Snabbstart: Skapa Apache Spark-kluster i Azure HDInsight med Hjälp av Azure-portalen
I den här snabbstarten använder du Azure-portalen för att skapa ett Apache Spark-kluster i Azure HDInsight. Sedan skapar du en Jupyter Notebook och använder den för att köra Spark SQL-frågor mot Apache Hive-tabeller. Azure HDInsight är en hanterad analystjänst med fullständigt spektrum med öppen källkod för företag. Apache Spark-ramverket för HDInsight möjliggör snabb dataanalys och klusterberäkning med minnesintern bearbetning. Med Jupyter Notebook kan du interagera med dina data, kombinera kod med markdown-text och göra enkla visualiseringar.
Detaljerade förklaringar av tillgängliga konfigurationer finns i Konfigurera kluster i HDInsight. Mer information om hur du använder portalen för att skapa kluster finns i Skapa kluster i portalen.
Om du använder flera kluster tillsammans kanske du vill skapa ett virtuellt nätverk. Om du använder ett Spark-kluster kanske du också vill använda Hive Warehouse-Anslut eller. Mer information finns i Planera ett virtuellt nätverk för Azure HDInsight och Integrera Apache Spark och Apache Hive med Hive Warehouse-Anslut eller.
Viktigt!
Fakturering för HDInsight-kluster sker proportionerligt per minut, oavsett om du använder dem eller inte. Se till att du tar bort dina kluster när du är klar med dem. Mer information finns i avsnittet Rensa resurser i den här artikeln.
Förutsättningar
Ett Azure-konto med en aktiv prenumeration. Skapa ett konto utan kostnad.
Skapa ett Apache Spark-kluster i HDInsight
