Zelfstudie deel 3: Een machine learning-model trainen en registreren
In deze zelfstudie leert u hoe u meerdere machine learning-modellen traint om de beste te selecteren om te voorspellen welke bankklanten waarschijnlijk vertrekken.
In deze zelfstudie gaat u:
- Train Random Forest- en LightGBM-modellen.
- Gebruik de systeemeigen integratie van Microsoft Fabric met het MLflow-framework om de getrainde machine learning-modellen, de gebruikte hyperaparameters en metrische evaluatiegegevens te registreren.
- Registreer het getrainde machine learning-model.
- Evalueer de prestaties van de getrainde Machine Learning-modellen op de validatiegegevensset.
MLflow is een opensource-platform voor het beheren van de levenscyclus van machine learning met functies zoals Tracking, Models en Model Registry. MLflow is systeemeigen geïntegreerd met de Fabric Datawetenschap-ervaring.
Vereisten
Haal een Microsoft Fabric-abonnement op. Of meld u aan voor een gratis proefversie van Microsoft Fabric.
Meld u aan bij Microsoft Fabric.
Gebruik de ervaringswisselaar aan de linkerkant van de startpagina om over te schakelen naar Fabric.

Dit is deel 3 van 5 in de reeks zelfstudies. Als u deze zelfstudie wilt voltooien, moet u eerst het volgende voltooien:
- Deel 1: Gegevens opnemen in een Microsoft Fabric Lakehouse met behulp van Apache Spark.
- Deel 2: Gegevens verkennen en visualiseren met behulp van Microsoft Fabric-notebooks voor meer informatie over de gegevens.
Volgen in notitieblok
3-train-evaluate.ipynb is het notebook dat bij deze zelfstudie hoort.
Als u het bijbehorende notitieblok voor deze zelfstudie wilt openen, volgt u de instructies in Uw systeem voorbereiden op zelfstudies voor gegevenswetenschap om het notebook in uw werkruimte te importeren.
Als u liever de code van deze pagina kopieert en plakt, kunt u een nieuw notitieblok maken.
Zorg ervoor dat u een lakehouse aan het notebook koppelt voordat u begint met het uitvoeren van code.
Belangrijk
Koppel hetzelfde lakehouse dat u in deel 1 en deel 2 hebt gebruikt.
Aangepaste bibliotheken installeren
Voor dit notebook installeert u onevenwichtige learn (geïmporteerd als imblearn) met behulp van %pip install. Onevenwichtig leren is een bibliotheek voor Synthetic Minority Oversampling Technique (SMOTE) die wordt gebruikt bij het omgaan met onevenwichtige gegevenssets. De PySpark-kernel wordt opnieuw opgestart nadat %pip install, dus u moet de bibliotheek installeren voordat u andere cellen uitvoert.
U krijgt toegang tot SMOTE met behulp van de imblearn bibliotheek. Installeer deze nu met behulp van de inline-installatiemogelijkheden (bijvoorbeeld %pip, %conda).
# Install imblearn for SMOTE using pip
%pip install imblearn
Belangrijk
Voer deze installatie uit telkens wanneer u het notebook opnieuw start.
Wanneer u een bibliotheek in een notitieblok installeert, is deze alleen beschikbaar voor de duur van de notebooksessie en niet in de werkruimte. Als u het notitieblok opnieuw start, moet u de bibliotheek opnieuw installeren.
Als u een bibliotheek hebt die u vaak gebruikt en u deze beschikbaar wilt maken voor alle notitieblokken in uw werkruimte, kunt u hiervoor een Fabric-omgeving gebruiken. U kunt een omgeving maken, de bibliotheek erin installeren en vervolgens kan uw werkruimtebeheerder de omgeving als standaardomgeving aan de werkruimte koppelen. Zie Admin stelt standaardbibliotheken in voor de werkruimte voor meer informatie over het instellen van een omgeving als de standaardinstelling voor de werkruimte.
Zie Werkruimtebibliotheken en Spark-eigenschappen migreren naar een standaardomgeving voor informatie over het migreren van bestaande werkruimtebibliotheken en Spark-eigenschappen naar een omgeving.
