolumnerna VCores Used och VCores Total . I huvudvyn kan det också vara en indikation på att det inte finns tillräckligt med resurser för att starta om ett program har stannat kvar i tillståndet ACCEPTERAd och inte övergår till körnings - eller FAILED-tillstånd .
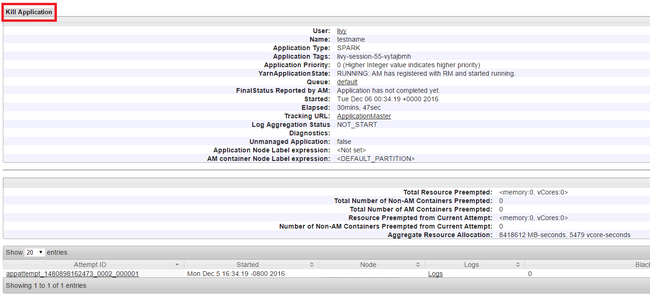
Avsluta program som körs
I yarn-användargränssnittet går du till den vänstra panelen och väljer Kör. I listan över program som körs avgör du vilket program som ska avlivas och väljer ID:t.
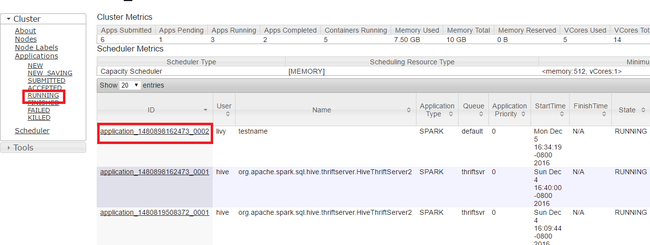
Välj Avsluta program i det övre högra hörnet och välj sedan OK.
Se även
För dataanalytiker
- Apache Spark med Machine Learning: Använda Spark i HDInsight för att analysera byggnadstemperaturen med hjälp av HVAC-data
- Apache Spark med Machine Learning: Använda Spark i HDInsight för att förutsäga resultat av livsmedelsinspektion
- Analys av webbplatsloggar med Apache Spark i HDInsight
- Application Insight-telemetridataanalys med Apache Spark i HDInsight
För Apache Spark-utvecklare
- Skapa ett fristående program med hjälp av Scala
- Köra jobb via fjärranslutning på ett Apache Spark-kluster med hjälp av Apache Livy
- Använda HDInsight Tools-plugin för IntelliJ IDEA till att skapa och skicka Spark Scala-appar
- Använda HDInsight Tools-plugin-programmet för IntelliJ IDEA för att fjärrsöka Apache Spark-program
- Använda Apache Zeppelin-notebook-filer med ett Apache Spark-kluster i HDInsight
- Kernels tillgängliga för Jupyter Notebook i Apache Spark-kluster för HDInsight
- Använda externa paket med Jupyter Notebooks
- Installera Jupyter på datorn och ansluta till ett HDInsight Spark-kluster