Samouczek lakehouse: pozyskiwanie danych do lakehouse
W tym samouczku pozyskasz bardziej wymiarowe i faktyczne tabele z wide world importers (WWI) do jeziora.
Wymagania wstępne
- Jeśli nie masz jeziora, musisz utworzyć jezioro.
Pozyskiwanie danych
W tej sekcji użyjesz działania Kopiowania danych potoku usługi Data Factory, aby pozyskać przykładowe dane z konta usługi Azure Storage do sekcji Pliki utworzonej wcześniej usługi Lakehouse.
Wybierz pozycję Obszary robocze w okienku nawigacji po lewej stronie, a następnie wybierz nowy obszar roboczy z menu Obszary robocze . Zostanie wyświetlony widok elementów obszaru roboczego.
Na wstążce obszaru roboczego z opcji Nowy element wybierz pozycję Potok danych.
W oknie dialogowym Nowy potok określ nazwę IngestDataFromSourceToLakehouse i wybierz pozycję Utwórz. Zostanie utworzony i otwarty nowy potok fabryki danych.
Następnie skonfiguruj połączenie HTTP, aby zaimportować przykładowe dane World Wide Importers do usługi Lakehouse. Z listy Nowe źródła wybierz pozycję Wyświetl więcej, wyszukaj ciąg Http i wybierz go.
W oknie Łączenie ze źródłem danych wprowadź szczegóły z poniższej tabeli i wybierz pozycję Dalej.
Właściwości Wartość URL https://assetsprod.microsoft.com/en-us/wwi-sample-dataset.zipConnection Utwórz nowe połączenie Nazwa połączenia wwisampledata Brama danych Brak Rodzaj uwierzytelniania Anonimowe 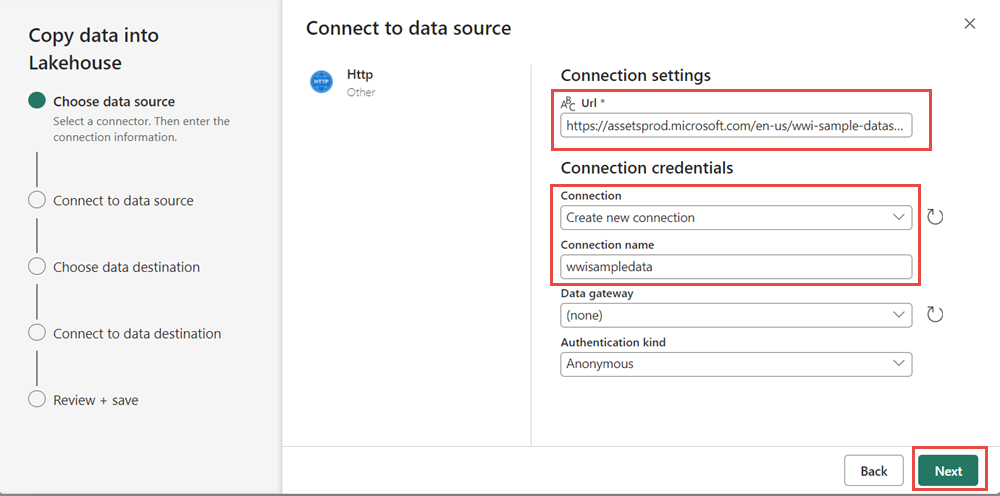
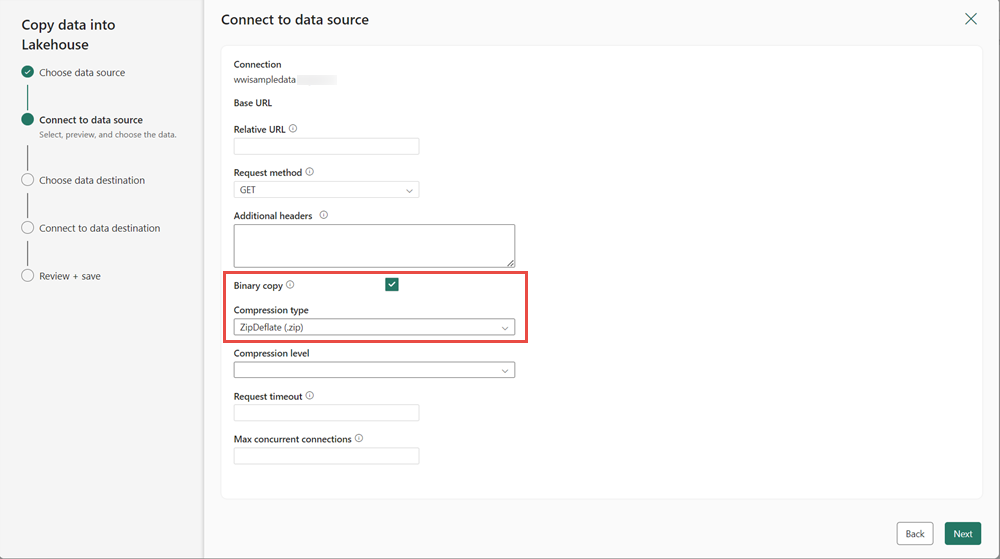
W następnym kroku włącz kopię binarną i wybierz pozycję ZipDeflate (.zip) jako typ kompresji, ponieważ źródło jest plikiem .zip. Zachowaj wartości domyślne pozostałych pól i kliknij przycisk Dalej.