De gegevens laden
Voordat u een machine learning-model traint, moet u de Delta-tabel uit lakehouse laden om de opgeschoonde gegevens te lezen die u in het vorige notebook hebt gemaakt.
import pandas as pd
SEED = 12345
df_clean = spark.read.format("delta").load("Tables/df_clean").toPandas()
Experiment genereren voor het bijhouden en vastleggen van het model met behulp van MLflow
In deze sectie wordt gedemonstreerd hoe u een experiment genereert, het machine learning-model en de trainingsparameters opgeeft, evenals scoregegevens, de machine learning-modellen traint, deze in een logboek opslaat en de getrainde modellen opslaat voor later gebruik.
import mlflow
# Setup experiment name
EXPERIMENT_NAME = "bank-churn-experiment" # MLflow experiment name
Het uitbreiden van de mogelijkheden voor automatisch vastleggen van MLflow-automatische logboekregistratie werkt door automatisch de waarden van invoerparameters en metrische uitvoergegevens van een machine learning-model vast te leggen terwijl het wordt getraind. Deze informatie wordt vervolgens vastgelegd in uw werkruimte, waar deze kan worden geopend en gevisualiseerd met behulp van de MLflow-API's of het bijbehorende experiment in uw werkruimte.
Alle experimenten met hun respectieve namen worden geregistreerd en u kunt hun parameters en prestatiemetrieken bijhouden. Zie Autologging in Microsoft Fabric voor meer informatie over automatisch aanmelden.
Specificaties voor experimenten en automatische logboeken instellen
mlflow.set_experiment(EXPERIMENT_NAME)
mlflow.autolog(exclusive=False)
Scikit-learn en LightGBM importeren
Nu uw gegevens zijn geïmplementeerd, kunt u de machine learning-modellen definiëren. In dit notebook past u Random Forest- en LightGBM-modellen toe. Gebruik scikit-learn en lightgbm implementeer de modellen binnen een paar regels code.
# Import the required libraries for model training
from sklearn.model_selection import train_test_split
from lightgbm import LGBMClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, f1_score, precision_score, confusion_matrix, recall_score, roc_auc_score, classification_report
Trainings-, validatie- en testgegevenssets voorbereiden
Gebruik de train_test_split functie van waaruit scikit-learn u de gegevens wilt splitsen in trainings-, validatie- en testsets.
y = df_clean["Exited"]
X = df_clean.drop("Exited",axis=1)
# Split the dataset to 60%, 20%, 20% for training, validation, and test datasets
# Train-Test Separation
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=SEED)
# Train-Validation Separation
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.25, random_state=SEED)
Testgegevens opslaan in een deltatabel
Sla de testgegevens op in de deltatabel voor gebruik in het volgende notebook.
table_name = "df_test"
# Create PySpark DataFrame from Pandas
df_test=spark.createDataFrame(X_test)
df_test.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark test DataFrame saved to delta table: {table_name}")
SMOTE toepassen op de trainingsgegevens om nieuwe steekproeven voor de minderheidsklasse te synthetiseren
Uit de gegevensverkenning in deel 2 bleek dat uit de 10.000 gegevenspunten die overeenkomen met 10.000 klanten, slechts 2037 klanten (ongeveer 20%) de bank hebben verlaten. Dit geeft aan dat de gegevensset zeer onevenwichtig is. Het probleem met onevenwichtige classificatie is dat er te weinig voorbeelden zijn van de minderheidsklasse voor een model om effectief de beslissingsgrens te leren. SMOTE is de meest gebruikte benadering om nieuwe steekproeven voor de minderheidsklasse te synthetiseren. Hier en hier vindt u meer informatie over SMOTE.
Tip
Houd er rekening mee dat SMOTE alleen moet worden toegepast op de trainingsgegevensset. U moet de testgegevensset in de oorspronkelijke onevenwichtige verdeling laten staan om een geldige benadering te krijgen van de prestaties van het machine learning-model op de oorspronkelijke gegevens, die de situatie in productie vertegenwoordigt.
from collections import Counter
from imblearn.over_sampling import SMOTE
sm = SMOTE(random_state=SEED)
X_res, y_res = sm.fit_resample(X_train, y_train)
new_train = pd.concat([X_res, y_res], axis=1)
Tip
U kunt het waarschuwingsbericht voor MLflow dat wordt weergegeven wanneer u deze cel uitvoert, negeren.
Als u een ModuleNotFoundError-bericht ziet, hebt u de eerste cel in dit notebook gemist, waarmee de imblearn bibliotheek wordt geïnstalleerd. U moet deze bibliotheek installeren telkens wanneer u het notitieblok opnieuw start. Ga terug en voer alle cellen opnieuw uit die beginnen met de eerste cel in dit notebook.
