Sökning efter mosaik-AI-vektorer
Den här artikeln ger en översikt över Databricks vektordatabaslösning, Mosaic AI Vector Search, inklusive vad den är och hur den fungerar.
Vad är Mosaic AI Vector Search?
Mosaic AI Vector Search är en vektordatabas som är inbyggd i Databricks Data Intelligence Platform och integrerad med dess styrnings- och produktivitetsverktyg. En vektordatabas är en databas som är optimerad för att lagra och hämta inbäddningar. Inbäddningar är matematiska representationer av det semantiska innehållet i data, vanligtvis text- eller bilddata. Inbäddningar genereras av en stor språkmodell och är en viktig komponent i många generativa AI-program som är beroende av att hitta dokument eller bilder som liknar varandra. Exempel är RAG-system, rekommenderade system samt bild- och videoigenkänning.
Med Mosaic AI Vector Search skapar du ett vektorsökningsindex från en Delta-tabell. Indexet innehåller inbäddade data med metadata. Du kan sedan köra frågor mot indexet med hjälp av ett REST-API för att identifiera de mest liknande vektorerna och returnera de associerade dokumenten. Du kan strukturera indexet så att det synkroniseras automatiskt när den underliggande Delta-tabellen uppdateras.
Mosaic AI Vector Search stöder följande:
- Hybridsök med nyckelordslikhet.
- Filtrering
- Åtkomstkontrollistor (ACL: er) för att hantera slutpunkter för vektorsökning.
- Synkronisera endast markerade kolumner.
- Spara och synkronisera genererade inbäddningar.
Hur fungerar Mosaic AI Vector Search?
Mosaic AI Vector Search använder HNSW-algoritmen (Hierarchical Navigable Small World) för sina ungefärliga närmsta grannsökningar och måttet för L2-avståndsavstånd för att mäta inbäddningsvektorlikhet. Om du vill använda cosinélikhet måste du normalisera dina inbäddningar för datapunkter innan du matar in dem i vektorsökning. När datapunkterna normaliseras är rangordningen som genereras av L2-avståndet samma som rangordningen ger av cosinélikhet.
Mosaic AI Vector Search stöder även sökning med nyckelordslikhet i hybrid, som kombinerar vektorbaserad inbäddningssökning med traditionella nyckelordsbaserade söktekniker. Den här metoden matchar exakta ord i frågan samtidigt som en vektorbaserad likhetssökning används för att samla in frågans semantiska relationer och kontext.
Genom att integrera dessa två tekniker hämtar hybridsök med nyckelordslikhet dokument som inte bara innehåller de exakta nyckelorden utan även de som är konceptuellt lika, vilket ger mer omfattande och relevanta sökresultat. Den här metoden är särskilt användbar i RAG-program där källdata har unika nyckelord som SKU:er eller identifierare som inte passar bra för ren likhetssökning.
Mer information om API:et finns i Python SDK-referensen och Fråga en slutpunkt för vektorsökning.
Beräkning av likhetssökning
Likhetssökningsberäkningen använder följande formel:
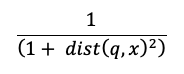
där dist är euklidiska avståndet mellan frågan q och indexposten x:
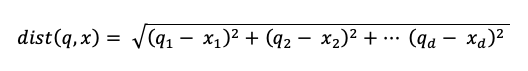
Algoritm för nyckelordssökning
Relevanspoäng beräknas med okapi BM25. Alla text- eller strängkolumner genomsöks, inklusive inbäddning av källtext och metadatakolumner i text- eller strängformat. Tokeniseringsfunktionen delar upp vid ordgränser, tar bort skiljetecken och konverterar all text till gemener.
Hur likhetssökning och nyckelordssökning kombineras
Sökresultaten för likhetssökning och nyckelord kombineras med funktionen Reciprocal Rank Fusion (RRF).
RRF beräknar om varje dokuments poäng från varje metod.
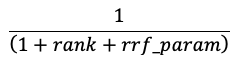
I ekvationen ovan börjar rangordningen vid 0, summerar poängen för varje dokument och returnerar de dokument med högst poäng.
rrf_param styr den relativa betydelsen av högre rankade och lägre rankade dokument. Baserat på litteraturen är rrf_param satt till 60.
