Beskrivning och bearbetningssteg för RAG-datapipelines
I den här artikeln får du lära dig hur du förbereder ostrukturerade data för användning i RAG-program. Ostrukturerade data refererar till data utan en specifik struktur eller organisation, till exempel PDF-dokument som kan innehålla text och bilder eller multimediainnehåll som ljud eller videor.
Ostrukturerade data saknar en fördefinierad datamodell eller ett fördefinierade schema, vilket gör det omöjligt att fråga enbart utifrån struktur och metadata. Därför kräver ostrukturerade data tekniker som kan förstå och extrahera semantisk betydelse från rå text, bilder, ljud eller annat innehåll.
Under dataförberedelsen tar RAG-programdatapipelinen ostrukturerade rådata och omvandlar dem till diskreta segment som kan efterfrågas baserat på deras relevans för en användares fråga. De viktigaste stegen i förbearbetning av data beskrivs nedan. Varje steg har en mängd olika rattar som kan justeras - för en djupare dykdiskussion om dessa knoppar, se Förbättra RAG-programkvaliteten.
Förbereda ostrukturerade data för hämtning
I resten av det här avsnittet beskriver vi processen med att förbereda ostrukturerade data för hämtning med hjälp av semantisk sökning. Semantisk sökning förstår den kontextuella innebörden och avsikten med en användarfråga för att ge mer relevanta sökresultat.
Semantisk sökning är en av flera metoder som kan användas när du implementerar hämtningskomponenten i ett RAG-program över ostrukturerade data. Dessa dokument omfattar alternativa hämtningsstrategier i avsnittet om hämtningsknappar.
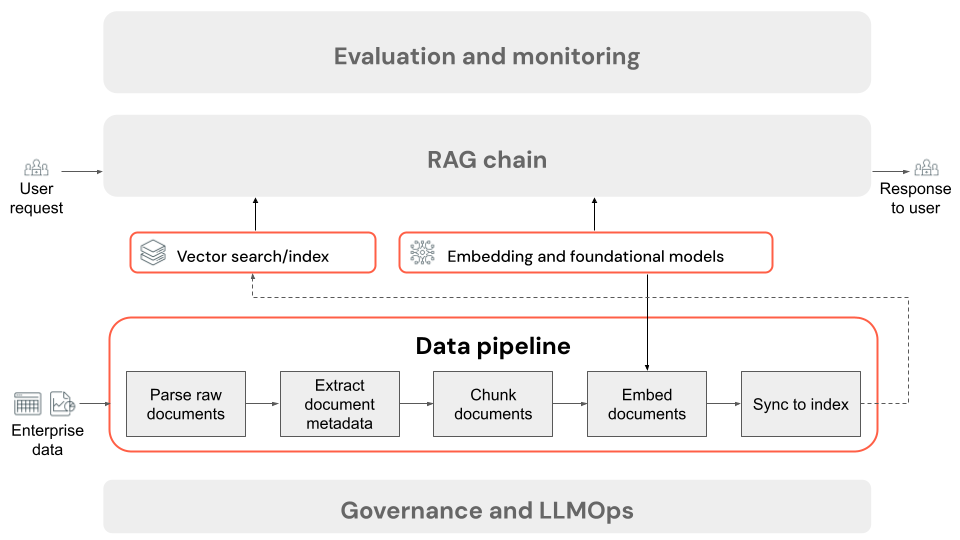
Steg i en RAG-programdatapipeline
Följande är de vanliga stegen i en datapipeline i ett RAG-program med ostrukturerade data:
- Parsa rådatadokumenten: Det första steget innebär att omvandla rådata till ett användbart format. Det kan vara att extrahera text, tabeller och bilder från en samling PDF-filer eller använda ocr-tekniker (optisk teckenigenkänning) för att extrahera text från bilder.
- Extrahera dokumentmetadata (valfritt): I vissa fall kan extrahering och användning av dokumentmetadata, till exempel dokumentrubriker, sidnummer, URL:er eller annan information hjälpa hämtningssteget att mer exakt fråga rätt data.
- Segmentdokument: För att säkerställa att de tolkade dokumenten får plats i inbäddningsmodellen och LLM:s kontextfönster delar vi upp de parsade dokumenten i mindre, diskreta segment. Om du hämtar dessa fokuserade segment i stället för hela dokument får LLM en mer riktad kontext som du kan generera svar från.
- Inbäddningssegment: I ett RAG-program som använder semantisk sökning omvandlar en särskild typ av språkmodell som kallas inbäddningsmodell vart och ett av segmenten från föregående steg till numeriska vektorer, eller listor med siffror, som kapslar in innebörden av varje innehåll. Avgörande är att dessa vektorer representerar den semantiska innebörden av texten, inte bara nyckelord på ytnivå. Detta gör det möjligt att söka baserat på innebörd snarare än literal textmatchningar.
- Indexsegment i en vektordatabas: Det sista steget är att läsa in segmentens vektorrepresentationer, tillsammans med segmentets text, till en vektordatabas. En vektordatabas är en specialiserad typ av databas som är utformad för att effektivt lagra och söka efter vektordata som inbäddningar. För att upprätthålla prestanda med ett stort antal segment innehåller vektordatabaser ofta ett vektorindex som använder olika algoritmer för att organisera och mappa vektorinbäddningarna på ett sätt som optimerar sökeffektiviteten. Vid frågetillfället bäddas en användares begäran in i en vektor och databasen använder vektorindexet för att hitta de mest liknande segmentvektorerna och returnerar motsvarande ursprungliga textsegment.
Processen för att beräkna likheter kan vara beräkningsmässigt dyr. Vektorindex, till exempel Databricks Vector Search, påskyndar processen genom att tillhandahålla en mekanism för att effektivt organisera och navigera i inbäddningar, ofta via avancerade uppskattningsmetoder. Detta möjliggör snabb rangordning av de mest relevanta resultaten utan att jämföra varje inbäddning med användarens fråga individuellt.
Varje steg i datapipelinen omfattar tekniska beslut som påverkar RAG-programmets kvalitet. Om du till exempel väljer rätt segmentstorlek i steg 3 ser du till att LLM får specifik men sammanhangsberoende information, medan valet av en lämplig inbäddningsmodell i steg 4 avgör noggrannheten för segmenten som returneras under hämtningen.
Den här dataförberedelseprocessen kallas för förberedelse av offlinedata, eftersom den sker innan systemet svarar på frågor, till skillnad från onlinestegen som utlöses när en användare skickar en fråga.