Modeltraining
- Het model trainen met random forest met een maximale diepte van 4 en 4 functies
mlflow.sklearn.autolog(registered_model_name='rfc1_sm') # Register the trained model with autologging
rfc1_sm = RandomForestClassifier(max_depth=4, max_features=4, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc1_sm") as run:
rfc1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc1_sm_run_id, run.info.status))
# rfc1.fit(X_train,y_train) # Imbalanaced training data
rfc1_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc1_sm.score(X_val, y_val)
y_pred = rfc1_sm.predict(X_val)
cr_rfc1_sm = classification_report(y_val, y_pred)
cm_rfc1_sm = confusion_matrix(y_val, y_pred)
roc_auc_rfc1_sm = roc_auc_score(y_res, rfc1_sm.predict_proba(X_res)[:, 1])
- Het model trainen met random forest met maximaal 8 en 6 functies
mlflow.sklearn.autolog(registered_model_name='rfc2_sm') # Register the trained model with autologging
rfc2_sm = RandomForestClassifier(max_depth=8, max_features=6, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc2_sm") as run:
rfc2_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc2_sm_run_id, run.info.status))
# rfc2.fit(X_train,y_train) # Imbalanced training data
rfc2_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc2_sm.score(X_val, y_val)
y_pred = rfc2_sm.predict(X_val)
cr_rfc2_sm = classification_report(y_val, y_pred)
cm_rfc2_sm = confusion_matrix(y_val, y_pred)
roc_auc_rfc2_sm = roc_auc_score(y_res, rfc2_sm.predict_proba(X_res)[:, 1])
- Het model trainen met LightGBM
# lgbm_model
mlflow.lightgbm.autolog(registered_model_name='lgbm_sm') # Register the trained model with autologging
lgbm_sm_model = LGBMClassifier(learning_rate = 0.07,
max_delta_step = 2,
n_estimators = 100,
max_depth = 10,
eval_metric = "logloss",
objective='binary',
random_state=42)
with mlflow.start_run(run_name="lgbm_sm") as run:
lgbm1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
# lgbm_sm_model.fit(X_train,y_train) # Imbalanced training data
lgbm_sm_model.fit(X_res, y_res.ravel()) # Balanced training data
y_pred = lgbm_sm_model.predict(X_val)
accuracy = accuracy_score(y_val, y_pred)
cr_lgbm_sm = classification_report(y_val, y_pred)
cm_lgbm_sm = confusion_matrix(y_val, y_pred)
roc_auc_lgbm_sm = roc_auc_score(y_res, lgbm_sm_model.predict_proba(X_res)[:, 1])
Artefact experimenten voor het bijhouden van modelprestaties
De uitvoeringen van het experiment worden automatisch opgeslagen in het experimentartefact dat u kunt vinden vanuit de werkruimte. Ze worden benoemd op basis van de naam die wordt gebruikt voor het instellen van het experiment. Alle getrainde machine learning-modellen, de uitvoeringen, metrische prestatiegegevens en modelparameters worden vastgelegd.
Uw experimenten weergeven:
Selecteer uw werkruimte in het linkerdeelvenster.
Filter rechtsboven om alleen experimenten weer te geven, zodat u het experiment dat u zoekt gemakkelijker kunt vinden.
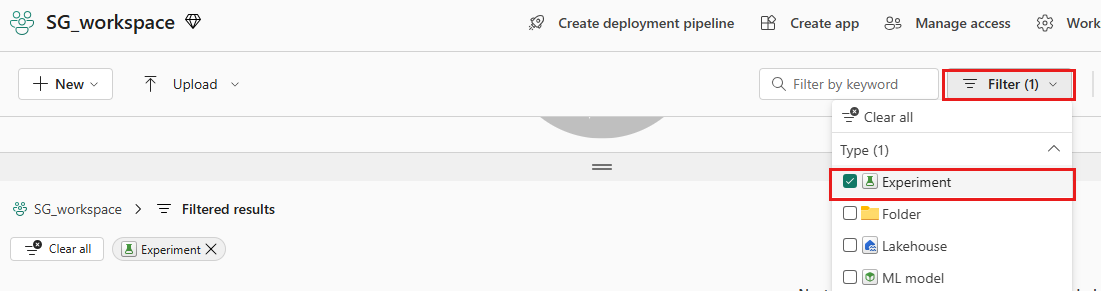
Zoek en selecteer de naam van het experiment, in dit geval bankverloop-experiment. Als u het experiment niet in uw werkruimte ziet, vernieuwt u de browser.