Du använder Azure-portalen för att skapa ett HDInsight-kluster som använder Azure Storage Blobs som klusterlagring. Mer information om att använda Data Lake Storage Gen2 finns i Snabbstart: Konfigurera kluster i HDInsight.
Logga in på Azure-portalen.
Välj + Skapa en resurs från menyn högst upp.
Välj Analytics>Azure HDInsight för att gå till sidan Skapa HDInsight-kluster.
På fliken Grundläggande anger du följande information:
Property Beskrivning Prenumeration I listrutan väljer du den Azure-prenumeration som används för klustret. Resursgrupp Välj din befintliga resursgrupp i listrutan eller välj Skapa ny. Klusternamn Ange ett globalt unikt namn. Region I listrutan väljer du en region där klustret skapas. Availability zone Valfritt – ange en tillgänglighetszon där klustret ska distribueras Klustertyp Välj klustertyp för att öppna en lista. Välj Spark i listan. Klusterversion Det här fältet fylls i automatiskt med standardversionen när klustertypen har valts. Användarnamn för klusterinloggning Ange användarnamnet för kluster-inloggningen. Standardnamnet är admin. Du använder det här kontot för att logga in på Jupyter Notebook senare i snabbstarten. Lösenord för klusterinloggning Ange lösenordet för klusterinloggningen: Secure Shell (SSH)-användarnamn Ange SSH-användarnamnet. SSH-användarnamnet som användes för den här snabbstarten är sshuser. Som standard delar här kontot samma lösenord som kontot användarnamn för klusterinloggning. 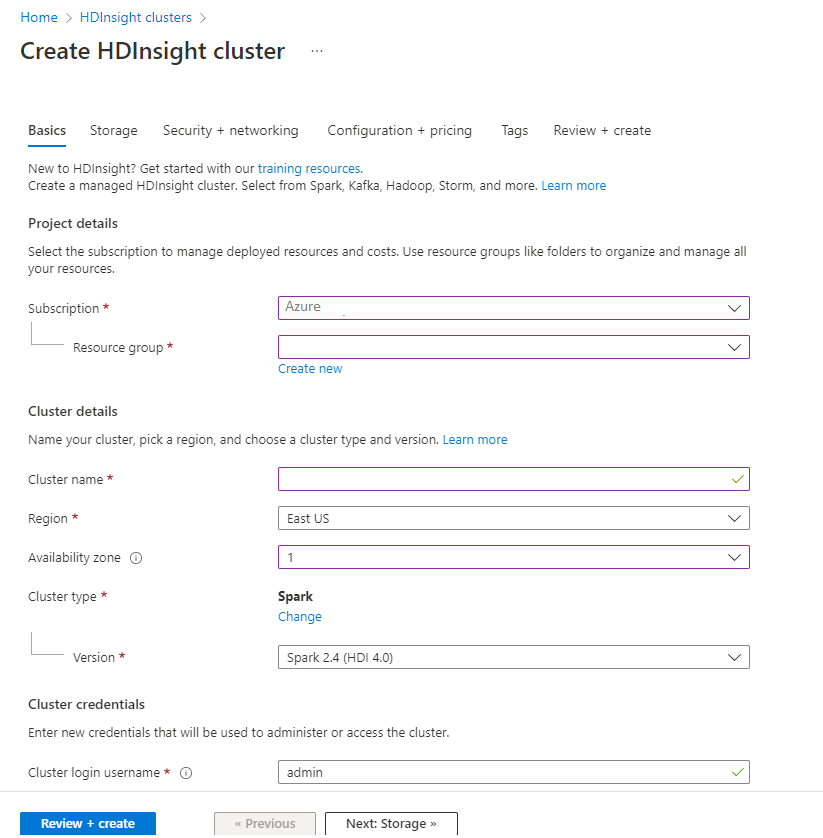
Välj Nästa: Lagring >> för att fortsätta till sidan Lagring .
Under Lagring, ange följande värden:
Property beskrivning Primär lagringstyp Använd standardvärdet Azure Storage. Urvalsmetod Använd standardvärdet Välj från lista. Primärt lagringskonto Använd det automatiskt ifyllda värdet. Container Använd det automatiskt ifyllda värdet. 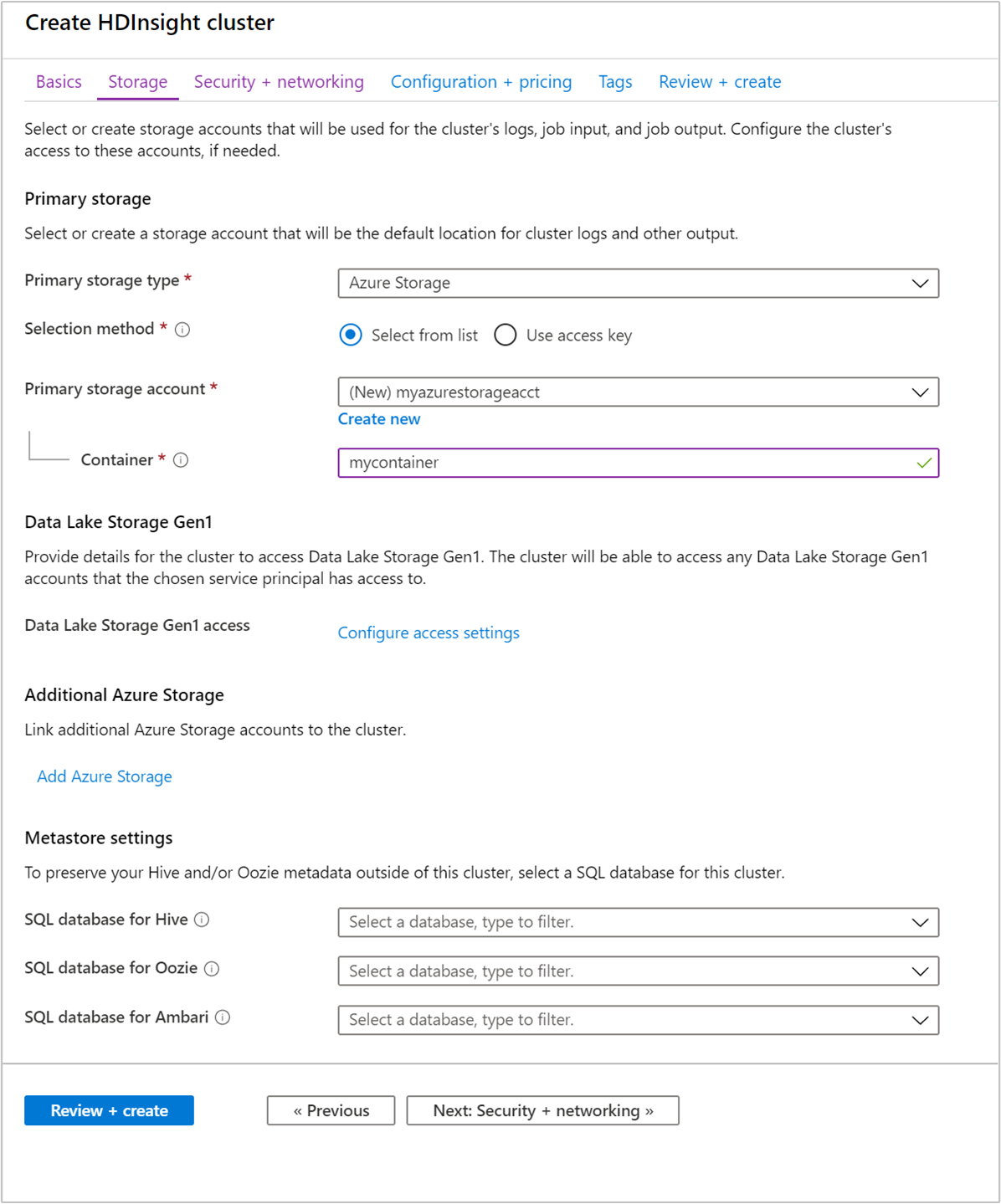
Välj Granska + skapa för att fortsätta.
Under Granska + skapa väljer du Skapa. Det tar cirka 20 minuter att skapa klustret. Klustret måste skapas innan du kan fortsätta till nästa session.
Om du stöter på ett problem med att skapa HDInsight-kluster kan det bero på att du inte har rätt behörighet att göra det. Mer information finns i åtkomstkravkontrollen.
Skapa en Jupyter Notebook
Jupyter Notebook är en interaktiv anteckningsboksmiljö som stöder flera olika datorspråk. Du kan använda anteckningsboken för att interagera med dina data, kombinera kod med markdown-text och utföra enkla visualiseringar.
Från en webbläsare går du till
https://CLUSTERNAME.azurehdinsight.net/jupyter, därCLUSTERNAMEär namnet på klustret. Ange autentiseringsuppgifterna för klustret om du uppmanas att göra det.Skapa en anteckningsbok genom att välja Ny>PySpark.
En ny anteckningsbok skapas och öppnas med namnet Untitled(Untitled.pynb).
Köra Apache Spark SQL-instruktioner
SQL (Structured Query Language) är det vanligaste språket för frågor och definition av data. Spark SQL fungerar som ett tillägg till Apache Spark för bearbetning av strukturerade data med den välbekanta SQL-syntaxen.
Verifiera att kerneln är klar. Kerneln är klar när du ser en tom cirkel bredvid kernelnamnet i den bärbara datorn. En fylld cirkel anger att kerneln är upptagen.

När du startar den bärbara datorn för första gången utför kerneln några uppgifter i bakgrunden. Vänta tills kerneln är klar.
