Indeksowanie danych z plików i skrótów usługi OneLake
W tym artykule dowiesz się, jak skonfigurować indeksator plików OneLake na potrzeby wyodrębniania danych z możliwością wyszukiwania i danych metadanych z usługi Lakehouse na podstawie usługi OneLake.
Aby skonfigurować i uruchomić indeksator, możesz użyć:
- 2024-05-01-preview INTERFEJS API REST lub nowszy interfejs API REST w wersji zapoznawczej.
- Pakiet beta zestawu Azure SDK, który udostępnia tę funkcję.
- Kreator importu danych w witrynie Azure Portal.
- Kreator importowania i wektoryzacji danych w witrynie Azure Portal.
W tym artykule użyto interfejsów API REST do zilustrowania poszczególnych kroków.
Wymagania wstępne
Obszar roboczy sieć szkieletowa. Wykonaj czynności opisane w tym samouczku, aby utworzyć obszar roboczy usługi Fabric.
Lakehouse w obszarze roboczym Sieć szkieletowa. Wykonaj czynności opisane w tym samouczku, aby utworzyć jezioro.
Dane tekstowe. Jeśli masz dane binarne, możesz użyć analizy obrazów wzbogacania sztucznej inteligencji, aby wyodrębnić tekst lub wygenerować opisy obrazów. Zawartość pliku nie może przekraczać limitów indeksatora dla warstwy usługi wyszukiwania.
Zawartość w lokalizacji Pliki w twoim lakehouse. Dane można dodawać, wykonując następujące czynności:
- Przekazywanie bezpośrednio do lakehouse
- Korzystanie z potoków danych z usługi Microsoft Fabric
- Dodaj skróty z zewnętrznych źródeł danych, takich jak Amazon S3 lub Google Cloud Storage.
Usługa wyszukiwania sztucznej inteligencji skonfigurowane dla tożsamości zarządzanej systemu lub przypisanej przez użytkownika tożsamości zarządzanej. Usługa wyszukiwania sztucznej inteligencji musi znajdować się w tej samej dzierżawie co obszar roboczy usługi Microsoft Fabric.
Przypisanie roli Współautor w obszarze roboczym usługi Microsoft Fabric, w którym znajduje się usługa Lakehouse. Kroki opisano w sekcji Udzielanie uprawnień w tym artykule.
Klient REST do formułowania wywołań REST podobnych do tych przedstawionych w tym artykule.
Obsługiwane zadania
Tego indeksatora można używać do wykonywania następujących zadań:
- Indeksowanie danych i indeksowanie przyrostowe: indeksator może indeksować pliki i skojarzone metadane ze ścieżek danych w usłudze Lakehouse. Wykrywa nowe i zaktualizowane pliki i metadane za pomocą wbudowanego wykrywania zmian. Odświeżanie danych można skonfigurować zgodnie z harmonogramem lub na żądanie.
- Wykrywanie usuwania: indeksator może wykrywać usunięcia za pośrednictwem niestandardowych metadanych dla większości plików i skrótów. Wymaga to dodania metadanych do plików w celu oznaczenia, że zostały one "usunięte nietrwale", co umożliwia usunięcie ich z indeksu wyszukiwania. Obecnie nie można wykryć usunięcia w usłudze Google Cloud Storage lub plikach skrótów Amazon S3, ponieważ niestandardowe metadane nie są obsługiwane dla tych źródeł danych.
- Zastosowana sztuczna inteligencja za pomocą zestawów umiejętności:zestawy umiejętności są w pełni obsługiwane przez indeksator plików OneLake. Obejmuje to kluczowe funkcje, takie jak wektoryzacja zintegrowana, które dodają kroki fragmentowania i osadzania danych.
- Tryby analizowania: indeksator obsługuje tryby analizowania JSON, jeśli chcesz przeanalizować tablice JSON lub wiersze do poszczególnych dokumentów wyszukiwania. Obsługuje również tryb analizowania języka Markdown.
- Zgodność z innymi funkcjami: indeksator OneLake został zaprojektowany tak, aby bezproblemowo współdziałał z innymi funkcjami indeksatora, takimi jak sesje debugowania, pamięć podręczna indeksatora na potrzeby wzbogacania przyrostowego i magazynu wiedzy.
Obsługiwane formaty dokumentów
Indeksator plików OneLake może wyodrębnić tekst z następujących formatów dokumentów:
- CSV (zobacz Indeksowanie obiektów blob CSV)
- EML
- EPUB
- GZ
- HTML
- JSON (zobacz Indeksowanie obiektów blob JSON)
- KML (XML dla reprezentacji geograficznych)
- Formaty pakietu Microsoft Office: DOCX/DOC/DOCM, XLSX/XLS/XLSM, PPTX/PPT/PPTM, MSG (wiadomości e-mail programu Outlook), XML (zarówno 2003, jak i 2006 WORD XML)
- Otwieranie formatów dokumentów: ODT, ODS, ODP
- Pliki zwykłego tekstu (zobacz też Indeksowanie zwykłego tekstu)
- RTF
- Plik XML
- ZIP
Obsługiwane skróty
Następujące skróty OneLake są obsługiwane przez indeksator plików OneLake:
Skrót OneLake (skrót do innego wystąpienia OneLake)
Ograniczenia w tej wersji zapoznawczej
Typy plików Parquet (w tym delta parquet) nie są obecnie obsługiwane.
Usuwanie plików nie jest obsługiwane w przypadku skrótów amazon S3 i Google Cloud Storage.
Ten indeksator nie obsługuje zawartości lokalizacji tabeli obszaru roboczego usługi OneLake.
Ten indeksator nie obsługuje zapytań SQL, ale zapytanie używane w konfiguracji źródła danych jest wyłącznie do dodawania folderu lub skrótu w celu uzyskania dostępu.
Nie ma obsługi pozyskiwania plików z obszaru roboczego Mój obszar roboczy w usłudze OneLake, ponieważ jest to repozytorium osobiste na użytkownika.
Przygotowywanie danych do indeksowania
Przed skonfigurowaniem indeksowania przejrzyj dane źródłowe, aby ustalić, czy jakiekolwiek zmiany powinny zostać wprowadzone z góry. Indeksator może indeksować zawartość z jednego kontenera jednocześnie. Domyślnie wszystkie pliki w kontenerze są przetwarzane. Istnieje kilka opcji bardziej selektywnego przetwarzania:
Umieść pliki w folderze wirtualnym. Definicja źródła danych indeksatora zawiera parametr "query", który może być podfolderem typu lakehouse lub skrótem. Jeśli ta wartość jest określona, indeksowane są tylko te pliki w podfolderze lub skrót w obiekcie lakehouse.
