Förbättra kvaliteten på RAG-kedjan
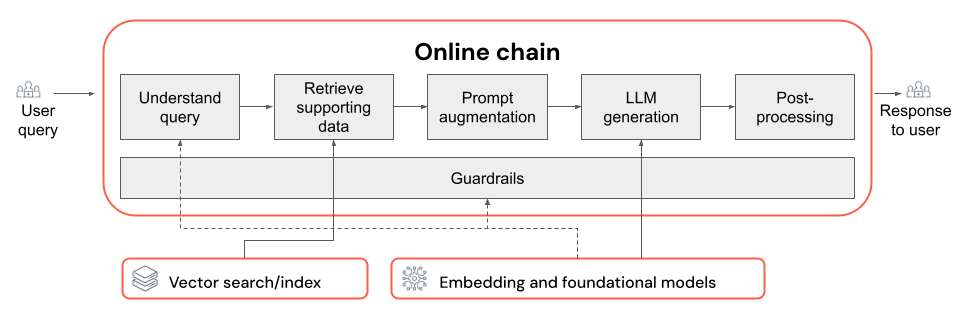
Den här artikeln beskriver hur du kan förbättra kvaliteten på RAG-appen med hjälp av komponenter i RAG-kedjan.
RAG-kedjan tar en användarfråga som indata, hämtar relevant information med tanke på frågan och genererar ett lämpligt svar baserat på hämtade data. Även om de exakta stegen i en RAG-kedja kan variera mycket beroende på användningsfall och krav, är följande viktiga komponenter att tänka på när du skapar din RAG-kedja:
- Frågetolkning: Analysera och transformera användarfrågor för att bättre representera avsikten och extrahera relevant information, till exempel filter eller nyckelord, för att förbättra hämtningsprocessen.
- Hämtning: Hitta de mest relevanta informationssegmenten med en hämtningsfråga. I det ostrukturerade datafallet omfattar detta vanligtvis en eller en kombination av semantisk eller nyckelordsbaserad sökning.
- Uppmaningsförstoring: Kombinera en användarfråga med hämtad information och instruktioner för att vägleda LLM mot att generera högkvalitativa svar.
- LLM: Välja den lämpligaste modellen (och modellparametrarna) för ditt program för att optimera/balansera prestanda, svarstid och kostnad.
- Efterbearbetning och skyddsräcken: Tillämpa ytterligare bearbetningssteg och säkerhetsåtgärder för att säkerställa att LLM-genererade svar är aktuella, sakligt konsekventa och följer specifika riktlinjer eller begränsningar.
Iterativt implementera och utvärdera kvalitetskorrigeringar visar hur du itererar över komponenterna i en kedja.
Frågetolkning
Att använda användarfrågan direkt som en hämtningsfråga kan fungera för vissa frågor. Det är dock allmänt fördelaktigt att omformulera frågan före hämtningssteget. Frågetolkning består av ett steg (eller en serie steg) i början av en kedja för att analysera och transformera användarfrågor för att bättre representera avsikten, extrahera relevant information och slutligen hjälpa den efterföljande hämtningsprocessen. Metoder för att transformera en användarfråga för att förbättra hämtningen är:
Frågeomskrivning: Frågeomskrivning innebär att översätta en användarfråga till en eller flera frågor som bättre representerar den ursprungliga avsikten. Målet är att omformulera frågan på ett sätt som ökar sannolikheten för att hämtningssteget hittar de mest relevanta dokumenten. Detta kan vara särskilt användbart när du hanterar komplexa eller tvetydiga frågor som kanske inte direkt matchar terminologin som används i hämtningsdokumenten.
Exempel:
- Parafrasera konversationshistorik i en chatt med flera turer
- Korrigera stavfel i användarens fråga
- Ersätta ord eller fraser i användarfrågan med synonymer för att samla in ett bredare utbud av relevanta dokument
Viktigt!
Frågeomskrivning måste göras tillsammans med ändringar i hämtningskomponenten
Extrahering av filter: I vissa fall kan användarfrågor innehålla specifika filter eller kriterier som kan användas för att begränsa sökresultaten. Filterextrahering innebär att identifiera och extrahera dessa filter från frågan och skicka dem till hämtningssteget som ytterligare parametrar. Detta kan bidra till att förbättra relevansen för de hämtade dokumenten genom att fokusera på specifika delmängder av tillgängliga data.
