Szybki start: wektoryzacja tekstu i obrazów przy użyciu witryny Azure Portal
Ten przewodnik Szybki start ułatwia rozpoczęcie zintegrowanej wektoryzacji przy użyciu kreatora Importowanie i wektoryzowanie danych w witrynie Azure Portal. Kreator fragmentuje zawartość i wywołuje model osadzania w celu wektoryzacji zawartości podczas indeksowania i zapytań.
Wymagania wstępne
Subskrypcja platformy Azure. Utwórz je bezpłatnie.
Usługa Azure AI usługa wyszukiwania w tym samym regionie co usługa Azure AI. Zalecamy warstwę Podstawowa lub nowszą.
Obsługiwane źródło danych z przykładowymi dokumentami PDF planu kondycji.
Obsługiwany model osadzania.
Znajomość kreatora. Aby uzyskać szczegółowe informacje, zobacz Importowanie kreatorów danych w witrynie Azure Portal .
Obsługiwane źródła danych
Kreator importowania i wektoryzacji danych obsługuje szeroką gamę źródeł danych platformy Azure, ale ten przewodnik Szybki start zawiera instrukcje dotyczące tylko tych źródeł danych, które współpracują z całymi plikami:
Usługa Azure Blob Storage dla obiektów blob i tabel. Usługa Azure Storage musi być standardowym kontem wydajności (ogólnego przeznaczenia w wersji 2). Warstwy dostępu mogą być gorące, chłodne i zimne.
Azure Data Lake Storage (ADLS) Gen2 (konto usługi Azure Storage z włączoną hierarchiczną przestrzenią nazw). Możesz potwierdzić, że masz usługę Data Lake Storage, sprawdzając kartę Właściwości na stronie Przegląd .
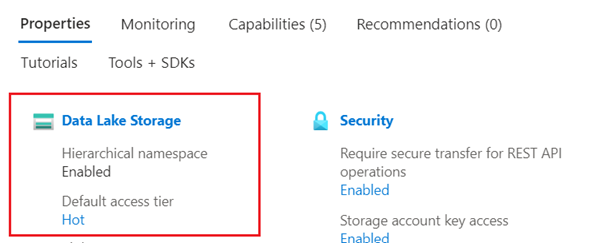
Obsługiwane modele osadzania
Użyj modelu osadzania na platformie Azure AI w tym samym regionie co usługa Azure AI Search. Instrukcje dotyczące wdrażania znajdują się w tym artykule.
| Dostawca | Obsługiwane modele |
|---|---|
| Azure OpenAI Service | text-embedding-ada-002 osadzanie tekstu —3 — duże osadzanie tekstu — 3 małe |
| Katalog modeli usługi Azure AI Foundry | Tekst: Cohere-embed-v3-english Cohere-embed-v3-wielojęzyczny W przypadku obrazów: Facebook-DinoV2-Image-Embeddings-ViT-Base Facebook-DinoV2-Image-Embeddings-ViT-Giant |
| Konto wieloasługowe usług azure AI | Multimodalne przetwarzanie obrazów i tekstu w usłudze Azure AI Vision dostępne w wybranych regionach. W zależności od sposobu dołączania zasobu z wieloma usługami konto wielosłużowe może być konieczne w tym samym regionie co usługa Azure AI Search. |
Jeśli używasz usługi Azure OpenAI Service, punkt końcowy musi mieć skojarzona niestandardowa poddomena. Niestandardowa poddomena to punkt końcowy, który zawiera unikatową nazwę (na przykład https://hereismyuniquename.cognitiveservices.azure.com). Jeśli usługa została utworzona za pośrednictwem witryny Azure Portal, ta poddomena zostanie automatycznie wygenerowana w ramach konfiguracji usługi. Przed rozpoczęciem korzystania z integracji usługi Azure AI Search upewnij się, że usługa zawiera niestandardową poddomenę podrzędną.
Zasoby usługi Azure OpenAI Service (z dostępem do modeli osadzania), które zostały utworzone w portalu usługi Azure AI Foundry, nie są obsługiwane. Tylko zasoby usługi Azure OpenAI utworzone w witrynie Azure Portal są zgodne z integracją umiejętności osadzania usługi Azure OpenAI.
Wymagania dotyczące publicznego punktu końcowego
Na potrzeby tego przewodnika Szybki start wszystkie poprzednie zasoby muszą mieć włączony dostęp publiczny, aby węzły witryny Azure Portal mogły uzyskiwać do nich dostęp. W przeciwnym razie kreator zakończy się niepowodzeniem. Po uruchomieniu kreatora można włączyć zapory i prywatne punkty końcowe w składnikach integracji na potrzeby zabezpieczeń. Aby uzyskać więcej informacji, zobacz Bezpieczne połączenia w kreatorach importu.
Jeśli prywatne punkty końcowe są już obecne i nie można ich wyłączyć, alternatywną opcją jest uruchomienie odpowiedniego kompleksowego przepływu ze skryptu lub programu na maszynie wirtualnej. Maszyna wirtualna musi znajdować się w tej samej sieci wirtualnej co prywatny punkt końcowy. Oto przykładowy kod w języku Python na potrzeby zintegrowanej wektoryzacji. To samo repozytorium GitHub zawiera przykłady w innych językach programowania.
