RAG-kedja för slutsatsdragning
Den här artikeln beskriver den process som inträffar när användaren skickar en begäran till RAG-programmet i en onlineinställning. När data har bearbetats av datapipelinen är de lämpliga att användas i RAG-programmet. Serien eller kedjan med steg som anropas vid slutsatsdragningstid kallas ofta FÖR RAG-kedjan.
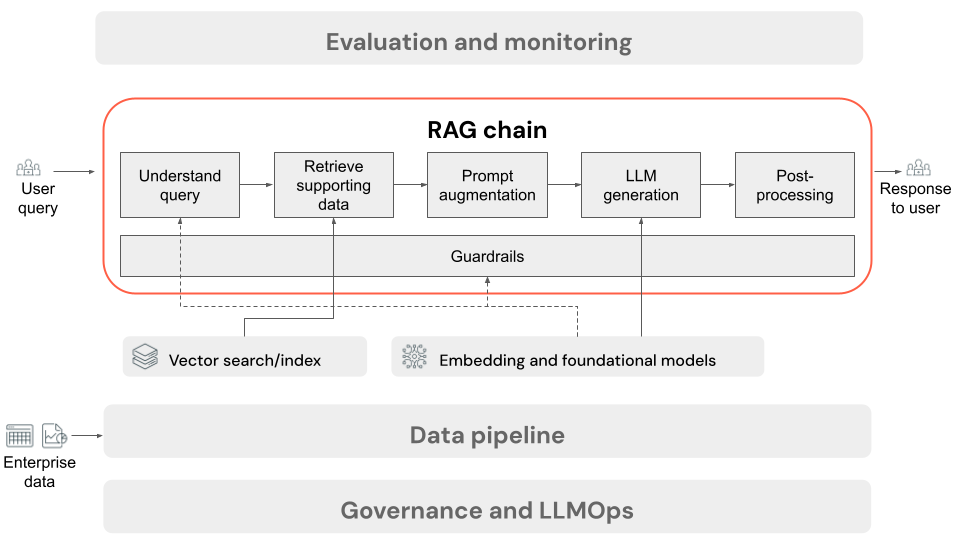
- (Valfritt) Förbearbetning av användarfrågor: I vissa fall är användarens fråga förbearbetad för att göra den mer lämplig för att köra frågor mot vektordatabasen. Det kan handla om att formatera frågan i en mall, använda en annan modell för att skriva om begäran eller extrahera nyckelord för att underlätta hämtningen. Utdata från det här steget är en hämtningsfråga som ska användas i det efterföljande hämtningssteget.
- Hämtning: För att hämta stödinformation från vektordatabasen översätts hämtningsfrågan till en inbäddning med samma inbäddningsmodell som användes för att bädda in dokumentsegmenten under förberedelsen av data. Dessa inbäddningar möjliggör jämförelse av den semantiska likheten mellan hämtningsfrågan och de ostrukturerade textsegmenten med hjälp av mått som cosinélikhet. Därefter hämtas segment från vektordatabasen och rangordnas baserat på hur lika de är för den inbäddade begäran. De översta (mest liknande) resultaten returneras.
- Uppmaningsförstoring: Uppmaningen som ska skickas till LLM skapas genom att utöka användarens fråga med den hämtade kontexten, i en mall som instruerar modellen hur varje komponent ska användas, ofta med ytterligare instruktioner för att styra svarsformatet. Processen att iterera på rätt promptmall som ska användas kallas promptteknik.
- LLM-generering: LLM tar den förhöjda prompten, som innehåller användarens fråga och hämtade stöddata som indata. Sedan genereras ett svar som baseras på den ytterligare kontexten.
- (Valfritt) Efterbearbetning: LLM:s svar kan bearbetas ytterligare för att tillämpa ytterligare affärslogik, lägga till citat eller på annat sätt förfina den genererade texten baserat på fördefinierade regler eller begränsningar.
Precis som med RAG-programdatapipelinen finns det många efterföljande tekniska beslut som kan påverka kvaliteten på RAG-kedjan. Om du till exempel fastställer hur många segment som ska hämtas i steg 2 och hur du kombinerar dem med användarens fråga i steg 3 kan det avsevärt påverka modellens förmåga att generera kvalitetssvar.
I hela kedjan kan olika skyddsräcken tillämpas för att säkerställa efterlevnad av företagsprinciper. Detta kan innebära filtrering för lämpliga begäranden, kontroll av användarbehörigheter innan du får åtkomst till datakällor och tillämpning av metoder för kon tältläge ration för de genererade svaren.