Poängen normaliseras så att den högsta poängen är 1 och den lägsta poängen är 0 med hjälp av följande ekvation:
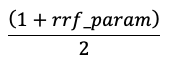
Alternativ för att tillhandahålla vektorbäddningar
Om du vill skapa en vektordatabas i Databricks måste du först bestämma hur vektorbäddningar ska tillhandahållas. Databricks har stöd för tre alternativ:
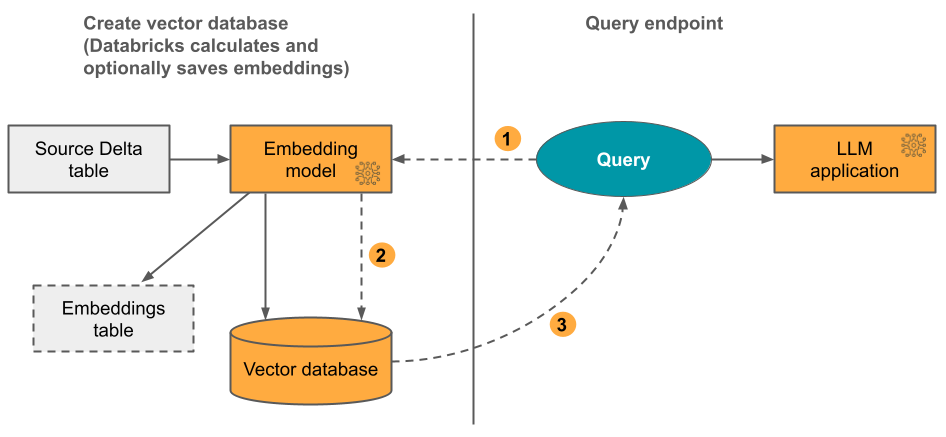
Alternativ 1: Delta Sync Index med inbäddningar som beräknas av Databricks Du anger en Delta-källtabell som innehåller data i textformat. Databricks beräknar inbäddningarna med hjälp av en modell som du anger och kan också spara inbäddningarna i en tabell i Unity Catalog. När deltatabellen uppdateras förblir indexet synkroniserat med Delta-tabellen.
Följande diagram illustrerar processen:
- Beräkna frågeinbäddningar. Frågan kan innehålla metadatafilter.
- Utför likhetssökning för att identifiera de mest relevanta dokumenten.
- Returnera de mest relevanta dokumenten och lägg till dem i frågan.
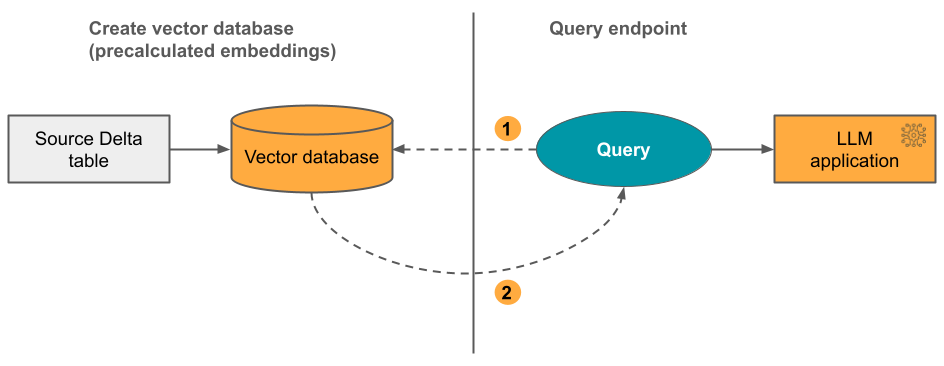
Alternativ 2: Delta Sync Index med självhanterade inbäddningar Du anger en Delta-källtabell som innehåller förberäknade inbäddningar. När deltatabellen uppdateras förblir indexet synkroniserat med Delta-tabellen.
Följande diagram illustrerar processen:
- Frågan består av inbäddningar och kan innehålla metadatafilter.