Uprawnienia
Możesz użyć uwierzytelniania klucza i pełnego dostępu parametry połączenia lub identyfikatora Entra firmy Microsoft z przypisaniami ról. Zalecamy przypisania ról dla połączeń usługi wyszukiwania z innymi zasobami.
W usłudze Azure AI Search włącz role.
Skonfiguruj usługę wyszukiwania tak, aby korzystała z tożsamości zarządzanej.
Na platformie źródła danych i dostawcy modelu osadzania utwórz przypisania ról, które umożliwiają usłudze wyszukiwania dostęp do danych i modeli. Przygotowanie przykładowych danych zawiera instrukcje dotyczące konfigurowania ról dla każdego obsługiwanego źródła danych.
Bezpłatna usługa wyszukiwania obsługuje połączenia oparte na rolach z usługą Azure AI Search, ale nie obsługuje tożsamości zarządzanych w przypadku połączeń wychodzących z usługą Azure Storage lub Azure AI Vision. Ten poziom obsługi oznacza, że musisz używać uwierzytelniania opartego na kluczach na połączeniach między bezpłatną usługą wyszukiwania i innymi usługami platformy Azure.
W przypadku bezpieczniejszych połączeń:
- Użyj warstwy Podstawowa lub nowszej.
- Skonfiguruj tożsamość zarządzaną i użyj ról na potrzeby autoryzowanego dostępu.
Uwaga
Jeśli nie możesz przejść przez kreatora, ponieważ opcje nie są dostępne (na przykład nie można wybrać źródła danych lub modelu osadzania), przejdź ponownie do przypisań ról. Komunikaty o błędach wskazują, że modele lub wdrożenia nie istnieją, gdy w rzeczywistości prawdziwą przyczyną jest to, że usługa wyszukiwania nie ma uprawnień dostępu do nich.
Sprawdzanie ilości wolnego miejsca
Jeśli zaczynasz od bezpłatnej usługi, masz ograniczenie do trzech indeksów, źródeł danych, zestawów umiejętności i indeksatorów. Podstawowe ograniczenia do 15. Przed rozpoczęciem upewnij się, że dysponujesz miejscem na dodatkowe elementy. Ten przewodnik Szybki start tworzy jeden z każdego obiektu.
Przygotowywanie przykładowych danych
Ta sekcja wskazuje zawartość, która działa na potrzeby tego przewodnika Szybki start.
Zaloguj się do witryny Azure Portal przy użyciu konta platformy Azure i przejdź do konta usługi Azure Storage.
W okienku po lewej stronie w obszarze Magazyn danych wybierz pozycję Kontenery.
Utwórz nowy kontener, a następnie przekaż dokumenty PDF planu kondycji używane na potrzeby tego przewodnika Szybki start.
W okienku po lewej stronie w obszarze Kontrola dostępu przypisz rolę Czytelnik danych obiektu blob usługi Storage do tożsamości usługi wyszukiwania. Możesz też uzyskać parametry połączenia do konta magazynu ze strony Klucze dostępu.
Opcjonalnie zsynchronizuj usunięcia w kontenerze z usunięciami w indeksie wyszukiwania. Te następne kroki umożliwiają skonfigurowanie indeksatora na potrzeby wykrywania usuwania:
Włącz usuwanie nietrwałe na koncie magazynu.
Jeśli używasz natywnego usuwania nietrwałego, w usłudze Azure Storage nie są wymagane żadne dalsze kroki.
W przeciwnym razie dodaj niestandardowe metadane, które indeksator może skanować, aby określić, które obiekty blob są oznaczone do usunięcia. Nadaj właściwości niestandardowej nazwę opisową. Można na przykład nazwać właściwość "IsDeleted", ustawioną na false. Zrób to dla każdego obiektu blob w kontenerze. Później, gdy chcesz usunąć obiekt blob, zmień właściwość na true. Aby uzyskać więcej informacji, zobacz Wykrywanie zmian i usuwania podczas indeksowania z usługi Azure Storage
Konfigurowanie modeli osadzania
Kreator może używać modeli osadzania wdrożonych z poziomu usług Azure OpenAI, Azure AI Vision lub z katalogu modeli w portalu Azure AI Foundry.
Kreator obsługuje osadzanie tekstu-ada-002, osadzanie tekstu-3-large i osadzanie tekstu-3-small. Wewnętrznie kreator wywołuje umiejętności AzureOpenAIEmbedding w celu nawiązania połączenia z usługą Azure OpenAI.
Zaloguj się do witryny Azure Portal przy użyciu konta platformy Azure i przejdź do zasobu Azure OpenAI.
Konfigurowanie uprawnień:
W menu po lewej stronie wybierz pozycję Kontrola dostępu.
Wybierz pozycję Dodaj, a następnie wybierz pozycję Dodaj przypisanie roli.
W obszarze Role funkcji zadania wybierz pozycję Użytkownik openAI usług Cognitive Services, a następnie wybierz pozycję Dalej.
W obszarze Członkowie wybierz pozycję Tożsamość zarządzana, a następnie wybierz pozycję Członkowie.