Exempel:
- Extrahera specifika tidsperioder som nämns i frågan, till exempel "artiklar från de senaste 6 månaderna" eller "rapporter från 2023".
- Identifiera omnämnanden av specifika produkter, tjänster eller kategorier i frågan, till exempel "Databricks Professional Services" eller "bärbara datorer".
- Extrahera geografiska entiteter från frågan, till exempel stadsnamn eller landskoder.
Anteckning
Filterextrahering måste göras tillsammans med ändringar i både metadataextraheringsdatapipelinen och komponenterna i hämtningskedjan. Steget för extrahering av metadata bör se till att relevanta metadatafält är tillgängliga för varje dokument/segment, och hämtningssteget bör implementeras för att acceptera och tillämpa extraherade filter.
Förutom frågeskrivning och extrahering av filter är en annan viktig faktor i frågetolkningen om du vill använda ett enda LLM-anrop eller flera anrop. Det kan vara effektivt att använda ett enda anrop med en noggrant utformad fråga, men det finns fall där en uppdelning av frågetolkningsprocessen i flera LLM-anrop kan leda till bättre resultat. Detta är förresten en allmänt tillämplig tumregel när du försöker implementera ett antal komplexa logiksteg i en enda fråga.
Du kan till exempel använda ett LLM-anrop för att klassificera fråge avsikten, en annan för att extrahera relevanta entiteter och en tredje för att skriva om frågan baserat på den extraherade informationen. Även om den här metoden kan lägga till viss svarstid i den övergripande processen kan den ge mer detaljerad kontroll och potentiellt förbättra kvaliteten på de hämtade dokumenten.
Frågetolkning i flera steg för en supportrobot
Så här kan en komponent för frågetolkning i flera steg leta efter en kundsupportrobot:
- Avsiktsklassificering: Använd en LLM för att klassificera användarens fråga i fördefinierade kategorier, till exempel "produktinformation", "felsökning" eller "kontohantering".
- Entitetsextrahering: Baserat på den identifierade avsikten använder du ett annat LLM-anrop för att extrahera relevanta entiteter från frågan, till exempel produktnamn, rapporterade fel eller kontonummer.
- Frågeomskrivning: Använd den extraherade avsikten och entiteterna för att skriva om den ursprungliga frågan till ett mer specifikt och målformat, till exempel "Min RAG-kedja kan inte distribueras i modellservern, jag ser följande fel...".
Hämtning
Hämtningskomponenten i RAG-kedjan ansvarar för att hitta de mest relevanta informationssegmenten med en hämtningsfråga. När det gäller ostrukturerade data innebär hämtning vanligtvis en eller en kombination av semantisk sökning, nyckelordsbaserad sökning och metadatafiltrering. Valet av hämtningsstrategi beror på programmets specifika krav, typen av data och vilka typer av frågor du förväntar dig att hantera. Nu ska vi jämföra de här alternativen:
- Semantisk sökning: Semantisk sökning använder en inbäddningsmodell för att konvertera varje textsegment till en vektorrepresentation som fångar dess semantiska betydelse. Genom att jämföra vektorrepresentationen av hämtningsfrågan med segmentens vektorrepresentationer kan semantisk sökning hämta konceptuellt liknande dokument, även om de inte innehåller de exakta nyckelorden från frågan.
- Nyckelordsbaserad sökning: Nyckelordsbaserad sökning avgör relevansen av dokument genom att analysera frekvensen och fördelningen av delade ord mellan hämtningsfrågan och de indexerade dokumenten. Ju oftare samma ord visas i både frågan och ett dokument, desto högre relevanspoäng tilldelas det dokumentet.
- Hybridsökning: Hybridsökning kombinerar fördelarna med både semantisk och nyckelordsbaserad sökning genom att använda en tvåstegsprocess för hämtning. Först utför den en semantisk sökning för att hämta en uppsättning konceptuellt relevanta dokument. Sedan tillämpas nyckelordsbaserad sökning på den här reducerade uppsättningen för att ytterligare förfina resultaten baserat på exakta nyckelordsmatchningar. Slutligen kombineras poängen från båda stegen för att rangordna dokumenten.
