Förbättra RAG-programkvaliteten
Den här artikeln innehåller en översikt över hur du kan förfina varje komponent för att öka kvaliteten på ditt RAG-program (retrieval augmented generation).
Det finns otaliga "knoppar" att justera vid varje punkt i både offline-datapipelinen och online-RAG-kedjan. Även om det finns otaliga andra fokuserar artikeln på de viktigaste rattarna som har störst inverkan på kvaliteten på ditt RAG-program. Databricks rekommenderar att du börjar med dessa rattar.
Två typer av kvalitetsöverväganden
Ur konceptuell synvinkel är det bra att se RAG-kvalitetsknoppar genom linsen för de två viktigaste typerna av kvalitetsproblem:
Hämtningskvalitet: Hämtar du den mest relevanta informationen för en viss hämtningsfråga?
Det är svårt att generera högkvalitativa RAG-utdata om kontexten som tillhandahålls till LLM saknar viktig information eller innehåller överflödig information.
Generationskvalitet: Med tanke på den hämtade informationen och den ursprungliga användarfrågan genererar LLM det mest exakta, sammanhängande och användbara svaret?
Problem här kan visas som hallucinationer, inkonsekventa utdata eller underlåtenhet att direkt hantera användarfrågan.
RAG-appar har två komponenter som kan itereras för att hantera kvalitetsutmaningar: datapipeline och kedjan. Det är frestande att anta en ren uppdelning mellan hämtningsproblem (uppdatera helt enkelt datapipelinen) och genereringsproblem (uppdatera RAG-kedjan). Verkligheten är dock mer nyanserad. Hämtningskvaliteten kan påverkas av både datapipelinen (till exempel parsning/segmenteringsstrategi, metadatastrategi, inbäddningsmodell) och RAG-kedjan (till exempel omvandling av användarfrågor, antal segment som hämtats, omrankning). På samma sätt påverkas produktionskvaliteten alltid av dålig hämtning (till exempel irrelevant eller saknad information som påverkar modellutdata).
Överlappningen understryker behovet av en holistisk metod för kvalitetsförbättring av RAG. Genom att förstå vilka komponenter som ska ändras i både datapipelinen och RAG-kedjan och hur dessa ändringar påverkar den övergripande lösningen kan du göra riktade uppdateringar för att förbättra RAG-utdatakvaliteten.
Kvalitetsöverväganden för datapipelines
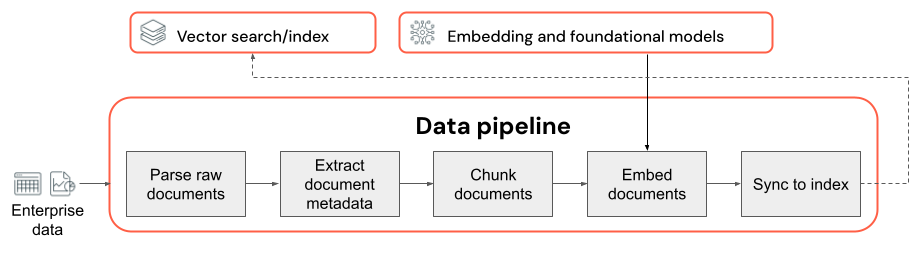
Viktiga överväganden om datapipelinen:
- Sammansättningen av indata corpus.
- Hur rådata extraheras och omvandlas till ett användbart format (till exempel parsning av ett PDF-dokument).
- Hur dokument delas upp i mindre segment och hur dessa segment formateras (till exempel segmenteringsstrategi och segmentstorlek).
- Metadata (t.ex. avsnittsrubrik eller dokumentrubrik) som extraheras om varje dokument och/eller segment. Hur dessa metadata inkluderas (eller ingår inte) i varje segment.
- Inbäddningsmodellen som används för att konvertera text till vektorrepresentationer för likhetssökning.
RAG-kedja
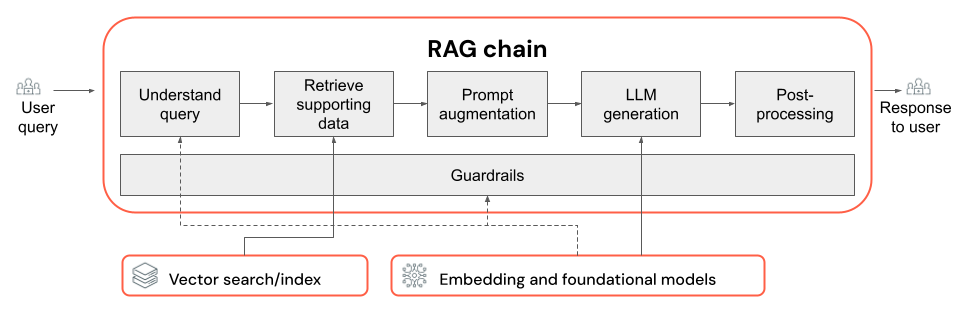
- Valet av LLM och dess parametrar (till exempel temperatur och maxtoken).
- Hämtningsparametrarna (till exempel antalet segment eller dokument som hämtats).
- Hämtningsmetoden (till exempel nyckelord kontra hybrid eller semantisk sökning, omskrivning av användarens fråga, transformering av en användares fråga till filter eller omrankning).
- Så här formaterar du prompten med den hämtade kontexten för att vägleda LLM mot kvalitetsutdata.