Filtruj według subskrypcji i typu zasobu (usługi wyszukiwania), a następnie wybierz tożsamość zarządzaną usługi wyszukiwania.
Wybierz Przejrzyj + przypisz.
Na stronie Przegląd wybierz pozycję Kliknij tutaj, aby wyświetlić punkty końcowe lub kliknij tutaj, aby zarządzać kluczami, jeśli chcesz skopiować punkt końcowy lub klucz interfejsu API. Możesz wkleić te wartości do kreatora, jeśli używasz zasobu usługi Azure OpenAI z uwierzytelnianiem opartym na kluczach.
W obszarze Zarządzanie zasobami i wdrożenia modelu wybierz pozycję Zarządzaj wdrożeniami, aby otworzyć usługę Azure AI Foundry.
Skopiuj nazwę
text-embedding-ada-002wdrożenia lub inny obsługiwany model osadzania. Jeśli nie masz modelu osadzania, wdróż go teraz.
Uruchamianie kreatora
Zaloguj się do witryny Azure Portal przy użyciu konta platformy Azure i przejdź do usługa wyszukiwania usługi Azure AI.
Na stronie Przegląd wybierz pozycję Importuj i wektoryzuj dane.

Nawiązywanie połączenia z danymi
Następnym krokiem jest nawiązanie połączenia ze źródłem danych w celu użycia indeksu wyszukiwania.
W obszarze Połącz z danymi wybierz pozycję Azure Blob Storage.
Określ subskrypcję platformy Azure.
Wybierz konto magazynu i kontener, który udostępnia dane.
Określ, czy chcesz obsługiwać wykrywanie usuwania. Podczas kolejnych przebiegów indeksowania indeks wyszukiwania jest aktualizowany w celu usunięcia wszelkich dokumentów wyszukiwania opartych na obiektach blob usuniętych nietrwale w usłudze Azure Storage.
- Obiekty blob obsługują natywne usuwanie nietrwałe obiektów blob lub usuwanie nietrwałe przy użyciu danych niestandardowych.
- Wcześniej włączono usuwanie nietrwałe w usłudze Azure Storage i opcjonalnie dodano niestandardowe metadane , które indeksowanie może rozpoznać jako flagę usuwania. Aby uzyskać więcej informacji na temat tych kroków, zobacz Przygotowywanie przykładowych danych.
- Jeśli obiekty blob zostały skonfigurowane do usuwania nietrwałego przy użyciu danych niestandardowych, podaj parę nazwa-wartość właściwości metadanych w tym kroku. Zalecamy użycie polecenia "IsDeleted". Jeśli wartość "IsDeleted" jest ustawiona na wartość true w obiekcie blob, indeksator pominie odpowiedni dokument wyszukiwania w następnym uruchomieniu indeksatora.
Kreator nie sprawdza prawidłowych ustawień usługi Azure Storage ani nie zgłasza błędu, jeśli wymagania nie zostały spełnione. Zamiast tego wykrywanie usuwania nie działa, a indeks wyszukiwania prawdopodobnie z czasem będzie zbierał oddzielone dokumenty.
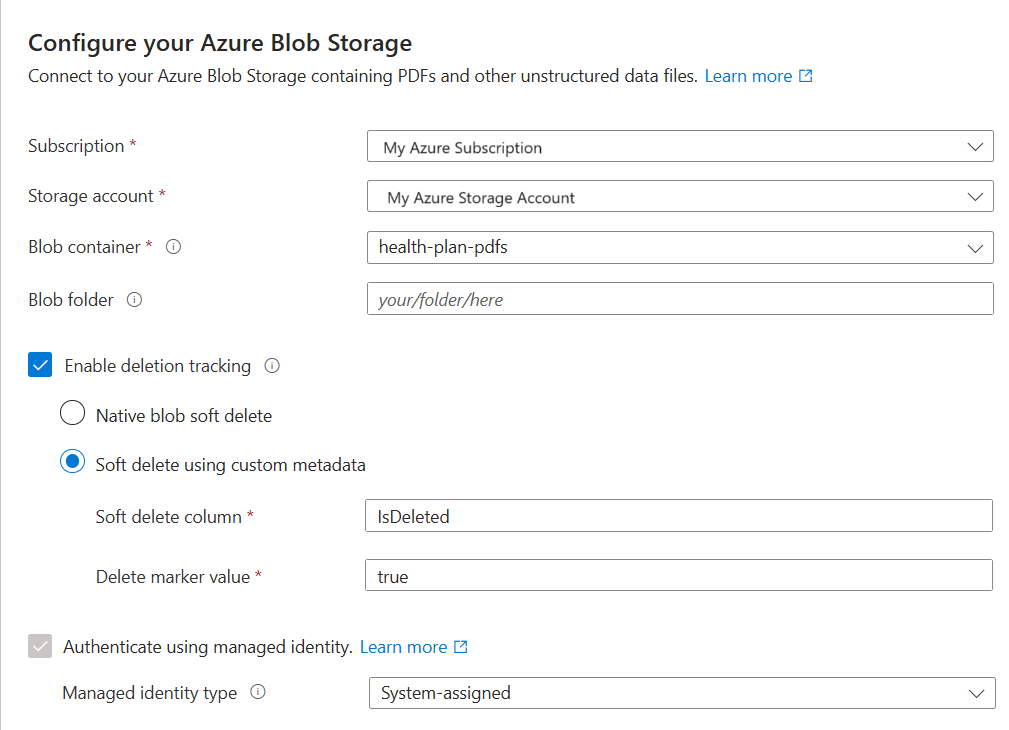
Określ, czy chcesz, aby usługa wyszukiwania łączyła się z usługą Azure Storage przy użyciu tożsamości zarządzanej.