Dołączanie lub wykluczanie plików według typu pliku. Lista obsługiwanych formatów dokumentów może pomóc w ustaleniu, które pliki mają zostać wykluczone. Możesz na przykład wykluczyć pliki obrazów lub audio, które nie udostępniają tekstu z możliwością wyszukiwania. Ta funkcja jest kontrolowana za pomocą ustawień konfiguracji w indeksatorze.
Dołączanie lub wykluczanie dowolnych plików. Jeśli chcesz pominąć określony plik z jakiegokolwiek powodu, możesz dodać właściwości i wartości metadanych do plików w usłudze OneLake Lakehouse. Gdy indeksator napotka tę właściwość, pomija plik lub jego zawartość w przebiegu indeksowania.
Dołączanie i wykluczanie plików zostało omówione w kroku konfiguracji indeksatora. Jeśli nie ustawisz kryteriów, indeksator zgłasza niekwalifikowany plik jako błąd i przechodzi dalej. Jeśli wystąpi wystarczająca liczba błędów, przetwarzanie może zostać zatrzymane. Tolerancja błędów można określić w ustawieniach konfiguracji indeksatora.
Indeksator zazwyczaj tworzy jeden dokument wyszukiwania na plik, w którym zawartość tekstowa i metadane są przechwytywane jako pola z możliwością wyszukiwania w indeksie. Jeśli pliki są całymi plikami, możesz je potencjalnie przeanalizować w wielu dokumentach wyszukiwania. Można na przykład przeanalizować wiersze w pliku CSV, aby utworzyć jeden dokument wyszukiwania dla każdego wiersza. Jeśli musisz podzielić pojedynczy dokument na mniejsze fragmenty, aby wektoryzować dane, rozważ użycie wektoryzacji zintegrowanej.
Metadane pliku indeksowania
Metadane plików mogą być również indeksowane i jest to przydatne, jeśli uważasz, że dowolne ze standardowych lub niestandardowych właściwości metadanych jest przydatne w filtrach i zapytaniach.
Właściwości metadanych określonych przez użytkownika są wyodrębniane dosłownie. Aby otrzymywać wartości, należy zdefiniować pole w indeksie wyszukiwania typu Edm.String, o takiej samej nazwie jak klucz metadanych obiektu blob. Jeśli na przykład obiekt blob ma klucz metadanych o Priority wartości High, należy zdefiniować pole o nazwie Priority w indeksie wyszukiwania i zostanie wypełnione wartością High.
Standardowe właściwości metadanych pliku można wyodrębnić do pól o podobnych nazwach i wpisanych, jak pokazano poniżej. Indeksator plików OneLake automatycznie tworzy wewnętrzne mapowania pól dla tych właściwości metadanych, konwertując oryginalną nazwę łącznika ("metadata-storage-name") na podkreślony odpowiednik ("metadata_storage_name").
Nadal musisz dodać pola podkreślone do definicji indeksu, ale można pominąć mapowania pól indeksatora, ponieważ indeksator automatycznie tworzy skojarzenie.
metadata_storage_name (
Edm.String) — nazwa pliku. Jeśli na przykład masz plik /mydatalake/my-folder/podfolder/resume.pdf, wartość tego pola toresume.pdf.metadata_storage_path (
Edm.String) — pełny identyfikator URI obiektu blob, w tym konto magazynu. Na przykładhttps://myaccount.blob.core.windows.net/my-container/my-folder/subfolder/resume.pdfmetadata_storage_content_type (
Edm.String) — typ zawartości określony przez kod użyty do przekazania obiektu blob. Na przykładapplication/octet-stream.metadata_storage_last_modified (
Edm.DateTimeOffset) — znacznik czasu ostatniej modyfikacji obiektu blob. Usługa Azure AI Search używa tego znacznika czasu do identyfikowania zmienionych obiektów blob, aby uniknąć ponownego indeksowania wszystkiego po początkowym indeksowaniu.metadata_storage_size (
Edm.Int64) — rozmiar obiektu blob w bajtach.metadata_storage_content_md5 (
Edm.String) — skrót MD5 zawartości obiektu blob, jeśli jest dostępny.
Na koniec wszystkie właściwości metadanych specyficzne dla formatu dokumentu plików indeksowania mogą być również reprezentowane w schemacie indeksu. Aby uzyskać więcej informacji na temat metadanych specyficznych dla zawartości, zobacz Właściwości metadanych zawartości.
Ważne jest, aby podkreślić, że nie musisz definiować pól dla wszystkich powyższych właściwości w indeksie wyszukiwania — po prostu przechwyć właściwości potrzebne dla aplikacji.
Udzielenie uprawnień
Indeksator OneLake używa uwierzytelniania tokenu i dostępu opartego na rolach dla połączeń z usługą OneLake. Uprawnienia są przypisywane w usłudze OneLake. Nie ma żadnych wymagań dotyczących uprawnień w fizycznych magazynach danych, na których są tworzone skróty. Jeśli na przykład indeksujesz z platformy AWS, nie musisz udzielać uprawnień usługi wyszukiwania na platformie AWS.
Minimalne przypisanie roli dla tożsamości usługi wyszukiwania to Współautor.
Skonfiguruj tożsamość systemową lub zarządzaną przez użytkownika dla usługa wyszukiwania sztucznej inteligencji.
Poniższy zrzut ekranu przedstawia tożsamość zarządzaną systemu dla usługi wyszukiwania o nazwie "onelake-demo".