- Utför likhetssökning för att identifiera de mest relevanta dokumenten. Returnera de mest relevanta dokumenten och lägg till dem i frågan.
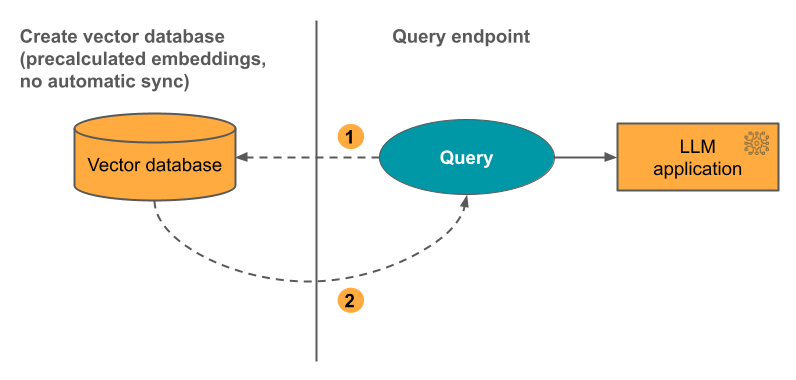
Alternativ 3: Direktvektoråtkomstindex Du måste uppdatera indexet manuellt med rest-API:et när inbäddningstabellen ändras.
Följande diagram illustrerar processen:
Så här konfigurerar du Mosaic AI Vector Search
Om du vill använda Mosaic AI Vector Search måste du skapa följande:
En slutpunkt för vektorsökning. Den här slutpunkten hanterar vektorsökningsindexet. Du kan fråga och uppdatera slutpunkten med hjälp av REST-API:et eller SDK:n. Anvisningar finns i Skapa en slutpunkt för vektorsökning.
Slutpunkter skalas upp automatiskt för att stödja indexets storlek eller antalet samtidiga begäranden. Slutpunkter skalas inte ned automatiskt.
Ett vektorsökningsindex. Vektorsökningsindexet skapas från en Delta-tabell och är optimerat för att ge ungefärliga närmsta grannsökningar i realtid. Målet med sökningen är att identifiera dokument som liknar frågan. Vektorsökningsindex visas i och styrs av Unity Catalog. Anvisningar finns i Skapa ett vektorsökningsindex .
Om du väljer att låta Databricks beräkna inbäddningarna kan du dessutom använda en förkonfigurerad Foundation Model-API:er-slutpunkt eller skapa en modell som betjänar slutpunkten för att hantera den inbäddningsmodell du väljer. Anvisningar finns i Betala per token Foundation Model API:er eller Skapa slutpunkter för betjäning av grundmodell.
Om du vill köra frågor mot modellens serverslutpunkt använder du antingen REST-API:et eller Python SDK. Din fråga kan definiera filter baserat på valfri kolumn i Delta-tabellen. Mer information finns i Använda filter för frågor, API-referensen eller Python SDK-referensen.
Krav
- Unity Catalog-aktiverad arbetsyta.
- Serverlös beräkning aktiverad. Anvisningar finns i Ansluta till serverlös beräkning.
- Källtabellen måste ha Ändringsdataflöde aktiverat. Anvisningar finns i Använda Delta Lake-ändringsdataflöde i Azure Databricks.
- Om du vill skapa ett vektorsökningsindex måste du ha CREATE TABLE behörigheter i katalogschemat där indexet skapas.
Behörighet att skapa och hantera slutpunkter för vektorsökning konfigureras med hjälp av åtkomstkontrollistor. Se slutpunkts-ACL:er för vektorsökning.
Dataskydd och autentisering
Databricks implementerar följande säkerhetskontroller för att skydda dina data:
- Varje kundbegäran till Mosaic AI Vector Search är logiskt isolerad, autentiserad och auktoriserad.
- Mosaic AI Vector Search krypterar alla vilande data (AES-256) och under överföring (TLS 1.2+).
Mosaic AI Vector Search stöder två autentiseringslägen, tjänstens huvudnamn och personliga åtkomsttoken (PAT). För produktionsprogram rekommenderar Databricks att du använder tjänsteprincipaler, vilket kan ha en hastighet per förfrågan upp till 100 ms snabbare i förhållande till personliga åtkomsttoken.