- Zostanie wyświetlony monit o wybranie tożsamości zarządzanej przez system lub tożsamości zarządzanej przez użytkownika.
- Tożsamość powinna mieć rolę Czytelnik danych obiektu blob usługi Storage w usłudze Azure Storage.
- Nie pomijaj tego kroku. Podczas indeksowania występuje błąd połączenia, jeśli kreator nie może nawiązać połączenia z usługą Azure Storage.
Wybierz Dalej.
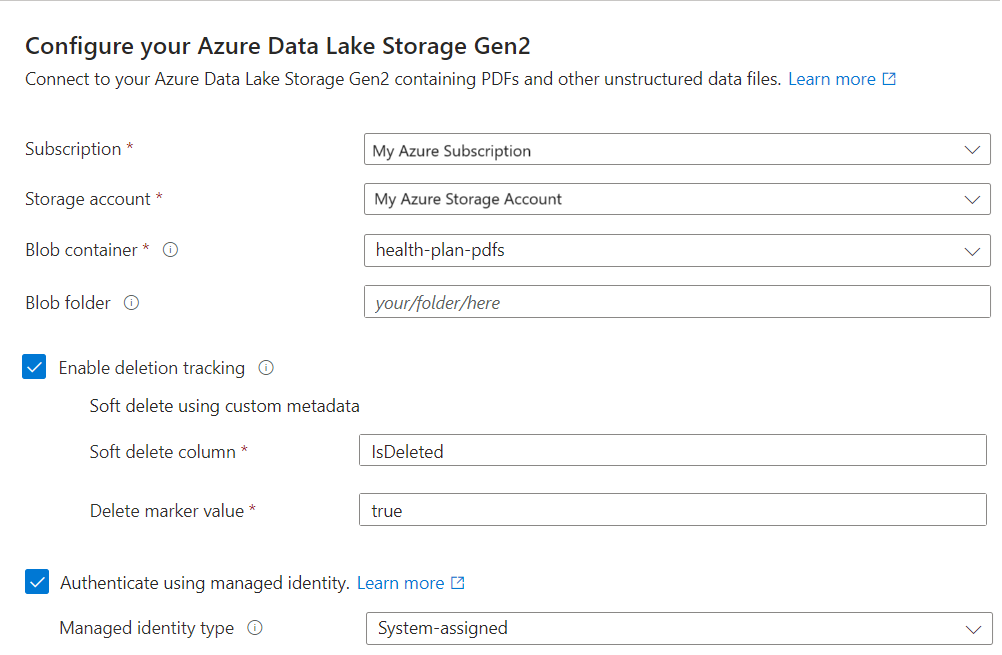
Wektoryzacja tekstu
W tym kroku określ model osadzania na potrzeby wektoryzacji danych fragmentowanych.
Fragmentowanie jest wbudowane i niekonfigurowalne. Obowiązujące ustawienia to:
"textSplitMode": "pages",
"maximumPageLength": 2000,
"pageOverlapLength": 500,
"maximumPagesToTake": 0, #unlimited
"unit": "characters"
Na stronie Wektoryzowanie tekstu wybierz źródło modelu osadzania:
- Azure OpenAI
- Katalog modeli usługi Azure AI Foundry
- Istniejący zasób wielomodalny usługi Azure AI Vision w tym samym regionie co usługa Azure AI Search. Jeśli w tym samym regionie nie ma konta usługi Azure AI Services, ta opcja nie jest dostępna.
Wybierz subskrypcję platformy Azure.
Dokonaj wyborów zgodnie z zasobem:
W przypadku usługi Azure OpenAI wybierz istniejące wdrożenie osadzania tekstu-ada-002, osadzanie tekstu-3-large lub osadzanie tekstu-3-small.
W przypadku katalogu usługi Azure AI Foundry wybierz istniejące wdrożenie modelu osadzania platformy Azure lub Cohere.
W przypadku osadzania wielomodalnego usługi AI Vision wybierz konto.
Aby uzyskać więcej informacji, zobacz Konfigurowanie modeli osadzania we wcześniejszej sekcji tego artykułu.
Określ, czy chcesz, aby usługa wyszukiwania uwierzytelniła się przy użyciu klucza interfejsu API, czy tożsamości zarządzanej.
- Tożsamość powinna mieć rolę użytkownika usług Cognitive Services na koncie usługi Azure AI z wieloma usługami.
Zaznacz pole wyboru, które potwierdza skutki rozliczeń korzystania z tych zasobów.
Wybierz Dalej.
Wektoryzacja i wzbogacanie obrazów
Pliki PDF planu kondycji zawierają logo firmowe, ale w przeciwnym razie nie ma żadnych obrazów. Jeśli używasz przykładowych dokumentów, możesz pominąć ten krok.