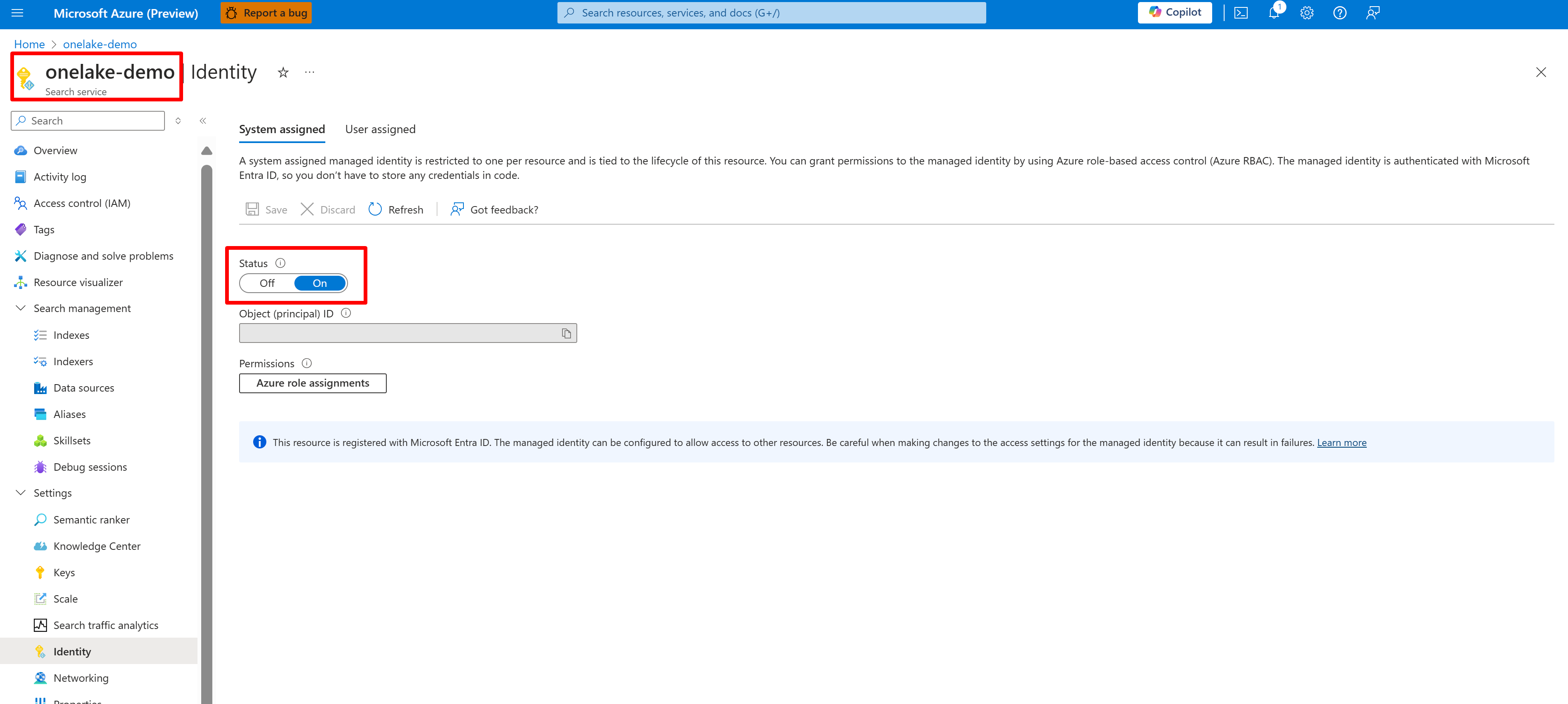
Ten zrzut ekranu przedstawia tożsamość zarządzaną przez użytkownika dla tej samej usługi wyszukiwania.
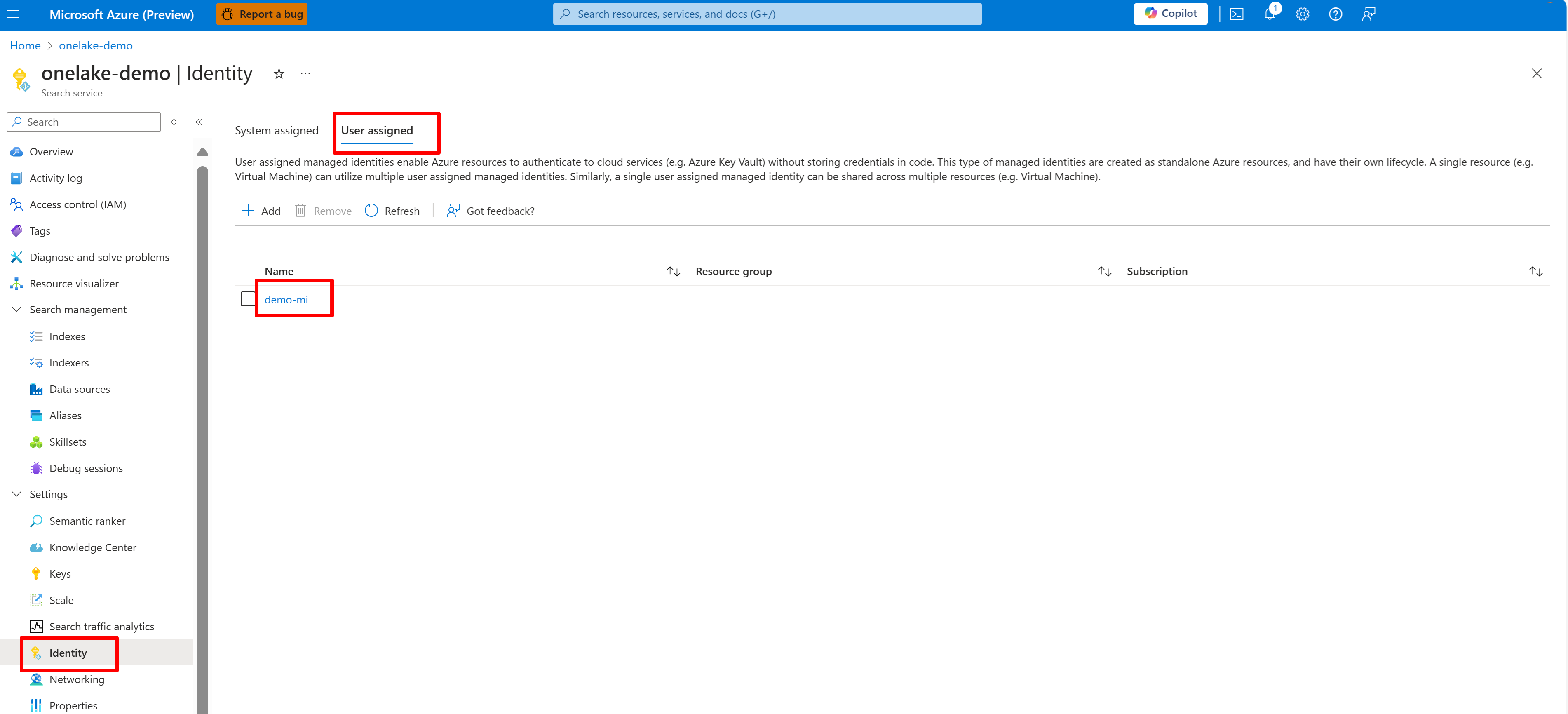
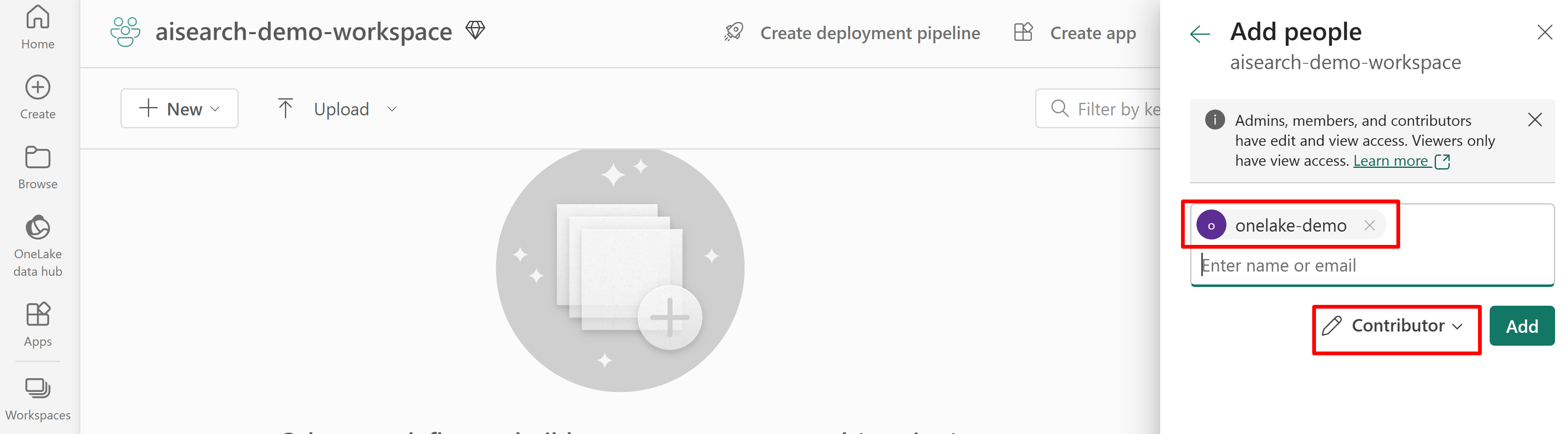
Udziel uprawnień dostępu usługi wyszukiwania do obszaru roboczego Sieć szkieletowa. Usługa wyszukiwania nawiązuje połączenie w imieniu indeksatora.
