Tutorial: Descobrir relações em um modelo semântico usando o link semântico
Este tutorial ilustra como interagir com o Power BI por meio de um notebook do Jupyter e detectar relações entre as tabelas com a ajuda da biblioteca SemPy.
Neste tutorial, você aprenderá a:
- Descubra as relações em um modelo semântico (conjunto de dados do Power BI) usando a biblioteca do Python do Link Semântico (SemPy).
- Use os componentes da SemPy que dão suporte à integração ao Power BI e ajudam a automatizar a análise de qualidade de dados. Esses componentes incluem:
- FabricDataFrame - uma estrutura semelhante a pandas aprimorada com informações semânticas adicionais.
- Funções para extrair modelos semânticos de um workspace do Fabric para o seu notebook.
- Funções que automatizam a avaliação de hipóteses sobre as dependências funcionais e que identificam as violações de relações nos modelos semânticos.
Pré-requisitos
Obtenha uma assinatura do Microsoft Fabric. Ou, inscreva-se para uma avaliação gratuita do Microsoft Fabric.
Entre no Microsoft Fabric.
Use o alternador de experiência no lado esquerdo da sua página inicial para mudar para a experiência de Ciência de Dados Synapse.
Selecione Workspaces no painel de navegação esquerdo para localizar e selecionar seu workspace. Esse workspace se torna seu workspace atual.
Baixe os modelos semânticos Customer Profitability Sample.pbix e Customer Profitability Sample (auto).pbix no repositório GitHub fabric-samples e carregue-os no seu workspace.
Acompanhar no notebook
O notebook powerbi_relationships_tutorial.ipynb acompanha este tutorial.
Para abrir o notebook que acompanha este tutorial, siga as instruções em Preparar seu sistema para tutoriais de ciência de dados para importar os notebooks para seu workspace.
Se preferir copiar e colar o código a partir dessa página, você poderá criar um novo notebook.
Certifique-se de anexar um lakehouse ao notebook antes de começar a executar o código.
Configurar o notebook
Nesta seção, você configura um ambiente de notebook com os módulos e dados necessários.
Instale o
SemPypor meio do PyPI usando a funcionalidade de instalação em linha%pipno notebook:%pip install semantic-linkFaça as importações necessárias dos módulos da SemPy de que você precisará mais tarde:
import sempy.fabric as fabric from sempy.relationships import plot_relationship_metadata from sempy.relationships import find_relationships from sempy.fabric import list_relationship_violationsImporte o pandas para impor uma opção de configuração que ajuda na formatação de saída:
import pandas as pd pd.set_option('display.max_colwidth', None)
Explorar modelos semânticos
Este tutorial usa um modelo semântico de exemplo padrão Customer Profitability Sample.pbix. Para obter uma descrição do modelo semântico, confira o Exemplo de Rentabilidade do Cliente para o Power BI.
Use a função
list_datasetsda SemPy para explorar modelos semânticos no seu workspace atual:fabric.list_datasets()
Para o restante deste notebook, você usará duas versões do modelo semântico do Exemplo de Rentabilidade do Cliente:
- Exemplo de Rentabilidade do Cliente: o modelo semântico no estado que ele é fornecido das amostras do Power BI com relações de tabela predefinidas
- Customer Profitability Sample (auto): os mesmos dados, mas as relações são limitadas àquelas que o Power BI detectará automaticamente.
Extrair um modelo semântico de exemplo com o modelo semântico predefinido
Carregue as relações predefinidas e armazenadas no modelo semântico do Exemplo de Rentabilidade do Cliente usando a função
list_relationshipsda SemPy. Esta função lista o conteúdo do Modelo de Objeto de Tabela:dataset = "Customer Profitability Sample" relationships = fabric.list_relationships(dataset) relationshipsVisualize o DataFrame de
relationshipscomo um grafo usando a funçãoplot_relationship_metadatada SemPy:plot_relationship_metadata(relationships)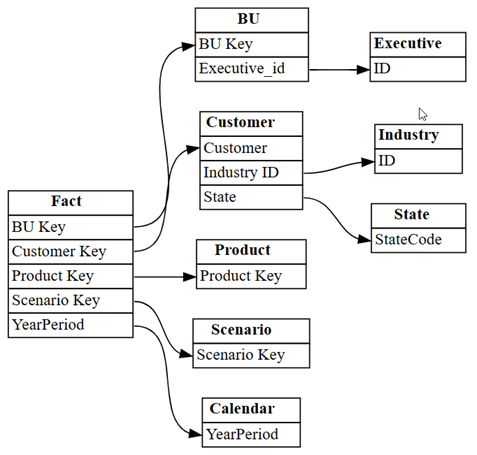

Este grafo mostra a “verdade básica” das relações entre as tabelas deste modelo semântico, pois reflete como elas foram definidas no Power BI por um especialista no assunto.
Complementar a descoberta de relações
Se você começou com as relações que o Power BI detectou automaticamente, você terá um conjunto menor.