Token för tjänstens huvudidentitet. En administratör kan generera en token för tjänstens huvudnamn och skicka den till SDK:n eller API:et. Se använda tjänstens huvudnamn. För användningsfall i produktion rekommenderar Databricks att du använder en service principal-token.
# Pass in a service principal vsc = VectorSearchClient(workspace_url="...", service_principal_client_id="...", service_principal_client_secret="..." )Personlig åtkomsttoken. Du kan använda en personlig åtkomsttoken för att autentisera med Mosaic AI Vector Search. Se autentiseringstoken för personlig åtkomst. Om du använder SDK:t i en notebook-miljö genererar SDK automatiskt en PAT-token för autentisering.
# Pass in the PAT token client = VectorSearchClient(workspace_url="...", personal_access_token="...")
Kundhanterade nycklar (CMK) stöds på slutpunkter som skapats den 8 maj 2024 eller senare.
Övervaka användning och kostnader
Med den fakturerbara användningssystemtabellen kan du övervaka användning och kostnader som är associerade med vektorsökningsindex och slutpunkter. Här är en exempelfråga:
WITH all_vector_search_usage (
SELECT *,
CASE WHEN usage_metadata.endpoint_name IS NULL THEN 'ingest'
WHEN usage_type = "STORAGE_SPACE" THEN 'storage'
ELSE 'serving'
END as workload_type
FROM system.billing.usage
WHERE billing_origin_product = 'VECTOR_SEARCH'
),
daily_dbus AS (
SELECT workspace_id,
cloud,
usage_date,
workload_type,
usage_metadata.endpoint_name as vector_search_endpoint,
CASE WHEN workload_type = 'serving' THEN SUM(usage_quantity)
WHEN workload_type = 'ingest' THEN SUM(usage_quantity)
ELSE null
END as dbus,
CASE WHEN workload_type = 'storage' THEN SUM(usage_quantity)
ELSE null
END as dsus
FROM all_vector_search_usage
GROUP BY all
ORDER BY 1,2,3,4,5 DESC
)
SELECT * FROM daily_dbus
Mer information om innehållet i tabellen för faktureringsanvändning finns i tabellreferens för fakturerbart användningssystem. Ytterligare frågor finns i följande notebook-exempel.
Vektorsökningssystem, tabeller, sökfrågor och anteckningsbok
Begränsningar för resurs- och datastorlek
I följande tabell sammanfattas resurs- och datastorleksgränser för slutpunkter och index för vektorsökning:
| Resurs | Detaljnivå | Gräns |
|---|---|---|
| Slutpunkter för vektorsökning | Per arbetsyta | 100 |
| Inbäddningar | Per slutpunkt | 320 000 000 |
| Inbäddningsdimension | Per indexen | 4096 |
| Indexar | Per ändpunkt | 50 |
| Kolumner | För varje index | 50 |
| Kolumner | Typer som stöds: Bytes, short, integer, long, float, double, boolean, string, tidsstämpel, datum | |
| Metadatafält | Per index | 50 |
| Indexnamn | Per index | 128 tecken |
Följande begränsningar gäller för skapande och uppdatering av vektorsökningsindex:
| Resurs | Detaljnivå | Gräns |
|---|---|---|
| Radstorlek för Delta Sync Index | Enligt index | 100 KB |
| Bädda in källkolumnstorlek för Delta Sync-index | per index | 32764 byte |
| Storleksgräns för massuppsertbegäran för Direct Vector-index | Enligt index | 10 MB |
| Storleksgräns för massborttagningsbegäran för Direct Vector-index | Per Index | 10 MB |
Följande begränsningar gäller för fråge-API:et.
| Resurs | Detaljnivå | Gräns |
|---|---|---|
| Frågetextlängd | Per fråga | 32764 byte |
| Maximalt antal returnerade resultat | Per fråga | 10 000 |
Begränsning
Behörigheter på rad- och kolumnnivå stöds inte. Du kan dock implementera dina egna ACL:er på programnivå med hjälp av filter-API:et.