Jeśli używasz tożsamości zarządzanej przypisanej przez system, wyszukaj nazwę usługa wyszukiwania sztucznej inteligencji. W przypadku tożsamości zarządzanej przypisanej przez użytkownika wyszukaj nazwę zasobu tożsamości.
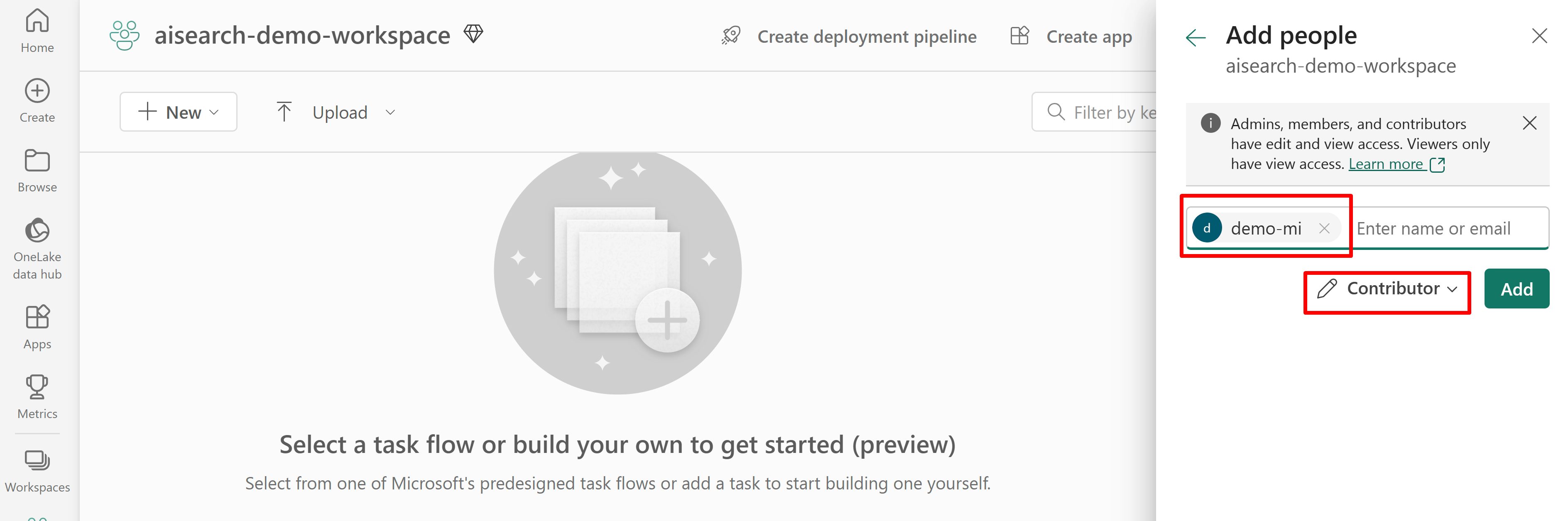
Poniższy zrzut ekranu przedstawia przypisanie roli Współautor przy użyciu tożsamości zarządzanej systemu.
Ten zrzut ekranu przedstawia przypisanie roli Współautor przy użyciu tożsamości zarządzanej przypisanej przez użytkownika:




Definiowanie źródła danych
Źródło danych jest definiowane jako niezależny zasób, dzięki czemu może być używane przez wiele indeksatorów. Aby utworzyć źródło danych, musisz użyć interfejsu API REST 2024-05-01-preview.
Użyj interfejsu API REST tworzenia lub aktualizowania źródła danych, aby ustawić jego definicję. Są to najważniejsze kroki definicji.