Jeśli jednak pracujesz z zawartością zawierającą przydatne obrazy, możesz zastosować sztuczną inteligencję na dwa sposoby:
Użyj obsługiwanego modelu osadzania obrazów z katalogu lub wybierz interfejs API osadzania wielomodalnego usługi Azure AI Vision, aby wektoryzować obrazy.
Rozpoznawanie znaków optycznych (OCR) umożliwia rozpoznawanie tekstu na obrazach. Ta opcja wywołuje umiejętności OCR do odczytywania tekstu z obrazów.
Usługa Azure AI Search i zasób usługi Azure AI muszą znajdować się w tym samym regionie lub skonfigurować pod kątem bezklukowych połączeń rozliczeniowych.
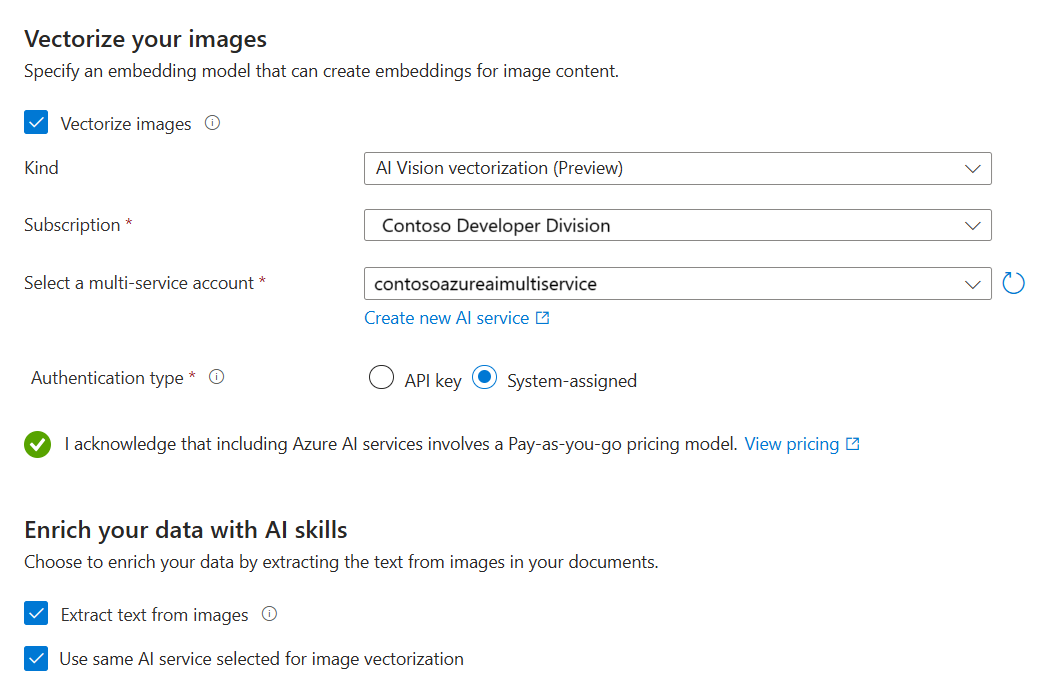
Na stronie Wektoryzacja obrazów określ rodzaj połączenia, które powinien wykonać kreator. W celu wektoryzacji obrazów kreator może nawiązać połączenie z osadzaniem modeli w witrynie Azure AI Foundry Portal lub azure AI Vision.
Określ subskrypcję.
W katalogu modeli usługi Azure AI Foundry określ projekt i wdrożenie. Aby uzyskać więcej informacji, zobacz Konfigurowanie modeli osadzania we wcześniejszej sekcji tego artykułu.
Opcjonalnie można złamać obrazy binarne (na przykład zeskanowane pliki dokumentów) i rozpoznawać tekst przy użyciu protokołu OCR .
Zaznacz pole wyboru, które potwierdza skutki rozliczeń korzystania z tych zasobów.
Wybierz Dalej.
Dodawanie klasyfikacji semantycznej
Na stronie Ustawienia zaawansowane możesz opcjonalnie dodać semantyczną klasyfikację, aby ponownie korbować wyniki na końcu wykonywania zapytania. Reranking promuje najbardziej semantycznie istotne mecze do góry.
Mapowanie nowych pól
Kluczowe kwestie dotyczące tego kroku:
- Schemat indeksu zapewnia pola wektorowe i niewektorowe dla fragmentowanych danych.
- Możesz dodawać pola, ale nie można usuwać ani modyfikować wygenerowanych pól.
- Tryb analizowania dokumentów tworzy fragmenty (jeden dokument wyszukiwania na fragment).
