Tutorial: Limpar dados com dependências funcionais
Neste tutorial, você usará dependências funcionais para limpeza de dados. Existe uma dependência funcional quando uma coluna em um modelo semântico (um conjunto de dados do Power BI) é uma função de outra coluna. Por exemplo, uma coluna CEP pode determinar os valores em uma coluna cidade. Uma dependência funcional se manifesta como uma relação um-para-muitos entre os valores em duas ou mais colunas dentro de um DataFrame. Este tutorial usa o conjunto de dados Synthea para mostrar como as relações funcionais podem ajudar a detectar problemas de qualidade de dados.
Neste tutorial, você aprenderá a:
- Aplique conhecimento de domínio para formular hipóteses sobre dependências funcionais em um modelo semântico.
- Familiarize-se com componentes da biblioteca Python do Link Semântico (SemPy) que ajudam a automatizar a análise de qualidade de dados. Esses componentes incluem:
- FabricDataFrame - uma estrutura semelhante a pandas aprimorada com informações semânticas adicionais.
- Funções úteis que automatizam a avaliação de hipóteses sobre as dependências funcionais e que identificam as violações de relações nos modelos semânticos.
Pré-requisitos
Obtenha uma assinatura do Microsoft Fabric. Ou, inscreva-se para uma avaliação gratuita do Microsoft Fabric.
Entre no Microsoft Fabric.
Use o alternador de experiência no lado esquerdo da sua página inicial para mudar para a experiência de Ciência de Dados Synapse.
- Selecione Workspaces no painel de navegação esquerdo para localizar e selecionar seu workspace. Esse workspace se torna seu workspace atual.
Acompanhar no notebook
O notebook data_cleaning_functional_dependencies_tutorial.ipynb acompanha este tutorial.
Para abrir o notebook que acompanha este tutorial, siga as instruções em Preparar seu sistema para tutoriais de ciência de dados para importar os notebooks para seu workspace.
Se preferir copiar e colar o código a partir dessa página, você poderá criar um novo notebook.
Certifique-se de anexar um lakehouse ao notebook antes de começar a executar o código.
Configurar o notebook
Nesta seção, você configura um ambiente de notebook com os módulos e dados necessários.
- Para o Spark 3.4 e superior, o link semântico está disponível no runtime padrão ao usar o Fabric e não há necessidade de instalá-lo. Se você estiver usando o Spark 3.3 ou inferior, ou se quiser atualizar para a versão mais recente do link semântico, poderá executar o comando:
python %pip install -U semantic-link
Execute as importações necessárias de módulos que você precisará mais tarde:
import pandas as pd import sempy.fabric as fabric from sempy.fabric import FabricDataFrame from sempy.dependencies import plot_dependency_metadata from sempy.samples import download_syntheaExtraia os dados de exemplo. Para este tutorial, você usará o conjunto de dados Synthea de registros médicos sintéticos (versão pequena para simplificar):
download_synthea(which='small')
Explorar os dados
Inicialize um
FabricDataFramecom o conteúdo do arquivo providers.csv:providers = FabricDataFrame(pd.read_csv("synthea/csv/providers.csv")) providers.head()Verifique se há problemas de qualidade de dados com a função
find_dependenciesdo SemPy plotando um grafo de dependências funcionais detectadas automaticamente:deps = providers.find_dependencies() plot_dependency_metadata(deps)
O grafo de dependências funcionais mostra que
IddeterminaNAMEeORGANIZATION(indicado pelas setas sólidas), o que é esperado, já queIdé exclusivo:Confirme se
Idé exclusivo:providers.Id.is_uniqueO código retorna
Truepara confirmar queIdé exclusivo.

Analisar as dependências funcionais em profundidade
O grafo de dependências funcionais também mostra que ORGANIZATION determina ADDRESS e ZIP, conforme o esperado. No entanto, você pode esperar que ZIP também determine CITY, mas a seta tracejada indica que a dependência é apenas aproximada, apontando para um problema de qualidade de dados.
Há outras peculiaridades no grafo. Por exemplo, NAME não determina GENDER, Id, SPECIALITY ou ORGANIZATION. Cada uma dessas peculiaridades pode valer a pena investigar.