Ustaw
"type"wartość"onelake"(wymagane).Pobierz identyfikator GUID obszaru roboczego usługi Microsoft Fabric i identyfikator GUID usługi Lakehouse:
Przejdź do lakehouse, który chcesz zaimportować dane z jego adresu URL. Powinien wyglądać podobnie do tego przykładu: "https://msit.powerbi.com/groups/00000000-0000-0000-0000-000000000000/lakehouses/11111111-1111-1111-1111-111111111111?experience=power-bi". Skopiuj następujące wartości, które są używane w definicji źródła danych:
Skopiuj identyfikator GUID obszaru roboczego, który zostanie wyświetlony
{FabricWorkspaceGuid}bezpośrednio po "grupach" w adresie URL. W tym przykładzie będzie to 000000000-0000-0000-0000-000000000000000.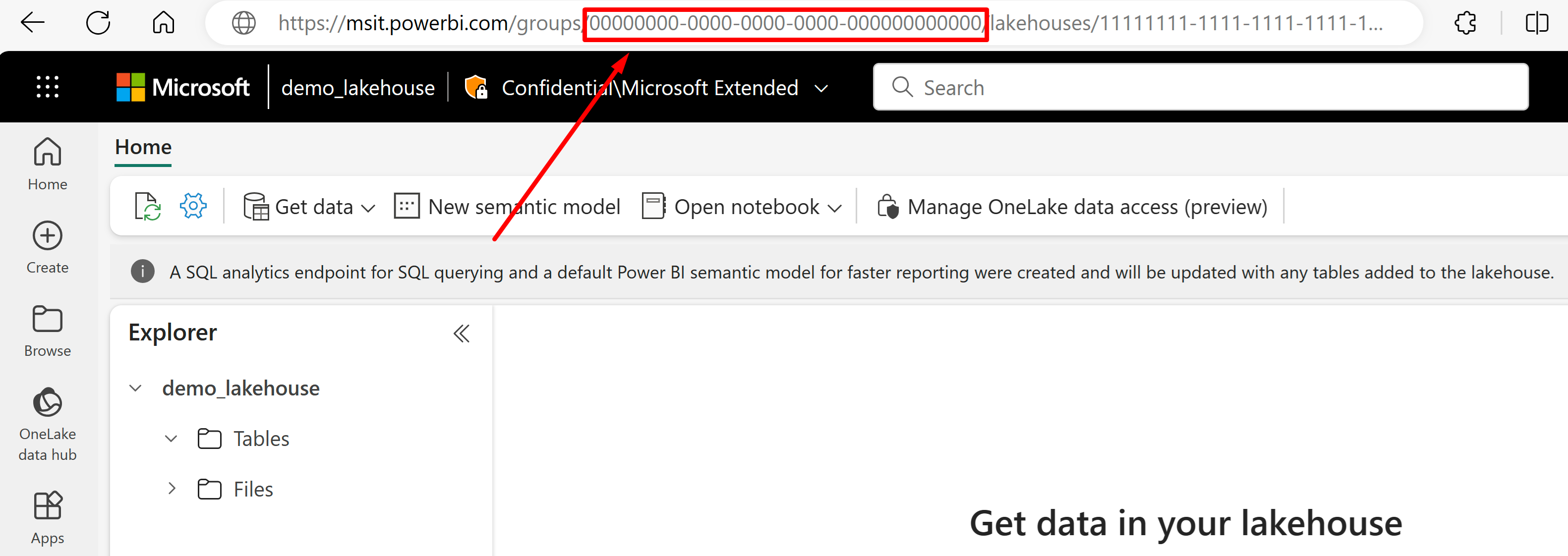
Skopiuj identyfikator GUID usługi Lakehouse, który zostanie wywołany
{lakehouseGuid}, który zostanie wyświetlony bezpośrednio po "lakehouses" w adresie URL. W tym przykładzie będzie to 1111111111-1111-1111-1111-1111111111111111111.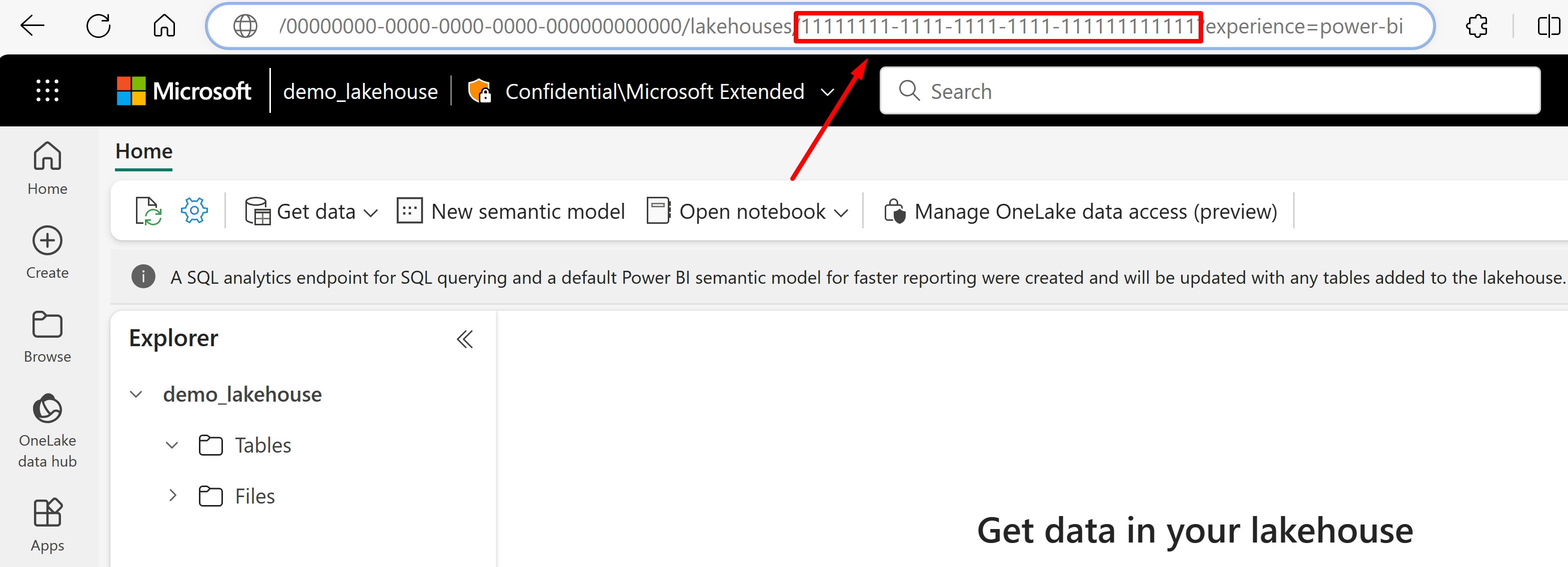
Ustaw
"credentials"identyfikator GUID obszaru roboczego usługi Microsoft Fabric, zastępując{FabricWorkspaceGuid}wartość skopiowaną w poprzednim kroku. Jest to usługa OneLake, do której można uzyskać dostęp przy użyciu tożsamości zarządzanej, którą skonfigurujesz w dalszej części tego przewodnika."credentials": { "connectionString": "ResourceId={FabricWorkspaceGuid}" }Ustaw
"container.name"wartość na identyfikator GUID usługi Lakehouse, zastępując wartość{lakehouseGuid}skopiowaną w poprzednim kroku. Użyj"query"polecenia , aby opcjonalnie określić podfolder lub skrót lakehouse."container": { "name": "{lakehouseGuid}", "query": "{optionalLakehouseFolderOrShortcut}" }Ustaw metodę uwierzytelniania przy użyciu tożsamości zarządzanej przypisanej przez użytkownika lub przejdź do następnego kroku tożsamości zarządzanej przez system.