Na stronie Ustawienia zaawansowane możesz opcjonalnie dodać nowe pola przy założeniu, że źródło danych udostępnia metadane lub pola, które nie są pobierane podczas pierwszego przekazywania. Domyślnie kreator generuje następujące pola z następującymi atrybutami:
| Pole | Dotyczy | opis |
|---|---|---|
| chunk_id | Wektory tekstowe i obrazowe | Wygenerowane pole ciągu. Można wyszukiwać, pobierać i sortować. Jest to klucz dokumentu dla indeksu. |
| text_parent_id | Wektory tekstowe | Wygenerowane pole ciągu. Możliwe do pobrania, filtrowanie. Identyfikuje dokument nadrzędny, z którego pochodzi fragment. |
| chunk | Wektory tekstowe i obrazowe | Pole ciągu. Czytelna dla człowieka wersja fragmentu danych. Można wyszukiwać i pobierać, ale nie można filtrować, aspektów lub sortowania. |
| title | Wektory tekstowe i obrazowe | Pole ciągu. Czytelny dla człowieka tytuł dokumentu lub tytuł strony lub numer strony. Można wyszukiwać i pobierać, ale nie można filtrować, aspektów lub sortowania. |
| text_vector | Wektory tekstowe | Collection(Edm.single). Wektorowa reprezentacja fragmentu. Można wyszukiwać i pobierać, ale nie można filtrować, aspektów lub sortowania. |
Nie można modyfikować wygenerowanych pól ani ich atrybutów, ale możesz dodać nowe pola, jeśli źródło danych je udostępni. Na przykład usługa Azure Blob Storage udostępnia kolekcję pól metadanych.
Wybierz Dodaj nowy.
Wybierz pole źródłowe z listy dostępnych pól, podaj nazwę pola dla indeksu i zaakceptuj domyślny typ danych lub przesłoń w razie potrzeby.
Pola metadanych można przeszukiwać, ale nie można ich pobierać, filtrować, aspektów lub sortować.
Wybierz pozycję Resetuj , jeśli chcesz przywrócić schemat do oryginalnej wersji.
Indeksowanie harmonogramu
Na stronie Ustawienia zaawansowane można opcjonalnie określić harmonogram uruchamiania indeksatora.
- Po zakończeniu pracy ze stroną Ustawienia zaawansowane wybierz pozycję Dalej.
Kończenie pracy kreatora
Na stronie Przeglądanie konfiguracji określ prefiks obiektów tworzonych przez kreatora. Wspólny prefiks pomaga zachować organizację.
Wybierz pozycję Utwórz.
Po zakończeniu konfiguracji kreator tworzy następujące obiekty:
Połączenie ze źródłem danych.
Indeksowanie z polami wektorowymi, wektoryzatorami, profilami wektorów i algorytmami wektorów. Nie można zaprojektować ani zmodyfikować indeksu domyślnego podczas przepływu pracy kreatora. Indeksy są zgodne z interfejsem API REST 2024-05-01-preview.
Zestaw umiejętności z umiejętnościami dzielenia tekstu na potrzeby fragmentowania i umiejętności osadzania na potrzeby wektoryzacji. Umiejętności osadzania to umiejętności AzureOpenAIEmbeddingModel dla usługi Azure OpenAI lub umiejętności AML dla katalogu modeli usługi Azure AI Foundry. Zestaw umiejętności ma również konfigurację projekcji indeksów , która umożliwia mapowanie danych z jednego dokumentu w źródle danych do odpowiadających mu fragmentów w indeksie "podrzędnym".
Indeksator z mapowaniami pól i mapowaniami pól wyjściowych (jeśli ma zastosowanie).
Sprawdzanie wyników
Eksplorator wyszukiwania akceptuje ciągi tekstowe jako dane wejściowe, a następnie wektoryzuje tekst na potrzeby wykonywania zapytania wektorowego.
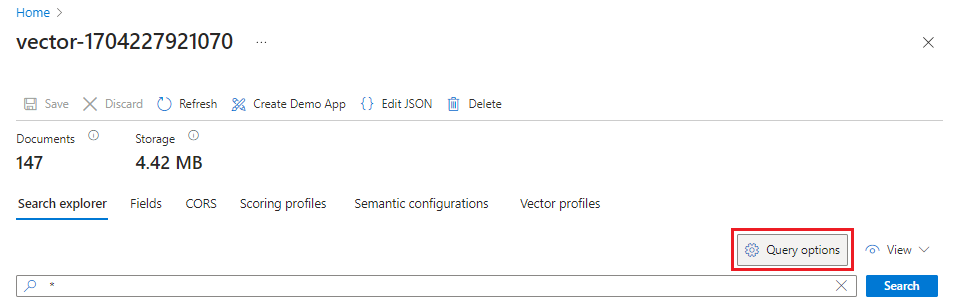
W witrynie Azure Portal przejdź do pozycji Indeksy zarządzania wyszukiwaniem>, a następnie wybierz utworzony indeks.
Wybierz pozycję Opcje zapytania i ukryj wartości wektorów w wynikach wyszukiwania. Ten krok ułatwia odczytywanie wyników wyszukiwania.