Jämföra hämtningsstrategier
I följande tabell kontrasterar var och en av dessa hämtningsstrategier mot varandra:
| Semantisk sökning | Nyckelordssökning | Hybridsökning | |
|---|---|---|---|
| Enkel förklaring | Om samma begrepp visas i frågan och ett potentiellt dokument är de relevanta. | Om samma ord visas i frågan och ett potentiellt dokument är de relevanta. Ju fler ord från frågan i dokumentet, desto mer relevant är dokumentet. | Kör BÅDE en semantisk sökning och nyckelordssökning och kombinerar sedan resultatet. |
| Exempel på användningsfall | Kundsupport där användarfrågor skiljer sig från orden i produkthandböckerna. Exempel: "hur aktiverar jag min telefon?" och det manuella avsnittet kallas "växla strömmen". | Kundsupport där frågor innehåller specifika, icke beskrivande tekniska termer. Exempel: "vad gör modellen HD7-8D?" | Kundsupportfrågor som kombinerar både semantiska och tekniska termer. Exempel: "Hur aktiverar jag min HD7-8D?" |
| Tekniska metoder | Använder inbäddningar för att representera text i ett kontinuerligt vektorutrymme, vilket möjliggör semantisk sökning. | Förlitar sig på diskreta tokenbaserade metoder som bag-of-words, TF-IDF, BM25 för nyckelordsmatchning. | Använd en omrankningsmetod för att kombinera resultaten, till exempel reciprocal rank fusion eller en omrankningsmodell. |
| Styrkor | Hämtar kontextuellt liknande information som en fråga, även om de exakta orden inte används. | Scenarier som kräver exakta nyckelordsmatchningar, perfekt för specifika termfokuserade frågor som produktnamn. | Kombinerar det bästa av båda metoderna. |
Sätt att förbättra hämtningsprocessen
Utöver dessa grundläggande hämtningsstrategier finns det flera tekniker som du kan använda för att ytterligare förbättra hämtningsprocessen:
- Frågeexpansion: Frågeexpansion kan hjälpa dig att samla in ett bredare utbud av relevanta dokument med hjälp av flera varianter av hämtningsfrågan. Detta kan uppnås genom att antingen utföra enskilda sökningar för varje expanderad fråga eller genom att använda en sammanlänkning av alla expanderade sökfrågor i en enda hämtningsfråga.
Anteckning
Frågeexpansion måste göras tillsammans med ändringar i frågetolkningskomponenten (RAG-kedjan). De flera varianterna av en hämtningsfråga genereras vanligtvis i det här steget.
- Omrankning: När du har hämtat en första uppsättning segment tillämpar du ytterligare rangordningsvillkor (till exempel sortering efter tid) eller en rerankermodell för att ordna om resultaten. Omrankning kan hjälpa till att prioritera de mest relevanta segmenten med tanke på en specifik hämtningsfråga. Om du använder omrankning med cross-encoder-modeller som mxbai-rerank och ColBERTv2 kan det förbättra prestanda för hämtning.
- Metadatafiltrering: Använd metadatafilter som extraherats från frågetolkningssteget för att begränsa sökutrymmet baserat på specifika kriterier. Metadatafilter kan innehålla attribut som dokumenttyp, skapandedatum, författare eller domänspecifika taggar. Genom att kombinera metadatafilter med semantisk eller nyckelordsbaserad sökning kan du skapa mer riktad och effektiv hämtning.
Anteckning
Metadatafiltrering måste göras tillsammans med ändringar i komponenterna för frågetolkning (RAG-kedja) och metadataextrahering (datapipeline).
Promptförstärkning
Promptförstoring är det steg där användarfrågan kombineras med hämtad information och instruktioner i en promptmall för att vägleda språkmodellen mot att generera högkvalitativa svar. Iterering av den här mallen för att optimera uppmaningen som tillhandahålls till LLM (AKA prompt engineering) krävs för att säkerställa att modellen vägleds för att producera korrekta, jordade och sammanhängande svar.