Examine mais detalhadamente a relação aproximada entre
ZIPeCITY, usando a funçãolist_dependency_violationsdo SemPy, para ver uma lista tabular de violações:providers.list_dependency_violations('ZIP', 'CITY')Desenhe um grafo com a função de visualização
plot_dependency_violationsdo SemPy. Esse grafo será útil se o número de violações for pequeno:providers.plot_dependency_violations('ZIP', 'CITY')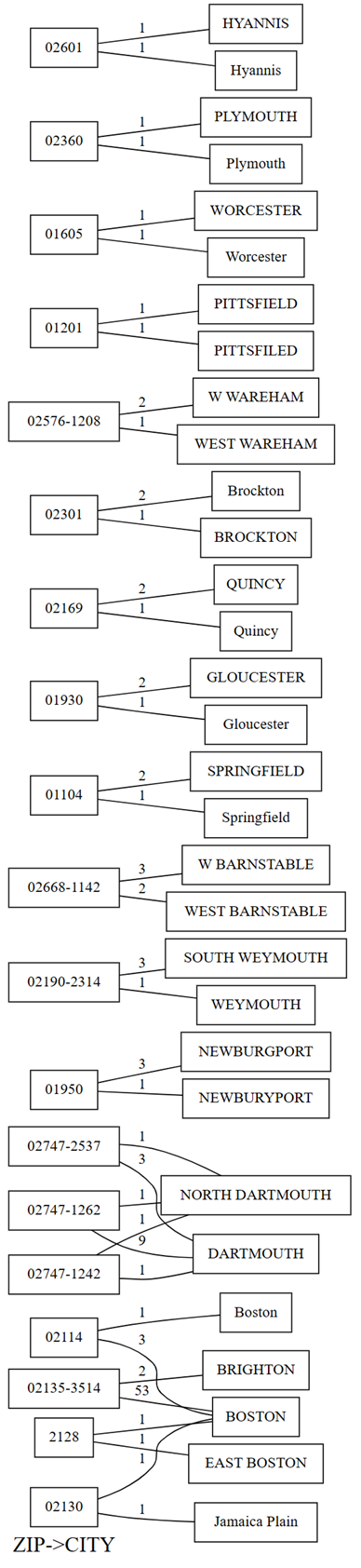
O gráfico de violações de dependência mostra valores para
ZIPno lado esquerdo e valores paraCITYno lado direito. Uma borda conecta um CEP no lado esquerdo do gráfico com uma cidade no lado direito se houver uma linha que contenha esses dois valores. As bordas são anotadas com a contagem dessas linhas. Por exemplo, há duas linhas com CEP 02747-1242, uma linha com a cidade "NORTH DARTHMOUTH" e a outra com a cidade "DARTHMOUTH", conforme mostrado no gráfico anterior e o seguinte código:Confirme as observações anteriores feitas com o gráfico de violações de dependência executando o seguinte código:
providers[providers.ZIP == '02747-1242'].CITY.value_counts()O gráfico também mostra que entre as linhas que têm
CITYcomo "DARTHMOUTH", nove linhas têm umZIPde 02747-1262; uma linha tem umZIPde 02747-1242; e uma linha tem umZIPde 02747-2537. Confirma estas observações com o seguinte código:providers[providers.CITY == 'DARTMOUTH'].ZIP.value_counts()Há outros CEPs associados a "DARTMOUTH", mas esses CEPs não são mostrados no grafo de violações de dependência, pois eles não sugerem problemas de qualidade de dados. Por exemplo, o CEP "02747-4302" é associado exclusivamente a "DARTMOUTH" e não aparece no grafo de violações de dependência. Confirme executando o seguinte código:
providers[providers.ZIP == '02747-4302'].CITY.value_counts()
Resumir problemas de qualidade de dados detectados com o SemPy
Voltando ao grafo de violações de dependência, você pode ver que há vários problemas interessantes de qualidade de dados presentes neste modelo semântico:
- Alguns nomes de cidade são todos maiúsculos. Esse problema é fácil de corrigir usando métodos de cadeia de caracteres.
- Alguns nomes de cidade têm qualificadores (ou prefixos), como "Norte" e "Leste". Por exemplo, o CEP "2128" mapeia para "EAST BOSTON" uma vez e para "BOSTON" uma vez. Um problema semelhante ocorre entre "NORTH DARTHMOUTH" e "DARTHMOUTH". Você pode tentar remover esses qualificadores ou mapear os CEPs para a cidade com a ocorrência mais comum.
- Há erros de digitação em algumas cidades, como "PITTSFIELD" vs. "PITTSFILED" e "NEWBURGPORT vs. "NEWBURYPORT". Para "NEWBURGPORT", esse erro de digitação pode ser corrigido usando a ocorrência mais comum. Para "PITTSFIELD", ter apenas uma ocorrência cada torna muito mais difícil para a desambiguação automática sem conhecimento externo ou o uso de um modelo de linguagem.
- Às vezes, prefixos como "West" são abreviados para uma única letra "W". Esse problema poderia ser corrigido com uma substituição simples, se todas as ocorrências de "W" representarem "West".
- O CEP "02130" mapeia para "BOSTON" uma vez e "Jamaica Plain" uma vez. Esse problema não é fácil de corrigir, mas se houver mais dados, o mapeamento para a ocorrência mais comum pode ser uma solução em potencial.
Limpar os dados
Corrija os problemas de capitalização alterando toda a capitalização para o caso do título:
providers['CITY'] = providers.CITY.str.title()Execute a detecção de violação novamente para ver que algumas das ambiguidades se foram (o número de violações é menor):
providers.list_dependency_violations('ZIP', 'CITY')Neste ponto, você pode refinar seus dados mais manualmente, mas uma tarefa potencial de limpeza de dados é remover linhas que violam restrições funcionais entre colunas nos dados usando a função
drop_dependency_violationsdo SemPy.Para cada valor da variável determinante,
drop_dependency_violationsfunciona escolhendo o valor mais comum da variável dependente e descartando todas as linhas com outros valores. Você deve aplicar essa operação somente se estiver confiante de que essa heurística estatística levaria aos resultados corretos para seus dados. Caso contrário, você deverá escrever seu próprio código para lidar com as violações detectadas conforme necessário.Execute a função
drop_dependency_violationsnas colunasZIPeCITY:providers_clean = providers.drop_dependency_violations('ZIP', 'CITY')Listar quaisquer violações de dependência entre
ZIPeCITY:providers_clean.list_dependency_violations('ZIP', 'CITY')O código retorna uma lista vazia para indicar que não há mais violações da restrição funcional CITY -> ZIP.
Conteúdo relacionado
Faça o check-out de outros tutoriais sobre link semântico / SemPy:
- Tutorial: Analisar dependências funcionais em um modelo semântico de exemplo
- Tutorial: Extrair e calcular medidas do Power BI por meio de um notebook do Jupyter
- Tutorial: Descobrir relações em um modelo semântico usando o link semântico
- Tutorial: Descobrir relacionamentos no conjunto de dados Synthea utilizando o link semântico
- Tutorial: Validar dados usando SemPy e Great Expectations (GX)