W menu Widok wybierz widok JSON, aby można było wprowadzić tekst zapytania wektorowego w parametrze zapytania wektorowego
text.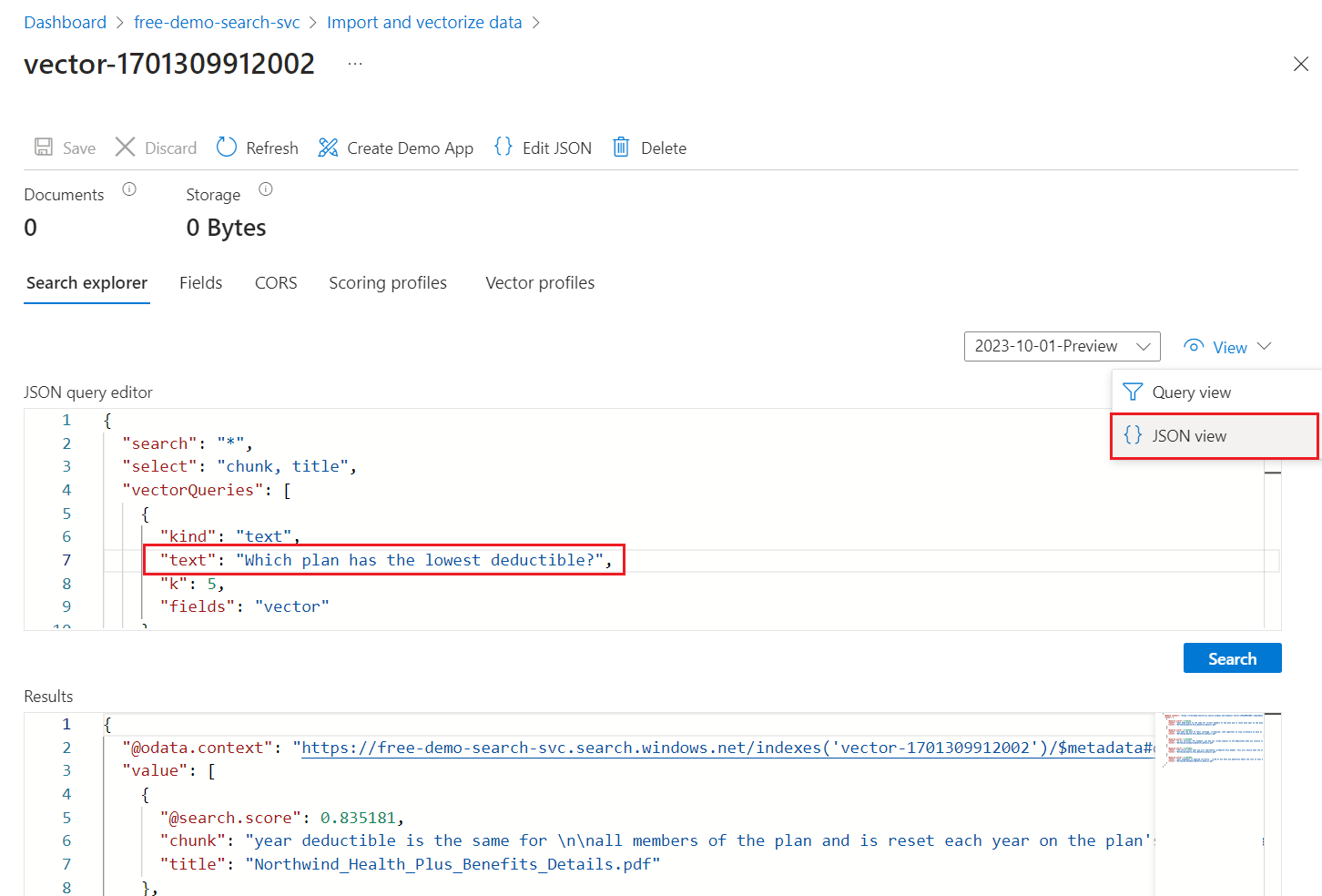
Zapytanie domyślne to puste wyszukiwanie (
"*"), ale zawiera parametry służące do zwracania dopasowań liczby. Jest to zapytanie hybrydowe, które uruchamia zapytania tekstowe i wektorowe równolegle. Obejmuje ona semantyczny ranking. Określa, które pola mają być zwracane w wynikach za pomocą instrukcjiselect.{ "search": "*", "count": true, "vectorQueries": [ { "kind": "text", "text": "*", "fields": "text_vector,image_vector" } ], "queryType": "semantic", "semanticConfiguration": "my-demo-semantic-configuration", "captions": "extractive", "answers": "extractive|count-3", "queryLanguage": "en-us", "select": "chunk_id,text_parent_id,chunk,title,image_parent_id" }Zastąp symbole zastępcze gwiazdki (
*) pytaniem związanym z planami zdrowotnymi, takimi jakWhich plan has the lowest deductible?.{ "search": "Which plan has the lowest deductible?", "count": true, "vectorQueries": [ { "kind": "text", "text": "Which plan has the lowest deductible?", "fields": "text_vector,image_vector" } ], "queryType": "semantic", "semanticConfiguration": "my-demo-semantic-configuration", "captions": "extractive", "answers": "extractive|count-3", "queryLanguage": "en-us", "select": "chunk_id,text_parent_id,chunk,title" }Wybierz pozycję Wyszukaj , aby uruchomić zapytanie.