{ "name": "{dataSourceName}", "description": "description", "type": "onelake", "credentials": { "connectionString": "ResourceId={FabricWorkspaceGuid}" }, "container": { "name": "{lakehouseGuid}", "query": "{optionalLakehouseFolderOrShortcut}" }, "identity": { "@odata.type": "Microsoft.Azure.Search.DataUserAssignedIdentity", "userAssignedIdentity": "{userAssignedManagedIdentity}" } }Wartość
userAssignedIdentitymożna znaleźć, przechodząc{userAssignedManagedIdentity}do zasobu w obszarze Właściwości i o nazwieId.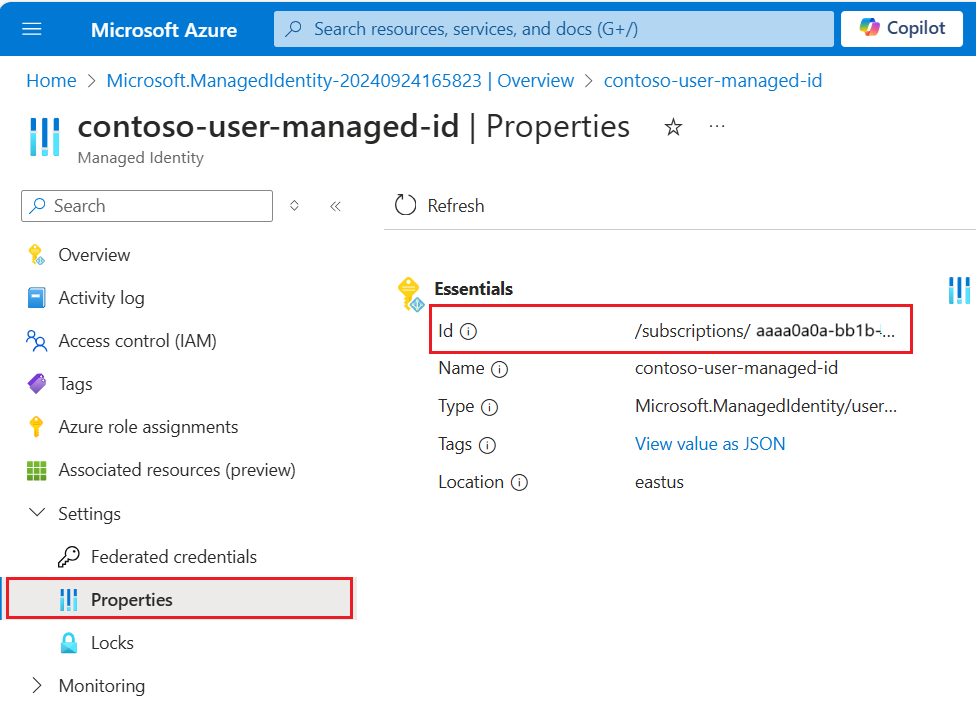
Przykład:
{ "name": "mydatasource", "description": "description", "type": "onelake", "credentials": { "connectionString": "ResourceId=a0a0a0a0-bbbb-cccc-dddd-e1e1e1e1e1e1" }, "container": { "name": "11111111-1111-1111-1111-111111111111", "query": "folder_name" }, "identity": { "@odata.type": "Microsoft.Azure.Search.DataUserAssignedIdentity", "userAssignedIdentity": "/subscriptions/333333-3333-3333-3333-33333333/resourcegroups/myresourcegroup/providers/Microsoft.ManagedIdentity/userAssignedIdentities/demo-mi" } }Opcjonalnie należy zamiast tego użyć tożsamości zarządzanej przypisanej przez system. Wartość "tożsamość" zostanie usunięta z definicji, jeśli jest używana tożsamość zarządzana przypisana przez system.
{ "name": "{dataSourceName}", "description": "description", "type": "onelake", "credentials": { "connectionString": "ResourceId={FabricWorkspaceGuid}" }, "container": { "name": "{lakehouseGuid}", "query": "{optionalLakehouseFolderOrShortcut}" } }Przykład:
{ "name": "mydatasource", "description": "description", "type": "onelake", "credentials": { "connectionString": "ResourceId=a0a0a0a0-bbbb-cccc-dddd-e1e1e1e1e1e1" }, "container": { "name": "11111111-1111-1111-1111-111111111111", "query": "folder_name" } }



Wykrywanie usuwania za pośrednictwem metadanych niestandardowych
Definicja źródła danych indeksatora plików OneLake może zawierać zasady usuwania nietrwałego, jeśli indeksator ma usunąć dokument wyszukiwania, gdy dokument źródłowy jest oflagowany do usunięcia.
Aby włączyć automatyczne usuwanie plików, użyj niestandardowych metadanych, aby wskazać, czy dokument wyszukiwania powinien zostać usunięty z indeksu.
Przepływ pracy wymaga trzech oddzielnych akcji:
- "Usuwanie nietrwałe" pliku w usłudze OneLake
- Indeksator usuwa dokument wyszukiwania w indeksie
- "Usuwanie twarde" pliku w usłudze OneLake
Polecenie "Usuwanie nietrwałe" informuje indeksatora, co należy zrobić (usunąć dokument wyszukiwania). Jeśli najpierw usuniesz plik fizyczny w usłudze OneLake, nie ma nic do odczytania przez indeksator, a odpowiedni dokument wyszukiwania w indeksie jest oddzielony.
Istnieją kroki, które należy wykonać zarówno w usłudze OneLake, jak i w usłudze Azure AI Search, ale nie ma żadnych innych zależności funkcji.
W pliku lakehouse dodaj do pliku niestandardową parę klucz-wartość metadanych, aby wskazać, że plik jest oflagowany do usunięcia. Można na przykład nazwać właściwość "IsDeleted", ustawioną na false. Jeśli chcesz usunąć plik, zmień go na true.