Visualize as relações que o Power BI detectou automaticamente no modelo semântico:
dataset = "Customer Profitability Sample (auto)" autodetected = fabric.list_relationships(dataset) plot_relationship_metadata(autodetected)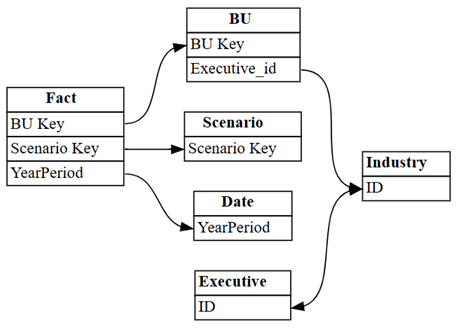
A detecção automática do Power BI perdeu muitas relações. Além disso, duas das relações detectadas automaticamente são semanticamente incorretas:
Executive[ID]->Industry[ID]BU[Executive_id]->Industry[ID]
Imprima as relações como uma tabela:
autodetectedAs relações incorretas com a tabela
Industryaparecem nas linhas com o índice 3 e 4. Use essas informações para remover essas linhas.Descarte as relações identificadas incorretamente.
autodetected.drop(index=[3,4], inplace=True) autodetectedAgora você tem relações corretas, mas incompletas.
Visualize essas relações incompletas usando
plot_relationship_metadata:plot_relationship_metadata(autodetected)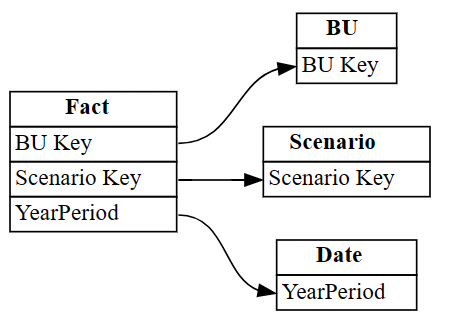
Carregue todas as tabelas do modelo semântico usando as funções
list_tableseread_tableda SemPy:tables = {table: fabric.read_table(dataset, table) for table in fabric.list_tables(dataset)['Name']} tables.keys()Encontre as relações entre as tabelas usando
find_relationshipse analise a saída do log para obter alguns insights sobre como essa função atua:suggested_relationships_all = find_relationships( tables, name_similarity_threshold=0.7, coverage_threshold=0.7, verbose=2 )Visualize as relações recém-descobertas:
plot_relationship_metadata(suggested_relationships_all)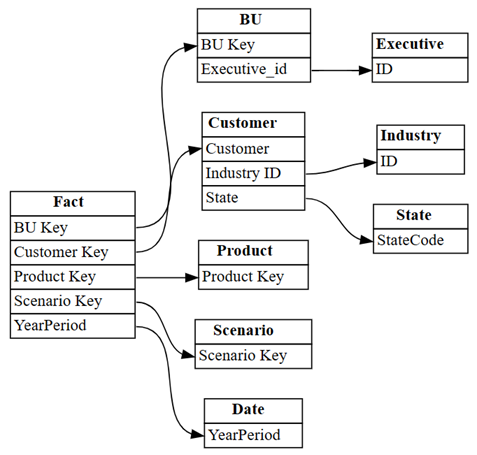
A SemPy conseguiu detectar todas as relações.
Use o parâmetro
excludepara limitar a pesquisa às relações adicionais que não foram identificadas anteriormente:additional_relationships = find_relationships( tables, exclude=autodetected, name_similarity_threshold=0.7, coverage_threshold=0.7 ) additional_relationships



Validar as relações
Primeiro, carregue os dados do modelo semântico do Exemplo de Rentabilidade do Cliente:
dataset = "Customer Profitability Sample" tables = {table: fabric.read_table(dataset, table) for table in fabric.list_tables(dataset)['Name']} tables.keys()Verifique se há sobreposição de valores de chave primária e estrangeira usando a função
list_relationship_violations. Forneça a saída da funçãolist_relationshipscomo entrada paralist_relationship_violations:list_relationship_violations(tables, fabric.list_relationships(dataset))As violações de relações fornecem alguns insights interessantes. Por exemplo, um em cada sete valores em
Fact[Product Key]não está presente emProduct[Product Key], e essa chave ausente é50.
A análise exploratória dos dados é um processo empolgante, assim como a limpeza de dados. Há sempre algo que os dados estão ocultando, dependendo de como você olha para ele, o que você quer perguntar e assim por diante. O link semântico fornece novas ferramentas que você pode utilizar para obter mais resultados com seus dados.
Conteúdo relacionado
Faça o check-out de outros tutoriais sobre link semântico / SemPy:
- Tutorial: Limpar dados com dependências funcionais
- Tutorial: Analisar dependências funcionais em um modelo semântico de exemplo
- Tutorial: Extrair e calcular medidas do Power BI por meio de um notebook do Jupyter
- Tutorial: Descobrir relacionamentos no conjunto de dados Synthea utilizando o link semântico
- Tutorial: validar dados usando SemPy e Great Expectations (GX) (versão prévia)