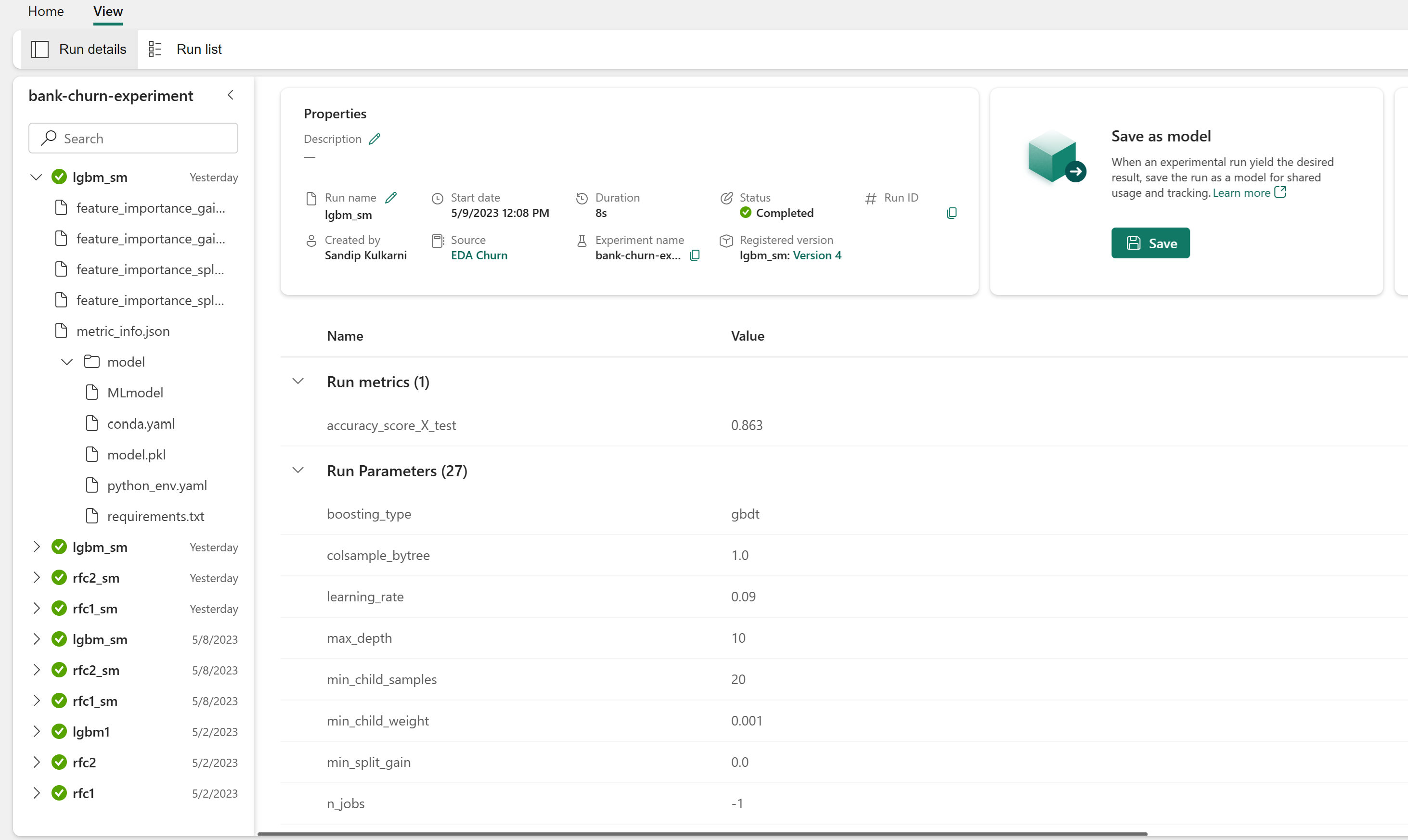


De prestaties van de getrainde modellen beoordelen op de validatiegegevensset
Zodra u klaar bent met machine learning-modeltraining, kunt u de prestaties van getrainde modellen op twee manieren beoordelen.
Open het opgeslagen experiment vanuit de werkruimte, laad de machine learning-modellen en evalueer vervolgens de prestaties van de geladen modellen in de validatiegegevensset.