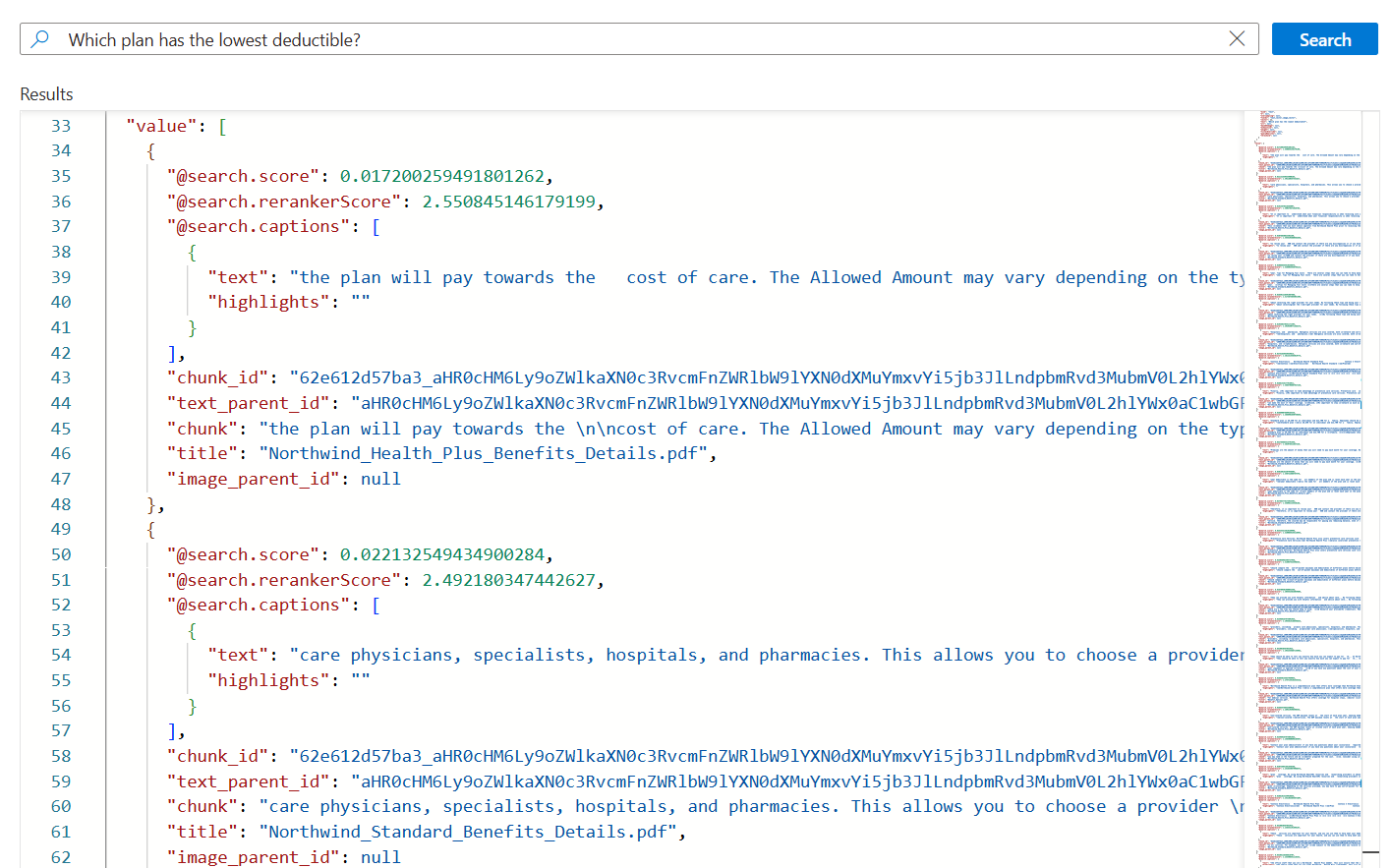
Każdy dokument jest fragmentem oryginalnego pliku PDF. Pole
titlepokazuje, z którego pliku PDF pochodzi fragment. Każdychunkz nich jest dość długi. Możesz skopiować i wkleić go do edytora tekstów, aby odczytać całą wartość.Aby wyświetlić wszystkie fragmenty z określonego dokumentu, dodaj filtr dla
title_parent_idpola dla określonego pliku PDF. Możesz sprawdzić kartę Pola indeksu, aby potwierdzić, że to pole jest filtrowalne.{ "select": "chunk_id,text_parent_id,chunk,title", "filter": "text_parent_id eq 'aHR0cHM6Ly9oZWlkaXN0c3RvcmFnZWRlbW9lYXN0dXMuYmxvYi5jb3JlLndpbmRvd3MubmV0L2hlYWx0aC1wbGFuLXBkZnMvTm9ydGh3aW5kX1N0YW5kYXJkX0JlbmVmaXRzX0RldGFpbHMucGRm0'", "count": true, "vectorQueries": [ { "kind": "text", "text": "*", "k": 5, "fields": "text_vector" } ] }
Czyszczenie
Usługa Azure AI Search to zasób rozliczany. Jeśli nie potrzebujesz go już, usuń go z subskrypcji, aby uniknąć naliczania opłat.
Następny krok
W tym przewodniku Szybki start przedstawiono kreatora Importowanie i wektoryzowanie danych , który tworzy wszystkie niezbędne obiekty do zintegrowanej wektoryzacji. Jeśli chcesz szczegółowo zapoznać się z poszczególnymi krokami, wypróbuj przykład zintegrowanej wektoryzacji.