Det finns hela guider för promptteknik, men här är några saker att tänka på när du itererar på promptmallen:
- Ange exempel
- Ta med exempel på välformade frågor och deras motsvarande ideala svar i själva promptmallen (few-shot learning). Detta hjälper modellen att förstå önskat format, format och innehåll i svaren.
- Ett användbart sätt att komma med bra exempel är att identifiera typer av frågor som din kedja kämpar med. Skapa gold-standard-svar för dessa frågor och inkludera dem som exempel i prompten.
- Se till att exemplen du anger är representativa för användarfrågor som du förväntar dig vid slutsatsdragningen. Sikta på att täcka en mängd olika förväntade frågor för att hjälpa modellen att generalisera bättre.
- Parametrisera din promptmall
- Utforma din promptmall så att den är flexibel genom att parametrisera den så att den innehåller ytterligare information utöver hämtade data och användarfrågor. Det kan vara variabler som aktuellt datum, användarkontext eller andra relevanta metadata.
- Om du matar in dessa variabler i prompten vid inferens kan du aktivera mer anpassade eller sammanhangsmedvetna svar.
- Överväg att använda en tankekedja som uppmaning
- För komplexa frågor där direkta svar inte är omedelbart uppenbara, överväg att använda Chain-of-Thought (CoT) prompting. Den här teknikstrategin delar upp komplicerade frågor i enklare, sekventiella steg som vägleder LLM genom en logisk resonemangsprocess.
- Genom att uppmana modellen att "tänka igenom problemet steg för steg" rekommenderar du att den tillhandahåller mer detaljerade och väl motiverade svar, vilket kan vara särskilt effektivt för hantering av frågor i flera steg eller öppna frågor.
- Uppmaningar kan inte överföras mellan modeller
- Identifiera att uppmaningar ofta inte överförs sömlöst mellan olika språkmodeller. Varje modell har sina egna unika egenskaper där en uppmaning som fungerar bra för en modell kanske inte är lika effektiv för en annan.
- Experimentera med olika promptformat och längder, se onlineguider (till exempel OpenAI Cookbook eller antropisk kokbok) och var beredd att anpassa och förfina dina frågor när du växlar mellan modeller.
LLM
Generationskomponenten i RAG-kedjan tar mallen för utökad prompt från föregående steg och skickar den till en LLM. När du väljer och optimerar en LLM för generationskomponenten i en RAG-kedja bör du tänka på följande faktorer, som är lika tillämpliga för andra steg som omfattar LLM-anrop:
- Experimentera med olika färdiga modeller.
- Varje modell har sina egna unika egenskaper, styrkor och svagheter. Vissa modeller kan ha en bättre förståelse för vissa domäner eller prestera bättre på specifika uppgifter.
- Som tidigare nämnts bör du tänka på att valet av modell också kan påverka processen för snabbteknik, eftersom olika modeller kan svara annorlunda på samma frågor.
- Om det finns flera steg i din kedja som kräver en LLM, till exempel anrop för frågetolkning utöver generationssteget, kan du överväga att använda olika modeller för olika steg. Dyrare modeller för generell användning kan vara överkvalificerade för uppgifter som att fastställa avsikten med en användarfråga.
- Starta litet och skala upp efter behov.
- Även om det kan vara frestande att omedelbart sträcka sig efter de mest kraftfulla och kompatibla modeller som finns tillgängliga (t.ex. GPT-4, Claude), är det ofta mer effektivt att börja med mindre, enklare modeller.
- I många fall kan mindre alternativ med öppen källkod som Llama 3 eller DBRX ge tillfredsställande resultat till en lägre kostnad och med snabbare slutsatsdragningstider. Dessa modeller kan vara särskilt effektiva för uppgifter som inte kräver mycket komplexa resonemang eller omfattande världskunskap.
- När du utvecklar och förfinar DIN RAG-kedja utvärderar du kontinuerligt prestanda och begränsningar för din valda modell. Om du upptäcker att modellen kämpar med vissa typer av frågor eller inte tillhandahåller tillräckligt detaljerade eller korrekta svar kan du överväga att skala upp till en mer kapabel modell.