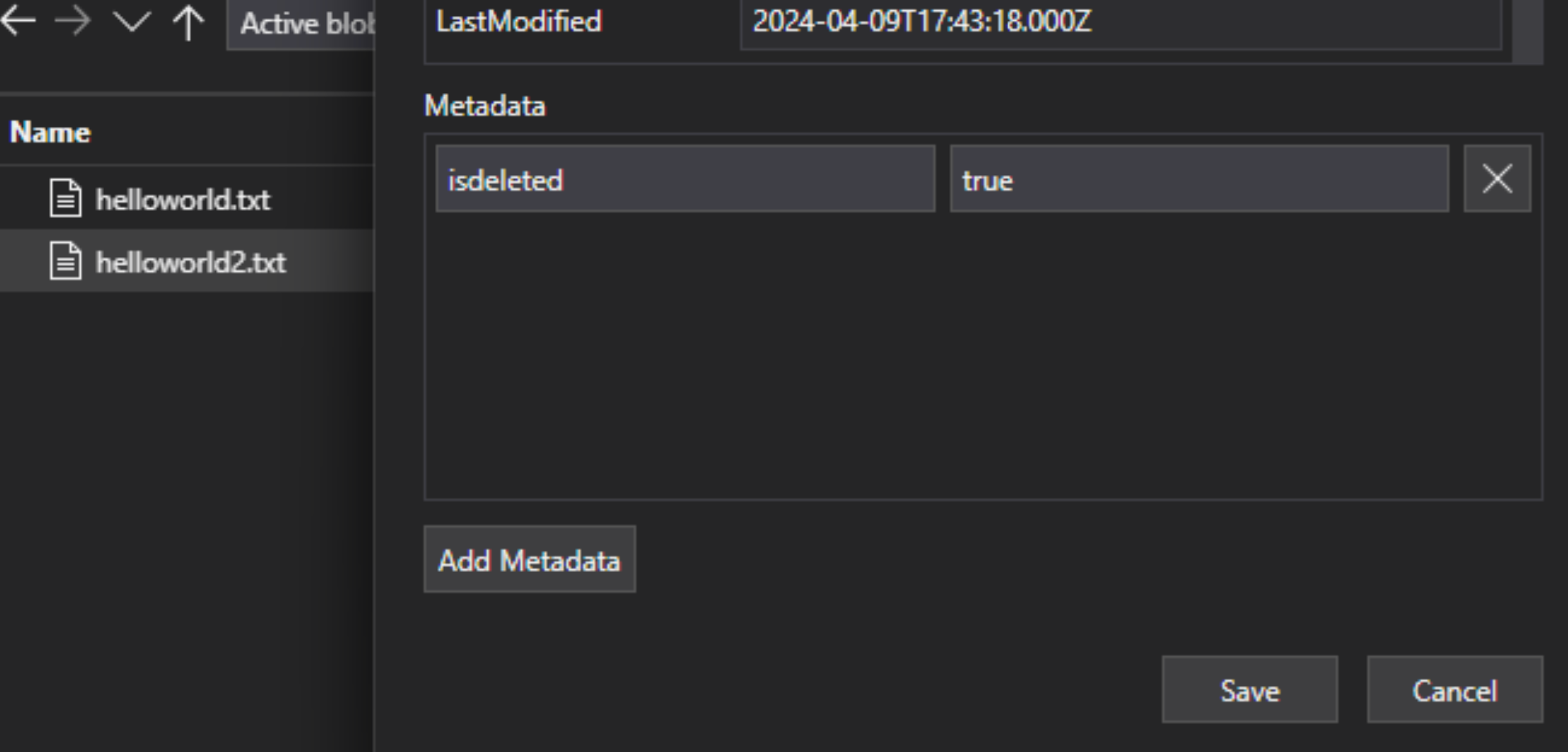
W usłudze Azure AI Search edytuj definicję źródła danych, aby uwzględnić właściwość "dataDeletionDetectionPolicy". Na przykład następujące zasady uznają plik za usunięty, jeśli ma właściwość metadanych "IsDeleted" o wartości true:
PUT https://[service name].search.windows.net/datasources/file-datasource?api-version=2024-05-01-preview { "name" : "onelake-datasource", "type" : "onelake", "credentials": { "connectionString": "ResourceId={FabricWorkspaceGuid}" }, "container": { "name": "{lakehouseGuid}", "query": "{optionalLakehouseFolderOrShortcut}" }, "dataDeletionDetectionPolicy" : { "@odata.type" :"#Microsoft.Azure.Search.SoftDeleteColumnDeletionDetectionPolicy", "softDeleteColumnName" : "IsDeleted", "softDeleteMarkerValue" : "true" } }

Po uruchomieniu indeksatora i usunięciu dokumentu z indeksu wyszukiwania można usunąć plik fizyczny w usłudze Data Lake.
Oto niektóre kluczowe kwestie:
Planowanie przebiegu indeksatora pomaga zautomatyzować ten proces. Zalecamy harmonogramy dla wszystkich scenariuszy indeksowania przyrostowego.
Jeśli zasady wykrywania usuwania nie zostały ustawione na pierwszym uruchomieniu indeksatora, należy zresetować indeksator , aby odczytał zaktualizowaną konfigurację.
Pamiętaj, że wykrywanie usuwania nie jest obsługiwane w przypadku skrótów amazon S3 i Google Cloud Storage ze względu na zależność od metadanych niestandardowych.
Dodawanie pól wyszukiwania do indeksu
W indeksie wyszukiwania dodaj pola, aby zaakceptować zawartość i metadane plików usługi OneLake data lake.
Utwórz lub zaktualizuj indeks , aby zdefiniować pola wyszukiwania, które przechowują zawartość pliku i metadane:
{ "name" : "my-search-index", "fields": [ { "name": "ID", "type": "Edm.String", "key": true, "searchable": false }, { "name": "content", "type": "Edm.String", "searchable": true, "filterable": false }, { "name": "metadata_storage_name", "type": "Edm.String", "searchable": false, "filterable": true, "sortable": true }, { "name": "metadata_storage_size", "type": "Edm.Int64", "searchable": false, "filterable": true, "sortable": true }, { "name": "metadata_storage_content_type", "type": "Edm.String", "searchable": false, "filterable": true, "sortable": true } ] }Utwórz pole klucza dokumentu ("key": true). W przypadku zawartości pliku najlepszymi kandydatami są właściwości metadanych.
metadata_storage_path(ustawienie domyślne) pełna ścieżka do obiektu lub pliku. Pole klucza ("ID" w tym przykładzie) jest wypełniane wartościami z metadata_storage_path, ponieważ jest to ustawienie domyślne.metadata_storage_name, można używać tylko wtedy, gdy nazwy są unikatowe. Jeśli chcesz, aby to pole było kluczem, przejdź"key": truedo tej definicji pola.Niestandardowa właściwość metadanych dodana do plików. Ta opcja wymaga, aby proces przekazywania pliku dodaje tę właściwość metadanych do wszystkich obiektów blob. Ponieważ klucz jest wymaganą właściwością, wszystkie pliki, których brakuje wartości, nie mogą być indeksowane. Jeśli używasz niestandardowej właściwości metadanych jako klucza, unikaj wprowadzania zmian w tej właściwości. Indeksatory dodają zduplikowane dokumenty dla tego samego pliku, jeśli właściwość klucza ulegnie zmianie.
Właściwości metadanych często zawierają znaki, takie jak
/i-, które są nieprawidłowe dla kluczy dokumentów. Ponieważ indeksator ma właściwość "base64EncodeKeys" (prawda domyślnie), automatycznie koduje właściwość metadanych bez wymaganej konfiguracji ani mapowania pól.Dodaj pole "content", aby przechowywać wyodrębniony tekst z każdego pliku za pomocą właściwości "content" pliku. Nie musisz używać tej nazwy, ale umożliwia to korzystanie z niejawnych mapowań pól.
Dodaj pola dla standardowych właściwości metadanych. Indeksator może odczytywać właściwości metadanych niestandardowych, właściwości standardowych metadanych i właściwości metadanych specyficznych dla zawartości.
Konfigurowanie i uruchamianie indeksatora plików OneLake
Po utworzeniu indeksu i źródła danych możesz utworzyć indeksator. Konfiguracja indeksatora określa dane wejściowe, parametry i właściwości kontrolujące zachowania czasu wykonywania. Można również określić, które części obiektu blob mają być indeksować.