Klistra in följande kod i en tom cell och tryck sedan på SKIFT+RETUR för att köra koden. Kommandot listar Hive-tabellerna i klustret:
%%sql SHOW TABLESNär du använder en Jupyter Notebook med ditt HDInsight-kluster får du en förinställning
sqlContextsom du kan använda för att köra Hive-frågor med Spark SQL.%%sqlanger att Jupyter Notebook ska använda den förinställdasqlContextnär Hive-frågan ska köras. Frågan hämtar de översta 10 raderna från en Hive-tabell (hivesampletable) som medföljer alla HDInsight-kluster som standard. Det tar ungefär 30 sekunder att få resultatet. Utdata ser ut så här: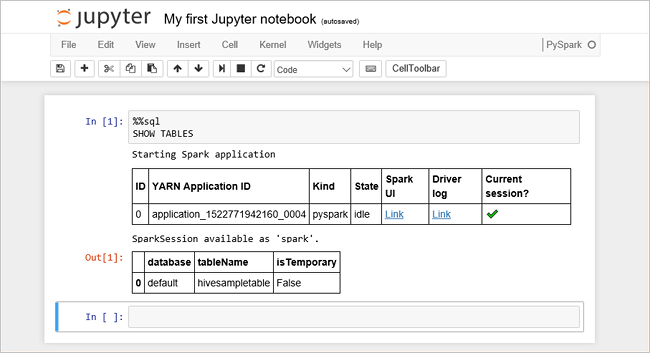 är snabbstart." border="true":::
är snabbstart." border="true":::Varje gång du kör en fråga i Jupyter visar fönsterrubriken i webbläsaren statusen (Upptagen) tillsammans med anteckningsbokens titel. Du ser även en fylld cirkel bredvid PySpark-texten i det övre högra hörnet.
Kör ytterligare en fråga för att visa data i
hivesampletable.%%sql SELECT * FROM hivesampletable LIMIT 10Skärmen bör uppdateras så att frågeresultatet visas.
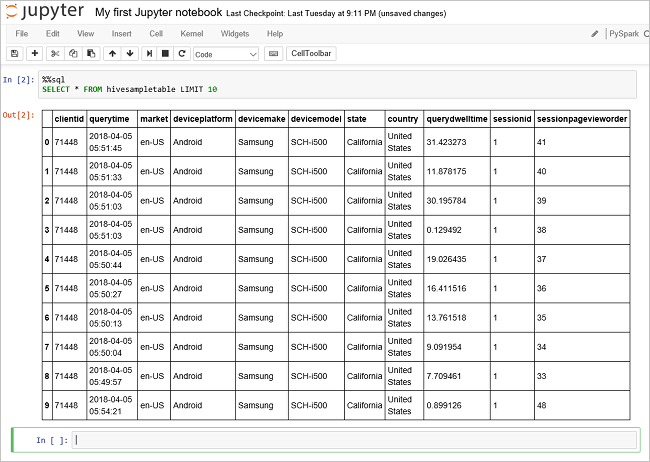 Insight" border="true":::
Insight" border="true":::Välj Stäng och stoppa på anteckningsbokens Arkiv-meny. När du stänger anteckningsboken frigörs klusterresurserna.
Rensa resurser
HDInsight sparar dina data i Azure Storage eller Azure Data Lake Storage, så att du på ett säkert sätt kan ta bort ett kluster när det inte används. Du debiteras också för ett HDInsight-kluster, även om det inte används. Eftersom avgifterna för klustret är många gånger högre än avgifterna för lagring är det ekonomiskt klokt att ta bort kluster när de inte används. Om du planerar att arbeta med självstudierna i Nästa steg direkt, kan du vilja behålla klustret.
Växla tillbaka till Azure Portal och välj Ta bort.
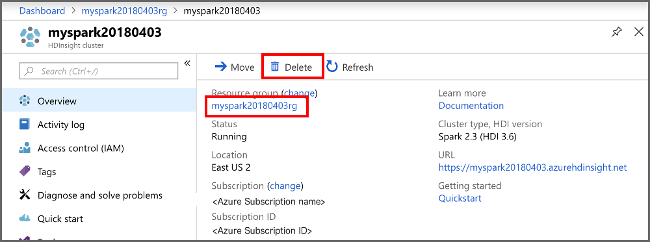 sight cluster" border="true":::
sight cluster" border="true":::
Du kan också välja resursgruppnamnet för att öppna resursgruppsidan. Välj sedan Ta bort resursgrupp. Genom att ta bort resursgruppen tar du bort både HDInsight-klustret och standardlagringskontot.
Nästa steg
I den här snabbstarten har du lärt dig hur du skapar ett Apache Spark-kluster i HDInsight och kör en grundläggande Spark SQL-fråga. Gå vidare till nästa självstudie för att lära dig hur du använder ett HDInsight-kluster för att köra interaktiva frågor på exempeldata.