# Define run_uri to fetch the model # mlflow client: mlflow.model.url, list model load_model_rfc1_sm = mlflow.sklearn.load_model(f"runs:/{rfc1_sm_run_id}/model") load_model_rfc2_sm = mlflow.sklearn.load_model(f"runs:/{rfc2_sm_run_id}/model") load_model_lgbm1_sm = mlflow.lightgbm.load_model(f"runs:/{lgbm1_sm_run_id}/model") # Assess the performance of the loaded model on validation dataset ypred_rfc1_sm_v1 = load_model_rfc1_sm.predict(X_val) # Random Forest with max depth of 4 and 4 features ypred_rfc2_sm_v1 = load_model_rfc2_sm.predict(X_val) # Random Forest with max depth of 8 and 6 features ypred_lgbm1_sm_v1 = load_model_lgbm1_sm.predict(X_val) # LightGBMBeoordeel rechtstreeks de prestaties van de getrainde Machine Learning-modellen op de validatiegegevensset.
ypred_rfc1_sm_v2 = rfc1_sm.predict(X_val) # Random Forest with max depth of 4 and 4 features ypred_rfc2_sm_v2 = rfc2_sm.predict(X_val) # Random Forest with max depth of 8 and 6 features ypred_lgbm1_sm_v2 = lgbm_sm_model.predict(X_val) # LightGBM
Afhankelijk van uw voorkeur is beide benaderingen prima en moeten identieke prestaties bieden. In dit notebook kiest u de eerste methode om de mogelijkheden voor automatische aanmelding van MLflow in Microsoft Fabric beter te demonstreren.
True/False Positives/Negatives weergeven met behulp van de Verwarringsmatrix
Vervolgens ontwikkelt u een script om de verwarringsmatrix uit te zetten om de nauwkeurigheid van de classificatie te evalueren met behulp van de validatiegegevensset. De verwarringsmatrix kan ook worden uitgezet met behulp van SynapseML-hulpprogramma's, die worden weergegeven in het voorbeeld fraudedetectie dat hier beschikbaar is.
import seaborn as sns
sns.set_theme(style="whitegrid", palette="tab10", rc = {'figure.figsize':(9,6)})
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
from matplotlib import rc, rcParams
import numpy as np
import itertools
def plot_confusion_matrix(cm, classes,
normalize=False,
title='Confusion matrix',
cmap=plt.cm.Blues):
print(cm)
plt.figure(figsize=(4,4))
plt.rcParams.update({'font.size': 10})
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45, color="blue")
plt.yticks(tick_marks, classes, color="blue")
fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt),
horizontalalignment="center",
color="red" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
- Verwarringsmatrix voor willekeurige forestclassificatie met maximale diepte van 4 en 4 functies
cfm = confusion_matrix(y_val, y_pred=ypred_rfc1_sm_v1)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 4')
tn, fp, fn, tp = cfm.ravel()
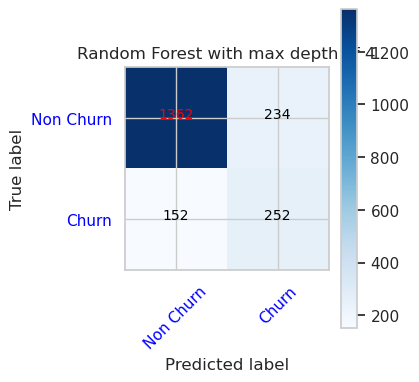
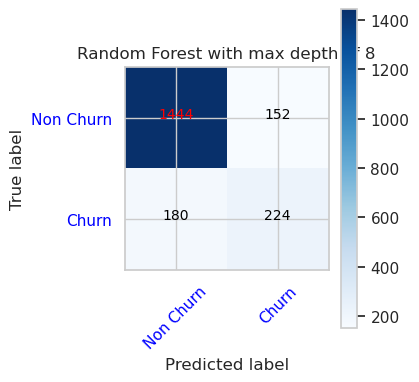
- Verwarringsmatrix voor willekeurige forestclassificatie met maximale diepte van 8 en 6 functies
cfm = confusion_matrix(y_val, y_pred=ypred_rfc2_sm_v1)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 8')
tn, fp, fn, tp = cfm.ravel()
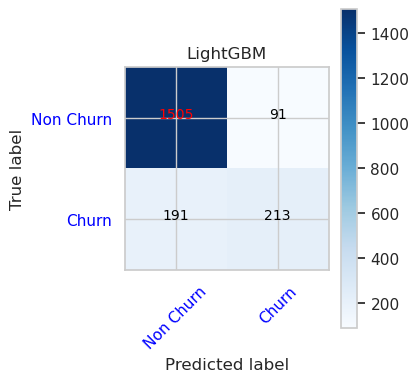
- Verwarringsmatrix voor LightGBM
cfm = confusion_matrix(y_val, y_pred=ypred_lgbm1_sm_v1)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='LightGBM')
tn, fp, fn, tp = cfm.ravel()