Utwórz lub zaktualizuj indeksator , podając mu nazwę i odwołując się do źródła danych i indeksu docelowego:
{ "name" : "my-onelake-indexer", "dataSourceName" : "my-onelake-datasource", "targetIndexName" : "my-search-index", "parameters": { "batchSize": null, "maxFailedItems": null, "maxFailedItemsPerBatch": null, "base64EncodeKeys": null, "configuration": { "indexedFileNameExtensions" : ".pdf,.docx", "excludedFileNameExtensions" : ".png,.jpeg", "dataToExtract": "contentAndMetadata", "parsingMode": "default" } }, "schedule" : { }, "fieldMappings" : [ ] }Ustaw wartość "batchSize", jeśli wartość domyślna (10 dokumentów) jest w obszarze wykorzystania lub przeciążenia dostępnych zasobów. Domyślne rozmiary partii są specyficzne dla źródła danych. Indeksowanie plików ustawia rozmiar partii na 10 dokumentów w rozpoznawaniu większego średniego rozmiaru dokumentu.
W obszarze "konfiguracja" steruj plikami, które są indeksowane na podstawie typu pliku, lub pozostaw nieokreślone, aby pobrać wszystkie pliki.
W przypadku
"indexedFileNameExtensions"programu podaj rozdzielaną przecinkami listę rozszerzeń plików (z kropką wiodącą). Wykonaj to samo dla"excludedFileNameExtensions"polecenia , aby wskazać, które rozszerzenia powinny zostać pominięte. Jeśli to samo rozszerzenie znajduje się na obu listach, jest wykluczone z indeksowania.W obszarze "configuration" ustaw wartość "dataToExtract", aby kontrolować, które części plików są indeksowane:
Wartość domyślna to "contentAndMetadata". Określa, że wszystkie metadane i zawartość tekstowa wyodrębniona z pliku są indeksowane.
"storageMetadata" określa, że indeksowane są tylko standardowe właściwości pliku i metadane określone przez użytkownika. Chociaż właściwości są udokumentowane dla obiektów blob platformy Azure, właściwości pliku są takie same dla usługi OneLkae, z wyjątkiem metadanych powiązanych z sygnaturą dostępu współdzielonego.
"allMetadata" określa, że standardowe właściwości pliku i wszelkie metadane dla znalezionych typów zawartości są wyodrębniane z zawartości pliku i indeksowane.
W obszarze "konfiguracja" ustaw wartość "parsingMode", jeśli pliki powinny być mapowane na wiele dokumentów wyszukiwania lub jeśli składają się z zwykłego tekstu, dokumentów JSON lub plików CSV.
Określ mapowania pól, jeśli istnieją różnice w nazwie lub typie pola lub jeśli potrzebujesz wielu wersji pola źródłowego w indeksie wyszukiwania.
W indeksowaniu plików często można pominąć mapowania pól, ponieważ indeksator ma wbudowaną obsługę mapowania właściwości "zawartości" i metadanych na podobnie nazwane i wpisane pola w indeksie. W przypadku właściwości metadanych indeksator automatycznie zastępuje łączniki
-podkreśleniami w indeksie wyszukiwania.
Aby uzyskać więcej informacji na temat innych właściwości, utwórz indeksator. Aby uzyskać pełną listę opisów parametrów, zobacz Tworzenie indeksatora (REST) w interfejsie API REST. Parametry są takie same dla usługi OneLake.
Domyślnie indeksator jest uruchamiany automatycznie podczas jego tworzenia. To zachowanie można zmienić, ustawiając wartość "disabled" na true. Aby kontrolować wykonywanie indeksatora, uruchom indeksator na żądanie lub umieść go zgodnie z harmonogramem.
Sprawdzanie stanu indeksatora
Zapoznaj się z wieloma podejściami do monitorowania stanu indeksatora i historii wykonywania tutaj.
Obsługa błędów
Błędy, które często występują podczas indeksowania, obejmują nieobsługiwane typy zawartości, brak zawartości lub nadmiernie zdużone pliki. Domyślnie indeksator plików OneLake zatrzymuje się zaraz po napotkaniu pliku z nieobsługiwanym typem zawartości. Jednak indeksowanie może być kontynuowane nawet w przypadku wystąpienia błędów, a następnie debugowanie poszczególnych dokumentów później.
Błędy przejściowe są typowe dla rozwiązań obejmujących wiele platform i produktów. Jeśli jednak indeksator zostanie zachowany zgodnie z harmonogramem (na przykład co 5 minut), indeksator powinien mieć możliwość odzyskania sprawności po tych błędach w następującym przebiegu.
Istnieje pięć właściwości indeksatora, które kontrolują odpowiedź indeksatora w przypadku wystąpienia błędów.
{
"parameters" : {
"maxFailedItems" : 10,
"maxFailedItemsPerBatch" : 10,
"configuration" : {
"failOnUnsupportedContentType" : false,
"failOnUnprocessableDocument" : false,
"indexStorageMetadataOnlyForOversizedDocuments": false
}
}
}
| Parametr | Prawidłowe wartości | opis |
|---|---|---|
| "maxFailedItems" | -1, null lub 0, dodatnia liczba całkowita | Kontynuuj indeksowanie, jeśli błędy występują w dowolnym momencie przetwarzania, podczas analizowania obiektów blob lub podczas dodawania dokumentów do indeksu. Ustaw te właściwości na liczbę dopuszczalnych niepowodzeń. Wartość -1 umożliwia przetwarzanie bez względu na liczbę błędów. W przeciwnym razie wartość jest dodatnią liczbą całkowitą. |
| "maxFailedItemsPerBatch" | -1, null lub 0, dodatnia liczba całkowita | Tak samo jak powyżej, ale używany do indeksowania wsadowego. |
| "failOnUnsupportedContentType" | prawda lub fałsz | Jeśli indeksator nie może określić typu zawartości, określ, czy kontynuować, czy nie wykonać zadania. |
| "failOnUnprocessableDocument" | prawda lub fałsz | Jeśli indeksator nie może przetworzyć dokumentu innego obsługiwanego typu zawartości, określ, czy kontynuować, czy nie wykonać zadania. |
| "indexStorageMetadataOnlyForOversizedDocuments" | prawda lub fałsz | Oversized blobs są domyślnie traktowane jako błędy. Jeśli ustawisz ten parametr na wartość true, indeksator spróbuje zaindeksować jego metadane, nawet jeśli nie można indeksować zawartości. Aby uzyskać informacje o limitach dotyczących rozmiaru obiektu blob, zobacz Limity usługi. |
Następne kroki
Sprawdź, jak działa kreator importowania i wektoryzacji danych i wypróbuj go dla tego indeksatora. Za pomocą zintegrowanej wektoryzacji można fragmentować i tworzyć osadzanie dla wektorów lub wyszukiwania hybrydowego przy użyciu schematu domyślnego.