- Övervaka effekten av att ändra modeller på viktiga mått, till exempel svarskvalitet, svarstid och kostnad för att säkerställa att du har rätt balans för kraven i ditt specifika användningsfall.
- Optimera modellparametrar
- Experimentera med olika parameterinställningar för att hitta den optimala balansen mellan svarskvalitet, mångfald och enhetlighet. Om du till exempel justerar temperaturen kan du styra slumpmässigheten i den genererade texten, medan max_tokens kan begränsa svarslängden.
- Tänk på att de optimala parameterinställningarna kan variera beroende på vilken uppgift, fråga och önskat utdataformat. Iterativt testa och förfina de här inställningarna baserat på utvärderingen av de genererade svaren.
- Uppgiftsspecifik finjustering
- När du förfinar prestanda bör du överväga att finjustera mindre modeller för specifika underaktiviteter i RAG-kedjan, till exempel frågetolkning.
- Genom att träna specialiserade modeller för enskilda uppgifter med RAG-kedjan kan du potentiellt förbättra den övergripande prestandan, minska svarstiden och sänka slutsatsdragningskostnaderna jämfört med att använda en enda stor modell för alla uppgifter.
- Fortsatt förträning
- Om ditt RAG-program hanterar en specialiserad domän eller kräver kunskap som inte är väl representerad i den förtränade LLM kan du överväga att utföra fortsatt förträning (CPT) på domänspecifika data.
- Fortsatt förträning kan förbättra en modells förståelse av specifik terminologi eller begrepp som är unika för din domän. Detta kan i sin tur minska behovet av omfattande snabbteknik eller få exempel.
Efterbearbetning och skyddsräcken
När LLM genererar ett svar är det ofta nödvändigt att tillämpa efterbearbetningstekniker eller skyddsräcken för att säkerställa att utdata uppfyller önskade format-, format- och innehållskrav. Det här sista steget (eller flera steg) i kedjan kan bidra till att upprätthålla konsekvens och kvalitet i de genererade svaren. Om du implementerar efterbearbetning och skyddsräcken bör du överväga några av följande:
- Framtvinga utdataformat
- Beroende på ditt användningsfall kan du kräva att de genererade svaren följer ett visst format, till exempel en strukturerad mall eller en viss filtyp (till exempel JSON, HTML, Markdown och så vidare).
- Om strukturerade utdata krävs ger bibliotek som Lärare eller Dispositioner bra utgångspunkter för att implementera den här typen av valideringssteg.
- När du utvecklar tar du dig tid att se till att efterbearbetningssteget är tillräckligt flexibelt för att hantera variationer i de genererade svaren samtidigt som det format som krävs bibehålls.
- Upprätthålla stilkonsekvens
- Om ditt RAG-program har specifika stilriktlinjer eller tonkrav (t.ex. formella eller tillfälliga, koncisa eller detaljerade) kan ett steg efter bearbetning både kontrollera och tillämpa dessa formatattribut mellan genererade svar.
- Innehållsfilter och skyddsräcken
- Beroende på typen av RAG-program och de potentiella riskerna med genererat innehåll kan det vara viktigt att implementera innehållsfilter eller skyddsräcken för att förhindra utdata från olämplig, stötande eller skadlig information.
- Överväg att använda modeller som Llama Guard eller API:er som är särskilt utformade för innehållsmoderering och säkerhet, till exempel OpenAI:s modererings-API, för att implementera skyddsåtgärder.
- Hantera hallucinationer
- Skydd mot hallucinationer kan också implementeras som ett steg efter bearbetning. Detta kan innebära att korsreferera de genererade utdata med hämtade dokument eller använda ytterligare LLM:er för att verifiera svarets faktiska noggrannhet.
- Utveckla reservmekanismer för att hantera fall där det genererade svaret inte uppfyller de faktiska noggrannhetskraven, till exempel att generera alternativa svar eller tillhandahålla ansvarsfriskrivningar till användaren.
- Felhantering
- Med eventuella efterbearbetningssteg implementerar du mekanismer för att på ett smidigt sätt hantera fall där steget stöter på ett problem eller inte genererar ett tillfredsställande svar. Detta kan innebära att generera ett standardsvar eller eskalera problemet till en mänsklig operatör för manuell granskning.