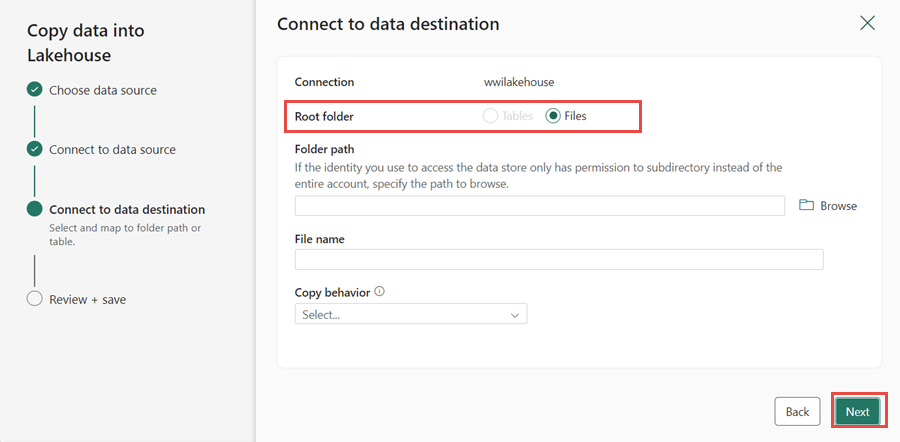
W oknie Łączenie z miejscem docelowym danych określ folder główny jako Pliki, a następnie kliknij przycisk Dalej. Spowoduje to zapisanie danych w sekcji Pliki w lakehouse.
Wybierz format pliku jako plik binarny dla miejsca docelowego. Kliknij przycisk Dalej , a następnie pozycję Zapisz i uruchom. Potoki można zaplanować, aby okresowo odświeżać dane. W tym samouczku uruchamiamy potok tylko raz. Proces kopiowania danych trwa około 10–15 minut.
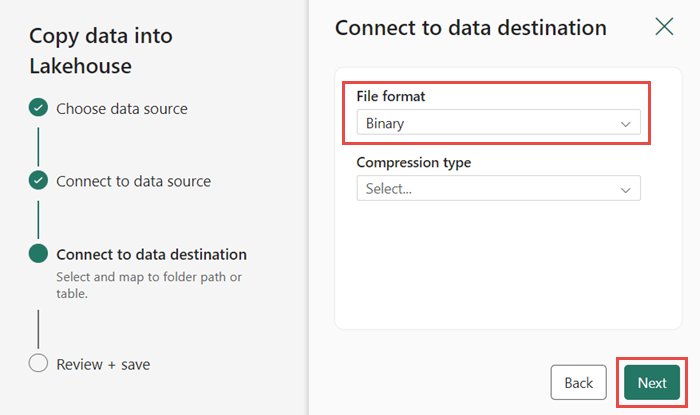
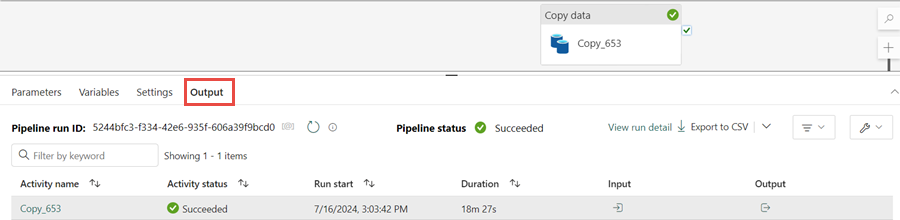
Możesz monitorować wykonywanie i działanie potoku na karcie Dane wyjściowe . Możesz również wyświetlić szczegółowe informacje o transferze danych, wybierając ikonę okularów obok nazwy potoku, która jest wyświetlana po umieszczeniu wskaźnika myszy na nazwie.
Po pomyślnym wykonaniu potoku przejdź do usługi Lakehouse (wwilakehouse) i otwórz eksploratora, aby wyświetlić zaimportowane dane.
Sprawdź, czy folder WideWorldImportersDW znajduje się w widoku Eksploratora i zawiera dane dla wszystkich tabel.
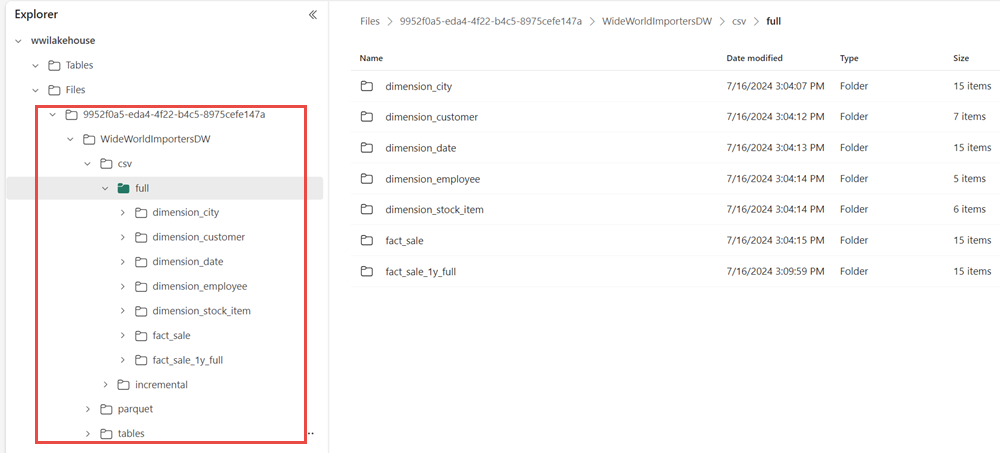
Dane są tworzone w sekcji Pliki eksploratora lakehouse. Nowy folder z identyfikatorem GUID zawiera wszystkie potrzebne dane. Zmienianie nazwy identyfikatora GUID na wwi-raw-data

Aby załadować dane przyrostowe do magazynu lakehouse, zobacz Przyrostowe ładowanie danych z magazynu danych do magazynu lakehouse.